数据整理

这周我们进入该书第二部分,讲解数据的整理和清理数据
分为三个部分:
Tibbles
data import
tidy data
我们主要针对三种类型的数据:
关系型数据
字符型数据
时间型数据
Tibbles
在这本书中,我们使用的是“tibbles”,而不是R的传统的 data.frame。Tibbles是数据框架,但是它们会调整一些旧的行为,使用者更方便。
Creating tibbles
将数据框转变成 tibbles用as_tibble()
library(tidyverse)
as_tibble(iris)
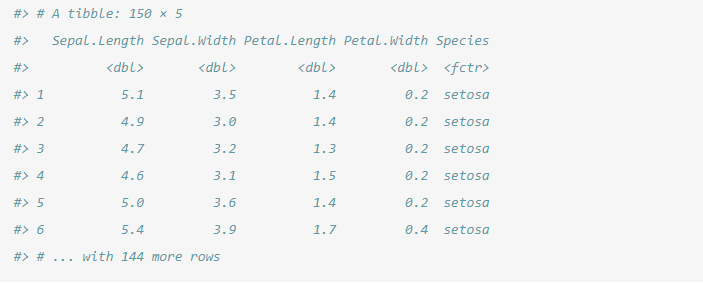
当然我们也可以利用自己的数据创造tibble
tibble(x = 1:5, y = 1, z = x ^ 2 + y)
Tibbles vs. data.frame
二者最主要的区别有两点
- 打印方式不同
Tibbles有一个改进的打印方法,只显示前10行,以及适合屏幕的所有列。这使得处理大数据变得更加容易。除了名称外,每个列都报告其类型,这是借鉴str()的一个很好的特性
当然也可以通过设置下列参数来控制默认的打印方式:
options(tibble.print_max = n, tibble.print_min = m) #if more than m rows, print only n rows.
options(dplyr.print_min = Inf)
#show all rows.options(tibble.width = Inf)
# print all columns, regardless of the width of the screen
- 取子集方式不同
如果你想要筛选标量,你可以使用 $ 和 [[. 和[[ 来提取名字或者位置
与数据集相比,tibbles更严格:它们从不进行部分匹配,如果您试图访问的列不存在,它们将生成一个警告。
Data import
数据导入采取的reader包,这是tidyverse的核心部分
大部分readr函数都会使得数据变为 tibble
read_csv()读取逗号分隔的文件,默认col_names=T
read_csv2()读取分号分隔的文件(在那些被用作小数点的国家通用),
read_tsv()读取制表符分隔的文件,
read_delim()读取带有任何分隔符的文件。
read_fwf()读取固定宽度的文件 使用fwf_widths()或其在fwf_position()的位置指定字段
read_table()读取固定宽度文件的常见变体,其中列之间用空格分隔。
read_log()读取Apache风格的日志文件
下面的章节,我们主要集中在read_csv函数

- read_csv() 函数默认使用第一行作为列名称
- skip=n skip 参数代表跳过前n行,从第n+1行开始读取
- comment 参数
comment="#",代表丢弃所有以"#"开头的行- 数据中没有列名称。可以使用
col_names=F,来告诉read_csv(),不要将第一行作为列标题,
而是将各列依次标注为X1到Xn:
有时候,文件顶部有几行元数据。可以使用skip = n跳过前n行;或者使用comment = "#"删除以#开头的所有行
read_csv("The first line of metadata The second line of metadata x,y,z 1,2,3", skip = 2)

read_csv("# A comment I want to skip x,y,z 1,2,3", comment = "#")

数据可能没有列名。您可以使用col_names = FALSE来告诉read_csv()不要将第一行作为标题,而是将它们按顺序标记为X1到Xn
read_csv("1,2,3\n4,5,6",col_names =F)

添加列名。数据可能没有列名,我们可以向col_names传递一个字符向量,以用作列名称:
read_csv("1,2,3\n,4,5,6",col_names=c("x","y","z"))

na值处理,用来定义文件中哪些值是缺失值
read_csv("a,b,c\n1,2,.", na = ".")

有时候csv文件中的字符串会包含逗号。为了防止引发问题,需要用引号(如 "或' )将逗号围起来。按照惯例,read_csv() 默认引号为", 如果想要改变默认值,就要转而使用read_delim() 函数。要想将以下文本读进入一个数据框,需要设定什么?
read_delim(x,delim = ",",quote = "'")

read_csv() now supports a quote argument, so the following code works.
read_csv(x,quote = "'")

写入文件 Writing to a file
write_csv
write_tsv
write_excel_csv (该函数会在文本开头写入一个特殊的字符(字节顺序标记),告诉Excel这个文件使用UTF-8编码 )
它们总是使用UTF-8对字符串进行编码
它们使用ISO 8601格式来保存日期和日期时间数据,以便这些数据不论在何种环境下都更容易被解析
write_csv(cha)
write_tsv()
write_excel_csv() #导出csv到excel
write_rds()和read_rds()是基本函数readRDS()和saveRDS()的统一包装器,这些数据以R的自定义二进制格式RDS存储,类似于save()函数重点Rda
write_rds(challenge, "challenge.rds")
read_rds("challenge.rds")