未经允许,不得转载,谢谢~~
TensorFlow作为深度学习的主流框架之一,还是非常有必要学习一下的.
本篇文章的代码与图片均来自官网文档Getting Started with TensorFLow
1 前期准备
预先善其事,必先利其器.
学习TensorFLow之前必须在电脑上下载并安装配置好TensorFlow。
关于TensorFlow的安装网上可以找到很多的教程,多找几个试试看就可以了。
官网也提供了相应的安装指南:Installing TensorFlow
2 获取样例代码
TensorFlow提供了很多的样例代码,供我们学习.
选择一个你想要用来放置这些代码的目录,然后运行以下命令就能获取到(当然前提是你的电脑上装好了git,更多关于git的操作戳这里哦~
git clone https://github.com/tensorflow/models-
然后进入到这篇文章里面用到的代码目录:
cd models/samples/core/get_started/
可以看到该目录下有4份代码文件。
这篇教程用到了其中的两个代码文件:-
premade_estimator.py用于模型建立以及训练测试 -
iris_data.py用于对数据集进行处理。
-
-
试试看运行程序
python premade_estimator.py我的电脑上运行的时候出现了错误。
- Bug:
AttributeError: 'module' object has no attribute 'keras' - 问题所在:AttributeError: module 'tensorflow' has no attribute 'keras'
- 原因: 我现在的tensorflow版本是1.3的,而官方的tensorflow已经升级到了1.4.新增加了
tf.kerastf.data等API - 解决方法:
pip install --upgrade tensorflow更新tensorflow
运行结果如下所示:
- Bug:

3 编程堆栈
如下所示是tensorflow给出的API结构图:
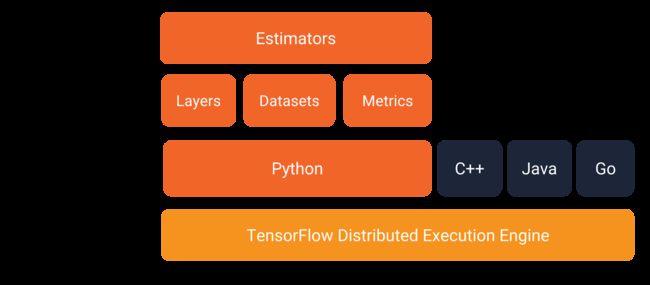
- 可以看到tensorflow支持Pytnon C++ Java Go四种语言,但对python的支持力度最大。
- 再往上提供了张量、数据集以及各种网络层的接口
- 最高层是
Estimators层,提供了训练模型,判断模型精确度等功能。
4 TensorFLow实战(Iris数据集分类)
4.1 任务介绍
如下所示,Iris总共有三种细分品种,从左到右分别为:Iris setosa, Iris versicolor, Iris virginica。
建立了一个根据图片的萼片大小以及花瓣大小来对Iris花朵进行分类的模型。
4.2 数据集
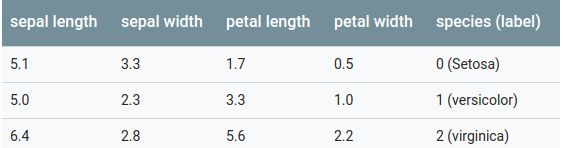
- Iris数据集包含4个特征和一个label
- 4个特征分别表示萼片长宽,花瓣长宽:
sepal length,sepal width,petal length,petal width,用float32的类型表示。 - label即花的品种,对应关系为:
Iris setosa (0),Iris versicolor (1),Iris virginica (2), 用int32的类型表示。 -
具体的3组样本如下所示:
4.3 网络结构设计
由于该问题并不复杂,所以设计的网络也不需要太大,2个隐含层就可以解决问题了,具体的细节如下图所示:
-
网络结构示意图:
网络结构 - 2层隐含层
- 每层隐含层都含10个节点
- 输出:3个数分别代表3个品种的可能性,3个数之和为1,例如图中所示的预测结果即为95%的可能性为
Iris Versicolor
4.4 Estimators评估器
-
Estimators评估器是TensorFlow用于实现一个完整的模型的最高层表示。 - 它可以处理参数初始化、日志记录、保存和恢复模型等功能。
- 更详细的介绍以及API可以戳这里
- TensorFLow提供了很多的预先写好的评估器,包括
DNNClassifier,DNNRegressor,LinearClassifier. - 一开始学习的时候可以直接使用tf提供的这些评估器,有经验之后也可以自己实现一个。
