什么是数据库?
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库,
每个数据库都有一个或多个不同的API用于创建,访问,管理,搜索和复制所保存的数据。
我们也可以将数据存储在文件中,但是在文件中读写数据速度相对较慢。
所以,现在我们使用关系型数据库管理系统(RDBMS)来存储和管理的大数据量。所谓的关系型数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。
RDBMS即关系数据库管理系统(Relational Database Management System)的特点:
1.数据以表格的形式出现
2.每行为各种记录名称
3.每列为记录名称所对应的数据域
4.许多的行和列组成一张表单
5.若干的表单组成database
其中,MySQL 是目前最流行的关系型数据库管理系统,在WEB应用方面 MySQL 是最好的RDBMS应用软件之一。
关系型数据库管理系统术语:
数据库: 数据库是一些关联表的集合。
数据表: 表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。
列: 一列(数据元素) 包含了相同的数据, 例如邮政编码的数据。
行:一行(=元组,或记录)是一组相关的数据,例如一条用户订阅的数据。
冗余:存储两倍数据,冗余降低了性能,但提高了数据的安全性。
主键:主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。
外键:外键用于关联两个表。
复合键:复合键(组合键)将多个列作为一个索引键,一般用于复合索引。
索引:使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。类似于书籍的目录。
参照完整性: 参照的完整性要求关系中不允许引用不存在的实体。与实体完整性是关系模型必须满足的完整性约束条件,目的是保证数据的一致性。
如果一个数据库声称支持事务的操作,那么该数据库必须要具备以下四个特性(简称:ACID):
原子性(Atomicity):
原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响。
一致性(Consistency):
一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。
拿转账来说,假设用户A和用户B两者的钱加起来一共是5000,那么不管A和B之间如何转账,转几次账,事务结束后两个用户的钱相加起来应该还得是5000,这就是事务的一致性。
隔离性(Isolation):
隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。
也就是要达到这样一种效果:对于任意两个并发的事务T1和T2,在事务T1看来,T2要么在T1开始之前就已经结束,要么在T1结束之后才开始,这样每个事务都感觉不到有其他事务在并发地执行。
持久性(Durability):
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
例如我们在使用JDBC操作数据库时,在提交事务方法后,提示用户事务操作完成,当我们程序执行完成直到看到提示后,就可以认定事务以及正确提交,即使这时候数据库出现了问题,也必须要将我们的事务完全执行完成,否则就会造成我们看到提示事务处理完毕,但是数据库因为故障而没有执行事务的重大错误。
注意!!!
当多个线程都开启事务操作数据库中的数据时,数据库系统要能进行隔离操作,以保证各个线程获取数据的准确性。如果不考虑事务的隔离性,会发生以下几种常见的问题。
A:脏读
脏读是指,在一个事务处理过程中 读取了 另一个未提交的事务中的数据。当一个事务正在多次修改某个数据,而在这个事务中这多次的修改都还未提交,这时一个并发的事务来访问该数据,就会造成两个事务得到的数据不一致。
假设用户A向用户B转账100元,对应SQL命令如下
update account set money=money+100 where name=’B’; (此时A通知B)
update account set money=money-100 where name=’A’;
当执行到第一条SQL时,A通知B查看账户,B发现确实钱已到账(此时即发生了脏读),而之后无论第二条SQL是否执行,只要该事务不提交,则所有操作都将回滚,那么当B以后再次查看账户时就会发现钱其实并没有转。
B:不可重复读
不可重复读是指在对于数据库中的某个数据,一个事务范围内多次查询却返回了不同的数据值,这是由于在查询间隔,被另一个事务修改并提交了。
例如事务T1在读取某一数据,而事务T2立马修改了这个数据并且提交事务给数据库,事务T1再次读取该数据就得到了不同的结果,发送了不可重复读。
不可重复读和脏读的区别是,脏读是某一事务读取了另一个事务未提交的脏数据,而不可重复读则是读取了前一事务提交的数据。
在某些情况下,不可重复读并不是问题,比如我们多次查询某个数据当然以最后查询得到的结果为主。但在另一些情况下就有可能发生问题,例如对于同一个数据A和B依次查询就可能不同
C:虚读(幻读)
幻读是事务非独立执行时发生的一种现象。
例如事务T1对一个表中所有的行的某个数据项做了从“1”修改为“2”的操作,这时事务T2又对这个表中插入了一行数据项,而这个数据项的数值还是为“1”并且提交给数据库。而操作事务T1的用户如果再查看刚刚修改的数据,会发现还有一行没有修改,其实这行是从事务T2中添加的,就好像产生幻觉一样,这就是发生了幻读。
幻读和不可重复读都是读取了另一条已经提交的事务(这点就脏读不同),所不同的是不可重复读查询的都是同一个数据项,而幻读针对的是一批数据整体(比如数据的个数)。
既然数据库操作可能会出现一些问题,来看看MySQL为我们提供的四种隔离级别:
① Serializable (串行化):可避免脏读、不可重复读、幻读的发生。
② Repeatable read (可重复读):可避免脏读、不可重复读的发生。
③ Read committed (读已提交):可避免脏读的发生。
④ Read uncommitted (读未提交):最低级别,任何情况都无法保证。
以上四种隔离级别最高的是Serializable级别,最低的是Read uncommitted级别,当然级别越高,执行效率就越低。像Serializable这样的级别,就是以锁表的方式(类似于Java多线程中的锁)使得其他的线程只能在锁外等待,所以平时选用何种隔离级别应该根据实际情况。在MySQL数据库中默认的隔离级别为Repeatable read (可重复读)。
在MySQL数据库中,支持上面四种隔离级别,默认的为Repeatable read (可重复读);而在Oracle数据库中,只支持Serializable (串行化)级别和Read committed (读已提交)这两种级别,其中默认的为Read committed级别。
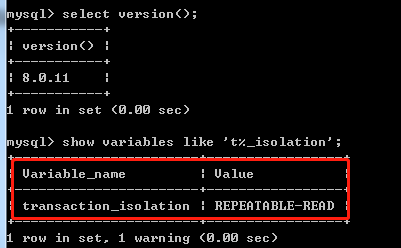
那么在MySQL中如何查看当前事务的隔离级别?
笔者的MYSQL版本是8.0.11,查询数据库隔离级别跟之前5.X版本的语法不一样,
新语法如下:show variables like 't%_isolation';
切记:设置数据库的隔离级别一定要是在开启事务之前!
另外,MySQL学习起来的难度适中,主要掌握基本的语法、优化策略,阅读一些优秀的开源资料有助于我们掌握一门数据库知识也是非常有必要的。
如果这篇文章对您有开发or学习上的些许帮助,希望各位看官留下宝贵的star,谢谢。
Ps:著作权归作者所有,转载请注明作者, 商业转载请联系作者获得授权,非商业转载请注明出处(开头或结尾请添加转载出处,添加原文url地址),文章请勿滥用,也希望大家尊重笔者的劳动成果。