本文主要用于介绍谷歌实验室团队于2017年提出的一种轻型网络MobileNets。本笔记主要为方便初学者快速入门,以及自我回顾。
论文链接:https://arxiv.org/pdf/1704.04861.pdf
基本目录如下:
- 摘要
- 核心思想
- 总结
------------------第一菇 - 摘要------------------
1.1 论文摘要
我们提出了一种高效的专门可用于手机端或其他终端视觉设备的网络,称为MobileNets。该网络利用多个连续的深度可分离卷积模块(depthwise separable convolutions)来构造轻型的深度神经网络。我们还同时介绍了2个简单的全局超参数用来有效提高时效性和准确性。这些超参数能够帮助从业人员在真实场景的条件约束下构造出合适大小的模型。我们利用该网络做了大量的实验来证明其有效性,并且除了图像分类,该网络还能够运用于其他的一些基础图像信息识别任务,比如目标检测,脸部关键点检测等等。
------------------第二菇 - 核心思想------------------
2.1 介绍
本文主要是提出了一种轻型的网络架构,使得其能够在损失一点准确率的情况下,能大大提高时效性,从而能够应用于手机端或其他终端设备比如机器人啊之类的~这里贴一张原文中的图,用以说明在手机端部署神经网络的应用场景(主要是觉得这张图画的好看,我才贴上来哈哈),
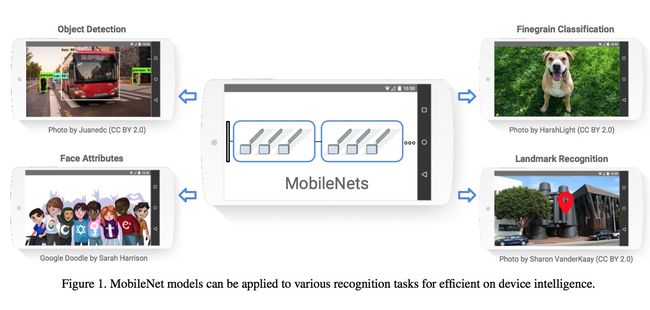
接下来我们就看一下具体的网络架构。
2.2 模型架构理解
2.2.1 Depthwise Separable Convolution
整套MobileNets的基础就是深度可分离卷积(depthwise separable convolutions),其本质就是由depthwise convolution和pointwise convolution两部分组成的。这两部分合起来,起到一个传统卷积操作的目的,但是参数量却减少了。因此,我们先理一下传统的卷积操作都干了哪些事情。
2.2.1.1 传统卷积操作
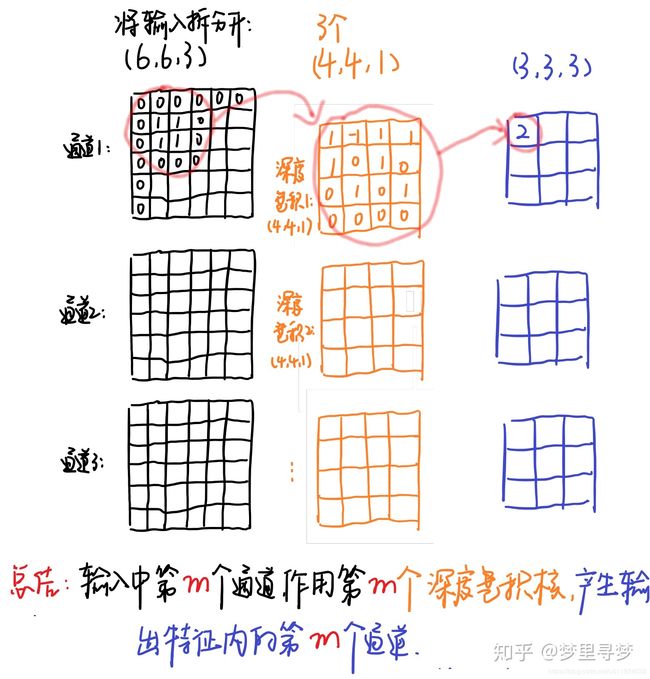
关于卷积的具体定义,就不阐述了,看看知乎上各路大神的阐述即可。这里贴一张最经典的理解卷积的操作的图片。

