Redis的全称是REmote Dictionary Server,它主要提供了5种数据结构:字符串、哈希、列表、集合、有序集合,同时在字符串的基础之上演变 出了位图(Bitmaps)和HyperLogLog两种神奇的“数据结构”,并且随着 LBS(Location Based Service,基于位置服务)的不断发展,Redis3.2版本中 加入有关GEO(地理信息定位)的功能
哈希
几乎所有的编程语言都提供了哈希(hash)类型,它们的叫法可能是哈 希、字典、关联数组。在Redis中,哈希类型是指键值本身又是一个键值对 结构,形如value={{field1,value1},...{fieldN,valueN}}

注意
哈希类型中的映射关系叫作field-value,注意这里的value是指field对应 的值,不是键对应的值
命令
设置值,获取值
设置值
hset key field value
获取值
hget key field
实例
127.0.0.1:6379> hset user1 name nerrys
(integer) 1
127.0.0.1:6379> hget user1 name
"nerrys"
键或field不存在
如果键或field不存在,会返回nil:
127.0.0.1:6379> hget user2 name
(nil)
删除field
hdel key field [field ...]
实例
127.0.0.1:6379> hdel user1 name
(integer) 1
127.0.0.1:6379> hget user1 name
(nil)
计算field个数
hlen key
实例
127.0.0.1:6379> hget user1 name
"nerrys"
127.0.0.1:6379> hget user1 age
"22"
127.0.0.1:6379> hget user1 sex
"man"
127.0.0.1:6379> hget user1 city
"beijing"
127.0.0.1:6379> hlen user1
(integer) 4
批量设置或获取field-value
hmget key field [field ...]
hmset key field value [field value ...]
hmset和hmget分别是批量设置和获取field-value,
hmset需要的参数是key 和多对field-value,hmget需要的参数是key和多个field。
实例
127.0.0.1:6379> hmget user name user2 22 sex
- "nerrys"
- "age"
- "user3"
- "man"
127.0.0.1:6379> hmset user1 name nerrys age 22 sex man city beijing
OK
127.0.0.1:6379> hmget user1 name age sex city - "nerrys"
- "22"
- "man"
- "beijing"
判断field是否存在
hexists key field
实例
127.0.0.1:6379> hexists user1 name
(integer) 1
获取所有field
hkeys key
实例
127.0.0.1:6379> hkeys user1
- "name"
- "age"
- "sex"
- "city"
获取所有value
hvals key
实例
127.0.0.1:6379> hvals user1
- "nerrys"
- "22"
- "man"
- "beijing"
获取所有的field-value
hgetall key
实例
127.0.0.1:6379> hgetall user1
- "name"
- "nerrys"
- "age"
- "22"
- "sex"
- "man"
- "city"
- "beijing"
注意:
在使用hgetall时,如果哈希元素个数比较多,会存在阻塞Redis的可能
hincrby hincrbyfloat
hincrby key field
hincrbyfloat key field
hincrby和hincrbyfloat,就像incrby和incrbyfloat命令一样,但是它们的作用域是filed。
