DUBBO线程模型
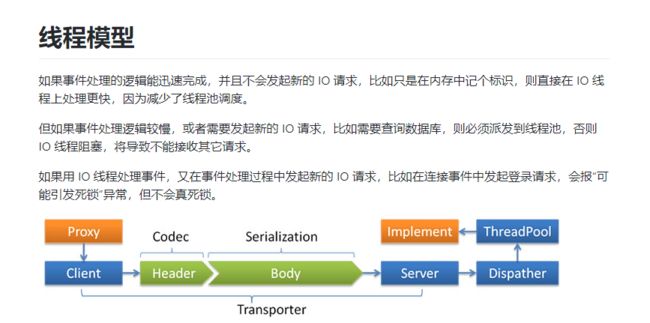
从官方描述来看dubbo线程模型支持业务线程和I/O线程分离,并且提供5种不同的调度策略。

拿Netty组件为例(Netty4x),在NettyServer的构造方法中通过ChannelHandlers#wrap方法设置MultiMessageHandler,HeartbeatHandler并通过SPI扩展选择调度策略。
public NettyServer(URL url, ChannelHandler handler) throws RemotingException {
super(url, ChannelHandlers.wrap(handler, ExecutorUtil.setThreadName(url, SERVER_THREAD_POOL_NAME))); // 线程派发
}
ChannelHandlers#wrapInternal
protected ChannelHandler wrapInternal(ChannelHandler handler, URL url) {
// 选择调度策略 默认是all
return new MultiMessageHandler(new HeartbeatHandler(ExtensionLoader.getExtensionLoader(Dispatcher.class)
.getAdaptiveExtension().dispatch(handler, url))); //
}
接下来看下NettyServer#doOpen方法 ,主要设置Netty的boss线程池数量为1,worker线程池(也就是I/O线程)为cpu核心数+1和向Netty中注测Handler用于消息的编解码和处理。
protected void doOpen() throws Throwable {
bootstrap = new ServerBootstrap();
// 多线程模型
// boss线程池,负责和消费者建立新的连接
bossGroup = new NioEventLoopGroup(1, new DefaultThreadFactory("NettyServerBoss", true));
// worker线程池,负责连接的数据交换
workerGroup = new NioEventLoopGroup(getUrl().getPositiveParameter(Constants.IO_THREADS_KEY, Constants.DEFAULT_IO_THREADS),
new DefaultThreadFactory("NettyServerWorker", true));
final NettyServerHandler nettyServerHandler = new NettyServerHandler(getUrl(), this);
channels = nettyServerHandler.getChannels();
bootstrap.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childOption(ChannelOption.TCP_NODELAY, Boolean.TRUE) // nagele 算法
.childOption(ChannelOption.SO_REUSEADDR, Boolean.TRUE)// TIME_WAIT
.childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT) //内存池
.childHandler(new ChannelInitializer() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
NettyCodecAdapter adapter = new NettyCodecAdapter(getCodec(), getUrl(), NettyServer.this);
ch.pipeline()//.addLast("logging",new LoggingHandler(LogLevel.INFO))//for debug
.addLast("decoder", adapter.getDecoder()) //设置编解码器
.addLast("encoder", adapter.getEncoder())
.addLast("handler", nettyServerHandler);
}
});
// bind 端口
ChannelFuture channelFuture = bootstrap.bind(getBindAddress());
channelFuture.syncUninterruptibly();
channel = channelFuture.channel();
}
可以看出,如果我们在一个JVM进程只暴露一个Dubbo服务端口,那么一个JVM进程只会有一个NettyServer实例,也会只有一个NettyHandler实例 。从上面代码也可以看出,Dubbo在Netty的Pipeline中只注册了三个Handler,而Dubbo内部也定义了一个ChannelHandler接口用来将和Channel相关的处理串起来,而第一个ChannelHandler就是由NettyHandler来调用的。有趣的是NettyServer本身也是一个ChannelHandler。当Dubbo将Spring容器中的服务实例做了动态代理的处理后,就会通过NettyServer#doOpen来暴露服务端口,再接着将服务注册到注册中心。这些步骤做完后,Dubbo的消费者就可以来和提供者建立连接了,当然是消费者来主动建立连接,而提供者在初始化连接后会调用NettyHandler#channelActive方法来创建一个NettyChannel:
public void channelActive(ChannelHandlerContext ctx) throws Exception {
logger.debug("channelActive <" + NetUtils.toAddressString((InetSocketAddress) ctx.channel().remoteAddress()) + ">" + " channle <" + ctx.channel());
//获取或者创建一个NettyChannel
NettyChannel channel = NettyChannel.getOrAddChannel(ctx.channel(), url, handler);
try {
if (channel != null) {
//
channels.put(NetUtils.toAddressString((InetSocketAddress) ctx.channel().remoteAddress()), channel);
}
// 这里的 handler就是NettyServer
handler.connected(channel);
} finally {
NettyChannel.removeChannelIfDisconnected(ctx.channel());
