返回主页
AdaBoost(Adaptive Boost)隶属于 Boosting 方法族,广泛用于分类任务,它通过改变训练集样本的权重,学习多个分类器,并将其线性组合,提高分类器的性能。该算法由 Freund 和 Schapire 于1995年提出。
1、算法思想
对于一个复杂任务来说,将多个专家的判断进行 适当的综合 所得出的判断,要比其中任何一个专家单独的判断好——“三个臭皮匠赛过诸葛亮”。
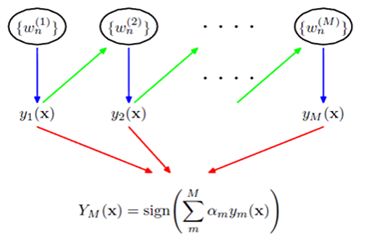
2、算法特点
AdaBoost 有四个独特的算法特点:
1、基分类器赋权重,通过权重的将多个基分类器线性组合,输出最终预测值,这相当于使学习率自适应(Adaptive),这也是 AdaBoost 以 Ada 开头的原因,而其他 Boosting 方法的学习率是固定的,因此,该权重也成为需要学习的目标之一。分类器权重之和未必等于 1。
2、样本赋权重,AdaBoost 另一个特别之处就是在训练每个基分类器时,事先先改变本轮训练集每个样本的概率分布(样本权重),而权重大小的赋予逻辑基于每个样本上一轮的误分类率,即某个样本在上一轮导致分类错误,则在下一轮会赋予更高的权重使之收到格外的关注。样本权重之和 = 1(通过归一化)。
3、基分类器多样性,AdaBoost 是一种提升思想,对基分类器的形态没有做强制限制,可以是 CART,SVM,Logistic Regression 等单模型,只是针对不同的单模型,需要在每一轮估计单模型的参数。
4、场景限制,由于 AdaBoost 需要给每个样本赋权重,因此该算法不适用于离散的特征。
3、数据集与特征空间

4、假设空间

5、目标函数及其推导(使用指数损失)
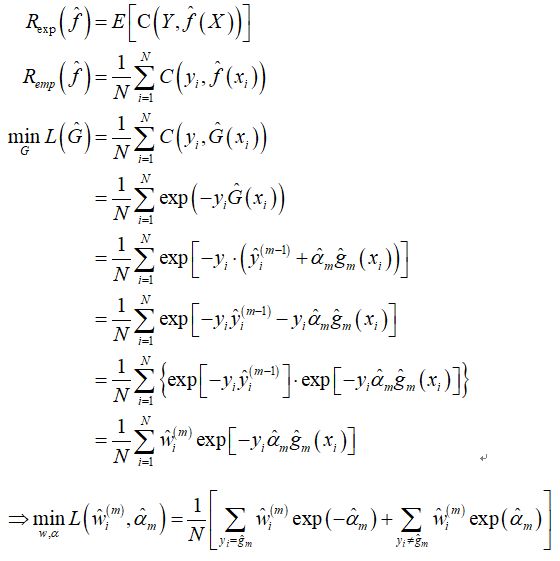
因指数函数在实数域上为凸函数,求函数极小值可通过对 alpha 求偏导得到,进而得到最优解的表达式。

此时,最优解中还存在 待估计的 w 不得而知,因此,定义 w 为第 m 轮所有误分类样本的权重之和,于是我们有:
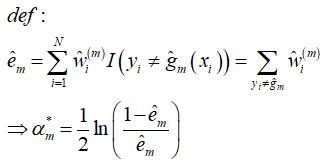
并且,由于每个样本的权重 w 在每轮都会根据上一轮的误差率发生更新,因此,还需要定义 w 的更新公式,w 其实就是每个样本的损失值,于是有(Z 为归一化分母,使得 w 之和 = 1):
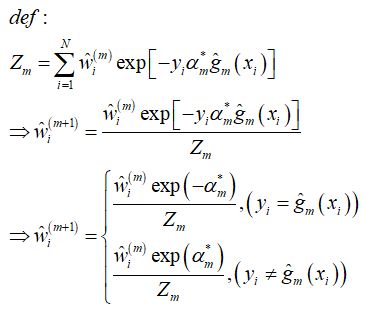
6、优化算法(前向分步式)
(1)、初始化样本权重,按样本量取均匀分布,赋到特征空间上,形成权重训练集

