rabbitMQ
微信公众号:云计算通俗讲义
持续输出技术干货,欢迎关注!
通过本文你将了解:
- AMQP协议
- RabbitMQ概述
- RabbitMQ架构
- RabbitMQ交换机
- 消息可靠性
- 消息幂等性
- 消息投递
- 消息端限流
- 消息端确认
- 重回队列/TTL队列/死信队列
- RabbitMQ常用指令
01 AMQP协议
1.1 概述
AMQP:是具有现代特征的二进制协议。是一个提供统一消息服务的应用层标准高级消息 队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。
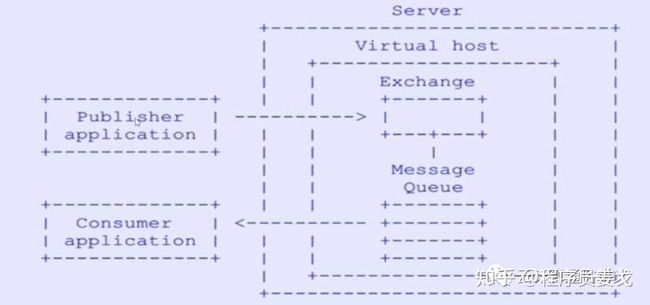
1.2 核心概念
Publisher
消息的生产者。也是一个向交换器Exchange发送消息的客户端应用程序。
Consumer
消息的消费者。表示一个从消息队列中取得消息的客户端应用程序。
Server/Broker
又称Broker,接受客户端的连接,实现AMQP实体服务。
Virtual host
虚拟地址,用于进行逻辑隔离,最上层的消息路由。
表示一批交换器,消息队列和相关对象。一个Virtual Host里面可以有若干个Exchange和Queue,同一个Virtual Host里面不能有相同名称的Exchange和Queue。
虚拟主机是共享相同的身份认证和加密环境的独立服务器域,每个vhost本质上就是一个mini版本的RabbitMQ服务器,拥有自己的队列、交换器、绑定和权限机制。vhost是AMQP概念的基础,必须在链接时指定,RabbitMQ默认的vhost是“/”。
Message
消息,服务器和应用程序之间传送的数据。消息是不具名的,由Properties和Body组成(消息头和消息体)。Properties可以对消息进行修饰,比如消息的优先级、延迟等高级特性;Body这就是消息体内容。
Exchange
交换机,接收生产者发送的消息,根据路由键转发消息到绑定的队列。
三种常见的交换机类型:
1、direct(发布与订阅,完全匹配)
2、fanout(广播)
3、topic(主题,规则匹配)
Binding
绑定。Exchange和Queue之间的虚拟连接,binding中可以包含routing key。
一个绑定就是基于路由键将交换器和消息队列连接起来的路由规则,所以可以将交换器理解成一个由绑定构成的路由表。
Routing key
路由键。一个路由规则,虚拟机可用它来确定如何路由一个特定消息。
队列通过路由键绑定到交换机。
消息发送到MQ服务器时,消息将拥有一个路由键,即便是空的。RabbitMQ也会将其和绑定使用的路由键进行匹配。
如果匹配,消息将投递到该队列;如果不匹配,消息将会进入黑洞。
Connection
连接,应用程序与Broker的TCP网络连接。
Channel
网络信道,是TCP里面的虚拟连接。几乎所有的操作都在Channel中进行, Channel是进行消息读写的通道。客户端可以建立多个Channel,每个Channel代表一个会话任务(类似数据库中Connection中的session)。例如:电缆相当于TCP,信道是一个独立光纤束,一条TCP连接上创建多条信道是没有问题的。
TCP一旦打开,就会创建AMQP信道。
无论是发布消息、接收消息、订阅队列,这些动作都是通过信道完成的。
RabbitMQ为什么需要信道?为什么不是直接通信?