实例
127.0.0.1:6379> hincrby user1 age 1
(integer) 23
127.0.0.1:6379> hget user1 age
"23"
计算value的字符串长度
hstrlen key field
实例
127.0.0.1:6379> hstrlen user1 name
(integer) 6
127.0.0.1:6379> hget user1 name
"nerrys"
内部编码
哈希类型的内部编码有两种:
·ziplist(压缩列表):当哈希类型元素个数小于hash-max-ziplist-entries 配置(默认512个)、同时所有值都小于hash-max-ziplist-value配置(默认64 字节)时,Redis会使用ziplist作为哈希的内部实现,ziplist使用更加紧凑的 结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀。
·hashtable(哈希表):当哈希类型无法满足ziplist的条件时,Redis会使 用hashtable作为哈希的内部实现,因为此时ziplist的读写效率会下降,而 hashtable的读写时间复杂度为O(1)。
测试
127.0.0.1:6379> object encoding user1
"ziplist"
当有value大于64字节,内部编码会由ziplist变为hashtable:
127.0.0.1:6379> hset hashkey f1 thishashkeyisbetterthan64byteisisisisisiisisisisisiisisisisisisisiisisisisiisisisisiisisisisisisisiisisisisisiisis
(integer) 1
127.0.0.1:6379> object encoding hashkey
"hashtable"
当field个数超过512,内部编码也会由ziplist变为hashtable:
127.0.0.1:6379> hmset hashkey f1 v1 f2 v2 f3 v3 ...忽略... f513 v513(太长了)
使用场景
1.对关系型数据库的数据存储
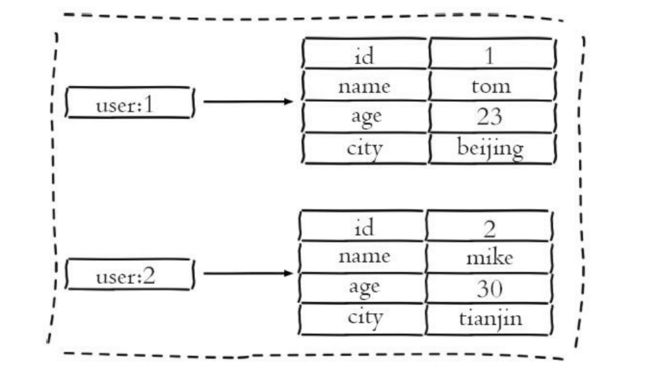
相比于使用字符串序列化缓存用户信息,哈希类型变得更加直观,并且在更新操作上会更加便捷。可以将每个用户的id定义为键后缀,多对field- value对应每个用户的属性
·哈希类型是稀疏的,而关系型数据库是完全结构化的,例如哈希类型 每个键可以有不同的field,而关系型数据库一旦添加新的列,所有行都要为 其设置值(即使为NULL)
·关系型数据库可以做复杂的关系查询,而Redis去模拟关系型复杂查询 开发困难,维护成本高。
列表
列表(list)类型是用来存储多个有序的字符串,如a、 b、c、d、e五个元素从左到右组成了一个有序的列表,列表中的每个字符串 称为元素(element),一个列表最多可以存储2^32-1个元素。在Redis中,可 以对列表两端插入(push)和弹出(pop),还可以获取指定范围的元素列 表、获取指定索引下标的元素等。列表是一种比较灵活的数据结构,它可以充当栈和队列的角色,在实际开发上有很多应用场景。
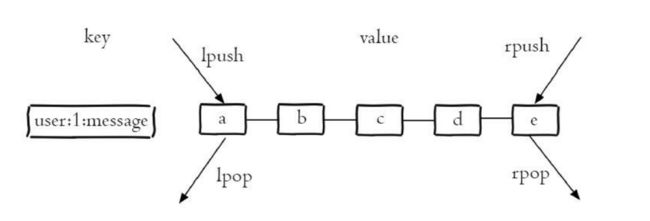
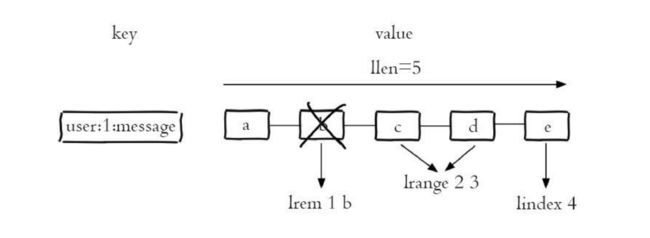
列表类型有两个特点:第一、列表中的元素是有序的,这就意味着可以 通过索引下标获取某个元素或者某个范围内的元素列表,例如要获取图的第5个元素,可以执行lindex user:1:message4(索引从0算起)就可以得 到元素e。第二、列表中的元素可以是重复的,例如图所示列表中包含 了两个字符串a。

命令
添加操作
(1)从右边插入元素
rpush key value [value ...]
lrange0-1命令可以从左到右获取列表的所有元素
命令
127.0.0.1:6379> rpush listkey a b c
(integer) 3
127.0.0.1:6379> lrange listkey 0 -1
- "a"
- "b"
- "c"
(2)从左边插入元素
lpush key value [value ...]
