1. 为何使用特征选择?
特征选择背后的概念:
事情应该力求简单,不过不能过于简单
需要寻求尽量少的特征,但是却能真正把握数据的趋势和模式
你的机器学习算法的上限,就是你放入的特征
- 你应该有在可选选项中找到最佳特征的方法
也就是抛弃对你不是有真正帮助的东西 - 可能你的数据中有些模式很有用,所以你可以通过人类的直觉对新加入的特征感知模式
2. 一个新的安然特征
向安然数据集加入新特征
在编写新特征时,遵循以下原则:
- 利用人的直觉
你认为什么特征可能包含一些利用机器学习算法的模式
比如我对安然数据集有这样的直觉:
嫌疑人间相互发邮件的频率很高
编写新特征
可视化
可视化结果会让你知道你的进展方向是否正确,你的新特征是否会帮助你鉴别我们想要解决的分类问题重复
如果你想要找到对你最有用的新特征是什么,经常要多次重复这个过程
3. 练习:一个新的安然特征练习
从每条消息中提取消息的作者,对比这个作者的邮件地址以及已知嫌疑人的邮件地址清单,返回布尔值
4. 可视化新特征

给出:
- from this person to poi (number of emails)
- from poi to this person (number of emails)
- from messages (number of emails)
- to messages (number of emails)
返回: - fraction to this person from poi
- fraction from this person to poi
def computeFraction( poi_messages, all_messages ):
""" given a number messages to/from POI (numerator)
and number of all messages to/from a person (denominator),
return the fraction of messages to/from that person
that are from/to a POI
"""
### you fill in this code, so that it returns either
### the fraction of all messages to this person that come from POIs
### or
### the fraction of all messages from this person that are sent to POIs
### the same code can be used to compute either quantity
### beware of "NaN" when there is no known email address (and so
### no filled email features), and integer division!
### in case of poi_messages or all_messages having "NaN" value, return 0.
if poi_messages =='NaN' or all_messages =='NaN':
fraction = 0.
else:
fraction = float(poi_messages)/float(all_messages)
return fraction
5. 警惕特征漏洞!
添加新特征时,be aware of bugs!
6. 示例:有漏洞的特征
Katie 在处理安然 POI 识别符时,设计了一个特征,用来对既定人员以 POI 身份出现在相同的邮件中时进行识别。 举一个例子,如果 Ken Lay 和 Katie Malone 是同一封邮件的接收人,那么 Katie Malone 的“shared receipt”特征就应该得到递增。 如果她与 POI 共享很多邮件,那么她自己很可能就是一个 POI。
这里有一个小漏洞,即当这种情况发生时,Ken Lay 的“shared receipt”计数器也应该得到递增。 当然,Ken Lay 总是与 POI 共享收据,因为他就是 POI。 因此,“shared receipt”特征在查找 POI 方面就变得异常强大,因为它将每个人的标签有效编成了一个特征。
我们最初发现这一点,是因为我们对总是返回 100% 准确率的一个分类器感到怀疑。于是,我们每次删除一个特征,然后就发现了这一特征是所有这一切的根源。 我们在回顾特征代码时发现了以上提到的漏洞。 我们更改了代码,以便仅当不同的 POI 收到邮件时,该既定人员的“shared receipt”特征才会得到递增,重新运行代码,然后再次尝试。准确率落到了更为合理的水平。
我们从这个例子中认识到:
任何人都有可能犯错—要对你得到的结果持怀疑态度!
你应该时刻警惕 100% 准确率。不寻常的主张要有不寻常的证据来支持。
如果有特征过度追踪你的标签,那么它很可能就是一个漏洞!