要使用tf预先写好的estimator,必须依次完成以下工作:
- 创建一个或多个输入函数
- 定义模型的特征列。
- 实例化estimator对象,并指定特征列和各种超参数。
- 在estimator对象上调用一个或多个方法,传递适当的输入函数作为数据源。
接下来将利用lris数据集来看看具体怎么样用estimator来一步步的实现神经网络模型的建立与训练。
1) 创建输入函数
- 任何的神经网络都需要数据来进行训练、评价以及测试。
- 输入函数需要返回
tf.data.Dataset对象,包含feature特征字典(key: featurename, value: featue),以及label两部分。 - 为了演示如何实现输入函数,具体的例子如下所示:
def input_evaluation_set():
features = {'SepalLength': np.array([6.4, 5.0]),
'SepalWidth': np.array([2.8, 2.3]),
'PetalLength': np.array([5.6, 3.3]),
'PetalWidth': np.array([2.2, 1.0])}
labels = np.array([2, 1])
return features, labels
- 以上的函数就会生成我们想要的
features字典以及label列表。 - 但tensorflow还是建议我们直接使用
Dataset类提供的API,来进行输入数据的处理。
Dataset类介绍
-
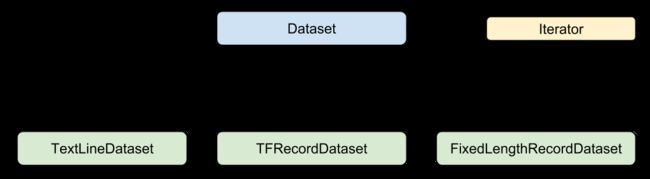
先看一下以下这张图:
-
Dataset:数据处理的父类,提供了用于创建、变换数据集的方法, 同时也支持从内存中初始化数据集。 -
TextLineDataset: 主要用于处理从文本文件中读取数据 -
TFRecordDataset: TFRecord数据文件是一种将图像数据和标签统一存储的二进制文件,能更好的利用内存,在tensorflow中快速的复制,移动,读取,存储等。TFRecordDataset就是对这样格式的数据读取提供接口。 -
FixedLengthRecordDataset: 从二进制文件中读取固定长度的数据。 -
Iterator: 提供迭代读取数据集元素的功能。 - 利用
Dataset提供的数据集可以方便的解决很多数据集读取的问题。
在iris_data.py中,我们先用pandas将数据载入到内存,然后用Dataset进行处理,具体的代码段如下:
def train_input_fn(features, labels, batch_size):
"""An input function for training"""
# Convert the inputs to a Dataset.
dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels))
# Shuffle, repeat, and batch the examples.
return dataset.shuffle(1000).repeat().batch(batch_size)
在处理自己的数据集的时候完成feature字典、 label列表的读取工作之后,用以上方法就能设置是否打乱数据集顺序并按batch_size读取数据集的功能。
更多的细节,比如Iris数据集的下载等等还是自己仔细看看iris_data.py这个代码文件哦~
2) 定义模型的特征列表
- 特征列表顾名思义就是包含样本各个特征名字的列表
- 当定义好estimator评估器的时候,传入特征的列表就表示这个模型需要使用哪些特征。
-
tf.feature_column:为将自己构建的特征列表传入评估器提供了接口。
在premade_estimator.py中,先构建了模型的特征列表:
# Feature columns describe how to use the input.
my_feature_columns = []
for key in train_x.keys():
my_feature_columns.append(tf.feature_column.numeric_column(key=key))
然后在estimator实例化的时候传入:
