一、软件环境
我使用的软件版本如下:
- Intellij Idea 2017.1
- Maven 3.3.9
- Hadoop分布式环境
二、创建maven工程
打开Idea,file->new->Project,左侧面板选择maven工程。(如果只跑MapReduce创建java工程即可,不用勾选Creat from archetype,如果想创建web工程或者使用骨架可以勾选)
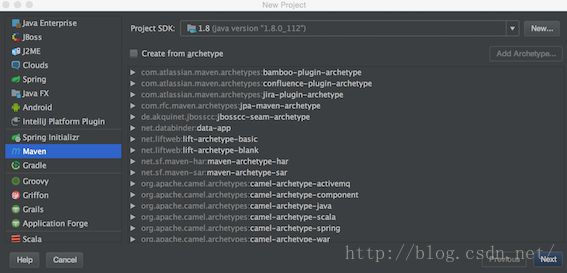
设置GroupId和ArtifactId,下一步。

设置工程存储路径,下一步。

Finish之后,空白工程的路径如下图所示。

完整的工程路径如下图所示:

三、添加maven依赖
在pom.xml添加依赖,对于hadoop 2.7.3版本的hadoop,需要的jar包有以下几个:
hadoop-common
hadoop-hdfs
hadoop-mapreduce-client-core
hadoop-mapreduce-client-jobclient
-
log4j( 打印日志)
pom.xml中的依赖如下:
junit
junit
4.12
test
org.apache.hadoop
hadoop-common
2.7.3
org.apache.hadoop
hadoop-hdfs
2.7.3
org.apache.hadoop
hadoop-mapreduce-client-core
2.7.3
org.apache.hadoop
hadoop-mapreduce-client-jobclient
2.7.3
log4j
log4j
1.2.17
四、配置log4j
在src/main/resources目录下新增log4j的配置文件log4j.properties,内容如下:
log4j.rootLogger = debug,stdout
### 输出信息到控制抬 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
五、启动Hadoop
启动Hadoop,运行命令:
cd hadoop-2.7.3/
./sbin/start-all.sh
访问http://localhost:50070/查看hadoop是否正常启动。
六、运行WordCount(从本地读取文件)
在工程根目录下新建input文件夹,input文件夹下新增dream.txt,随便写入一些单词:
I have a dream
a dream
在src/main/java目录下新建包,新增FileUtil.java,创建一个删除output文件的函数,以后就不用手动删除了。内容如下:
package com.mrtest.hadoop;
import java.io.File;
/**
* Created by bee on 3/25/17.
*/
public class FileUtil {
public static boolean deleteDir(String path) {
File dir = new File(path);
if (dir.exists()) {
for (File f : dir.listFiles()) {
if (f.isDirectory()) {
deleteDir(f.getName());
} else {
f.delete();
}
}
dir.delete();
return true;
} else {
System.out.println("文件(夹)不存在!");
return false;
}
}
}
2、wordcount程序实现
1、编写map方法
package com.neusoft;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* 该类做为一个 mapTask 使用。类声名中所使用的四个泛型意义为别为:
*
* KEYIN: 默认情况下,是mr框架所读到的一行文本的起始偏移量,Long,
* 但是在hadoop中有自己的更精简的序列化接口,所以不直接用Long,而用LongWritable
* VALUEIN: 默认情况下,是mr框架所读到的一行文本的内容,String,同上,用Text
* KEYOUT: 是用户自定义逻辑处理完成之后输出数据中的key,在此处是单词,String,同上,用Text
* VALUEOUT:是用户自定义逻辑处理完成之后输出数据中的value,在此处是单词次数,Integer,同上,用IntWritable
*/
public class WordcountMapper extends Mapper {
/**
* map阶段的业务逻辑就写在自定义的map()方法中 maptask会对每一行输入数据调用一次我们自定义的map()方法
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 将maptask传给我们的文本内容先转换成String
String line = value.toString();
// 根据空格将这一行切分成单词
String[] words = line.split(" ");
// 将单词输出为<单词,1>
for (String word : words) {
// 将单词作为key,将次数1作为value,以便于后续的数据分发,可以根据单词分发,以便于相同单词会到相同的reduce task
context.write(new Text(word), new IntWritable(1));
}
}
}
2、编写reduce方法
package com.neusoft;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* 与 Mapper 类似,继承的同事声名四个泛型。
* KEYIN, VALUEIN 对应 mapper输出的KEYOUT,VALUEOUT类型对应
* KEYOUT, VALUEOUT 是自定义reduce逻辑处理结果的输出数据类型。此处 keyOut 表示单个单词,valueOut 对应的是总次数
*/
public class WordcountReducer extends Reducer{
/**
*
*
*
* 入参key,是一组相同单词kv对的key
*/
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int count=0;
for(IntWritable value : values){
count += value.get();
}
context.write(key, new IntWritable(count)); //输出每一个单词出现的次数