如果你确定它不是漏洞,那么你很大程度上就不需要机器学习了——你可以只用该特征来分配标签。
7. 去除特征
删除你不想要的特征
原因在于:
- 特征太杂乱了,很难分辨它是否能可靠地帮助你测量你想测量的东西
- 由于某种原因,特征可能会导致你的模型过度拟合
- 这个特征与当前已存在的特征密切关联,高度相关,它只是在不停地向你提供重复的信息,是当前其他特征也有提供的信息
- 新特征可能会拖慢训练/测试过程,为了让所有的东西都快速运转,只保留最低的必要的特征数量,以便达到最好的效果
8. 特征不等于信息
我们想要从数据中得到的是信息,想要得到结论,形成见解,这和数据中拥有大量特征是不一样的
特征只是特定的试图获取信息的数据点的实际数量或者特点,它和信息本身是不同的
如果你有大量的特征,你可能有大量的数据,而特征的质量就是信息的内容
总的来说,我们需要的是能带给你尽量多信息的数量尽可能少的特征,如果你认为特征没有给予你信息,就要删除它,因为它可能引起问题
9. 单变量特征选择
在 sklearn 中自动选择特征有多种辅助方法。多数方法都属于单变量特征选择的范畴,即独立对待每个特征并询问其在分类或回归中的能力。
sklearn 中有两大单变量特征选择工具:SelectPercentile 和 SelectKBest。 两者之间的区别从名字就可以看出:SelectPercentile 选择最强大的 X% 特征(X 是参数),而 SelectKBest 选择 K 个最强大的特征(K 是参数)。
由于数据维度太高,特征约简显然要用到文本学习。 实际上,在最初的几个迷你项目中,我们就已经在 Sara/Chris 邮件分类的问题上进行了特征选择;你可以在 tools/email_preprocess.py 的代码中看到它。
10. TfIdf 向量器中的特征选择
import pickle
import cPickle
import numpy
from sklearn import cross_validation
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_selection import SelectPercentile, f_classif
def preprocess(words_file = "../tools/word_data.pkl", authors_file="../tools/email_authors.pkl"):
"""
this function takes a pre-made list of email texts (by default word_data.pkl)
and the corresponding authors (by default email_authors.pkl) and performs
a number of preprocessing steps:
-- splits into training/testing sets (10% testing)
-- vectorizes into tfidf matrix
-- selects/keeps most helpful features
after this, the feaures and labels are put into numpy arrays, which play nice with sklearn functions
4 objects are returned:
-- training/testing features
-- training/testing labels
"""
### the words (features) and authors (labels), already largely preprocessed
### this preprocessing will be repeated in the text learning mini-project
authors_file_handler = open(authors_file, "r")
authors = pickle.load(authors_file_handler)
authors_file_handler.close()
words_file_handler = open(words_file, "r")
word_data = cPickle.load(words_file_handler)
words_file_handler.close()
### test_size is the percentage of events assigned to the test set
### (remainder go into training)
features_train, features_test, labels_train, labels_test = cross_validation.train_test_split(word_data, authors, test_size=0.1, random_state=42)
### text vectorization--go from strings to lists of numbers
vectorizer = TfidfVectorizer(sublinear_tf=True, max_df=0.5,
stop_words='english')
features_train_transformed = vectorizer.fit_transform(features_train)
features_test_transformed = vectorizer.transform(features_test)
### feature selection, because text is super high dimensional and
### can be really computationally chewy as a result
selector = SelectPercentile(f_classif, percentile=10)
selector.fit(features_train_transformed, labels_train)
features_train_transformed = selector.transform(features_train_transformed).toarray()
features_test_transformed = selector.transform(features_test_transformed).toarray()
