姓名:苗春雨 学号:16019110036
转载自:http://www.chinarobots.cn/JiQiXueXi/3648.html
【嵌牛导读】:机器学习的时代已经来临,它能带来怎样非凡的成就,现在还不好说,但是说它将改变软件工程师解决问题的方式,却是毋庸置疑的。
【嵌牛鼻子】:人工智能
【嵌牛提问】:机器学习是如何进行的?
机器学习的时代已经来临,它能带来怎样非凡的成就,现在还不好说,但是说它将改变软件工程师解决问题的方式,却是毋庸置疑的。
现在机器学习已经被不少公司广泛应用于各个领域,比如苹果的 Apple ARKit 用来创造更丰富更有层次感的用户体验,亚马逊的 Amazon Echo 用来回答复杂的用户问题,惠普将机器学习技术用于解决3D打印问题。机器学习是个非常强大的技术,编程人员应该学习如何利用机器学习去解决技术,最好不要在将来才开始,现在就行动。
《硅谷》里的Jing Yang也知道怎么用机器学习开发APP

应用机器学习
机器学习有很多运转部件。在本文,我会先通过帮你写一些代码来解释机器学习,然后再讨论开始下一步工作前可以做哪些准备工作。
首先我们想想在机器学习出现之前,软件都是怎么编出来的。软件工程师会通过给电脑逐步操作的指令解决具体的问题。

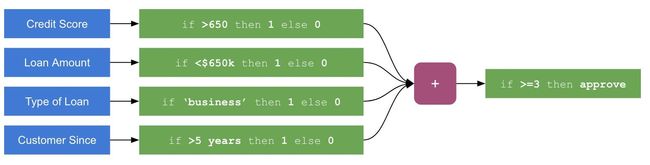
我们举一个银行业的例子。比如说,我们想写一个程序能预测贷款人会不会还他们的借款。我们可以写一个程序分析他们的用户资料,为关键变量设置参数:
信用评分(credit score)
贷款数目(loan amount)
贷款种类(type of loan)
成为银行用户的时间(Length of membership)
程序逻辑会如下所示:
简明银行贷款审批程序逻辑
如果问题复杂程度很高,那么手动调整参数和写指令的难度也会相应很高,甚至有时无法实现。想象一下给物体识别系统编程的难度吧。
但是机器看一下范例,就能学习怎么解决这些问题。
有了机器学习技术,编程人员就能训练一个机器学习模型,从数千个贷款人的数据中学习。模型还能随着时间推移不断更新,响应新趋势和更多的数据。例如,2017年国际信用界巨头艾可飞爆发安全漏洞后,那么来自艾可飞的信用评分就没有其它信用报告机构的数据那么有价值了。如果这要反映在真实的贷款结果上,机器学习模型可以调整相应的参数,减少艾可飞提供的信用评分的权重。有了足够的数据,机器学习模型会训练自己找到最优的参数。
这种技术称为监督式学习,在后面的教程中会用到它。(另外两种较为通用的技术是非监督式学习和增强学习)
简明银行贷款审批机器学习逻辑

搭建房价预测模型教程
学习机器学习技术的最快途径就是自己尝试去搭建一个机器学习模型,那么我们就来建一个自己的房价预测模型。先假定每套房子的基值为24万美元,每多一间卧室就增加15000美元(为了方便表达数字,以下用K代表1000)。
如下:
卧室数量房屋价格
0$240k
1$255k
2$270k
3$285k
4$300k
预测房价需要一个简单的线性模型:(y = mx + b)。我们可以用这个公式:
Priceof house = ($15k *# of bedrooms) + $240k
现在我们建一个机器学习模型去做这件事。通过使用训练数据,我想让模型找出m和b的值,这个我们知道分别是15和240。
我们用Python编写程序。用下面的代码新建一个 Python 文件,命名为 home_price.py。在代码中,我们先导入资料和数据,设置好一些初始变量,线性模型和损失函数。如果你的环境设置不允许,可以考虑安装 Docker,使用下面的 Docker 命令:
dockerrun-itgcr.io/tensorflow/tensorflow:latest /bin/bash
没错,不用打印报表和注释,就是15行代码 !
1. 数据建模
请点击运行按钮,导入TensorFlow并定义相应变量和模型。
Python 3重置复制
准备工作
1
importtensorflowastf
2
3
# 导入数据
4
y=tf.placeholder(tf.float32)
5
m=tf.Variable([1.0],tf.float32)
6
b=tf.Variable([1.0],tf.float32)
7
x=tf.placeholder(tf.float32)
8
9
# 创建模型
10
prediction=m*x+b
11
12
# 损失函数
13
loss=tf.reduce_sum(tf.square(prediction-y))
14
15
# 优化
16
optimizer=tf.trAIn.GradientDescentOptimizer(0.01)
17
train=optimizer.minimize(loss)
18
19
# 训练数据
20
bedrooms= [0,1,2,3,4]
21
price= [240,255,270,285,300]
运行
2. 模型训练
请点击运行按钮,启动TensorFlow的计算图。
注:如刷新了页面,请先重新运行上一段代码
Python 3重置复制
计算过程
1
# Session to run our code
2
withtf.Session()assess:
3
sess.run(tf.global_variables_initializer())
4
5
# Train our model 1000 times on training data
6
foriinrange(1000):
7
sess.run(train, {x:bedrooms,y:price})
8
9
# Print trained values for m and b
10
val_m,val_b=sess.run([m,b])
11
print("Value of m is %s and value of b is %s."%(val_m,val_b))
运行
希望读者朋友们除了阅读和运行代码之外,能够自由地修改、调试甚至调戏代码,尝试不同的训练数据、模型参数下输出结果的差异。
在代码中,我们设置了一些基本的在训练中会用到的占位符和变量。然后我们写一个损失函数,通过减去预测值中的y (给定值或者真实数值)进行计算。接着把得到的数值传给优化程序。每迭代一次,优化程序就会通过更新变量m和b的值尽可能地得到y的值和预测值。
接下来,我们就用训练数据把模型训练上1000次。最后,你应该会得到这样一个输出:
Valueofmis[15.00007153]andvalueofbis[239.99978638].
m的值为[ 15.00007153],b的值为[239.99978638]。
你觉得得到的m和b的值怎么样?和我们预测的值很接近对吧?

下面是每次迭代中模型如何被优化的直观图。最初m和b的值从1.0开始(我们在代码中指定了),但是随着时间推移,它们会慢慢接近正确的值。我们也可以看到损失值(预测— y)慢慢降低至0。
迭代100次后m,b的值和损失值(loss)

希望上面的教程能帮你理解机器学习的基础知识。不远的将来,每个编程人员都会在实际工作中用到机器学习技术,我们离npm install object-detect并不遥远。