}
}
解释:
map()方法中我们设置的时候单词做为key,1作为value写出,比如
package com.neusoft;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 相当于一个yarn集群的客户端
* 需要在此封装我们的mr程序的相关运行参数,指定jar包
* 最后提交给yarn
*/
public class WordcountDriver {
public static void main(String[] args) throws Exception {
System.setProperty("hadoop.home.dir", "e:/hadoop-2.8.3");
if (args == null || args.length == 0) {
return;
}
//该对象会默认读取环境中的 hadoop 配置。当然,也可以通过 set 重新进行配置
Configuration conf = new Configuration();
//job 是 yarn 中任务的抽象。
Job job = Job.getInstance(conf);
/*job.setJar("/home/hadoop/wc.jar");*/
//指定本程序的jar包所在的本地路径
job.setJarByClass(WordcountDriver.class);
//指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
//指定mapper输出数据的kv类型。需要和 Mapper 中泛型的类型保持一致
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//指定最终输出的数据的kv类型。这里也是 Reduce 的 key,value类型。
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定job的输出结果所在目录
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//将job中配置的相关参数,以及job所用的java类所在的jar包,提交给yarn去运行
/*job.submit();*/
boolean res = job.waitForCompletion(true);
System.exit(res?0:1);
}
}
这里在main函数中新增了一个String类型的数组,如果想用main函数的args数组接受参数,在运行时指定输入和输出路径也是可以的。运行WordCount之前,配置Configuration并指定Program arguments即可。

七、运行WordCount(从HDFS读取文件)
在HDFS上新建文件夹:
hadoop fs -mkdir /worddir
如果出现Namenode安全模式导致的不能创建文件夹提示:
mkdir: Cannot create directory /worddir. Name node is in safe mode.
运行以下命令关闭safe mode:
hadoop dfsadmin -safemode leave
上传本地文件:
hadoop fs -put dream.txt /worddir
修改otherArgs参数,指定输入为文件在HDFS上的路径:
String[] otherArgs = new String[]{"hdfs://localhost:9000/worddir/dream.txt","output"};
解决org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
这个问题来的有点莫名奇妙,之前我的hadoop运行一直是正常的,某一天开始运行Mapreduce就报这个错。
试过很多种方法都没有用,比如
1.path环境变量
2.Hadoop bin目录下hadoop.dll和winutils.exe
3.c:\windows\system32 下的hadoop.dll
4.64为jdk
条件都满足了还是报错



试了这些方法都没有用,最后只有改源码了。
下载相应版本的源码解压,找到NativeIO.java文件。将它加入到工程中去,如下图

修改NativeIO.java

最后重新执行程序就正常了
Windows7出现这个问题
需要在你的 Module下创建一个名为org.apache.hadoop.io.nativeio的包
在这个包下创建一个Class 名为 NativeIO
然后粘贴如下代码
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.io.nativeio;
import java.io.File;
import java.io.FileDescriptor;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.lang.reflect.Field;
import java.nio.ByteBuffer;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.CommonConfigurationKeys;
import org.apache.hadoop.fs.HardLink;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.SecureIOUtils.AlreadyExistsException;
import org.apache.hadoop.util.NativeCodeLoader;
import org.apache.hadoop.util.Shell;
import org.apache.hadoop.util.PerformanceAdvisory;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import sun.misc.Unsafe;
import com.google.common.annotations.VisibleForTesting;
/**
* JNI wrappers for various native IO-related calls not available in Java.
* These functions should generally be used alongside a fallback to another
* more portable mechanism.