### info on the data
print "no. of Chris training emails:", sum(labels_train)
print "no. of Sara training emails:", len(labels_train)-sum(labels_train)
return features_train_transformed, features_test_transformed, labels_train, labels_test
vectorizer = TfidfVectorizer(sublinear_tf=True, max_df=0.5,
stop_words='english')
如果一个特征出现得非常频繁,即几乎出现在每一个文件中,那么TfidfVectorizer的max_df参数会删除这个特征
而这个参数无视某个单词的门槛是什么呢?如果max_df,那么当它出现在50%的文件中时会被删除
max_df参数会实际缩小词汇表的大小,它会根据含有某个特定单词的文件数量来执行,所以max_df=0.5代表如果单词出现在超过50%的文件中,那么就在Tfidf中不使用它 ,因为它可能不含有太多的信息,太普遍了,因此这里是你可以进行特征缩减/维数缩减的一个地方
这里再次强盗特征≠信息,你可能删除了文本90%的特征,但这可能对你分类器的精确度没有什么影响,而事实上由于特征数量更少,它能运行得更快,效果更好,尤其是处理很高维数的数据时,数据中有大量特征,你需要对这些特征保持怀疑态度,思考哪些特征能真正帮助你实现分类
11. 偏差、方差和特征数量
本节讲解你在算法中使用的特征个数和偏差-方差困境有何关系
高偏差算法
-1 对训练数据关心很少
-2 是一种过度简化,只是一次又一次地重复同样的事情,而不管数据可能尝试告诉算法要做什么
-3 在训练集上有很高的误差,例如进行回归时,意味着很低的R或较大的残差平方和高方差算法
-1 对数据关心太多
-2 不会很好地推广至以前从未见过的情况,基本上只是记住了训练示例而已,一旦获得新的示例或者新的数据点,和原有的训练示例不完全一致的时候,就不知道如何去做了
-3 会过度拟合数据
-4 可能对于训练集有很好的拟合度,但对于测试数据却拟合不佳,因为它不能很好地推广,一旦你给它新的输入,立刻就会出现问题
-5 你通常期望在训练集上做得比测试集上更好一些,但高方差意味着你在训练机上好太多,高方差是当你对训练数据过度拟合后,在测试集上的性能就很差
问题:
你有一个算法只是使用其中的一些特征,即较少的特征使用倾向于导致高偏差算法。
非常典型的情况是你可能需要几个特征来完整描述数据中的所有模式,但你只使用了其中的1-2个,这回让你处于高偏差状态
12. 偏差、方差和特征数量 2
假如你有一个模型,你非常小心地调整了模型参数,最小化了回归的误差平方和
加入你为了最小化误差平方和,小心地调节参数,同时运用大量特征,这时你可能会陷入高方差困境
如果你使用很多特征来获得拟合程度最好的回归/分类器,这就是一个经典的高方差情形
最终我们需要的是:
使用较少的几个特征来拟合算法,但同时,就回归而言,希望得到较大的R²,或者很低的残余误差平方和,这就是你需要寻找的最佳平衡点
13. 肉眼过拟合
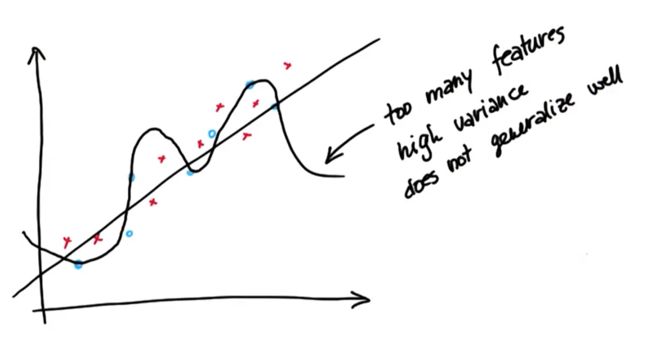
过拟合给回归造成的影响
过拟合效果很差的原因
过拟合在训练集中表现得很好,但在测试集中表现很差,方差很高,泛化效果不好
14. 带有特征数量的平衡误差
我们想要平衡(回归误差)和(得到误差所需的特征数量)
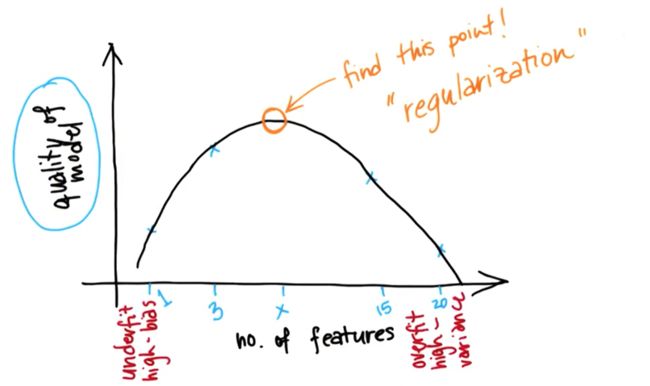
正则化是一种自动形式的特征选择
15. 正则化
regularization in regression
method for automatically penalizing extra features
能非常有效地采用正则化的地方就是回归
正则化回归--lasso regression
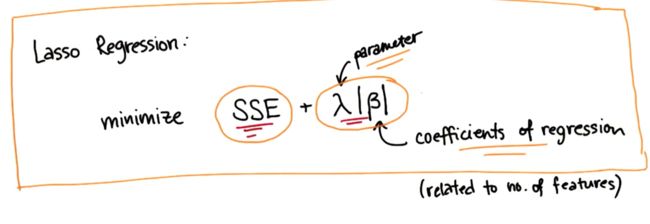
一般的回归是要最小化误差平方和
但是lasso regression在最小化误差平方和的同时,还要最小化使用的特征数量
β描述的就是使用的特征数量
这个公式精确地规定了更少的误差和使用更少特征数量更简单的拟合之间的平衡
所以lasso regression自动考虑惩罚参数,这样它就能帮你指出哪些特征对你的回归有最重要的影响,在发现这些特征后,它就能减少或删除用处不大的特征的系数
16.lasso regression
regularization in regression
method for automatically penalizing extra features
can set coefficient to a feature to zero

17. lasso regression练习
import sklearn.linear_model.Lasso
features,labels = GetMyData()
regression = Lasso()
regression.fit(features,labels)
回归是一种监督算法,需要特征和标签,因此在创建拟合时,应该把两个参数都传递给拟合指令,否则它不知道如何得到答案
18. 使用 Sklearn 进行lasso预测练习
from sklearn import linear_model
features,labels = linear_model.GetMyData()
regression = Lasso()
regression.fit(features,labels)
regression.predict([2,4]) #predict a label for a new point
19. Sklearn 中的套索系数练习
查看回归的系数
import sklearn.linear_model.Lasso
features,labels = GetMyData()
regression = Lasso()
regression.fit(features,labels)
regression.predict([2,4])
print regression.coef_ #将返回回归找到的所有系数的列表
print regression.coef_将返回回归找到的所有系数的列表,在这个列表中,哪个特征的系数最大,就表明该特征是重要的特征
20. 在sklearn中使用lasso练习
if print regression.coef_returns [0.7,0.0], how many features really matter?
