一、什么是Sarsa
在强化学习中 Sarsa 和 Q learning及其类似,这节内容会基于之前所讲的 Q learning。如果还不熟悉 Q learning 可以去看看。我们会对比 Q learning,来看看 Sarsa 是特殊在哪些方面。
Sarsa 的决策部分和 Q learning 一模一样,因为我们使用的是 Q 表的形式决策,所以我们会在 Q 表中挑选值较大的动作值施加在环境中来换取奖惩,但是不同的地方在于 Sarsa 的更新方式是不一样的。
二、Sarsa更新方式
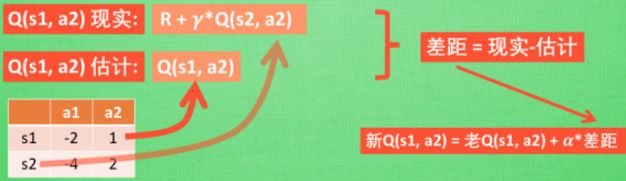
与 Q-learning 一样, 我们会经历状态 s1, 然后再挑选一个带来最大潜在奖励的动作 a2, 这样我们就到达了状态 s2, 而在这一步, 如果你用的是 Q learning, 你会观看一下在 s2 上选取哪一个动作会带来最大的奖励, 但是在真正要做决定时, 却不一定会选取到那个带来最大奖励的动作, Q-learning 在这一步只是估计了一下接下来的动作值. 而 Sarsa 到做到, 在 s2 这一步估算的动作也是接下来要做的动作. 所以 Q(s1, a2) 现实的计算值, 我们也会稍稍改动, 去掉maxQ, 取而代之的是在 s2 上我们实实在在选取的 a2 的 Q 值. 最后像 Q learning 一样, 求出现实和估计的差距 并更新 Q 表里的 Q(s1, a2)。
三、Sarsa 与 Q-learning 对比
Sarsa算法(on-policy):
Initialize Q arbitrarily // 随机初始化Q表
Repeat (for each episode): // 每一次从开始到结束是一个episode
Initialize S // S为初始位置的状态
Choose a from s using policy derived from Q(ε-greedy)
Repeat (for each step of episode):
Take action a, observe r, s'
Choose a' from s' using policy derived from Q(ε-greedy)
Q(S,A) ← Q(S,A) + α*[R + γ*Q(S',a')-Q(s,a)] //在Q中更新S
S ← S'; a← a'
until S is terminal //即到游戏结束为止
处于状态 s 时,根据当前 Q 网络以及一定的策略来选取动作 a,进而观测到下一步状态 s',并再次根据当前 Q 网络及相同的策略选择动作 a',这样就有了一个【 s,a,r,s',a' 】序列。
处于状态 s' 时,就知道了要采取哪个 a',并真的采取了这个动作。动作 a 的选取遵循 ε-greedy 策略,目标 Q 值的计算也是根据策略得到的动作 a' 计算得来。
Q-learning算法(off-policy):
Initialize Q arbitrarily // 随机初始化Q表
Repeat (for each episode): // 每一次游戏,从开始到结束是一个episode
Initialize S // S为初始位置的状态
Repeat (for each step of episode):
Choose a from s using policy derived from Q(ε-greedy) //根据当前Q和位置S,使用一种策略,得到动作A,这个策略可以是ε-greedy等
Take action a, observe r // 做了动作A,到达新的位置S',并获得奖励R,奖励可以是1,50或者-1000
Q(S,A) ← Q(S,A) + α*[R + γ*maxQ(S',a))-Q(s,a)] //在Q中更新S
S ← S'
until S is terminal //即到游戏结束为止
处于状态 s 时,根据当前 Q 网络以及一定的策略来选取动作 a,进而观测到下一步状态 s' ,并再次根据当前 Q 网络计算出下一步采取哪个动作会得到 max Q 值,用这个 Q 值作为当前状态动作对 Q 值的目标。这样就有了一个【s,a,r,s' 】序列。
处于状态 s' 时,仅计算了 在 s' 时要采取哪个 a' 可以得到更大的 Q 值,并没有真的采取这个动作 a';动作 a 的选取是根据当前 Q 网络以及策略(e-greedy),目标 Q 值的计算是根据 Q 值最大的动作 a' 计算得来。
从算法来看,这就是他们两最大的不同之处了。因为 Sarsa 是说到做到型,所以我们也叫他 On-policy(在线学习),学着自己在做的事情。而 Q learning 是说到但并不一定做到,所以它也叫作 Off-policy(离线学习)。如果你还不清楚 在线学习 和 离线学习,可以参看强化学习。
四、什么是 Sarsa(lambda)
之前所说的 Sarsa 是一种单步更新法,在环境中每走一步,更新一次自己的行为准则,我们可以在这样的 Sarsa 后面打一个括号,说他是 Sarsa(0),因为他等走完这一步以后直接更新行为准则。如果延续这种想法,走完这步,再走一步,然后再更新,我们可以叫他 Sarsa(1)。同理,如果等待回合完毕我们一次性再更新呢?比如这回合我们走了 n 步,那我们就叫 Sarsa(n)。为了统一这样的流程,我们就有了一个 lambda 值来代替我们想要选择的步数,这也就是 Sarsa(lambda) 的由来。
简单的说,Sarsa(0) 就是单步更新,Sarsa(n) 就是回合更新,如果你还不清楚什么是单步更新、回合更新,可参看强化学习。
其实 lambda 就是一个衰变值,他可以让你知道离奖励越远的步,可能并不是让你最快拿到奖励的步,所以我们想象我们站在宝藏的位置,回头看看我们走过的寻宝之路,离宝藏越近的脚印越看得清,远处的脚印太渺小,我们都很难看清,那我们就索性记下离宝藏越近的脚印越重要,越需要被好好的更新。和之前我们提到过的奖励衰减值 gamma 一样,lambda 是脚步衰减值,都是一个在 0 和 1 之间的数。
以上内容参考莫凡Python。