}
}
与Netty和Dubbo都有自己的ChannelHandler一样,Netty和Dubbo也有着自己的Channel。该方法最后会调用NettyServer#connected方法来检查新添加channel后是否会超出提供者配置的accepts配置,如果超出,则直接打印错误日志并关闭该Channel,这样的话消费者端自然会收到连接中断的异常信息,详细可以见AbstractServer#connected方法。
public void connected(Channel ch) throws RemotingException {
// If the server has entered the shutdown process, reject any new connection
if (this.isClosing() || this.isClosed()) {
logger.warn("Close new channel " + ch + ", cause: server is closing or has been closed. For example, receive a new connect request while in shutdown process.");
ch.close();
return;
}
Collection channels = getChannels();
//大于accepts的tcp连接直接关闭
if (accepts > 0 && channels.size() > accepts) {
logger.error("Close channel " + ch + ", cause: The server " + ch.getLocalAddress() + " connections greater than max config " + accepts);
ch.close();
return;
}
super.connected(ch);
}
注意的是在dubbo中消费者和提供者默认只建立一个TCP长连接,为了增加消费者调用服务提供者的吞吐量, 可以在消费方增加如下配置:
而作为提供者可以使用accepts控制长连接的数量防止连接数量过多,配置如下:
当连接建立完成后,消费者就可以请求提供者的服务了,当请求到来,提供者这边会依次经过如下Handler的处理:
--->NettyServerHandler#channelRead接收请求消息
--- >AbstractPeer#received:如果服务已经关闭,则返回,否则调用下一个Handler来处理。
--->MultiMessageHandler#received:如果是批量请求,则依次对请求调用下一个Handler来处理。
--->HeartbeatHandler#received: 处理心跳消息。
--->AllChannelHandler#received:该Dubbo的Handler非常重要,因为从这里是IO线程池和业务线程池的隔离。
--->DecodeHandler#received: 消息解码
--->HeaderExchangeHandler #received :消息处理
--->DubboProtocol : 远程调用
看下AllChannelHandler#received:
public void received(Channel channel, Object message) throws RemotingException {
// 获取业务线程池
ExecutorService cexecutor = getExecutorService();
try {
// 使用线程池处理消息
cexecutor.execute(new ChannelEventRunnable(channel, handler, ChannelState.RECEIVED, message));
} catch (Throwable t) {
throw new ExecutionException(message, channel, getClass() + " error when process received event .", t);
}
}
这里对execute进行了异常捕获,这是因为I/O线程池是无界的,但业务线程池可能是有界的,所以进行execute提交可能会遇到RejectedExecutionException异常 。
那么这里是如何获取到业务线程池的那?实际上WrappedChannelHandler是xxxChannelHandlerd的装饰类,根据dubbo SPI可以知道,获取AllChannelHandler会首先实例化WrappedChannelHandler。
public WrappedChannelHandler(ChannelHandler handler, URL url) {
this.handler = handler;
this.url = url;
// 获取业务线程池
executor = (ExecutorService) ExtensionLoader.getExtensionLoader(ThreadPool.class).getAdaptiveExtension().getExecutor(url);
String componentKey = Constants.EXECUTOR_SERVICE_COMPONENT_KEY;
if (Constants.CONSUMER_SIDE.equalsIgnoreCase(url.getParameter(Constants.SIDE_KEY))) {
componentKey = Constants.CONSUMER_SIDE;
}
DataStore dataStore = ExtensionLoader.getExtensionLoader(DataStore.class).getDefaultExtension();
dataStore.put(componentKey, Integer.toString(url.getPort()), executor);
}
根据上面的代码可以看出dubbo业务线程池是在WrappedChannelHandler实例化的时候获取的。
接下来我们要看下dubbo的业务线程池模型,先上一个官方描述:

- FixedThreadPool:
public class FixedThreadPool implements ThreadPool {
@Override
public Executor getExecutor(URL url) {
// 线程池名称DubboServerHanler-server:port
String name = url.getParameter(Constants.THREAD_NAME_KEY, Constants.DEFAULT_THREAD_NAME);
// 缺省线程数量200
int threads = url.getParameter(Constants.THREADS_KEY, Constants.DEFAULT_THREADS);
// 任务队列类型
int queues = url.getParameter(Constants.QUEUES_KEY, Constants.DEFAULT_QUEUES);