(2)、根据定义好的基分类器训练模型 g1,并保存本轮模型参数

(3)、计算本轮的 误分类率 和 alpha 最优值,并保存 alpha*
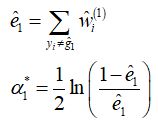
(4)、计算 累积截止到本轮 的 训练集损失 和 测试集损失
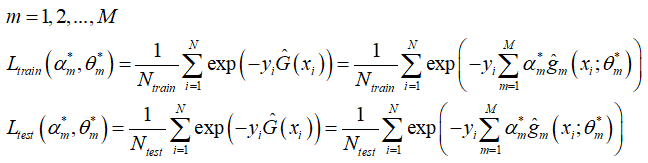
(5)、计算下一轮的样本权重分布 w
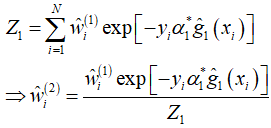
(6)、循环(1-4),直到测试集损失不再下降,算法停止避免过拟合,确定最优分类器个数 M best
(7)、模型预测
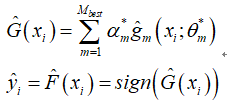
手写算法并与 Sklearn 进行对比
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
#from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
# LogitRegModel 略
class AdaBoostModel(LogitRegModel):
def __init__(self, ada_iter, base_iter, eta, alpha, beta):
self.ada_iter = ada_iter
super(AdaBoostModel, self).__init__(base_iter, eta, alpha, beta)
def update_weights(self, weights, y_train, a, y_pred):
'''更新样本权重'''
Z = np.sum(weights * np.exp(-y_train * a * y_pred))
weights = weights * np.exp(-y_train * a * y_pred) / Z
return weights
def fit_adaboost(self, x_train_scale, y_train, x_test_scale, y_test):
'''模型训练'''
# 定义子模型
base_model = LogitRegModel()
# 样本权重初始化
weights = 1.0 / x_train_scale.shape[0]
weights = np.ones_like(y_train) * weights
d_train_scale = weights * x_train_scale
# 参数初始化
a_res = []
theta_res = []
G_train = 0
G_test = 0
loss_train_res = []
loss_test_res = []
for epoch in range(self.ada_iter):
# 根据定义好的基分类器训练模型 g1,并保存本轮模型参数
theta, loss_res = base_model.fit(d_train_scale, y_train)
theta_res.append(theta)
# 计算本轮的 误分类率 和 alpha 最优值,并保存 alpha*
y_pred_probs, y_pred = base_model.predict(d_train_scale, theta)
e = weights[y_train != y_pred].sum()
a = 0.5 * np.log((1.0 - e) / e)
a_res.append(a)
# 计算 累积截止到本轮 的 训练集损失 和 测试集损失
_, y_pred_train = base_model.predict(x_train_scale, theta)
_, y_pred_test = base_model.predict(x_test_scale, theta)
G_train += a * y_pred_train
G_test += a * y_pred_test
loss_train = np.mean(np.exp(-y_train * G_train))
loss_test = np.mean(np.exp(-y_test * G_test))
loss_train_res.append(loss_train)
loss_test_res.append(loss_test)
# 计算下一轮的样本权重分布 w
weights = self.update_weights(weights, y_train, a, y_pred)
# 更新样本权重赋值
d_train_scale = weights * x_train_scale
return a_res, theta_res, loss_train_res, loss_test_res
def choose_best(self, loss_test_res, a_res, theta_res):
'''确定最优分类器个数'''
best_iter = np.argmin(loss_test_res)
print(f"最优迭代次数(基于测试集):{best_iter}")
a_best = a_res[0: best_iter + 1]
theta_best = theta_res[0: best_iter + 1]
return a_best, theta_best
def predict(self, x_test_scale, a_res, theta_res):
'''模型预测'''
# 定义子模型
base_model = LogitRegModel()
# 参数初始化
G_test = 0
# 综合子模型预测值
for i in range(len(a_res)):
_, y_pred_test = base_model.predict(x_test_scale, theta_res[i])
G_test += a_res[i] * y_pred_test
y_pred = np.sign(G_test)
return y_pred
def get_score(self, y_true, y_pred):
'''模型评估'''
score = sum(y_true == y_pred) / len(y_true)
return score
if __name__ == "__main__":
# 构造二分类数据集
N = 200; n = 4
x1 = np.random.uniform(low=1, high=5, size=[N, n]) + np.random.randn(N, n)
y1 = np.tile(-1, N)
x2 = np.random.uniform(low=4, high=10, size=[N, n]) + np.random.randn(N, n)
y2 = np.tile(1, N)
x = np.concatenate([x1, x2], axis=0)
y = np.concatenate([y1, y2]).reshape(-1, 1)
x, y = shuffle(x, y, random_state=0)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
# 手写模型
model = AdaBoostModel(ada_iter=10, base_iter=100, eta=0.01, alpha=0.5, beta=0.9)
mu, std = model.z_scale(x_train)
x_train_scale, x_test_scale = model.data_transform(mu, std, x_train, x_test)
a_res, theta_res, loss_train_res, loss_test_res = model.fit_adaboost(x_train_scale, y_train,
x_test_scale, y_test)
fig, ax = plt.subplots(figsize=(8, 8))
pd.DataFrame({"loss_train": loss_train_res, "loss_test": loss_test_res}).plot()
plt.xlabel("a")
plt.ylabel("loss")
plt.title("AdaBoostModel Loss")
plt.show()
a_best, theta_best = model.choose_best(loss_test_res, a_res, theta_res)
y_pred = model.predict(x_test_scale, a_best, theta_best)
score = model.get_score(y_test, y_pred)
print(f"AdaBoostModel 预测准确率:{score}")
# sklearn
scale = StandardScaler(with_mean=True, with_std=True)
scale.fit(x_train)
x_train_scale = scale.transform(x_train)
x_test_scale = scale.transform(x_test)
clf = AdaBoostClassifier(n_estimators=50)
clf.fit(x_train_scale, y_train)
y_pred = clf.predict(x_test_scale).reshape(-1, 1)
score = sum(y_test == y_pred) / len(y_test)
print(f"Sklearn 预测准确率:{score}")
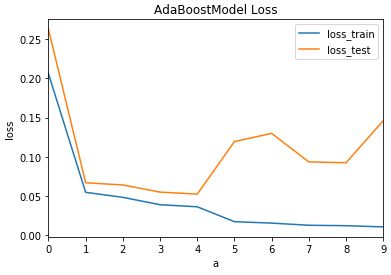
最优迭代次数(基于测试集):4
AdaBoostModel 预测准确率:[0.98333333]
Sklearn 预测准确率:[0.98333333]
返回主页