127.0.0.1:6379> lpush listkey1 a b c
(integer) 3
127.0.0.1:6379> lrange listkey1 0 -1
- "c"
- "b"
- "a"
(3)向某个元素前或者后插入元素
linsert key before|after pivot value
linsert命令会从列表中找到等于pivot的元素,在其前(before)或者后 (after)插入一个新的元素value
127.0.0.1:6379> linsert listkey before b e
(integer) 4
127.0.0.1:6379> lrange listkey 0 -1
- "a"
- "e"
- "b"
- "c"
查找
(1)获取指定范围内的元素列表
lrange key start end
lrange操作会获取列表指定索引范围所有的元素。索引下标有两个特点:
- 第一,索引下标从左到右分别是0到N-1,但是从右到左分别是-1到-N。
- 第二,lrange中的end选项包含了自身
127.0.0.1:6379> lrange listkey 1 3
- "e"
- "b"
- "c"
(2)获取列表指定索引下标的元素
lindex key index
实例
127.0.0.1:6379> lindex listkey 0
"a"
(3)获取列表长度
llen key
实例
127.0.0.1:6379> llen listkey
(integer) 4
删除
(1)从列表左侧弹出元素
lpop key
实例
127.0.0.1:6379> lpop listkey
"a"
127.0.0.1:6379> lrange listkey 0 -1
- "e"
- "b"
- "c"
(2)从列表右侧弹出
rpop key
实例
127.0.0.1:6379> rpop listkey
"c"
127.0.0.1:6379> lrange listkey 0 -1
- "e"
- "b"
(3)删除指定元素
lrem key count value
lrem命令会从列表中找到等于value的元素进行删除,根据count的不同分为三种情况:
- count>0,从左到右,删除最多count个元素。
- count<0,从右到左,删除最多count绝对值个元素。
- count=0,删除所有。
实例
127.0.0.1:6379> lpush listdel a a a b b b c c c
(integer) 9
127.0.0.1:6379> lrange listdel 0 -1
- "c"
- "c"
- "c"
- "b"
- "b"
- "b"
- "a"
- "a"
- "a"
127.0.0.1:6379> lrem listdel 2 a
(integer) 2
127.0.0.1:6379> lrange listdel 0 -1 - "c"
- "c"
- "c"
- "b"
- "b"
- "b"
- "a"
(4)按照索引范围修剪列表
ltrim key start end
127.0.0.1:6379> lrange listdel 0 -1
- "c"
- "c"
- "c"
- "b"
- "b"
- "b"
- "a"
127.0.0.1:6379> ltrim listdel 2 4
OK
127.0.0.1:6379> lrange listdel 0 -1 - "c"
- "b"
- "b"
修改
修改指定索引下标的元素:
lset key index newValue
实例
127.0.0.1:6379> lset listdel 0 a
OK
127.0.0.1:6379> lrange listdel 0 -1 - "a"
- "b"
- "b"
阻塞操作
blpop key [key ...] timeout
brpop key [key ...] timeout
blpop和brpop是lpop和rpop的阻塞版本,它们除了弹出方向不同,使用方法基本相同,所以下面以brpop命令进行说明,brpop命令包含两个参数: ·key[key...]:多个列表的键。 ·timeout:阻塞时间(单位:秒)。
1)列表为空:如果timeout=3,那么客户端要等到3秒后返回,如果 timeout=0,那么客户端一直阻塞等下去:
实例
127.0.0.1:6379> lrange empty 0 -1
(empty array)
127.0.0.1:6379> brpop empty 3
(nil)
(3.08s)
2)列表不为空:客户端会立即返回
实例
127.0.0.1:6379> brpop listdel 0
- "listdel"
- "b"
使用brpop时,有两点需要注意。 第一点,如果是多个键,那么brpop会从左至右遍历键,一旦有一个键能弹出元素,客户端立即返回
如果多个客户端对同一个键执行brpop,那么最先执行brpop命令的客户端可以获取到弹出的值
内部编码
列表类型的内部编码有两种。
- ziplist(压缩列表):当列表的元素个数小于list-max-ziplist-entries配置 (默认512个),同时列表中每个元素的值都小于list-max-ziplist-value配置时 (默认64字节),Redis会选用ziplist来作为列表的内部实现来减少内存的使 用。
- linkedlist(链表):当列表类型无法满足ziplist的条件时,Redis会使用 linkedlist作为列表的内部实现。
quicklist内部编码,简单地说它是以一个ziplist为节 点的linkedlist,它结合了ziplist和linkedlist两者的优势,为列表类型提供了一 种更为优秀的内部编码实现
实例
127.0.0.1:6379> object encoding code
"quicklist"
使用场景
1.消息队列
Redis的lpush+brpop命令组合即可实现阻塞队列,生产 者客户端使用lrpush从列表左侧插入元素,多个消费者客户端使用brpop命令 阻塞式的“抢”列表尾部的元素,多个客户端保证了消费的负载均衡和高可用性
2.文章列表
实际上列表的使用场景很多,在选择时可以参考以下:
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpsh+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
集合
集合(set)类型也是用来保存多个的字符串元素,但和列表类型不一 样的是,集合中不允许有重复元素,并且集合中的元素是无序的,不能通过 索引下标获取元素。一个集合最多可以存储2^32-1个元 素。Redis除了支持集合内的增删改查,同时还支持多个集合取交集、并 集、差集
命令
集合内操作
(1)添加元素
sadd key element [element ...]