*/
@InterfaceAudience.Private
@InterfaceStability.Unstable
public class NativeIO {
public static class POSIX {
// Flags for open() call from bits/fcntl.h
public static final int O_RDONLY = 00;
public static final int O_WRONLY = 01;
public static final int O_RDWR = 02;
public static final int O_CREAT = 0100;
public static final int O_EXCL = 0200;
public static final int O_NOCTTY = 0400;
public static final int O_TRUNC = 01000;
public static final int O_APPEND = 02000;
public static final int O_NONBLOCK = 04000;
public static final int O_SYNC = 010000;
public static final int O_ASYNC = 020000;
public static final int O_FSYNC = O_SYNC;
public static final int O_NDELAY = O_NONBLOCK;
// Flags for posix_fadvise() from bits/fcntl.h
/* No further special treatment. */
public static final int POSIX_FADV_NORMAL = 0;
/* Expect random page references. */
public static final int POSIX_FADV_RANDOM = 1;
/* Expect sequential page references. */
public static final int POSIX_FADV_SEQUENTIAL = 2;
/* Will need these pages. */
public static final int POSIX_FADV_WILLNEED = 3;
/* Don't need these pages. */
public static final int POSIX_FADV_DONTNEED = 4;
/* Data will be accessed once. */
public static final int POSIX_FADV_NOREUSE = 5;
/* Wait upon writeout of all pages
in the range before performing the
write. */
public static final int SYNC_FILE_RANGE_WAIT_BEFORE = 1;
/* Initiate writeout of all those
dirty pages in the range which are
not presently under writeback. */
public static final int SYNC_FILE_RANGE_WRITE = 2;
/* Wait upon writeout of all pages in
the range after performing the
write. */
public static final int SYNC_FILE_RANGE_WAIT_AFTER = 4;
private static final Log LOG = LogFactory.getLog(NativeIO.class);
private static boolean nativeLoaded = false;
private static boolean fadvisePossible = true;
private static boolean syncFileRangePossible = true;
static final String WORKAROUND_NON_THREADSAFE_CALLS_KEY =
"hadoop.workaround.non.threadsafe.getpwuid";
static final boolean WORKAROUND_NON_THREADSAFE_CALLS_DEFAULT = true;
private static long cacheTimeout = -1;
private static CacheManipulator cacheManipulator = new CacheManipulator();
public static CacheManipulator getCacheManipulator() {
return cacheManipulator;
}
public static void setCacheManipulator(CacheManipulator cacheManipulator) {
POSIX.cacheManipulator = cacheManipulator;
}
/**
* Used to manipulate the operating system cache.
*/
@VisibleForTesting
public static class CacheManipulator {
public void mlock(String identifier, ByteBuffer buffer,
long len) throws IOException {
POSIX.mlock(buffer, len);
}
public long getMemlockLimit() {
return NativeIO.getMemlockLimit();
}
public long getOperatingSystemPageSize() {
return NativeIO.getOperatingSystemPageSize();
}
public void posixFadviseIfPossible(String identifier,
FileDescriptor fd, long offset, long len, int flags)
throws NativeIOException {
NativeIO.POSIX.posixFadviseIfPossible(identifier, fd, offset,
len, flags);
}
public boolean verifyCanMlock() {
return NativeIO.isAvailable();
}
}
/**
* A CacheManipulator used for testing which does not actually call mlock.
* This allows many tests to be run even when the operating system does not
* allow mlock, or only allows limited mlocking.
*/
@VisibleForTesting
public static class NoMlockCacheManipulator extends CacheManipulator {
public void mlock(String identifier, ByteBuffer buffer,
long len) throws IOException {
LOG.info("mlocking " + identifier);
}
public long getMemlockLimit() {
return 1125899906842624L;
}
public long getOperatingSystemPageSize() {
return 4096;
}
public boolean verifyCanMlock() {
return true;
}
}
static {
if (NativeCodeLoader.isNativeCodeLoaded()) {
try {
Configuration conf = new Configuration();
workaroundNonThreadSafePasswdCalls = conf.getBoolean(
WORKAROUND_NON_THREADSAFE_CALLS_KEY,
WORKAROUND_NON_THREADSAFE_CALLS_DEFAULT);
initNative();
nativeLoaded = true;
cacheTimeout = conf.getLong(
CommonConfigurationKeys.HADOOP_SECURITY_UID_NAME_CACHE_TIMEOUT_KEY,
CommonConfigurationKeys.HADOOP_SECURITY_UID_NAME_CACHE_TIMEOUT_DEFAULT) *
1000;
LOG.debug("Initialized cache for IDs to User/Group mapping with a " +
" cache timeout of " + cacheTimeout/1000 + " seconds.");
} catch (Throwable t) {
// This can happen if the user has an older version of libhadoop.so
// installed - in this case we can continue without native IO
// after warning
PerformanceAdvisory.LOG.debug("Unable to initialize NativeIO libraries", t);
}
}
}
/**
* Return true if the JNI-based native IO extensions are available.
*/
public static boolean isAvailable() {
return NativeCodeLoader.isNativeCodeLoaded() && nativeLoaded;
}
private static void assertCodeLoaded() throws IOException {
if (!isAvailable()) {
throw new IOException("NativeIO was not loaded");
}
}
/** Wrapper around open(2) */
public static native FileDescriptor open(String path, int flags, int mode) throws IOException;
/** Wrapper around fstat(2) */
private static native Stat fstat(FileDescriptor fd) throws IOException;
/** Native chmod implementation. On UNIX, it is a wrapper around chmod(2) */
private static native void chmodImpl(String path, int mode) throws IOException;
public static void chmod(String path, int mode) throws IOException {
if (!Shell.WINDOWS) {
chmodImpl(path, mode);
} else {
try {
chmodImpl(path, mode);
} catch (NativeIOException nioe) {
if (nioe.getErrorCode() == 3) {
throw new NativeIOException("No such file or directory",
Errno.ENOENT);
} else {
LOG.warn(String.format("NativeIO.chmod error (%d): %s",
nioe.getErrorCode(), nioe.getMessage()));
throw new NativeIOException("Unknown error", Errno.UNKNOWN);
}
}
}
}
/** Wrapper around posix_fadvise(2) */
static native void posix_fadvise(
FileDescriptor fd, long offset, long len, int flags) throws NativeIOException;
/** Wrapper around sync_file_range(2) */
static native void sync_file_range(
FileDescriptor fd, long offset, long nbytes, int flags) throws NativeIOException;
/**
* Call posix_fadvise on the given file descriptor. See the manpage
* for this syscall for more information. On systems where this
* call is not available, does nothing.