1、TCP的创建和销毁开销特别大。创建需要3次握手,销毁需要4次分手;
2、如果不用信道,那应用程序就会以TCP连接RabbitMQ,高峰时每秒成千上万条连接会造成资源巨大浪费,而且操作系统每秒处理TCP连接数也是有限制的,必定造成性能瓶颈;
3、信道的原理是一条线程一条通道,多条线程多条通道同用一条TCP连接。一条TCP连接可以容纳无限的信道,即使每秒成千上万的请求也不会成为性能瓶颈。
Queue
也称为Message Queue(消费者创建),消息队列,保存消息并将它们转发给消费者。它是消息的容器,也是消息的终点。一个消息可以投入一个或多个队列。消息一直在队列里面,等待消费者连接到这个队列上将其取走。
02 概述
RabbitMQ(Advanced Message Queuing Protocol,高级消息队列协议)是一个开源的消息代理和队列服务器,用来通过普通协议在完全不同的应用之间共享数据,RabbitMQ是使用Erlang语言来编写的,并且RabbitMQ是基于AMQP协议的。
RabbitMQ高性能的原因:
Erlang语言是一种通用的面向并发的编程语言,最初在于交换机领域的架构模式,这样使得RabbitMQ在Broker之间通过数据交互的性能是非常优秀的,Erlang有着和原生Socket一样的延迟。
03 架构
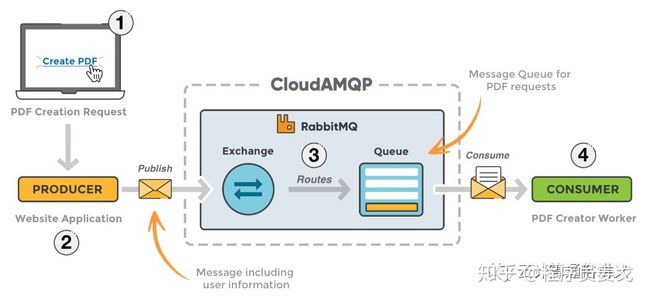
RabbitMQ架构
发消息的时候需要指定发往哪个Exchange,然后借助routing key发送到对应的消息队列queue,消费者从订阅的消息队列上取消息。
可以从架构图看出,RabbitMQ是典型的生产者-消费者模型。
04 RabbitMQ交换机
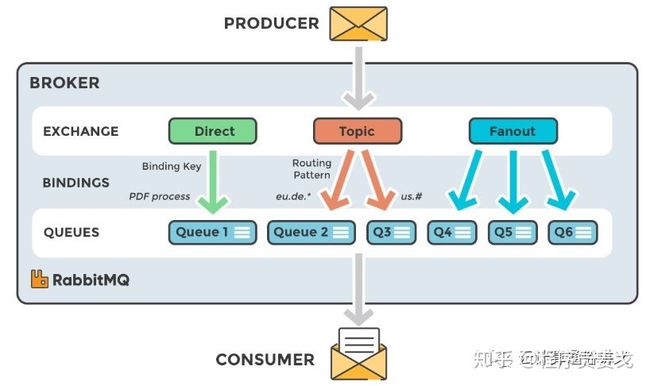
RabbitMQ交换机
Exchange交换机,接收消息,并根据路由键转发消息所绑定的队列。
交换机属性:
Name:交换机名称
Type:交换机类型direct、topic、fanout、headers
Durability:是否需要持久化(true表示需要持久化)
Auto Delete:当最后一个绑定到Exchange上的队列删除后,自动删除该Exchange
Internal:当前Exchange是否用于RabbitMQ内部使用,默认为false(很多场景都不会用到该设置)
Arguments:扩展参数,用于扩展AMQP协议自制定化使用
4.1 Direc Exchange
所有发送到Direct Exchange的消息被转发到RouteKey中指定Queue。
注意:Direct模式可以使用RabbitMQ自带的Exchange:default Exchange,所以不需要将Exchange进行任何绑定(binding)操作,消息传递时,RouteKey必须完全匹配才会被队列接收,否则该消息会抛弃。
4.2 Topic Exchange
所有发送到Topic Exchange的消息被转发到所有关心RouteKey中指定Topic的Queue上。
Exchange将RouteKey和某个Topic进行模糊匹配,此时队列需要绑定一个Topic。
注:可以使用通配符进行模糊匹配。
4.3 Fanout Exchange
Fanout(群发)不处理路由键,只需要简单的将队列绑定到交换机上。
发送到交换机的消息都会被转发到与该交换机绑定的所有队列上。
Fanout交换机转发消息是最快的。
05 消息可靠性
5.1 可靠性投递
什么是生产端的可靠性投递?
1、保障消息的成功发出;
2、保障MQ节点的成功接收;
3、发送端收到MQ节点(Broker)确认应答ACK;
4、完善的消息进行补偿机制。
5.2 解决方案
互联网大厂的解决方案:
消息落库,对消息状态进行打标;
消息的延迟投递,做二次确认,回调检查。
1、消息落库/持久化
消息信息落库(即消息持久化),对消息状态进行打标:

注:这种方案需要对数据库进行两次持久化操作。
2、延迟投递
消息落库在高并发场景下,数据库IO压力大,不适用。互联网大厂一般采用的是延迟投递,做二次检查,回调检查。
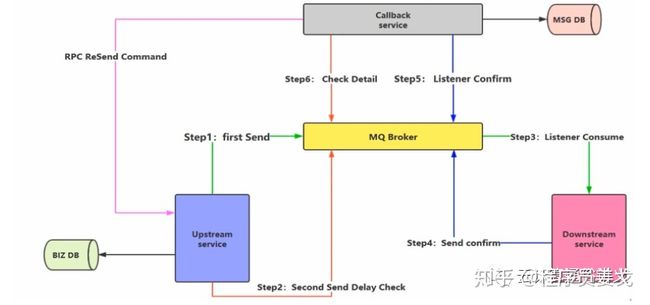
注:upstream表示生产端,downstream表示消费端。
1、首先,数据库持久化,然后发送first send消息;
2、同时发送一个延迟的检查消息(检查第一次发送消息消费情况);
3、消费端消费消息;
4、消费端发送一个确认消息给Broker;
5、回调服务检测到消费端的确认消息,进行数据库的状态持久化(这样相当于数据库一次操作,异步持久化);
6、回调服务响应第二个延时消息,确认消息成功消费,如果出现异常,回调服务调用RPC给生产者,再次发送。
06 消息幂等性
6.1 幂等性
幂等性即对数据进行若干次操作,仍然保证正确。
消费端实现幂等性,就意味着,我们的消息永远不会消费多次,即使收到多条一样的消息。
6.2 解决方案
业界主流的幂等性操作:
唯一ID+指纹码机制
利用Redis的原子性实现
1、唯一ID+指纹码机制
使用唯一ID不能保证唯一性(用户可能在短时间内执行多次消费),还需要一个指纹码(这个可能是业务规则,比如时间戳等生成的,也可以是数据库主键)。
执行SQL:
SELECTCOUNT(1)FROMT_ORDERWHEREID=唯一ID+指纹码
如果返回0可以执行ISNERT操作,如果返回1则不执行。
优点:
实现简单
缺点:
高并发下有数据库写入的性能瓶颈
解决方案:
跟进ID进行分库分表进行算法路由
2、利用Redis的原子性实现
借助Redis本身的原子性操作实现。使用Redis进行幂等,需要考虑的问题:
1、我们是否要进行数据落库,如果落库的话,关键解决的问题是数据库和缓存如何做到原子性?
2、如果不进行落库,那么都存储在缓存中,如何设置定时同步的策略?
07 消息投递
7.1 Confirm确认消息
消息的确认,是指生产者投递消息后,如果Broker收到消息,则会给我们生产者一个应答。
生产者进行接收应答,用来确定这个消息是否正常的发送到Broker,这种方式也是消息的可靠性投递的核心保证!

如何实现Confirm确认消息?
1、在channel上开启确认模式:channel.confirmSelect()
2、在channel上添加监听addConfirmListener,监听成功和失败的返回结果,根据具体的结果对消息进行重新发送、或记录日志等后续处理。
7.2 Return返回消息
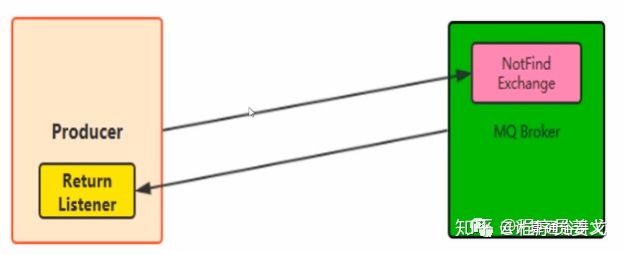
Return Listener用于处理一些不可路由的消息!
我们的消息生产者通过指定一个Exchange和RoutingKey,把消息送到到某一个队列中去,然后我们的消费者监听队列,进行消费处理操作。
但是在某些情况下,如果我们在发送消息的时候,当前的Exchange不存在或者指定的路由key路由不到,这个时候如果我们需要监听这种不可达的消息,就要使用Return Listener。
08 消息端限流
假设这样一个场景,首先,RabbitMQ服务器有上万条未处理的消息,我们随便打开一个消费者客户端,会出现下面情况:巨量的消息瞬间全部推送过来,但是我们单个客户端无法同时处理这么多数据。
RabbitMQ提供了一种QOS(服务质量保证)功能,即在非自动确认消息的前提下,如果一定数目的消息(通过基于consumer或者channel设置Qos的值)未被确认前,不进行消费新的消息。
09 消息端确认
消费端进行消费的时候,如果由于业务异常我们可以进行日志的记录,然后进行补偿。如果由于服务器宕机等严重问题,那我们就需要手工进行ACK保障消费端消费成功。
消息确认ACK:如果在处理消息的过程中,消费者的服务器在处理消息时出现异常,那可能这条正在处理的消息就没有完成消息消费,数据就会丢失。为了确保数据不会丢失,RabbitMQ支持消息确认ACK。
ACK的消息确认机制是消费者从RabbitMQ收到消息并处理完成后,反馈给RabbitMQ,RabbitMQ收到反馈后才将此消息从队列中删除。
1、如果一个消费者在处理消息出现了网络不稳定、服务器异常等现象,那么就不会有ACK反馈,RabbitMQ会认为这个消息没有正常消费,会将消息重新放入队列中。
2、如果在集群的情况下:RabbitMQ会立即将这个消息推送给这个在线的其他消费者。这种机制保证了在消费者服务器故障的时候,不丢失任何消息和任务。
3、消息永远不会从RabbitMQ中删除:只有当消费者正确发送ACK反馈,RabbitMQ确认收到后,消息才会从RabbitMQ服务器的数据中删除;
4、消息的ACK确认机制默认是打开的。
ACK机制的开发注意事项:
如果忘记了ACK,那么后果很严重。当Consumer退出时,Message会一直重新分发,然后RabbitMQ会占用越来越多的额内存,由于RabbitMQ会长时间运行,因此这个“内存泄露”是致命的。
10 重回队列/TTL队列/死信队列
10.1 重回队列机制
消费端重回队列是为了对没有处理成功的消息,把消息重新递给Broker。
一般在实际应用中,都会关闭重回队列,也就是设置为false。
10.2 TTL队列/消息
TTL是Time To Live的缩写,也就是生存时间。
RabbitMQ支持消息的过期时间,在消息发送时可以进行指定。
RabbitMQ支持队列的过期时间,从消息入队列开始计算,只要超过了队列的超时时间配置,那么消息会自动的清除。
10.3 死信队列
死信队列(DLX,Dead-Letter-Exchange)。利用DLX,当消息在一个队列中变成死信(dead message)之后,它能被重新publish到另一个Exchange,这个Exchange就是DLX。
消息变成死信的几种情况:
1、 消息被拒绝(basic.reject/basic.nack)并且request=false;
2、 消息TTL过期;
3、 队列达到最大长度。
DLX也是一个正常的Exchange,和一般的Exchange没有区别,它能在任何的队列上被指定,实际上就是设置某个队列的属性。
当这个队列中有死信时,RabbitMQ就会自动的将这个消息重新分布到设置的Exchange上去,进而被路由到另一个队列。
可以监听这个队列中消息做相应的处理,这个特性可以弥补RabbitMQ3.0以前的immediate参数的功能。
死信队列的设置:
1、首先,需要设置死信队列的Exchange和queue,然后进行绑定:
Exchange:dlx.exchangeQueue:dlx.queueRoutingKey:#
2、然后,我们进行正常声明交换机、队列、绑定,只不过我们需要在队列机上一个参数即可:arguments.put(“x-dead-letter-exchange”,”dlx.exchange”);这样消息在过期、requeue、队列在达到最大长度时,消息就可以直接路由到死信队列。
11 RabbitMQ常用命令
rabbitmqctl stop_app:关闭应用
rabbitmqctl start_app:启动应用
rabbitmqctl status:节点状态
rabbitmqctl add_user username password:添加用户
rabbitmqctl list_users:列出所有用户
rabbitmqctl delete_user username:删除用户
rabbitmqctl clear_permissions -p vhostpath username:清除用户权限
rabbitmqctl list_user_permissions username:列出用户权限
rabbitmqctl change_password username newpassword:修改密码
rabbitmqctlset_permission -p vhostpath username “.*”“.*”“.*”:设置用户权限