127.0.0.1:6379> sadd myset a b c
(integer) 3
127.0.0.1:6379> sadd myset a b c
(integer) 3
127.0.0.1:6379> smembers myset
- "c"
- "a"
- "b"
(2)删除元素
srem key element [element ...]
127.0.0.1:6379> srem myset a b
(integer) 2
127.0.0.1:6379> smembers myset
- "c"
(3)计算元素个数
scard key
scard的时间复杂度为O(1),它不会遍历集合所有元素,而是直接用 Redis内部的变量
127.0.0.1:6379> scard myset
(integer) 1
(4)判断元素是否在集合中
sismember key element
127.0.0.1:6379> sismember myset c
(integer) 1
(5)随机从集合返回指定个数元素
srandmember key [count]
[count]是可选参数,如果不写默认为1
实例
127.0.0.1:6379> sismember myset c
(integer) 1
127.0.0.1:6379> srandmember set 2
- "a"
- "b"
127.0.0.1:6379> srandmember set 2 - "c"
- "a"
(6)从集合随机弹出元素
spop key
实例
127.0.0.1:6379> spop set
"b"
127.0.0.1:6379> spop set
"a"
(7)获取所有元素
smembers key
集合间操作
先add两个集合
127.0.0.1:6379> sadd user:a it is a man
(integer) 4
127.0.0.1:6379> sadd user:b this is a girl
(integer) 4
(1)求多个集合的交集
sinter key [key ...]
实例
127.0.0.1:6379> sinter user:a user:b
- "a"
- "is"
(2)求多个集合的并集
sunion key [key ...]
实例
127.0.0.1:6379> sunion user:a user:b
- "this"
- "girl"
- "is"
- "a"
(3)求多个集合的差集
sdiff key [key ...]
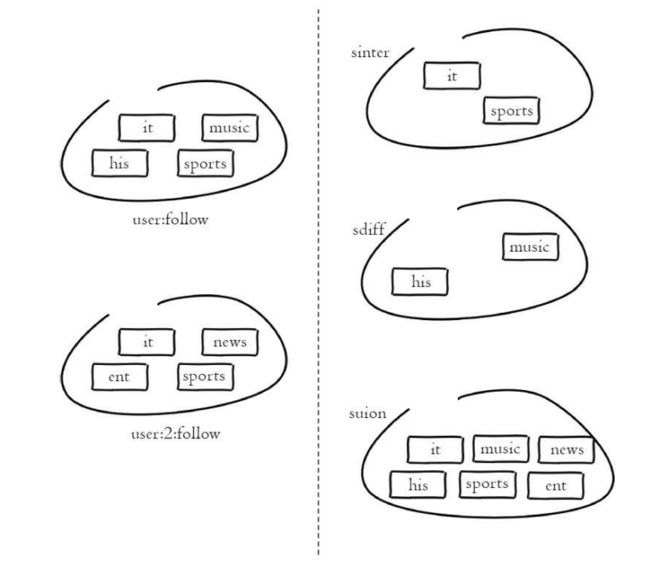
(4)将交集、并集、差集的结果保存
sinterstore destination key [key ...]
suionstore destination key [key ...]
sdiffstore destination key [key ...]
集合间的运算在元素较多的情况下会比较耗时,所以Redis提供了上面 三个命令(原命令+store)将集合间交集、并集、差集的结果保存在 destination key
内部编码
集合类型的内部编码有两种:
- intset(整数集合):当集合中的元素都是整数且元素个数小于set-max- intset-entries配置(默认512个)时,Redis会选用intset来作为集合的内部实 现,从而减少内存的使用。
- hashtable(哈希表):当集合类型无法满足intset的条件时,Redis会使 用hashtable作为集合的内部实现。
1)当元素个数较少且都为整数时,内部编码为intset
2)当元素个数超过512个,内部编码变为hashtable
3)当某个元素不为整数时,内部编码也会变为hashtable
使用场景
给用户添加标签,给标签添加用户,etc
有序集合
有序集合相对于哈希、列表、集合来说会有一点点陌生,但既然叫有序 集合,那么它和集合必然有着联系,它保留了集合不能有重复成员的特性, 但不同的是,有序集合中的元素可以排序。但是它和列表使用索引下标作为 排序依据不同的是,它给每个元素设置一个分数(score)作为排序的依 据。如图2-24所示,该有序集合包含kris、mike、frank、tim、martin、tom, 它们的分数分别是1、91、200、220、250、251,有序集合提供了获取指定 分数和元素范围查询、计算成员排名等功能

有序集合中的元素不能重复,但是score可以重复
命令
集合内
(1)添加成员
zadd key score member [score member ...]