*
* @throws NativeIOException if there is an error with the syscall
*/
static void posixFadviseIfPossible(String identifier,
FileDescriptor fd, long offset, long len, int flags)
throws NativeIOException {
if (nativeLoaded && fadvisePossible) {
try {
posix_fadvise(fd, offset, len, flags);
} catch (UnsupportedOperationException uoe) {
fadvisePossible = false;
} catch (UnsatisfiedLinkError ule) {
fadvisePossible = false;
}
}
}
/**
* Call sync_file_range on the given file descriptor. See the manpage
* for this syscall for more information. On systems where this
* call is not available, does nothing.
*
* @throws NativeIOException if there is an error with the syscall
*/
public static void syncFileRangeIfPossible(
FileDescriptor fd, long offset, long nbytes, int flags)
throws NativeIOException {
if (nativeLoaded && syncFileRangePossible) {
try {
sync_file_range(fd, offset, nbytes, flags);
} catch (UnsupportedOperationException uoe) {
syncFileRangePossible = false;
} catch (UnsatisfiedLinkError ule) {
syncFileRangePossible = false;
}
}
}
static native void mlock_native(
ByteBuffer buffer, long len) throws NativeIOException;
/**
* Locks the provided direct ByteBuffer into memory, preventing it from
* swapping out. After a buffer is locked, future accesses will not incur
* a page fault.
*
* See the mlock(2) man page for more information.
*
* @throws NativeIOException
*/
static void mlock(ByteBuffer buffer, long len)
throws IOException {
assertCodeLoaded();
if (!buffer.isDirect()) {
throw new IOException("Cannot mlock a non-direct ByteBuffer");
}
mlock_native(buffer, len);
}
/**
* Unmaps the block from memory. See munmap(2).
*
* There isn't any portable way to unmap a memory region in Java.
* So we use the sun.nio method here.
* Note that unmapping a memory region could cause crashes if code
* continues to reference the unmapped code. However, if we don't
* manually unmap the memory, we are dependent on the finalizer to
* do it, and we have no idea when the finalizer will run.
*
* @param buffer The buffer to unmap.
*/
public static void munmap(MappedByteBuffer buffer) {
if (buffer instanceof sun.nio.ch.DirectBuffer) {
sun.misc.Cleaner cleaner =
((sun.nio.ch.DirectBuffer)buffer).cleaner();
cleaner.clean();
}
}
/** Linux only methods used for getOwner() implementation */
private static native long getUIDforFDOwnerforOwner(FileDescriptor fd) throws IOException;
private static native String getUserName(long uid) throws IOException;
/**
* Result type of the fstat call
*/
public static class Stat {
private int ownerId, groupId;
private String owner, group;
private int mode;
// Mode constants
public static final int S_IFMT = 0170000; /* type of file */
public static final int S_IFIFO = 0010000; /* named pipe (fifo) */
public static final int S_IFCHR = 0020000; /* character special */
public static final int S_IFDIR = 0040000; /* directory */
public static final int S_IFBLK = 0060000; /* block special */
public static final int S_IFREG = 0100000; /* regular */
public static final int S_IFLNK = 0120000; /* symbolic link */
public static final int S_IFSOCK = 0140000; /* socket */
public static final int S_IFWHT = 0160000; /* whiteout */
public static final int S_ISUID = 0004000; /* set user id on execution */
public static final int S_ISGID = 0002000; /* set group id on execution */
public static final int S_ISVTX = 0001000; /* save swapped text even after use */
public static final int S_IRUSR = 0000400; /* read permission, owner */
public static final int S_IWUSR = 0000200; /* write permission, owner */
public static final int S_IXUSR = 0000100; /* execute/search permission, owner */
Stat(int ownerId, int groupId, int mode) {
this.ownerId = ownerId;
this.groupId = groupId;
this.mode = mode;
}
Stat(String owner, String group, int mode) {
if (!Shell.WINDOWS) {
this.owner = owner;
} else {
this.owner = stripDomain(owner);
}
if (!Shell.WINDOWS) {
this.group = group;
} else {
this.group = stripDomain(group);
}
this.mode = mode;
}
@Override
public String toString() {
return "Stat(owner='" + owner + "', group='" + group + "'" +
", mode=" + mode + ")";
}
public String getOwner() {
return owner;
}
public String getGroup() {
return group;
}
public int getMode() {
return mode;
}
}
/**
* Returns the file stat for a file descriptor.