classifier = tf.estimator.DNNClassifier(
feature_columns=my_feature_columns,
# Two hidden layers of 10 nodes each.
hidden_units=[10, 10],
# The model must choose between 3 classes.
n_classes=3)
当然,tf.feature_column的使用比现在展示的可以复杂的多。
3) 实例化estimator对象
- 现在我们已经知道模型需要什么特征,接下来就可以实例化estimator评估器对象。
- tensorflow为我们提供了几个已经写好的分类器:
-
tf.estimator.DNNClassifier: 适用于多分类任务的深层模型 -
tf.estimator.DNNLinearCombinedClassifier: 适用于wide & deep模型。 -
tf.estimator.LinearClassifier: 适用于线性分类任务。
-
对于Iris分类任务来说,DNNClassifier貌似是最佳的选择:
# Build a DNN with 2 hidden layers and 10 nodes in each hidden layer.
classifier = tf.estimator.DNNClassifier(
feature_columns=my_feature_columns,
# Two hidden layers of 10 nodes each.
hidden_units=[10, 10],
# The model must choose between 3 classes.
n_classes=3)
4) 训练、评价以及测试
- 现在我们已经处理好了输入数据,并且定义好了estimator。
- 最后的工作就是训练模型、评价模型性能以及用训练好的模型来进行分类任务。
训练模型
-通过调动之前实例化好的estimator对象的train函数可以完成训练过程了,具体的调用形式如下所示:
# Train the Model.
classifier.train(
input_fn=lambda:iris_data.train_input_fn(train_x, train_y, args.batch_size),
steps=args.train_steps)
- 我们注意到用
lambda将输入数据的函数包装起来 - 另外
input_fn本身并没有有带参数,这一点符合Estimator的要求。 -
steps参数传入训练的步数。
评价模型
- 模型训练好之后,我们可以用一些数据来测试模型的性能。
# Evaluate the model.
eval_result = classifier.evaluate(
input_fn=lambda:iris_data.eval_input_fn(test_x, test_y, args.batch_size))
print('\nTest set accuracy: {accuracy:0.3f}\n'.format(**eval_result))
- 输出结果:
Test set accuracy: 0.967 - 跟
train不一样的时候,我们没有传入steps参数。
用训练好的模型进行分类任务
- 现在可以用经过训练的模型进行预测没有标注过的样本数据的预测任务:
# Generate predictions from the model
expected = ['Setosa', 'Versicolor', 'Virginica']
predict_x = {
'SepalLength': [5.1, 5.9, 6.9],
'SepalWidth': [3.3, 3.0, 3.1],
'PetalLength': [1.7, 4.2, 5.4],
'PetalWidth': [0.5, 1.5, 2.1],
}
predictions = classifier.predict(
input_fn=lambda:iris_data.eval_input_fn(predict_x,
batch_size=args.batch_size))
-
predict函数返回了一个包含每个样本的预测值的字典,接下来的这几行代码会将具体的内容打印出来:
for pred_dict, expec in zip(predictions, expected):
template = ('\nPrediction is "{}" ({:.1f}%), expected "{}"')
class_id = pred_dict['class_ids'][0]
probability = pred_dict['probabilities'][class_id]
print(template.format(iris_data.SPECIES[class_id],
100 * probability, expec))
结果就如我们开头所见的那样:

如图我们总共输入3个样本的数据,模型帮我们分别预测了3个样本的所属类别。
5 总结
01
我自己也真的是刚刚开始学习使用TensorFow,虽然跟着官网的文档一点点的学下来了,但还是感觉很多小的细节都还不是很清楚呢(/捂脸.jpg)
02
个人感觉PyTorch会比TensorFlow好用一点呢,至少从官网给出的文档来说,感觉PyTorch的思路更加清晰, 学完60分钟入门的文档基本就知道用Pytorch实现整个网络从构建到训练,测试的整个过程了~
当然也有可能是花在TensorFlow上的时候还是不够多。毕竟是Google推出的深度学习框架,不敢妄加评议。
03
安利最近在看的一本书《TensorFlow 实战Google深度学习框架》给同样想学习TensorFlow的小伙伴们,还是不错的。
最后有错误或者不合适的地方欢迎简信交流,感激不尽。
参考资料
TensorFlow官网-Getting Started with TensorFLow