进一步理解卷积神经网络,对卷积网络可视化
随着深度学习的快速发展,卷积神经网络应用于各个方面,图像的分类、目标检测、图像分割等等。很多人,包括自己也是,在刚学习这些内容的时候只是看了相关理论后,然后就把数据集扔进网络开始“炼丹”。但在训练和检测过程中,虽然得到最终的分类或检测效果,却并不知道中间到底发生了什么,神经网络就犹如黑盒一样。所以想把卷积网络的处理过程进一步可视化,更好的理解中间到底发生了什么。也是作为个人学习笔记,欢迎大家讨论学习。
这里先以图像分类为例(目标检测以后有计划再进行整理)。分类网络代码参考b站up主Bubbliiiing(个人很多东西也是和这位大佬学习的,所以关于网络方面的讲解我这里不过多再说,大家可看这位大佬的视频:https://www.bilibili.com/video/BV143411B7wg?spm_id_from=333.999.0.0)
分类主干网络我选用的是经典的VGG16做猫狗分类。下面接入正题。
我们可以通过卷积核对图像逐步提取特征。这里我使用的是pytorch来举例,
先读取图片:
img = plt.imread(r'./cat.jpg')
plt.imshow(img)
plt.show()

读入的图片为numpy形式,可以用torch.tensor(img,dtype=torch.float32) / 255,转换为tensor形式。此时的图片shape为(H,W,C),需要利用**permute(2, 0, 1).unsqueeze(0)**进行维度的转换。其中unsqueeze(0)就是在最前面加一个维度,即batch_size这一维度。那么此时的图像shape将变为【1,3,H, W】才可进行卷积
设计一个卷积核:nn.Conv2d(3,3,3,1,1)【为了简单为例方便展示,我这里输出还是3通道,卷积核的权重可以自己定义,但这里我使用的默认的,只是为了演示一下】
conv1 = nn.Conv2d(3,3,3,1,1)
conv1_img = conv1(img)
# 下述代码是为了显示卷积后的图像
img1 = conv1_img.squeeze(0).permute(1,2,0)*255 # 转化维度,并且转化为0~255,数值类型转为uint8
img1 = img1.detach().numpy() # tensor 变为numpy
img1 = img1.astype('uint8')
卷积后的图像如下【每次卷积后的效果是不同的,因为Conv2d权重不是固定值】:

然后我们在来看下每个通道卷积后提取特征的效果
可以看到每个通道提取的纹理特征是不一样的,网络在训练过程会不断的更新卷积核的权重,等最终提取到的特征能满足绝大多数猫的特征的时候就可以了,然后将这个权重保存下来就是我们最终得到的权重文件了。
接下来我们再看一下图像进过已经训练好的VGG16分类网络【有关VGG16网络讲解网上有很多资料,我这里不在讲了】
我们先来看下分类效果:

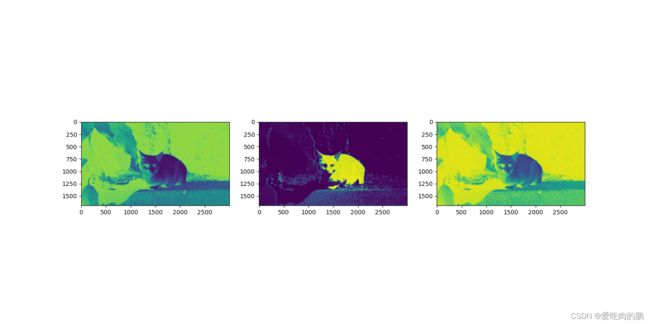
同样的,我们可以看一下网络最终在每个通道提取的特征是什么样的【通道太多,我只展现部分的】,黄色部分都是经过激活函数激活后得到的,可以认为是该通道这一区域有识别的物体。

可以计算每个通道提取的特征平均值,然后筛选出哪个通道平均特征值最大,再将该通道和原始图像叠加后看看效果图


再通过nn.Linear()进行分类,这个分类后的结果是hard target形式,类似这种形式[ 13.6133, -13.4983],预测的是二分类,假如13.6133代表预测的猫,-13.4983代表预测的狗,因为猫得到的值最大,所以得到的分类结果是猫【注意这还不是概率值,需要再经过softmax进行soft操作得到概率值】。然后可以再通过np.max()函数筛选出最大的概率值即可。
实现卷积可视化,有助于我们进一步看到这个“黑盒”中到底发生了什么,进一步理解卷积神经网络。
文章写的比较粗糙,可能还有些地方没有写到,望谅解。