*
* @param fd file descriptor.
* @return the file descriptor file stat.
* @throws IOException thrown if there was an IO error while obtaining the file stat.
*/
public static Stat getFstat(FileDescriptor fd) throws IOException {
Stat stat = null;
if (!Shell.WINDOWS) {
stat = fstat(fd);
stat.owner = getName(IdCache.USER, stat.ownerId);
stat.group = getName(IdCache.GROUP, stat.groupId);
} else {
try {
stat = fstat(fd);
} catch (NativeIOException nioe) {
if (nioe.getErrorCode() == 6) {
throw new NativeIOException("The handle is invalid.",
Errno.EBADF);
} else {
LOG.warn(String.format("NativeIO.getFstat error (%d): %s",
nioe.getErrorCode(), nioe.getMessage()));
throw new NativeIOException("Unknown error", Errno.UNKNOWN);
}
}
}
return stat;
}
private static String getName(IdCache domain, int id) throws IOException {
Map idNameCache = (domain == IdCache.USER)
? USER_ID_NAME_CACHE : GROUP_ID_NAME_CACHE;
String name;
CachedName cachedName = idNameCache.get(id);
long now = System.currentTimeMillis();
if (cachedName != null && (cachedName.timestamp + cacheTimeout) > now) {
name = cachedName.name;
} else {
name = (domain == IdCache.USER) ? getUserName(id) : getGroupName(id);
if (LOG.isDebugEnabled()) {
String type = (domain == IdCache.USER) ? "UserName" : "GroupName";
LOG.debug("Got " + type + " " + name + " for ID " + id +
" from the native implementation");
}
cachedName = new CachedName(name, now);
idNameCache.put(id, cachedName);
}
return name;
}
static native String getUserName(int uid) throws IOException;
static native String getGroupName(int uid) throws IOException;
private static class CachedName {
final long timestamp;
final String name;
public CachedName(String name, long timestamp) {
this.name = name;
this.timestamp = timestamp;
}
}
private static final Map USER_ID_NAME_CACHE =
new ConcurrentHashMap();
private static final Map GROUP_ID_NAME_CACHE =
new ConcurrentHashMap();
private enum IdCache { USER, GROUP }
public final static int MMAP_PROT_READ = 0x1;
public final static int MMAP_PROT_WRITE = 0x2;
public final static int MMAP_PROT_EXEC = 0x4;
public static native long mmap(FileDescriptor fd, int prot,
boolean shared, long length) throws IOException;
public static native void munmap(long addr, long length)
throws IOException;
}
private static boolean workaroundNonThreadSafePasswdCalls = false;
public static class Windows {
// Flags for CreateFile() call on Windows
public static final long GENERIC_READ = 0x80000000L;
public static final long GENERIC_WRITE = 0x40000000L;
public static final long FILE_SHARE_READ = 0x00000001L;
public static final long FILE_SHARE_WRITE = 0x00000002L;
public static final long FILE_SHARE_DELETE = 0x00000004L;
public static final long CREATE_NEW = 1;
public static final long CREATE_ALWAYS = 2;
public static final long OPEN_EXISTING = 3;
public static final long OPEN_ALWAYS = 4;
public static final long TRUNCATE_EXISTING = 5;
public static final long FILE_BEGIN = 0;
public static final long FILE_CURRENT = 1;
public static final long FILE_END = 2;
public static final long FILE_ATTRIBUTE_NORMAL = 0x00000080L;
/**
* Create a directory with permissions set to the specified mode. By setting
* permissions at creation time, we avoid issues related to the user lacking
* WRITE_DAC rights on subsequent chmod calls. One example where this can
* occur is writing to an SMB share where the user does not have Full Control
* rights, and therefore WRITE_DAC is denied.
*
* @param path directory to create
* @param mode permissions of new directory
* @throws IOException if there is an I/O error
*/
public static void createDirectoryWithMode(File path, int mode)
throws IOException {
createDirectoryWithMode0(path.getAbsolutePath(), mode);
}
/** Wrapper around CreateDirectory() on Windows */
private static native void createDirectoryWithMode0(String path, int mode)
throws NativeIOException;
/** Wrapper around CreateFile() on Windows */
public static native FileDescriptor createFile(String path,
long desiredAccess, long shareMode, long creationDisposition)
throws IOException;
/**
* Create a file for write with permissions set to the specified mode. By
* setting permissions at creation time, we avoid issues related to the user
* lacking WRITE_DAC rights on subsequent chmod calls. One example where
* this can occur is writing to an SMB share where the user does not have
* Full Control rights, and therefore WRITE_DAC is denied.
*
* This method mimics the semantics implemented by the JDK in
* {@link java.io.FileOutputStream}. The file is opened for truncate or
* append, the sharing mode allows other readers and writers, and paths
* longer than MAX_PATH are supported. (See io_util_md.c in the JDK.)
*
* @param path file to create
* @param append if true, then open file for append
* @param mode permissions of new directory
* @return FileOutputStream of opened file
* @throws IOException if there is an I/O error
*/
public static FileOutputStream createFileOutputStreamWithMode(File path,
boolean append, int mode) throws IOException {
long desiredAccess = GENERIC_WRITE;
long shareMode = FILE_SHARE_READ | FILE_SHARE_WRITE;
long creationDisposition = append ? OPEN_ALWAYS : CREATE_ALWAYS;
return new FileOutputStream(createFileWithMode0(path.getAbsolutePath(),
desiredAccess, shareMode, creationDisposition, mode));
}
/** Wrapper around CreateFile() with security descriptor on Windows */
private static native FileDescriptor createFileWithMode0(String path,
long desiredAccess, long shareMode, long creationDisposition, int mode)
throws NativeIOException;
/** Wrapper around SetFilePointer() on Windows */
public static native long setFilePointer(FileDescriptor fd,
long distanceToMove, long moveMethod) throws IOException;
/** Windows only methods used for getOwner() implementation */
private static native String getOwner(FileDescriptor fd) throws IOException;
/** Supported list of Windows access right flags */
public static enum AccessRight {
ACCESS_READ (0x0001), // FILE_READ_DATA
ACCESS_WRITE (0x0002), // FILE_WRITE_DATA
ACCESS_EXECUTE (0x0020); // FILE_EXECUTE
private final int accessRight;
AccessRight(int access) {
accessRight = access;
}
public int accessRight() {
return accessRight;
}
};
/** Windows only method used to check if the current process has requested
* access rights on the given path. */
private static native boolean access0(String path, int requestedAccess);
/**
* Checks whether the current process has desired access rights on
* the given path.
*
* Longer term this native function can be substituted with JDK7
* function Files#isReadable, isWritable, isExecutable.
*
* @param path input path
* @param desiredAccess ACCESS_READ, ACCESS_WRITE or ACCESS_EXECUTE
* @return true if access is allowed
* @throws IOException I/O exception on error
*/
public static boolean access(String path, AccessRight desiredAccess)
throws IOException {
return true;
// return access0(path, desiredAccess.accessRight());
}
/**
* Extends both the minimum and maximum working set size of the current
* process. This method gets the current minimum and maximum working set
* size, adds the requested amount to each and then sets the minimum and
* maximum working set size to the new values. Controlling the working set
* size of the process also controls the amount of memory it can lock.
*
* @param delta amount to increment minimum and maximum working set size
* @throws IOException for any error
* @see POSIX#mlock(ByteBuffer, long)
*/
public static native void extendWorkingSetSize(long delta) throws IOException;
static {
if (NativeCodeLoader.isNativeCodeLoaded()) {
try {
initNative();
nativeLoaded = true;
} catch (Throwable t) {
// This can happen if the user has an older version of libhadoop.so
// installed - in this case we can continue without native IO
// after warning
PerformanceAdvisory.LOG.debug("Unable to initialize NativeIO libraries", t);
}
}
}
}
private static final Log LOG = LogFactory.getLog(NativeIO.class);
private static boolean nativeLoaded = false;
static {
if (NativeCodeLoader.isNativeCodeLoaded()) {
try {
initNative();
nativeLoaded = true;
} catch (Throwable t) {
// This can happen if the user has an older version of libhadoop.so
// installed - in this case we can continue without native IO
// after warning
PerformanceAdvisory.LOG.debug("Unable to initialize NativeIO libraries", t);
}
}
}
/**
* Return true if the JNI-based native IO extensions are available.
*/
public static boolean isAvailable() {
return NativeCodeLoader.isNativeCodeLoaded() && nativeLoaded;
}
/** Initialize the JNI method ID and class ID cache */
private static native void initNative();
/**
* Get the maximum number of bytes that can be locked into memory at any
* given point.
*
* @return 0 if no bytes can be locked into memory;
* Long.MAX_VALUE if there is no limit;
* The number of bytes that can be locked into memory otherwise.
*/
static long getMemlockLimit() {
return isAvailable() ? getMemlockLimit0() : 0;
}
private static native long getMemlockLimit0();
/**
* @return the operating system's page size.
*/
static long getOperatingSystemPageSize() {
try {
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
Unsafe unsafe = (Unsafe)f.get(null);
return unsafe.pageSize();
} catch (Throwable e) {
LOG.warn("Unable to get operating system page size. Guessing 4096.", e);
return 4096;
}
}
private static class CachedUid {
final long timestamp;
final String username;
public CachedUid(String username, long timestamp) {
this.timestamp = timestamp;
this.username = username;
}
}
private static final Map uidCache =
new ConcurrentHashMap();
private static long cacheTimeout;
private static boolean initialized = false;
/**
* The Windows logon name has two part, NetBIOS domain name and
* user account name, of the format DOMAIN\UserName. This method
* will remove the domain part of the full logon name.
*
* @param Fthe full principal name containing the domain
* @return name with domain removed
*/
private static String stripDomain(String name) {
int i = name.indexOf('\\');
if (i != -1)
name = name.substring(i + 1);
return name;
}
public static String getOwner(FileDescriptor fd) throws IOException {
ensureInitialized();
if (Shell.WINDOWS) {
String owner = Windows.getOwner(fd);
owner = stripDomain(owner);
return owner;
} else {
long uid = POSIX.getUIDforFDOwnerforOwner(fd);
CachedUid cUid = uidCache.get(uid);
long now = System.currentTimeMillis();
if (cUid != null && (cUid.timestamp + cacheTimeout) > now) {
return cUid.username;
}
String user = POSIX.getUserName(uid);
LOG.info("Got UserName " + user + " for UID " + uid
+ " from the native implementation");
cUid = new CachedUid(user, now);
uidCache.put(uid, cUid);
return user;
}
}
/**
* Create a FileInputStream that shares delete permission on the
* file opened, i.e. other process can delete the file the
* FileInputStream is reading. Only Windows implementation uses
* the native interface.
*/
public static FileInputStream getShareDeleteFileInputStream(File f)
throws IOException {
if (!Shell.WINDOWS) {
// On Linux the default FileInputStream shares delete permission
// on the file opened.
//
return new FileInputStream(f);
} else {
// Use Windows native interface to create a FileInputStream that
// shares delete permission on the file opened.
//
FileDescriptor fd = Windows.createFile(
f.getAbsolutePath(),
Windows.GENERIC_READ,
Windows.FILE_SHARE_READ |
Windows.FILE_SHARE_WRITE |
Windows.FILE_SHARE_DELETE,
Windows.OPEN_EXISTING);
return new FileInputStream(fd);
}
}
/**
* Create a FileInputStream that shares delete permission on the
* file opened at a given offset, i.e. other process can delete
* the file the FileInputStream is reading. Only Windows implementation
* uses the native interface.
*/
public static FileInputStream getShareDeleteFileInputStream(File f, long seekOffset)
throws IOException {
if (!Shell.WINDOWS) {
RandomAccessFile rf = new RandomAccessFile(f, "r");
if (seekOffset > 0) {
rf.seek(seekOffset);
}
return new FileInputStream(rf.getFD());
} else {
// Use Windows native interface to create a FileInputStream that
// shares delete permission on the file opened, and set it to the
// given offset.
//
FileDescriptor fd = NativeIO.Windows.createFile(
f.getAbsolutePath(),
NativeIO.Windows.GENERIC_READ,
NativeIO.Windows.FILE_SHARE_READ |
NativeIO.Windows.FILE_SHARE_WRITE |
NativeIO.Windows.FILE_SHARE_DELETE,
NativeIO.Windows.OPEN_EXISTING);
if (seekOffset > 0)
NativeIO.Windows.setFilePointer(fd, seekOffset, NativeIO.Windows.FILE_BEGIN);
return new FileInputStream(fd);
}
}
/**
* Create the specified File for write access, ensuring that it does not exist.
* @param f the file that we want to create
* @param permissions we want to have on the file (if security is enabled)
*
* @throws AlreadyExistsException if the file already exists
* @throws IOException if any other error occurred
*/
public static FileOutputStream getCreateForWriteFileOutputStream(File f, int permissions)
throws IOException {
if (!Shell.WINDOWS) {
// Use the native wrapper around open(2)
try {
FileDescriptor fd = NativeIO.POSIX.open(f.getAbsolutePath(),
NativeIO.POSIX.O_WRONLY | NativeIO.POSIX.O_CREAT
| NativeIO.POSIX.O_EXCL, permissions);
return new FileOutputStream(fd);
} catch (NativeIOException nioe) {
if (nioe.getErrno() == Errno.EEXIST) {
throw new AlreadyExistsException(nioe);
}
throw nioe;
}
} else {
// Use the Windows native APIs to create equivalent FileOutputStream
try {
FileDescriptor fd = NativeIO.Windows.createFile(f.getCanonicalPath(),
NativeIO.Windows.GENERIC_WRITE,
NativeIO.Windows.FILE_SHARE_DELETE
| NativeIO.Windows.FILE_SHARE_READ
| NativeIO.Windows.FILE_SHARE_WRITE,
NativeIO.Windows.CREATE_NEW);
NativeIO.POSIX.chmod(f.getCanonicalPath(), permissions);
return new FileOutputStream(fd);
} catch (NativeIOException nioe) {
if (nioe.getErrorCode() == 80) {
// ERROR_FILE_EXISTS
// 80 (0x50)
// The file exists
throw new AlreadyExistsException(nioe);
}
throw nioe;
}
}
}
private synchronized static void ensureInitialized() {
if (!initialized) {
cacheTimeout =
new Configuration().getLong("hadoop.security.uid.cache.secs",
4*60*60) * 1000;
LOG.info("Initialized cache for UID to User mapping with a cache" +
" timeout of " + cacheTimeout/1000 + " seconds.");
initialized = true;
}
}
/**
* A version of renameTo that throws a descriptive exception when it fails.