我们首先假设输入是,对应到上图就是,5为长宽,3为通道数。然后我们对应用了N个卷积核(上图为2),每一个卷积核的大小都是,对应上图就为(注:一般情况下卷积核的深度与输入图像的深度保持一致)。最终,因为有N个卷积核,我们对应的输出维度也是N。因此,我们最终的时间复杂度就是,
而我们仔细观察一下,整个卷积的过程其实可以拆分为2部分,第一部分就是每一个卷积核对各自对应输入的通道数分别进行滤波操作(即如上图所示,1个卷积核有3个通道,每一个通道分别对应输入的一个通道),然后再将各自通道的滤波结果进行相加,最终得到输出,用公式表达就是(假设步长为1且有padding),
因此,接下来,我们就要将传统卷积这两步给拆分开来,分别由depthwise convolutions和pointwise convolutions来完成。
2.2.1.2 depthwise convolutions
深度卷积的意思其实就是对每一个输入通道,分别进行滤波操作。意思就是,这个时候,各层通道之间将不会再有联系了(即最后的相加操作没有了),那么这个时候的时间复杂度就没有N了,即为,
如果没有理解的话,这里贴一张网上盗的示意图【1】,大家就应该都懂了,

看完上面这两张对比图,应该都明白了。因此,这个时候,输入有多少通道数,我们输出就有多少通道数了。
2.2.1.3 pointwise convolutions
深度卷积相比传统卷积已经省了很多事情啦,但是其仅仅对每一个通道进行了滤波操作,各个通道之间的特征联系就没有了。因此,为了达到与传统的卷积操作同样的效果,我们还需要提供一种结构来结合各个通道,这种结构就是pointwise convolutions。
这种结构。。其实很简单,就是1*1的卷积。。。这样就能把各个通道的特征连在一起了哈哈~并且其输出取决于配了几个卷积核。再贴一张示意图,方便大家理解整个过程,

因此,这一层操作的时间复杂度就是,
因此与上面的时间复杂度合起来,再与传统卷积的相对比,可以看到,

当的时候,差不多少了8-9倍的计算量~有一点值得注意的就是,MobileNets在每一层后面都加了BN + ReLU层,因此,总结来看,
- 普通卷积:3*3 Conv + BN + ReLU
- MobileNets卷积:3*3 Depthwise Conv + BN + ReLU + 1*1 Pointwise Conv + BN + ReLU

参数量的对比,我们也看一下,假设输入通道数为3,输出通道数为256,
- 直接来一个33256的卷积核,参数量为
- MobileNets里面,
第一部分为 = 27
第二部分为
一共就为768 + 9 = 795
可以说是减少了很多量~至此,整一套MobileNets的核心思想已经讲明白了,就是将卷积操作拆分成两部来做。当然作者还提了几个优化的超参数,我们再来理解一下。
2.3 Width Multiplier: Thinner Models
The role of the width multiplier is to thin a network uniformly at each layer. For a given layer and width multiplier , the number of input channels M becomes and the number of output channels N becomes .
意思就是通过减少输入大小和输出大小进一步缩减了时间复杂度(大概是)。
2.4 Resolution Multiplier: Reduced Representation
意思就是进一步减少输入图像的大小,用超参数。因此,动用了上述2个超参数后,最后的时间复杂度可以表述为,
我们再来看一张实验中的每一层操作的时间消耗图,
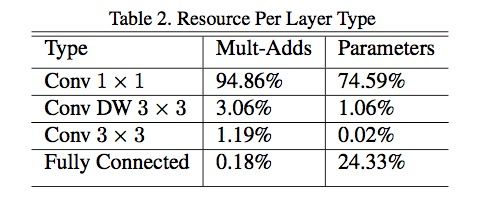
可以发现与理论基本相符合,其他一些实验过程及结论,这里就不多作展示了~基本上准确率上不会差太多的~还是很能打的一个网络架构,很赞~
------------------第三菇 - 总结------------------
3.1 总结
到这里,整篇论文的核心思想已经说清楚了。本论文主要是提出了一种轻型的网络架构MobileNets,并实验证明了该网络的可行性,为后续发展奠定了基础。
简单总结一下本文就是先罗列了一下该论文的摘要,再具体介绍了一下本文作者的思路,也简单表述了一下,自己对整个MobileNets网络架构的理解。希望大家读完本文后能进一步加深对该论文的理解。有说的不对的地方也请大家指出,多多交流,大家一起进步~