1
22. 特征选择迷你项目
Katie 在视频中解释了她在为“作者识别”项目准备 Chris 和 Sara 的邮件时遇到的一个问题, 即一个特征过于强大(就像签名一样,可以说给了算法一个有失公平的优势)。你将在此亲自探究这一发现。
23. 过拟合决策树 1
此漏洞是在 Katie 试图为决策树迷你项目创建过拟合决策树的示例时发现的。 决策树作为传统算法非常容易过拟合,获得过拟合决策树最简单的一种方式就是使用小型训练集和大量特征。
If a decision tree is overfit,would you expect the accuracy on a test set to be very high or pretty low?
low
24. 过拟合决策树 2
If a decision tree is overfit,would you expect high or low accuracy on the training set ?
high
25. 特征数量和过拟合
过拟合算法的一种传统方式是使用大量特征和少量训练数据。你可以在 feature_selection/find_signature.py 中找到初始代码。准备好决策树,开始在训练数据上进行训练,打印出准确率。
根据初始代码,有多少训练点?
#!/usr/bin/python
import pickle
import numpy
numpy.random.seed(42)
words_file = "../text_learning/your_word_data.pkl"
authors_file = "../text_learning/your_email_authors.pkl"
word_data = pickle.load( open(words_file, "r"))
authors = pickle.load( open(authors_file, "r") )
from sklearn import cross_validation
features_train, features_test, labels_train, labels_test = cross_validation.train_test_split(word_data, authors, test_size=0.1, random_state=42)
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(sublinear_tf=True, max_df=0.5,
stop_words='english')
features_train = vectorizer.fit_transform(features_train)
features_test = vectorizer.transform(features_test).toarray()
features_train = features_train[:150].toarray()
labels_train = labels_train[:150]
### your code goes here
print len(features_train) #150
特别说明:根据你何时下载 find_signature.py 代码,你可能需要将第 9 至 10 行的代码更改为
words_file = "../text_learning/your_word_data.pkl" authors_file = "../text_learning/your_email_authors.pkl"
这样一来,通过运行 vectorize_text.py 创建而来的文件就可以得到适当的体现了。
另外,如果你由于内存问题而无法运行代码,而且如果你的 scikit-learn 版本是 0.16.x, 你可以从 features_train 被创建出来的行中删除 .toarray() 函数, 以节省内存——该版本中的决策树分类器可以将稀疏数组而非仅仅是密集数组作为输入。
26. 过拟合决策树的准确率
你刚才创建的决策树的准确率是多少?
(记住,我们设置决策树用于过拟合——理想情况下,我们希望看到的是相对较低的测试准确率。)
from sklearn import tree
from sklearn.metrics import accuracy_score
clf = tree.DecisionTreeClassifier()
clf.fit(features_train,labels_train)
pred = clf.predict(features_test)
acc = accuracy_score(pred,labels_test)
print acc #0.947667804323
27. 识别最强大特征
选择(过拟合)决策树并使用 feature_importances_ 属性来获得一个列表, 其中列出了所有用到的特征的相对重要性(由于是文本数据,因此列表会很长)。 我们建议迭代此列表并且仅在超过阈值(比如 0.2——记住,所有单词都同等重要,每个单词的重要性都低于 0.01)的情况下将特征重要性打印出来。
最重要特征的重要性是什么?该特征的数字是多少?
what's the importance of the most important feature?what's the number of this feature?
最重要特征的重要性是什么?特征数是多少?