*
* @param src The source path
* @param dst The destination path
*
* @throws NativeIOException On failure.
*/
public static void renameTo(File src, File dst)
throws IOException {
if (!nativeLoaded) {
if (!src.renameTo(dst)) {
throw new IOException("renameTo(src=" + src + ", dst=" +
dst + ") failed.");
}
} else {
renameTo0(src.getAbsolutePath(), dst.getAbsolutePath());
}
}
public static void link(File src, File dst) throws IOException {
if (!nativeLoaded) {
HardLink.createHardLink(src, dst);
} else {
link0(src.getAbsolutePath(), dst.getAbsolutePath());
}
}
/**
* A version of renameTo that throws a descriptive exception when it fails.
*
* @param src The source path
* @param dst The destination path
*
* @throws NativeIOException On failure.
*/
private static native void renameTo0(String src, String dst)
throws NativeIOException;
private static native void link0(String src, String dst)
throws NativeIOException;
/**
* Unbuffered file copy from src to dst without tainting OS buffer cache
*
* In POSIX platform:
* It uses FileChannel#transferTo() which internally attempts
* unbuffered IO on OS with native sendfile64() support and falls back to
* buffered IO otherwise.
*
* It minimizes the number of FileChannel#transferTo call by passing the the
* src file size directly instead of a smaller size as the 3rd parameter.
* This saves the number of sendfile64() system call when native sendfile64()
* is supported. In the two fall back cases where sendfile is not supported,
* FileChannle#transferTo already has its own batching of size 8 MB and 8 KB,
* respectively.
*
* In Windows Platform:
* It uses its own native wrapper of CopyFileEx with COPY_FILE_NO_BUFFERING
* flag, which is supported on Windows Server 2008 and above.
*
* Ideally, we should use FileChannel#transferTo() across both POSIX and Windows
* platform. Unfortunately, the wrapper(Java_sun_nio_ch_FileChannelImpl_transferTo0)
* used by FileChannel#transferTo for unbuffered IO is not implemented on Windows.
* Based on OpenJDK 6/7/8 source code, Java_sun_nio_ch_FileChannelImpl_transferTo0
* on Windows simply returns IOS_UNSUPPORTED.
*
* Note: This simple native wrapper does minimal parameter checking before copy and
* consistency check (e.g., size) after copy.
* It is recommended to use wrapper function like
* the Storage#nativeCopyFileUnbuffered() function in hadoop-hdfs with pre/post copy
* checks.
*
* @param src The source path
* @param dst The destination path
* @throws IOException
*/
public static void copyFileUnbuffered(File src, File dst) throws IOException {
if (nativeLoaded && Shell.WINDOWS) {
copyFileUnbuffered0(src.getAbsolutePath(), dst.getAbsolutePath());
} else {
FileInputStream fis = null;
FileOutputStream fos = null;
FileChannel input = null;
FileChannel output = null;
try {
fis = new FileInputStream(src);
fos = new FileOutputStream(dst);
input = fis.getChannel();
output = fos.getChannel();
long remaining = input.size();
long position = 0;
long transferred = 0;
while (remaining > 0) {
transferred = input.transferTo(position, remaining, output);
remaining -= transferred;
position += transferred;
}
} finally {
IOUtils.cleanup(LOG, output);
IOUtils.cleanup(LOG, fos);
IOUtils.cleanup(LOG, input);
IOUtils.cleanup(LOG, fis);
}
}
}
private static native void copyFileUnbuffered0(String src, String dst)
throws NativeIOException;
}
然后应该就可以了
将程序放到hadoop集群运行
1.打包插件
org.apache.maven.plugins
maven-jar-plugin
com.roadom.WordcountDriver
1.打jar包

2.将jar包(不包括hadoop lib)上传到hadoop集群
D:\hadoopmr\out\artifacts\hadoopmr_jar\hadoopmr.jar
3.执行命令运行mr作业
./hadoop jar hadoopmr.jar com.neusoft.WordCount /wc.input /out42
可能遇到的问题
hadoop.dll 和 winutils.exe 添加到hadoop解压目录
如果双击winutils.exe弹出错误,需要安装
DirectX_Repair_3.7_Enhanced_XiaZaiBa.zip
更新电脑的dll
MapReduce优化之Combiner
https://blog.csdn.net/qq_38262266/article/details/79185631