127.0.0.1:6379> zadd zset 175 bob
(integer) 1
有关zadd命令有两点需要注意: nx、xx、ch、incr四个选项:
- nx:member必须不存在,才可以设置成功,用于添加。
- xx:member必须存在,才可以设置成功,用于更新。
- ch:返回此次操作后,有序集合元素和分数发生变化的个数
- incr:对score做增加
有序集合相比集合提供了排序字段,但是也产生了代价,zadd的时间 复杂度为O(log(n)),sadd的时间复杂度为O(1)
(2)计算成员个数
zcard key
实例
127.0.0.1:6379> zcard zset
(integer) 3
(3)计算某个成员的分数
zscore key member
实例
127.0.0.1:6379> zscore zset member
(nil)
127.0.0.1:6379> zscore zset bob
"175"
(4)计算成员的排名
zrank key member
zrevrank key member
zrank是从分数从低到高返回排名,zrevrank反之。
实例
127.0.0.1:6379> zrank zset bob
(integer) 0
127.0.0.1:6379> zrevrank zset bob
(integer) 2
(5)删除成员
zrem key member [member ...]
实例
127.0.0.1:6379> zrem zset bob
(integer) 1
(6)增加成员的分数
zincrby key increment member
实例
127.0.0.1:6379> zincrby zset 20 lili
"200"
(7)返回指定排名范围的成员
zrange key start end [withscores]
zrevrange key start end [withscores]
有序集合是按照分值排名的,zrange是从低到高返回,zrevrange反之,如果加上withscores选项,同时会返 回成员的分数
实例
127.0.0.1:6379> zrange zset 0 1 withscores
- "ss"
- "190"
- "lili"
- "200"
(8)返回指定分数范围的成员
zrangebyscore key min max [withscores] [limit offset count]
zrevrangebyscore key max min [withscores] [limit offset count]
其中zrangebyscore按照分数从低到高返回,zrevrangebyscore反之,withscores选项会同时返回每个 成员的分数
同时min和max还支持开区间(小括号)和闭区间(中括号),-inf和 +inf分别代表无限小和无限大
实例
127.0.0.1:6379> zrangebyscore zset 180 190 withscores
- "ss"
- "190"
(9)返回指定分数范围成员个数
zcount key min max
实例
127.0.0.1:6379> zcount zset 180 200
(integer) 2
(10)删除指定排名内的升序元素
zremrangebyrank key start end
(11)删除指定分数范围的成员
zremrangebyscore key min max
集合间的操作
(1)交集
zinterstore destination numkeys key [key ...] [weights weight [weight ...]] [aggregate sum|min|max]
参数说明:
- destination:交集计算结果保存到这个键。
- numkeys:需要做交集计算键的个数。
- key[key...]:需要做交集计算的键。
- weights weight[weight...]:每个键的权重,在做交集计算时,每个键中 的每个member会将自己分数乘以这个权重,每个键的权重默认是1。
- aggregate sum|min|max:计算成员交集后,分值可以按照sum(和)、 min(最小值)、max(最大值)做汇总,默认值是sum。
(2)并集
zunionstore destination numkeys key [key ...] [weights weight [weight ...]] [aggregate sum|min|max]
该命令的所有参数和zinterstore是一致的,只不过是做并集计算
内部编码
有序集合类型的内部编码有两种:
- ziplist(压缩列表):当有序集合的元素个数小于zset-max-ziplist- entries配置(默认128个),同时每个元素的值都小于zset-max-ziplist-value配 置(默认64字节)时,Redis会用ziplist来作为有序集合的内部实现,ziplist 可以有效减少内存的使用。
- skiplist(跳跃表):当ziplist条件不满足时,有序集合会使用skiplist作 为内部实现,因为此时ziplist的读写效率会下降。
1)当元素个数较少且每个元素较小时,内部编码为ziplist
127.0.0.1:6379> object encoding zset
"ziplist"
2)当元素个数超过128个,内部编码变为skiplist
使用场景
(1)添加用户赞数,(2)取消用户赞数 等等
关于字符串的介绍,见合集中
redis字符串理解