特别说明:根据你何时下载 find_signature.py 代码,你可能需要将第 9 至 10 行的代码更改为
words_file = "../text_learning/your_word_data.pkl" authors_file = "../text_learning/your_email_authors.pkl"
这样一来,通过运行 vectorize_text.py 创建而来的文件就可以得到适当的体现了。
imp = clf.feature_importances_
print max(imp) #0.764705882353
print imp.argmax() #33614
方法二:
imp = clf.feature_importances_
for index,feature in enumerate(imp):
if feature >0.2:
print index,feature
28. 使用 TfIdf 获得最重要的单词
为了确定是什么单词导致了问题的发生,你需要返回至 TfIdf,使用你从迷你项目的上一部分中获得的特征数量来获取关联词。 你可以在 TfIdf 中调用 get_feature_names() 来返回包含所有单词的列表; 抽出造成大多数决策树歧视的单词。
这个单词是什么?类似于签名这种与 Chris Germany 或 Sara Shackleton 唯一关联的单词是否讲得通?
what's the most powerful word when your decision tree is making its classification decisions?
当你的决策树进行分类决策时,最强大的词是什么?
请确保你修改 find_signature.py 以获得最有影响力的单词。
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(sublinear_tf=True, max_df=0.5,
stop_words='english')
features_train = vectorizer.fit_transform(features_train)
features_test = vectorizer.transform(features_test).toarray()
words_bag = vectorizer.get_feature_names()
print words_bag[33614] #sshacklensf
29. 删除、重复
从某种意义上说,这一单词sshacklensf看起来像是一个异常值,所以让我们在删除它之后重新拟合。 返回至 text_learning/vectorize_text.py,使用我们删除“sara”、“chris”等的方法,从邮件中删除此单词。 重新运行 vectorize_text.py,完成以后立即重新运行 find_signature.py。
words = words.replace("sara",'').replace("shackleton",'').replace("chris",'')\
.replace("germani",'').replace("sshacklensf",'')
from sklearn import tree
from sklearn.metrics import accuracy_score
clf = tree.DecisionTreeClassifier()
clf.fit(features_train,labels_train)
pred = clf.predict(features_test)
acc = accuracy_score(pred,labels_test)
imp = clf.feature_importances_
for index,feature in enumerate(imp):
if feature >0.2:
print index,feature #14343 0.666666666667
有跳出其他任何的异常值吗?是什么单词?像是一个签名类型的单词?(跟之前一样,将异常值定义为重要性大于 0.2 的特征)。
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(sublinear_tf=True, max_df=0.5,
stop_words='english')
features_train = vectorizer.fit_transform(features_train)
features_test = vectorizer.transform(features_test).toarray()
words_bag = vectorizer.get_feature_names()
print words_bag[14343] #cgermannsf
特别说明:根据你何时下载 find_signature.py 代码,你可能需要将第 9 至 10 行的代码更改为
words_file = "../text_learning/your_word_data.pkl" authors_file = "../text_learning/your_email_authors.pkl"
这样一来,通过运行 vectorize_text.py 创建而来的文件就可以得到适当的体现了。
30. 再次检查重要特征
再次更新 vectorize_test.py 后重新运行。然后,再次运行 find_signature.py。
是否出现其他任何的重要特征(重要性大于 0.2)?有多少?它们看起来像“签名文字”,还是更像来自邮件正文的“邮件内容文字”?
当你消除了特征词并重新处理电子邮件,是否出现了任何新的“重要特征”(重要性> 0.2)?会有多少? 是,还有一个新的重要词 是,还有 4 个重要词 是,还有很多重要词 否,我们已消除了所有重要性 > 0.2 的词
words = words.replace("sara",'').replace("shackleton",'').replace("chris",'')\
.replace("germani",'').replace("sshacklensf",'').replace("cgermannsf",'')
from sklearn import tree
from sklearn.metrics import accuracy_score
clf = tree.DecisionTreeClassifier()
clf.fit(features_train,labels_train)
pred = clf.predict(features_test)
acc = accuracy_score(pred,labels_test) #0.816837315131
imp_list=[]
imp = clf.feature_importances_
for index,feature in enumerate(imp):
if feature >0.2:
imp_list.append(feature)
print index,feature #21323 0.363636363636
print len(imp_list) #1
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(sublinear_tf=True, max_df=0.5,
stop_words='english')
words_bag = vectorizer.get_feature_names()
print words_bag[21323] #houectect
once you have removed the signature words and reprocess the emails,do any new "important features"(importance>0.2) arise?how many?
yes,there is one new important word
31. 过拟合树的准确率
现在决策树的准确率是多少?
我们已经移除了两个“签名词语”,所以要让我们的算法拟合训练集,同时不出现过拟合更为困难。 记住,我们这里是想要知道我们是否会让算法过拟合,准确率如何并不是关键!
你的过拟合决策树现在的准确度是多少?
0.816837315131