return new ThreadPoolExecutor(threads, threads, 0, TimeUnit.MILLISECONDS,
queues == 0 ? new SynchronousQueue() :
(queues < 0 ? new LinkedBlockingQueue()
: new LinkedBlockingQueue(queues)),
new NamedInternalThreadFactory(name, true), new AbortPolicyWithReport(name, url));
}
}
缺省情况下使用200个线程和SynchronousQueue这意味着如果如果线程池所有线程都在工作再有新任务会直接拒绝。
-
CachedThreadPool:
public class CachedThreadPool implements ThreadPool { @Override public Executor getExecutor(URL url) { String name = url.getParameter(Constants.THREAD_NAME_KEY, Constants.DEFAULT_THREAD_NAME); // 核心线程数量 缺省为0 int cores = url.getParameter(Constants.CORE_THREADS_KEY, Constants.DEFAULT_CORE_THREADS); // 最大线程数量 缺省为Integer.MAX_VALUE int threads = url.getParameter(Constants.THREADS_KEY, Integer.MAX_VALUE); // queue 缺省为0 int queues = url.getParameter(Constants.QUEUES_KEY, Constants.DEFAULT_QUEUES); // 空闲线程存活时间 int alive = url.getParameter(Constants.ALIVE_KEY, Constants.DEFAULT_ALIVE); return new ThreadPoolExecutor(cores, threads, alive, TimeUnit.MILLISECONDS, queues == 0 ? new SynchronousQueue() : (queues < 0 ? new LinkedBlockingQueue () : new LinkedBlockingQueue (queues)), new NamedInternalThreadFactory(name, true), new AbortPolicyWithReport(name, url)); } } 缓存线程池,可以看出如果提交任务的速度大于maxThreads将会不断创建线程,极端条件下将会耗尽CPU和内存资源。在突发大流量进入时不适合使用。
-
LimitedThreadPool:
public class LimitedThreadPool implements ThreadPool { @Override public Executor getExecutor(URL url) { String name = url.getParameter(Constants.THREAD_NAME_KEY, Constants.DEFAULT_THREAD_NAME); // 缺省核心线程数量为0 int cores = url.getParameter(Constants.CORE_THREADS_KEY, Constants.DEFAULT_CORE_THREADS); // 缺省最大线程数量200 int threads = url.getParameter(Constants.THREADS_KEY, Constants.DEFAULT_THREADS); // 任务队列缺省0 int queues = url.getParameter(Constants.QUEUES_KEY, Constants.DEFAULT_QUEUES); return new ThreadPoolExecutor(cores, threads, Long.MAX_VALUE, TimeUnit.MILLISECONDS, queues == 0 ? new SynchronousQueue() : (queues < 0 ? new LinkedBlockingQueue () : new LinkedBlockingQueue (queues)), new NamedInternalThreadFactory(name, true), new AbortPolicyWithReport(name, url)); } } 不配置的话和FixedThreadPool没有区别
-
EagerThreadPool :
public class EagerThreadPool implements ThreadPool { @Override public Executor getExecutor(URL url) { String name = url.getParameter(Constants.THREAD_NAME_KEY, Constants.DEFAULT_THREAD_NAME); // 0 int cores = url.getParameter(Constants.CORE_THREADS_KEY, Constants.DEFAULT_CORE_THREADS); // Integer.MAX_VALUE int threads = url.getParameter(Constants.THREADS_KEY, Integer.MAX_VALUE); // 0 int queues = url.getParameter(Constants.QUEUES_KEY, Constants.DEFAULT_QUEUES); // 60s int alive = url.getParameter(Constants.ALIVE_KEY, Constants.DEFAULT_ALIVE); // init queue and executor // 初始任务队列为1 TaskQueuetaskQueue = new TaskQueue (queues <= 0 ? 1 : queues); EagerThreadPoolExecutor executor = new EagerThreadPoolExecutor(cores, threads, alive, TimeUnit.MILLISECONDS, taskQueue, new NamedInternalThreadFactory(name, true), new AbortPolicyWithReport(name, url)); taskQueue.setExecutor(executor); return executor; } } EagerThreadPoolExecutor:
public void execute(Runnable command) { if (command == null) { throw new NullPointerException(); } // do not increment in method beforeExecute! //已提交任务数量 submittedTaskCount.incrementAndGet(); try { super.execute(command); } catch (RejectedExecutionException rx) { //大于最大线程数被拒绝任务 重新添加到任务队列 // retry to offer the task into queue. final TaskQueue queue = (TaskQueue) super.getQueue(); try { if (!queue.retryOffer(command, 0, TimeUnit.MILLISECONDS)) { submittedTaskCount.decrementAndGet(); throw new RejectedExecutionException("Queue capacity is full.", rx); } } catch (InterruptedException x) { submittedTaskCount.decrementAndGet(); throw new RejectedExecutionException(x); } } catch (Throwable t) { // decrease any way submittedTaskCount.decrementAndGet(); throw t; } }TaskQueue:
public boolean offer(Runnable runnable) { if (executor == null) { throw new RejectedExecutionException("The task queue does not have executor!"); } // 获取当前线程池中的线程数量 int currentPoolThreadSize = executor.getPoolSize(); // have free worker. put task into queue to let the worker deal with task. // 如果已经提交的任务数量小于当前线程池中线程数量(不是很理解这里的操作) if (executor.getSubmittedTaskCount() < currentPoolThreadSize) { return super.offer(runnable); } // return false to let executor create new worker. //当前线程数小于最大线程程数直接创建新worker if (currentPoolThreadSize < executor.getMaximumPoolSize()) { return false; } // currentPoolThreadSize >= max return super.offer(runnable); }优先创建
Worker线程池。在任务数量大于corePoolSize但是小于maximumPoolSize时,优先创建Worker来处理任务。当任务数量大于maximumPoolSize时,将任务放入阻塞队列中。阻塞队列充满时抛出RejectedExecutionException。(相比于cached:cached在任务数量超过maximumPoolSize时直接抛出异常而不是将任务放入阻塞队列)
根据以上的代码分析,如果消费者的请求过快很有可能导致服务提供者业务线程池抛出RejectedExecutionException异常。这个异常是duboo的采用的线程拒绝策略AbortPolicyWithReport#rejectedExecution抛出的,并且会被反馈到消费端,此时简单的解决办法就是将提供者的服务调用线程池数目调大点,例如如下配置:
我们为了保证模块内的主要服务有线程可用(防止次要服务抢占过多服务调用线程),可以对次要服务进行并发限制,例如:
回过头来再看下dubbo得Dispatcher 策略默认是all,实际上比较好的处理方式是I/O线程和业务线程分离,所以采取message是比较好得配置。并且如果采用all如果使用的dubo版本比较低很有可能会触发dubbo的bug。
原因请参见:全部请求都使用业务线程池的问题
在dubbo重新维护之后这个bug已经被修复:
public void received(Channel channel, Object message) throws RemotingException {
// 获取业务线程池
ExecutorService cexecutor = getExecutorService();
try {
// 使用线程池处理消息
cexecutor.execute(new ChannelEventRunnable(channel, handler, ChannelState.RECEIVED, message));
} catch (Throwable t) {
//TODO A temporary solution to the problem that the exception information can not be sent to the opposite end after the thread pool is full. Need a refactoring
//fix The thread pool is full, refuses to call, does not return, and causes the consumer to wait for time out
if(message instanceof Request && t instanceof RejectedExecutionException){
Request request = (Request)message;
if(request.isTwoWay()){
String msg = "Server side(" + url.getIp() + "," + url.getPort() + ") threadpool is exhausted ,detail msg:" + t.getMessage();
Response response = new Response(request.getId(), request.getVersion());
response.setStatus(Response.SERVER_THREADPOOL_EXHAUSTED_ERROR);
response.setErrorMessage(msg);
channel.send(response);
return;
}
}
throw new ExecutionException(message, channel, getClass() + " error when process received event .", t);
}
}
如果是RejectedExecutionException异常直接返回给消费者。
建议的配置是: