Runtime源码剖析---图解Category
源码面前,了无秘密
无论一个类设计的多么完美,在未来的需求演进中,都有可能会碰到一些无法预测的情况。那怎么扩展已有的类呢?一般而言,继承和组合是不错的选择。但是在Objective-C 2.0中,又提供了category这个语言特性,可以动态地为已有类添加新行为。
什么是Category?
category 的主要作用是为已经存在的类添加方法。
可以把类的实现分开在几个不同的文件里面。这样做有几个显而易见的好处。
- 把不同的功能组织到不同的
category里,减少单个文件的体积,且易于维护; - 可以由多个开发者共同完成一个类;
- 可以按需加载想要的
category; - 声明私有方法;
不过除了 apple 推荐的使用场景,还衍生出了category 的其他几个使用场景:
- 模拟多继承(另外可以模拟多继承的还有 protocol)
- 把
framework的私有方法公开
extension
extension被开发者称之为扩展、延展、匿名分类。extension看起来很像一个匿名的category,但是extension和category几乎完全是两个东西。和
category不同的是extension不但可以声明方法,还可以声明属性、成员变量。extension一般用于声明私有方法,私有属性,私有成员变量。使用
extension必须有原有类的源码。extension声明的方法、属性和成员变量必须在类的主@implementation区间内实现,可以避免使用有名称的category带来的多个不必要的implementation段。extension很常见的用法,是用来给类添加私有的变量和方法,用于在类的内部使用。例如在@interface中定义为readonly类型的属性,在实现中添加extension,将其重新定义为readwrite,这样我们在类的内部就可以直接修改它的值,然而外部依然不能调用setter方法来修改。
category 与 extension 的区别
category 和 extension 的区别:
-
extension可以添加实例变量,而category是无法添加实例变量的。 -
extension在编译期决议,是类的一部分,category则在运行期决议。extension在编译期和头文件里的@interface以及实现文件里的@implement一起形成一个完整的类,extension伴随类的产生而产生,亦随之一起消亡。 -
extension一般用来隐藏类的私有信息,你必须有一个类的源码才能为一个类添加extension,所以你无法为系统的类比如NSString添加extension,除非创建子类再添加extension。而category不需要有类的源码,我们可以给系统提供的类添加category。 -
extension和category都可以添加属性,但是category的属性不能生成成员变量和getter、setter方法的实现。
Category的实质
category_t 结构体
struct category_t {
const char *name;//类的名字
classref_t cls;//类
struct method_list_t *instanceMethods;//实例方法列表
struct method_list_t *classMethods;//类方法列表
struct protocol_list_t *protocols;//协议列表
struct property_list_t *instanceProperties;//属性列表
struct property_list_t *_classProperties;
method_list_t *methodsForMeta(bool isMeta) {
if (isMeta) return classMethods;
else return instanceMethods;
}
property_list_t *propertiesForMeta(bool isMeta, struct header_info *hi);
};
- 从源码基本可以看出我们平时使用
categroy的方式,对象方法,类方法,协议,和属性都可以找到对应的存储方式。并且我们发现分类结构体中是不存在成员变量的,因此分类中是不允许添加成员变量的。分类中添加的属性并不会帮助我们自动生成成员变量,只会生成get、set方法的声明,需要我们自己去实现。
分类如何存储在类对象中
- 我们先写一个分类,看看分类到底是何方妖魔
#import
@interface BFPerson : NSObject
@property (nonatomic, assign)NSInteger age;
- (void)test;
@end
@interface BFPerson (Work)
@property (nonatomic, assign) double workAge;
- (void)work;
+ (void)workIn:(NSString *)city;
- (void)test;
@end
@interface BFPerson (Study)
@property (nonatomic, copy) NSString *lesson;
@property (nonatomic, assign) NSInteger classNo;
- (void)study;
+ (void)studyLession:(NSString *)les;
- (void)test;
@end
- 我们再通过命令行将
BFPerson+Study.m文件转换成c++文件
clang -rewrite-objc Person+Study.m
- 在分类转化为c++文件中可以看出
_category_t结构体中,存放着类名,对象方法列表,类方法列表,协议列表,以及属性列表。
struct _category_t {
const char *name;
struct _class_t *cls;
const struct _method_list_t *instance_methods;
const struct _method_list_t *class_methods;
const struct _protocol_list_t *protocols;
const struct _prop_list_t *properties;
};
- 接着我们查看
_method_list_t类型的结构体
static struct /*_method_list_t*/ {
unsigned int entsize; //内存
unsigned int method_count; //方法数量
struct _objc_method method_list[1]; //方法列表
} _OBJC_$_CATEGORY_INSTANCE_METHODS_BFPerson_$_Study __attribute__ ((used, section ("__DATA,__objc_const"))) = {
sizeof(_objc_method),
1,
{{(struct objc_selector *)"study", "v16@0:8", (void *)_I_BFPerson_Study_study}}
};
上面我们发现这个结构体_OBJC_$_CATEGORY_INSTANCE_METHODS_BFPerson_$_Study从名称上可以看出是INSTANCE_METHODS对象方法,并且一一对应为上面结构体内赋值。并从赋值中找到了我们实现的对象方法stduy
- 接着我们发现同样的
_method_list_t类型的类方法结构体
static struct /*_method_list_t*/ {
unsigned int entsize; // sizeof(struct _objc_method)
unsigned int method_count;
struct _objc_method method_list[1];
} _OBJC_$_CATEGORY_CLASS_METHODS_BFPerson_$_Study __attribute__ ((used, section ("__DATA,__objc_const"))) = {
sizeof(_objc_method),
1,
{{(struct objc_selector *)"studyLession:", "v24@0:8@16", (void *)_C_BFPerson_Study_studyLession_}}
};
同上面对象方法列表一样,这个我们可以看出是类方法列表结构体_OBJC_$_CATEGORY_CLASS_METHODS_BFPerson_$_Study,同对象方法一样,同样可以看到我们实现的类方法studyLession
- 接下来是属性方法列表
static struct /*_prop_list_t*/ {
unsigned int entsize; // sizeof(struct _prop_t)
unsigned int count_of_properties;
struct _prop_t prop_list[2];
} _OBJC_$_PROP_LIST_BFPerson_$_Study __attribute__ ((used, section ("__DATA,__objc_const"))) = {
sizeof(_prop_t),
2,
{{"lesson","T@\"NSString\",C,N"},
{"classNo","Tq,N"}}
};
属性列表结构体_OBJC_$_PROP_LIST_BFPerson_$_Study存储属性数量、以及属性列表,我们可以发现我们自己写的lesson 和classNo属性
- 最后我们可以看到定义了
_OBJC_$_CATEGORY_BFPerson_$_Study结构体,并且将我们上面的结构体一一赋值
static struct _category_t _OBJC_$_CATEGORY_BFPerson_$_Study __attribute__ ((used, section ("__DATA,__objc_const"))) =
{
"BFPerson",
0, // &OBJC_CLASS_$_BFPerson,
(const struct _method_list_t *)&_OBJC_$_CATEGORY_INSTANCE_METHODS_BFPerson_$_Study,
(const struct _method_list_t *)&_OBJC_$_CATEGORY_CLASS_METHODS_BFPerson_$_Study,
0,
(const struct _prop_list_t *)&_OBJC_$_PROP_LIST_BFPerson_$_Study,
};
//将_OBJC_$_CATEGORY_BFPerson_$_Study的cls指针指向OBJC_CLASS_$_BFPerson结构的地址
static void OBJC_CATEGORY_SETUP_$_BFPerson_$_Study(void ) {
_OBJC_$_CATEGORY_BFPerson_$_Study.cls = &OBJC_CLASS_$_BFPerson;
}
我们这里可以看出,cls指针指向的应该是分类的主类类对象的地址
- 通过上面分析我们发现。分类源码中确实是将我们定义的对象方法,类方法,属性等都存放在catagory_t结构体中。
- 接下来我们在回到runtime源码查看catagory_t存储的方法,属性,协议等是如何存储在类对象中的。
category运行期
分类在运行期做了什么
- runtime 会加载某个类的所有 category 数据;
- 将所有 category 的方法(对象方法、类方法)、属性、协议数据,合并到一个大数组中
- 后面参与编译的 category 数据,会在合并数组的前面;
- 将合并后的分类数据(方法、属性、协议),插入到类原来数据的前面;
运行流程
- 首先来到
runtime初始化函数
void _objc_init(void)
{
static bool initialized = false;
if (initialized) return;
initialized = true;
// fixme defer initialization until an objc-using image is found?
environ_init();
tls_init();
static_init();
lock_init();
exception_init();
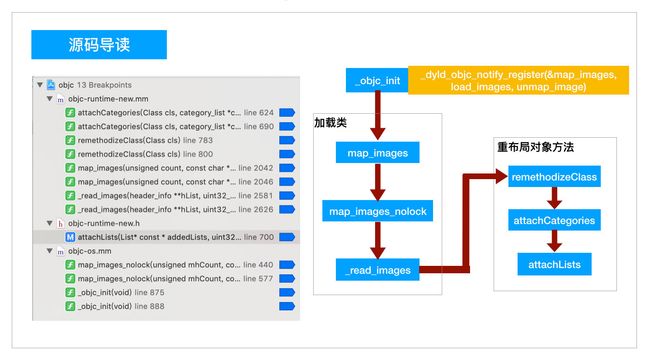
// _objc_init->map_images->map_images_nolock->_read_images->realizeClass
_dyld_objc_notify_register(&map_images, load_images, unmap_image);
}
- 接下来我们来到
&map_images读取模块(images这里代表模块),然后来到map_images_nolock函数中找到_read_images函数,在_read_images函数中找到分类相关代码
// Discover categories.
//外部循环遍历所有类,并取出当前类对应的catrgory数组
for (EACH_HEADER) {
category_t **catlist =
_getObjc2CategoryList(hi, &count);//编译器为我们准备的category_t数组
bool hasClassProperties = hi->info()->hasCategoryClassProperties();
//内部循环会遍历取出catrgory数组,将每个category_t对象取出,最终执行addUnattachedCategoryForClass函数添加到Category哈希表中
for (i = 0; i < count; i++) {
category_t *cat = catlist[i];
Class cls = remapClass(cat->cls);
if (!cls) {
// Category's target class is missing (probably weak-linked).
// Disavow any knowledge of this category.
catlist[i] = nil;
if (PrintConnecting) {
_objc_inform("CLASS: IGNORING category \?\?\?(%s) %p with "
"missing weak-linked target class",
cat->name, cat);
}
continue;
}
// Process this category.
// First, register the category with its target class.
// Then, rebuild the class's method lists (etc) if
// the class is realized.
bool classExists = NO;
if (cat->instanceMethods || cat->protocols
|| cat->instanceProperties)
{
addUnattachedCategoryForClass(cat, cls, hi);//只是把类和catrgory做一个关联映射
if (cls->isRealized()) {
remethodizeClass(cls);//真正处理添加事宜
classExists = YES;
}
if (PrintConnecting) {
_objc_inform("CLASS: found category -%s(%s) %s",
cls->nameForLogging(), cat->name,
classExists ? "on existing class" : "");
}
}
if (cat->classMethods || cat->protocols
|| (hasClassProperties && cat->_classProperties))
{
addUnattachedCategoryForClass(cat, cls->ISA(), hi);
if (cls->ISA()->isRealized()) {
remethodizeClass(cls->ISA());
}
if (PrintConnecting) {
_objc_inform("CLASS: found category +%s(%s)",
cls->nameForLogging(), cat->name);
}
}
}
}
我们可以看到最上面有一行注释:// Discover categories.,从这句话就可以看出这就是我们要找的处理Category模块了。
第一行代码我们拿到的catlist就是上节中讲到的编译器为我们准备的category_t数组,然后进行遍历,获取分类中的方法、协议、属性等。我们重点看这几行代码
if (cls->isRealized()) {
remethodizeClass(cls);//真正处理添加事宜
classExists = YES;
}
if (cls->ISA()->isRealized()) {
remethodizeClass(cls->ISA());//class的ISA指针指向的是元类对象
}
这几行代码关键函数remethodizeClass,通过函数名我们大概猜测这个方法是重新组织类中的方法,如果传入的是类,则重新组织对象方法,如果传入的是元类,则重新组织类方法。
- 下面我进入
remethodizeClass(cls)函数中
static void remethodizeClass(Class cls)
{
category_list *cats;
bool isMeta;
runtimeLock.assertLocked();
isMeta = cls->isMetaClass();
// Re-methodizing: check for more categories
// 从Category哈希表中查找category_t对象,并将已找到的对象从哈希表中删除
if ((cats = unattachedCategoriesForClass(cls, false/*not realizing*/))) {
if (PrintConnecting) {
_objc_inform("CLASS: attaching categories to class '%s' %s",
cls->nameForLogging(), isMeta ? "(meta)" : "");
}
//在attachCategories函数中,查找到Category的方法列表、属性列表、协议列表
attachCategories(cls, cats, true /*flush caches*/);
free(cats);
}
}
通过上述代码我们发现attachCategories函数接收了类对象cls和分类数组cats,如我们一开始写的代码所示,一个类可以有多个分类。之前我们说到分类信息存储在category_t结构体中,那么多个分类则保存在category_list中。
- 我们来到
attachCategories函数内部
//获取到catrgory的Protocol list、Property list、Method list,然后通过attachLists函数添加到所属的类中
static void
attachCategories(Class cls, category_list *cats, bool flush_caches)
{
if (!cats) return;
if (PrintReplacedMethods) printReplacements(cls, cats);
bool isMeta = cls->isMetaClass();
//按照Category个数,分配对应的内存空间
method_list_t **mlists = (method_list_t **)
malloc(cats->count * sizeof(*mlists));
property_list_t **proplists = (property_list_t **)
malloc(cats->count * sizeof(*proplists));
protocol_list_t **protolists = (protocol_list_t **)
malloc(cats->count * sizeof(*protolists));
// Count backwards through cats to get newest categories first
int mcount = 0;
int propcount = 0;
int protocount = 0;
int i = cats->count;
bool fromBundle = NO;
// 循环查找出Protocol list、Property list、Method list
// i-- 在category list最后面的,先添加到mlists
while (i--) {
auto& entry = cats->list[i];//遍历拿到每一个分类
//将所有分类中的方法存入在mlist数组中
method_list_t *mlist = entry.cat->methodsForMeta(isMeta);
if (mlist) {
mlists[mcount++] = mlist;
fromBundle |= entry.hi->isBundle();
}
//将所有分类中的所有属性存入proplist数组
property_list_t *proplist =
entry.cat->propertiesForMeta(isMeta, entry.hi);
if (proplist) {
proplists[propcount++] = proplist;
}
//将所有分类中所有协议存入protolists数组
protocol_list_t *protolist = entry.cat->protocols;
if (protolist) {
protolists[protocount++] = protolist;
}
}
//rw:class_rw_t结构体,class结构体中用来存储对象方法,属性、协议的结构体
auto rw = cls->data();
//将mlists数组传入rw->method的attachList函数,之后释放mlist
prepareMethodLists(cls, mlists, mcount, NO, fromBundle);
rw->methods.attachLists(mlists, mcount);
free(mlists);
if (flush_caches && mcount > 0) flushCaches(cls);
//将proplists数组传入rw->properties的attachLists函数,之后释放prolists
rw->properties.attachLists(proplists, propcount);
free(proplists);
//将protolists传入rw->protocols的attachLists函数,之后释放protplists
rw->protocols.attachLists(protolists, protocount);
free(protolists);
}
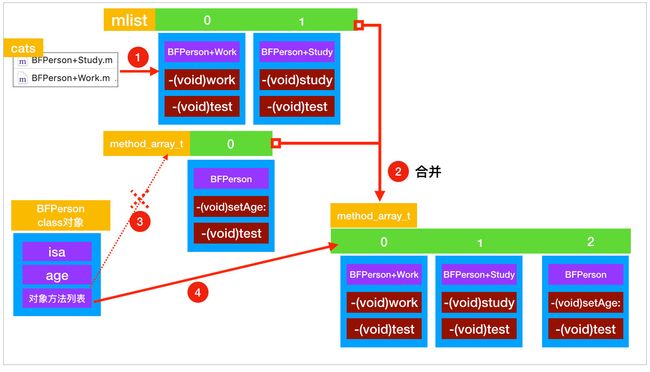
上述源码中可以看出,首先根据方法列表、属性列表、协议列表、malloc分配内存,根据多少个分类以及每一块方法需要多少内存来分配相应的内存地址。之后从分类数组里面往三个数组里面存放分类数组里面存放的分类方法,属性以及协议放入对应mlist、proplists、protolosts数组中,这三个数组放着所有分类的方法,属性和协议。
之后通过类对象的data()方法,拿到类对象的class_rw_t结构体rw,在class结构中我们介绍过,class_rw_t中存放着类对象的方法,属性和协议等数据,rw结构体通过类对象的data方法获取,所以rw里面存放这类对象里面的数据。
之后分别通过rw调用方法列表、属性列表、协议列表的attachList函数,将所有的分类的方法、属性、协议列表数组传进去,我们大致可以猜想到在attachList方法内部将分类和本类相应的对象方法,属性,和协议进行了合并。
- 我们来看一下
attachLists函数内部
void attachLists(List* const * addedLists, uint32_t addedCount) {
if (addedCount == 0) return;
if (hasArray()) {
// many lists -> many lists
//先获取原来已有的方法列表数量
uint32_t oldCount = array()->count;
//这是添加分类之后方法列表的数量
uint32_t newCount = oldCount + addedCount;
//重新分配内存
setArray((array_t *)realloc(array(), array_t::byteSize(newCount)));
array()->count = newCount;
//array()->lists:原来的列表数组
//内存移动,将array->lists的内存移动oldCount *sizeof(array()->lists[0])个内存到array()->lista+addedCound中
memmove(array()->lists + addedCount, array()->lists,
oldCount * sizeof(array()->lists[0]));
//addedList:分类的列表数组
//内存复制,将addedLists的内存复制addedCount *sizeof(array()->lists[0])个内存到array()->lists中
memcpy(array()->lists, addedLists,
addedCount * sizeof(array()->lists[0]));
}
else if (!list && addedCount == 1) {
// 0 lists -> 1 list
list = addedLists[0];
}
else {
// 1 list -> many lists
List* oldList = list;
uint32_t oldCount = oldList ? 1 : 0;
uint32_t newCount = oldCount + addedCount;
setArray((array_t *)malloc(array_t::byteSize(newCount)));
array()->count = newCount;
if (oldList) array()->lists[addedCount] = oldList;
memcpy(array()->lists, addedLists,
addedCount * sizeof(array()->lists[0]));
}
}
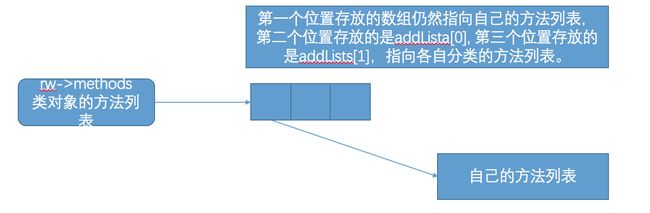
传进来的这个addedLists参数就是前面得到的这个类的所有分类的对象方法或者类方法,而addedCount就是addedLists这个数组的个数。假设这个类有两个分类,且每个分类有两个方法,那么addedLists的结构大概就应该是这样的:
[ [method, method] [method, method] ] addedCount = 2
我们看一下这个类方法列表之前的结构

所以oldCoutn = 1
//重新分配内存
setArray((array_t *)realloc(array(), array_t::byteSize(newCount)));
array()->count = newCount;
这一句是重新分配内存,由于要把分类的方法合并进来,所以以前分配的内存就不够了,重新分配后的内存:
attachLists函数中最重要的两个方法为memmove内存移动和memcpy内存拷贝。我们先来分别看一下这两个函数
// memmove :内存移动。
/* __dst : 移动内存的目的地
* __src : 被移动的内存首地址
* __len : 被移动的内存长度
* 将__src的内存移动__len块内存到__dst中
*/
void *memmove(void *__dst, const void *__src, size_t __len);
// memcpy :内存拷贝。
/* __dst : 拷贝内存的拷贝目的地
* __src : 被拷贝的内存首地址
* __n : 被移动的内存长度
* 将__src的内存移动__n块内存到__dst中
*/
void *memcpy(void *__dst, const void *__src, size_t __n);
下面我们图示经过memmove和memcpy方法过后的内存变化。

经过memmove方法之后,内存变化为
// array()->lists 原来方法、属性、协议列表数组
// addedCount 分类数组长度
// oldCount * sizeof(array()->lists[0]) 原来数组占据的空间
memmove(array()->lists + addedCount, array()->lists,
oldCount * sizeof(array()->lists[0]));

经过memmove方法之后,我们发现,虽然本类的方法,属性,协议列表会分别后移,但是本类的对应数组的指针依然指向原始位置。
memcpy方法之后,内存变化
// array()->lists 原来方法、属性、协议列表数组
// addedLists 分类方法、属性、协议列表数组
// addedCount * sizeof(array()->lists[0]) 原来数组占据的空间
memcpy(array()->lists, addedLists,
addedCount * sizeof(array()->lists[0]));

我们发现原来指针并没有改变,至始至终指向开头的位置。并且经过memmove和memcpy方法之后,分类的方法,属性,协议列表被放在了类对象中原本存储的方法,属性,协议列表前面。
至此就把分类中的方法列表合并到了类的方法列表中。
通过上面的合并过程我们也明白了,当分类和类中有同样的方法时,类中的方法并没有被覆盖,只是分类的方法被放在了类的方法前面,导致先找到了分类的方法,所以分类的方法就被执行了。源码执行流程图
- 分类合并到原类中的流程图
load与initialize的区别
load
-
load方法会在程序启动就会调用,当装载类信息的时候就会调用 - 调用过程和机制是怎么样的呢?我们找到
objc-os.mm这个文件,然后找到这个文件的void _objc_init(void)这个方法
// Runtime初始化方法
void _objc_init(void)
{
static bool initialized = false;
if (initialized) return;
initialized = true;
// fixme defer initialization until an objc-using image is found?
environ_init();
tls_init();
static_init();
lock_init();
exception_init();
// _objc_init->map_images->map_images_nolock->_read_images->realizeClass
_dyld_objc_notify_register(&map_images, load_images, unmap_image);
}
- 我们点进
load_images
void
load_images(const char *path __unused, const struct mach_header *mh)
{
// Return without taking locks if there are no +load methods here.
if (!hasLoadMethods((const headerType *)mh)) return;
recursive_mutex_locker_t lock(loadMethodLock);
// Discover load methods
{
mutex_locker_t lock2(runtimeLock);
prepare_load_methods((const headerType *)mh);
}
// Call +load methods (without runtimeLock - re-entrant)
//通过这个方法的名字就很清楚这个是加载load方法用的
call_load_methods();
}
- 我们进入
cal_load_methods()
void call_load_methods(void)
{
static bool loading = NO;
bool more_categories;
loadMethodLock.assertLocked();
// Re-entrant calls do nothing; the outermost call will finish the job.
if (loading) return;
loading = YES;
void *pool = objc_autoreleasePoolPush();
do {
// 1. Repeatedly call class +loads until there aren't any more
//先调用完所有的类的load方法,再调用分类的load方法
while (loadable_classes_used > 0) {
call_class_loads();//加载类的load方法
}
// 2. Call category +loads ONCE
more_categories = call_category_loads();//加载分类的load方法
// 3. Run more +loads if there are classes OR more untried categories
} while (loadable_classes_used > 0 || more_categories);
objc_autoreleasePoolPop(pool);
loading = NO;
}
- 我们点进
call_class_loads();这个方法查看对类的load方法的调用过程:
static void call_class_loads(void)
{
int i;
// Detach current loadable list.
struct loadable_class *classes = loadable_classes;
int used = loadable_classes_used;
loadable_classes = nil;
loadable_classes_allocated = 0;
loadable_classes_used = 0;
// Call all +loads for the detached list.
for (i = 0; i < used; i++) {
Class cls = classes[i].cls;
//load_method_t是一个指针类型,这一句是找到类中的load方法,并初始化一个指针指向它
load_method_t load_method = (load_method_t)classes[i].method;
if (!cls) continue;
if (PrintLoading) {
_objc_inform("LOAD: +[%s load]\n", cls->nameForLogging());
}
//通过load方法的地址来访问load方法
(*load_method)(cls, SEL_load);
}
// Destroy the detached list.
if (classes) free(classes);
}
- 然后我们再点进
call_category_loads()查看对分类的load方法的调用过程:
static bool call_category_loads(void)
{
int i, shift;
bool new_categories_added = NO;
// Detach current loadable list.
struct loadable_category *cats = loadable_categories;
int used = loadable_categories_used;
int allocated = loadable_categories_allocated;
loadable_categories = nil;
loadable_categories_allocated = 0;
loadable_categories_used = 0;
// Call all +loads for the detached list.
for (i = 0; i < used; i++) {
Category cat = cats[i].cat;
//跟前面加载类的load方法一样,创建一个指针指向分类的load方法
load_method_t load_method = (load_method_t)cats[i].method;
Class cls;
if (!cat) continue;
cls = _category_getClass(cat);
if (cls && cls->isLoadable()) {
if (PrintLoading) {
_objc_inform("LOAD: +[%s(%s) load]\n",
cls->nameForLogging(),
_category_getName(cat));
}
//通过方法地址来调用方法
(*load_method)(cls, SEL_load);
cats[i].cat = nil;
}
}
// Compact detached list (order-preserving)
shift = 0;
for (i = 0; i < used; i++) {
if (cats[i].cat) {
cats[i-shift] = cats[i];
} else {
shift++;
}
}
used -= shift;
// Copy any new +load candidates from the new list to the detached list.
new_categories_added = (loadable_categories_used > 0);
for (i = 0; i < loadable_categories_used; i++) {
if (used == allocated) {
allocated = allocated*2 + 16;
cats = (struct loadable_category *)
realloc(cats, allocated *
sizeof(struct loadable_category));
}
cats[used++] = loadable_categories[i];
}
// Destroy the new list.
if (loadable_categories) free(loadable_categories);
// Reattach the (now augmented) detached list.
// But if there's nothing left to load, destroy the list.
if (used) {
loadable_categories = cats;
loadable_categories_used = used;
loadable_categories_allocated = allocated;
} else {
if (cats) free(cats);
loadable_categories = nil;
loadable_categories_used = 0;
loadable_categories_allocated = 0;
}
if (PrintLoading) {
if (loadable_categories_used != 0) {
_objc_inform("LOAD: %d categories still waiting for +load\n",
loadable_categories_used);
}
}
return new_categories_added;
}
- 那么问题来了,同样是类方法,同样是分类中实现了类的方法,为什么load方法不像test方法一样,调用分类的实现,而是类和每个分类中的load方法都被调用了呢?load方法到底有什么不同呢?
因为load方法的调用并不是objc_msgSend机制,它是直接找到类的load方法的地址,然后调用类的load方法,然后再找到分类的load方法的地址,再去调用它。
而test方法是通过消息机制去调用的。首先找到类对象,由于test方法是类方法,存储在元类对象中,所以通过类对象的isa指针找到元类对象,然后在元类对象中寻找test方法,由于分类也实现了test方法,所以分类的test方法是在类的test方法的前面,首先找到了分类的test方法,然后去调用它。
有继承关系时load方法的调用顺序
通过上面的分析我们确定了load方法的一个调用规则:先调用所有类的load方法,然后再调用所有分类的load方法。
但是当我们无论怎样的编译顺序,总是父类的
load方法先调用,子类的load方法后调用。那么我们就需要思考一下是不是由于Student和Person之间的继承关系导致的呢?
为了搞清楚这个问题,我们只能从runtime的源码入手。我们在上边已经看到
void call_load_methods(void)这个方法了,现在我们回退到void load_images()方法
void
load_images(const char *path __unused, const struct mach_header *mh)
{
// Return without taking locks if there are no +load methods here.
if (!hasLoadMethods((const headerType *)mh)) return;
recursive_mutex_locker_t lock(loadMethodLock);
// Discover load methods
{
mutex_locker_t lock2(runtimeLock);
prepare_load_methods((const headerType *)mh);
}
// Call +load methods (without runtimeLock - re-entrant)
call_load_methods();
}
- 然后我们进入
prepare_load_methods这个方法
void prepare_load_methods(const headerType *mhdr)
{
size_t count, i;
runtimeLock.assertLocked();
classref_t *classlist =
_getObjc2NonlazyClassList(mhdr, &count);
//这一部分就是调整类在数组中的顺序,我们通过方法名也可以看出来
for (i = 0; i < count; i++) {
schedule_class_load(remapClass(classlist[i]));
}
category_t **categorylist = _getObjc2NonlazyCategoryList(mhdr, &count);
//这一部分是调整分类在数组中的顺序
for (i = 0; i < count; i++) {
category_t *cat = categorylist[i];
Class cls = remapClass(cat->cls);
if (!cls) continue; // category for ignored weak-linked class
realizeClass(cls);
assert(cls->ISA()->isRealized());
add_category_to_loadable_list(cat);
}
}
- 我们进入
schedule_class_load这个函数
static void schedule_class_load(Class cls)
{
if (!cls) return;
assert(cls->isRealized()); // _read_images should realize
if (cls->data()->flags & RW_LOADED) return;
// Ensure superclass-first ordering
//cls->superclass找到自己的父类,然后对父类对象调用schedule_class_load方法,这样一层一层找到自己的父类
schedule_class_load(cls->superclass);
//把类加入到数组中
add_class_to_loadable_list(cls);
cls->setInfo(RW_LOADED);
}
通过这个方法我们就可以很清晰的看到,当要把一个类加入最终的这个classes数组的时候,会先去上溯这个类的父类,先把父类加入这个数组。
由于在classes数组中父类永远在子类的前面,所以在加载类的load方法时一定是先加载父类的load方法,再加载子类的load方法。
- 类的load方法调用顺序搞清楚了我们再来看一下分类的load方法调用顺序
- 我们还是看一下
void prepare_load_methods(const headerType *mhdr)这个函数
void prepare_load_methods(const headerType *mhdr)
{
size_t count, i;
runtimeLock.assertLocked();
classref_t *classlist =
_getObjc2NonlazyClassList(mhdr, &count);
//这一部分就是调整类在数组中的顺序,我们通过方法名也可以看出来
for (i = 0; i < count; i++) {
schedule_class_load(remapClass(classlist[i]));
}
//根据编译顺序拿到分类列表
category_t **categorylist = _getObjc2NonlazyCategoryList(mhdr, &count);
//这一部分是调整分类在数组中的顺序
//把父类的添加进数组,然后分类直接添加进数组,不用考虑继承问题
for (i = 0; i < count; i++) {
category_t *cat = categorylist[i];
Class cls = remapClass(cat->cls);
if (!cls) continue; // category for ignored weak-linked class
realizeClass(cls);
assert(cls->ISA()->isRealized());
add_category_to_loadable_list(cat);
}
}
通过这个分析我们就能知道,分类的load方法加载顺序很简单,就是谁先编译的,谁的load方法就被先加载。
-
总结load方法调用顺序
1.先调用类的load方法
- 按照编译先后顺序调用(先编译,先调用)
- 调用子类的load方法之前会先调用父类的load方法
2.再调用分类的load方法
- 按照编译先后顺序,先编译,先调用
源码调用顺序
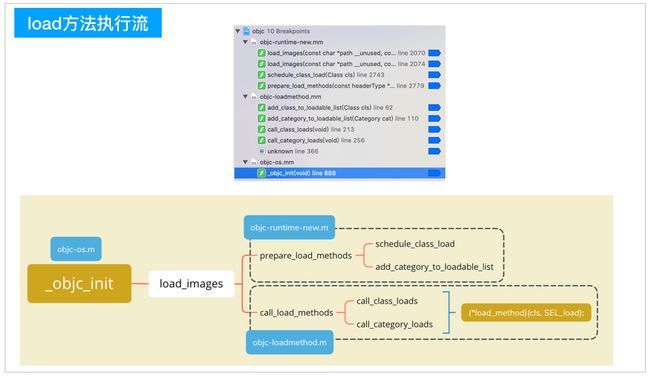
initialize
-
initialize方法的调用时机-
initialize在类第一次接收到消息时调用,也就是objc_msgSend()。 - 先调用父类的
+initialize,再调用子类的initialize。
-
我们首先给Student类和Person类覆写+initialize方法:
//Person
+ (void)initialize{
NSLog(@"Person + initialize");
}
//Person+Test1
+ (void)initialize{
NSLog(@"Person (Test1) + initialize");
}
//Person+Test2
+ (void)initialize{
NSLog(@"Person (Test2) + initialize");
}
//Student
+ (void)initialize{
NSLog(@"Student + initialize");
}
//Student (Test1)
+ (void)initialize{
NSLog(@"Student (Test1) + initialize");
}
//Student (Test2)
+ (void)initialize{
NSLog(@"Student (Test2) + initialize");
}
我们运行程序,发现什么也没有打印,说明在运行期没有调用+initialize方法。
然后我们给Person类发送消息,也就是调用函数:
[Person alloc];
//打印结果:
Person (Test2) + initialize
可以看到调用了Person类的分类的initialize方法。通过这个打印结果我们能看出initialize方法和load方法的不同,load方法由于是直接获取方法的地址,然后调用方法,所以Person及其分类的load方法都会调用。而initialize方法则更像是通过消息机制,也即是objc_msgend(Person, @selector(initialize))这种来调用的。
- 然后我们再给Student类发送消息
[Student alloc]
//打印结果:
Person (Test2) + initialize
Student (Test1) + initialize
我们看到不仅调用了Student类的initialize方法,而且还调用了Student类的父类,Person类的方法,因此我们猜测在调用类的initialize方法之前会先调用父类的initialize方法。
- 下面我们通过源码来验证我们的想法
Method class_getClassMethod(Class cls, SEL sel)
{
if (!cls || !sel) return nil;
//通过这里可以发现,获取对象方法和类方法的本质都是调用class_getInstanceMethod
return class_getInstanceMethod(cls->getMeta(), sel);
}
- 我们点进
class_getInstanceMethod
Method class_getInstanceMethod(Class cls, SEL sel)
{
if (!cls || !sel) return nil;
// This deliberately avoids +initialize because it historically did so.
// This implementation is a bit weird because it's the only place that
// wants a Method instead of an IMP.
#warning fixme build and search caches
// Search method lists, try method resolver, etc.
//主要是这个方法,寻找方法的实现
lookUpImpOrNil(cls, sel, nil,
NO/*initialize*/, NO/*cache*/, YES/*resolver*/);
#warning fixme build and search caches
return _class_getMethod(cls, sel);
}
- 进入
lookUpImpOrNil后
IMP lookUpImpOrNil(Class cls, SEL sel, id inst,
bool initialize, bool cache, bool resolver)
{
//进入如下方法
IMP imp = lookUpImpOrForward(cls, sel, inst, initialize, cache, resolver);
if (imp == _objc_msgForward_impcache) return nil;
else return imp;
}
- 进入后
IMP lookUpImpOrForward(Class cls, SEL sel, id inst,
bool initialize, bool cache, bool resolver)
{
IMP imp = nil;
bool triedResolver = NO;
runtimeLock.assertUnlocked();
// Optimistic cache lookup
if (cache) {
imp = cache_getImp(cls, sel);
if (imp) return imp;
}
runtimeLock.lock();
checkIsKnownClass(cls);
if (!cls->isRealized()) {
realizeClass(cls);
}
重点
---------------------------------------------------------------------------------
//如果需要initialized并且还没有被initialize过
if (initialize && !cls->isInitialized()) {
runtimeLock.unlock();
//这个函数是真正的初始化实例
_class_initialize (_class_getNonMetaClass(cls, inst));
runtimeLock.lock();
}
---------------------------------------------------------------------------------
retry:
runtimeLock.assertLocked();
imp = cache_getImp(cls, sel);
if (imp) goto done;
// Try this class's method lists.
{
Method meth = getMethodNoSuper_nolock(cls, sel);
if (meth) {
log_and_fill_cache(cls, meth->imp, sel, inst, cls);
imp = meth->imp;
goto done;
}
}
// Try superclass caches and method lists.
{
unsigned attempts = unreasonableClassCount();
for (Class curClass = cls->superclass;
curClass != nil;
curClass = curClass->superclass)
{
// Halt if there is a cycle in the superclass chain.
if (--attempts == 0) {
_objc_fatal("Memory corruption in class list.");
}
// Superclass cache.
imp = cache_getImp(curClass, sel);
if (imp) {
if (imp != (IMP)_objc_msgForward_impcache) {
// Found the method in a superclass. Cache it in this class.
log_and_fill_cache(cls, imp, sel, inst, curClass);
goto done;
}
else {
break;
}
}
// Superclass method list.
Method meth = getMethodNoSuper_nolock(curClass, sel);
if (meth) {
log_and_fill_cache(cls, meth->imp, sel, inst, curClass);
imp = meth->imp;
goto done;
}
}
}
// No implementation found. Try method resolver once.
if (resolver && !triedResolver) {
runtimeLock.unlock();
_class_resolveMethod(cls, sel, inst);
runtimeLock.lock();
// Don't cache the result; we don't hold the lock so it may have
// changed already. Re-do the search from scratch instead.
triedResolver = YES;
goto retry;
}
imp = (IMP)_objc_msgForward_impcache;
cache_fill(cls, sel, imp, inst);
done:
runtimeLock.unlock();
return imp;
}
这个代码也说明了每个类的+initialize方法只会被调用一次。
我们点进
_class_initialize (_class_getNonMetaClass(cls, inst));寻找真正的实现:
void _class_initialize(Class cls)
{
assert(!cls->isMetaClass());
Class supercls;
bool reallyInitialize = NO;
// Make sure super is done initializing BEFORE beginning to initialize cls.
// See note about deadlock above.
supercls = cls->superclass;
//这个条件是如果父类存在且父类还没有调用过initialize方法,那么就递归调用_class_initialize方法
if (supercls && !supercls->isInitialized()) {
_class_initialize(supercls);
}
{
monitor_locker_t lock(classInitLock);
if (!cls->isInitialized() && !cls->isInitializing()) {
cls->setInitializing();
reallyInitialize = YES;
}
}
if (reallyInitialize) {
_setThisThreadIsInitializingClass(cls);
if (MultithreadedForkChild) {
// LOL JK we don't really call +initialize methods after fork().
performForkChildInitialize(cls, supercls);
return;
}
if (PrintInitializing) {
_objc_inform("INITIALIZE: thread %p: calling +[%s initialize]",
pthread_self(), cls->nameForLogging());
}
#if __OBJC2__
@try
#endif
{
//父类处理完了才调用自己的intialized方法
callInitialize(cls);
if (PrintInitializing) {
_objc_inform("INITIALIZE: thread %p: finished +[%s initialize]",
pthread_self(), cls->nameForLogging());
}
}
…………
}
- 然后我们通过
callInitialize(cls);查看具体的调用
void callInitialize(Class cls)
{
//这里就是简单的通过objc_msgSend()调用initialize方法
((void(*)(Class, SEL))objc_msgSend)(cls, SEL_initialize);
asm("");
}
-
+initialize的调用过程:- 1查看本类的
initialize方法有没有实现过,如果已经实现过就返回,不再实现。 - 2.如果本类没有实现过
initialize方法,那么就去递归查看该类的父类有没有实现过initialize方法,如果没有实现就去实现,最后实现本类的initialize方法。并且initialize方法是通过objc_msgSend()实现的。
- 1查看本类的
load和initialized总结

关联对象
如何关联对象
使用
RunTime给系统的类添加属性,首先需要了解对象与属性的关系。我们通过之前的学习知道,对象一开始初始化的时候其属性为nil,给属性赋值其实就是让属性指向一块存储内容的内存,使这个对象的属性跟这块内存产生一种关联。那么如果想动态的添加属性,其实就是动态的产生某种关联就好了。而想要给系统的类添加属性,只能通过分类。
我们可以使用
@property给分类添加属性
@property(nonatomic,strong)NSString *name;
虽然在分类中可以写@property添加属性,但是不会自动生成私有属性,也不会生成set,get方法的实现,只会生成set,get的声明,需要我们自己去实现。
- RunTime提供了动态添加属性和获得属性的方法。
-(void)setName:(NSString *)name
{
objc_setAssociatedObject(self, @"name",name, OBJC_ASSOCIATION_RETAIN_NONATOMIC);
}
-(NSString *)name
{
return objc_getAssociatedObject(self, @"name");
}
- 动态添加属性
objc_setAssociatedObject(id object, const void *key, id value, objc_AssociationPolicy policy);
参数一:id object: 给哪个对象添加属性,这里要给自己添加属性,用self。
参数二:void * == id key: 属性名,根据key获取关联对象的属性的值,在objc_getAssociatedObject中通过次key获得属性的值并返回。
参数三:id value: 关联的值,也就是set方法传入的值给属性去保存。
参数四:objc_AssociationPolicy policy: 策略,属性以什么形式保存。
有以下几种
typedef OBJC_ENUM(uintptr_t, objc_AssociationPolicy) {
OBJC_ASSOCIATION_ASSIGN = 0, // 指定一个弱引用相关联的对象
OBJC_ASSOCIATION_RETAIN_NONATOMIC = 1, // 指定相关对象的强引用,非原子性
OBJC_ASSOCIATION_COPY_NONATOMIC = 3, // 指定相关的对象被复制,非原子性
OBJC_ASSOCIATION_RETAIN = 01401, // 指定相关对象的强引用,原子性
OBJC_ASSOCIATION_COPY = 01403 // 指定相关的对象被复制,原子性
};
- 获得属性
objc_getAssociatedObject(id object, const void *key);
参数一:id object : 获取哪个对象里面的关联的属性。
参数二:void * == id key : 什么属性,与objc_setAssociatedObject中的key相对应,即通过key值取出value。
- 移除所有关联对象
- (void)removeAssociatedObjects
{
// 移除所有关联对象
objc_removeAssociatedObjects(self);
}
可以看出关联对象的使用非常简单,接下来我们来探寻关联对象的底层原理
关联对象的实现原理
- 实现关联对象技术的核心对象有
- AssociationsManager
- AssociationsHashMap
- ObjectAssociationMap
- ObjcAssociation
其中Map同我们平时使用的字典类似。通过key-value一一对应存值。
- 首先来到
runtime源码,首先找到objc_setAssociatedObject函数,看一下其实现
// 设置关联对象的方法
void objc_setAssociatedObject(id object, const void *key, id value, objc_AssociationPolicy policy) {
_object_set_associative_reference(object, (void *)key, value, policy);
}
我们看到其实内部调用的是_object_set_associative_reference函数,我们来到_object_set_associative_reference函数中
- _object_set_associative_reference函数
// 该方法完成了设置关联对象的操作
void _object_set_associative_reference(id object, void *key, id value, uintptr_t policy) {
// retain the new value (if any) outside the lock.
// 初始化空的ObjcAssociation(关联对象)
ObjcAssociation old_association(0, nil);
id new_value = value ? acquireValue(value, policy) : nil;
{
// 初始化一个manager
AssociationsManager manager;
AssociationsHashMap &associations(manager.associations());
// 获取对象的DISGUISE值,作为AssociationsHashMap的key
disguised_ptr_t disguised_object = DISGUISE(object);
if (new_value) {
// value有值,不为nil
// break any existing association.
// AssociationsHashMap::iterator 类型的迭代器
AssociationsHashMap::iterator i = associations.find(disguised_object);
if (i != associations.end()) {
// secondary table exists
// 获取到ObjectAssociationMap(key是外部传来的key,value是关联对象类ObjcAssociation)
ObjectAssociationMap *refs = i->second;
// ObjectAssociationMap::iterator 类型的迭代器
ObjectAssociationMap::iterator j = refs->find(key);
if (j != refs->end()) {
// 原来该key对应的有关联对象
// 将原关联对象的值存起来,并且赋新值
old_association = j->second;
j->second = ObjcAssociation(policy, new_value);
} else {
// 无该key对应的关联对象,直接赋值即可
// ObjcAssociation(policy, new_value)提供了这样的构造函数
(*refs)[key] = ObjcAssociation(policy, new_value);
}
} else {
// create the new association (first time).
// 执行到这里,说明该对象是第一次添加关联对象
// 初始化ObjectAssociationMap
ObjectAssociationMap *refs = new ObjectAssociationMap;
associations[disguised_object] = refs;
// 赋值
(*refs)[key] = ObjcAssociation(policy, new_value);
// 设置该对象的有关联对象,调用的是setHasAssociatedObjects()方法
object->setHasAssociatedObjects();
}
} else {
// setting the association to nil breaks the association.
// value无值,也就是释放一个key对应的关联对象
AssociationsHashMap::iterator i = associations.find(disguised_object);
if (i != associations.end()) {
ObjectAssociationMap *refs = i->second;
ObjectAssociationMap::iterator j = refs->find(key);
if (j != refs->end()) {
old_association = j->second;
// 调用erase()方法删除对应的关联对象
refs->erase(j);
}
}
}
}
// release the old value (outside of the lock).
// 释放旧的关联对象
if (old_association.hasValue()) ReleaseValue()(old_association);
}
这个函数的实现看起来非常复杂,都是C++的语法,对于不了解C++的人来说非常困难,不过没关系,即便我们看不懂上面的代码,通过下面的分析,我们也能明白关联对象的原理:
首先我们来分析一下我上面提到的那几个核心对象
- 我们点进
AssociationsManager查看其结构:
class AssociationsManager {
// AssociationsManager中只有一个变量AssociationsHashMap
static AssociationsHashMap *_map;
public:
// 构造函数中加锁
AssociationsManager() { AssociationsManagerLock.lock(); }
// 析构函数中释放锁
~AssociationsManager() { AssociationsManagerLock.unlock(); }
// 构造函数、析构函数中加锁、释放锁的操作,保证了AssociationsManager是线程安全的
AssociationsHashMap &associations() {
// AssociationsHashMap 的实现可以理解成单例对象
if (_map == NULL)
_map = new AssociationsHashMap();
return *_map;
}
};
- 我们来看一下
AssociationsHashMap内部的源码
// AssociationsHashMap是字典,key是对象的disguised_ptr_t值,value是ObjectAssociationMap
class AssociationsHashMap : public unordered_map {
public:
void *operator new(size_t n) { return ::malloc(n); }
void operator delete(void *ptr) { ::free(ptr); }
};
通过AssociationsHashMap内部源码我们发现AssociationsHashMap继承自unordered_map首先来看一下unordered_map内的源码
template , class _Pred = equal_to<_Key>,
class _Alloc = allocator > >
class _LIBCPP_TEMPLATE_VIS unordered_map
{
public:
// types
typedef _Key key_type;
typedef _Tp mapped_type;
typedef _Hash hasher;
typedef _Pred key_equal;
typedef _Alloc allocator_type;
typedef pair value_type;
typedef value_type& reference;
typedef const value_type& const_reference;
static_assert((is_same::value),
"Invalid allocator::value_type");
static_assert(sizeof(__diagnose_unordered_container_requirements<_Key, _Hash, _Pred>(0)), "");
private:
.......
}
从unordered_map源码中我们可以看出_Key和_Tp也就是前两个参数对应着map中的Key和Value,那么对照上面AssociationsHashMap内源码发现_Key中传入的是disguised_ptr_t,_Tp中传入的值则为ObjectAssociationMap*。
- 接着我们来到ObjectAssociationMap中
// ObjectAssociationMap是字典,key是从外面传过来的key,例如@selector(hello),value是关联对象,也就是
// ObjectAssociation
class ObjectAssociationMap : public std::map {
public:
void *operator new(size_t n) { return ::malloc(n); }
void operator delete(void *ptr) { ::free(ptr); }
};
我们发现ObjectAssociationMap中同样以key、Value的方式存储着ObjcAssociation。
- 接着我们来到ObjcAssociation中
// ObjcAssociation就是关联对象类
class ObjcAssociation {
uintptr_t _policy;//策略
// 值
id _value;
public:
// 构造函数
ObjcAssociation(uintptr_t policy, id value) : _policy(policy), _value(value) {}
// 默认构造函数,参数分别为0和nil
ObjcAssociation() : _policy(0), _value(nil) {}
uintptr_t policy() const { return _policy; }
id value() const { return _value; }
bool hasValue() { return _value != nil; }
};
我们发现ObjcAssociation存储着_policy、_value,而这两个值我们可以发现正是我们调用objc_setAssociatedObject函数传入的值,也就是说我们在调用objc_setAssociatedObject函数中传入的value和policy这两个值最终是存储在ObjcAssociation中的。
- 下面我们用一张图来解释他们之间的关系
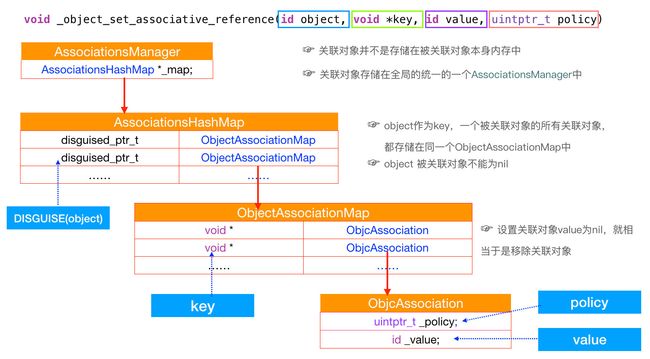
- 这个结构有啥巧妙之处?
- 一个
objc对象不光有一个属性需要关联时,比如说要关联name和age这两个属性,我们就以objc对象作为disguised_ptr_t,然后value是ObjectAssociationMap这个字典类型,在这个字典类型中,分别使用@"name"和@"age"作为key,传递进来的值和策略生成ObjectAssociation作为value。 - 如果有多个对象进行关联时,我们只需要在
AssociationHashMap中创造更多的键值对就可以解决这个问题。 - 关联对象的值它不是存储在自己的实例对象的结构中,而是维护了一个全局的结构AssociationManager
- 一个
- 下面我们再重新回到_object_set_associative_reference函数实现中
// 该方法完成了设置关联对象的操作
void _object_set_associative_reference(id object, void *key, id value, uintptr_t policy) {
// retain the new value (if any) outside the lock.
// 初始化空的ObjcAssociation(关联对象)
ObjcAssociation old_association(0, nil);
id new_value = value ? acquireValue(value, policy) : nil;
{
// 初始化一个manager
AssociationsManager manager;
AssociationsHashMap &associations(manager.associations());
// 获取对象的DISGUISE值,作为AssociationsHashMap的key
disguised_ptr_t disguised_object = DISGUISE(object);
if (new_value) {
// value有值,不为nil
// AssociationsHashMap::iterator 类型的迭代器
AssociationsHashMap::iterator i = associations.find(disguised_object);
if (i != associations.end()) {
// 获取到ObjectAssociationMap(key是外部传来的key,value是关联对象类ObjcAssociation)
ObjectAssociationMap *refs = i->second;
// 在ObjectAssociationMap寻找key对应的ObjcAssociation
ObjectAssociationMap::iterator j = refs->find(key);
if (j != refs->end()) {
// 原来该key对应的有关联对象
// 将旧值保存在old_association,并且赋新值
old_association = j->second;
j->second = ObjcAssociation(policy, new_value);
} else {
// 无该key对应的关联对象,直接赋值即可
// ObjcAssociation(policy, new_value)提供了这样的构造函数
(*refs)[key] = ObjcAssociation(policy, new_value);
}
} else {
// 执行到这里,说明该对象是第一次添加关联对象
// 初始化ObjectAssociationMap
ObjectAssociationMap *refs = new ObjectAssociationMap;
associations[disguised_object] = refs;
// 赋值
(*refs)[key] = ObjcAssociation(policy, new_value);
// 设置该对象的有关联对象,调用的是setHasAssociatedObjects()方法
object->setHasAssociatedObjects();
}
} else {
// value无值,也就是释放一个key对应的关联对象
AssociationsHashMap::iterator i = associations.find(disguised_object);
if (i != associations.end()) {
ObjectAssociationMap *refs = i->second;
ObjectAssociationMap::iterator j = refs->find(key);
if (j != refs->end()) {
old_association = j->second;
// 调用erase()方法删除对应的关联对象
refs->erase(j);
}
}
}
}
// 释放旧的关联对象
if (old_association.hasValue()) ReleaseValue()(old_association);
}
- 首先根据我们传入的
value经过acquireValue函数处理获取new_value。acquireValue函数内部其实是通过对策略的判断返回不同的值
// 根据policy的值,对value进行retain或者copy
static id acquireValue(id value, uintptr_t policy) {
switch (policy & 0xFF) {
case OBJC_ASSOCIATION_SETTER_RETAIN:
return objc_retain(value);
case OBJC_ASSOCIATION_SETTER_COPY:
return ((id(*)(id, SEL))objc_msgSend)(value, SEL_copy);
}
return value;
}
- 之后创建
AssociationsManager manager;以及拿到manager内部的AssociationsHashMap即associations。
之后我们看到了我们传入的第一个参数object
object经过DISGUISE函数被转化为了disguised_ptr_t类型的disguised_object。
typedef uintptr_t disguised_ptr_t;
inline disguised_ptr_t DISGUISE(id value) { return ~uintptr_t(value); }
inline id UNDISGUISE(disguised_ptr_t dptr) { return id(~dptr); }
DISGUISE函数其实仅仅对object做了位运算
- 接着我们来看看objc_getAssociatedObject函数
// 获取关联对象的方法
id objc_getAssociatedObject(id object, const void *key) {
return _object_get_associative_reference(object, (void *)key);
}
- objc_getAssociatedObject内部调用的是_object_get_associative_reference
// 获取关联对象
id _object_get_associative_reference(id object, void *key) {
id value = nil;
uintptr_t policy = OBJC_ASSOCIATION_ASSIGN;
{
AssociationsManager manager;
// 获取到manager中的AssociationsHashMap
AssociationsHashMap &associations(manager.associations());
// 获取对象的DISGUISE值
disguised_ptr_t disguised_object = DISGUISE(object);
AssociationsHashMap::iterator i = associations.find(disguised_object);
if (i != associations.end()) {
// 获取ObjectAssociationMap
ObjectAssociationMap *refs = i->second;
ObjectAssociationMap::iterator j = refs->find(key);
if (j != refs->end()) {
// 获取到关联对象ObjcAssociation
ObjcAssociation &entry = j->second;
// 获取到value
value = entry.value();
policy = entry.policy();
if (policy & OBJC_ASSOCIATION_GETTER_RETAIN) {
objc_retain(value);
}
}
}
}
if (value && (policy & OBJC_ASSOCIATION_GETTER_AUTORELEASE)) {
objc_autorelease(value);
}
// 返回关联对像的值
return value;
}
- objc_removeAssociatedObjects函数
// 移除对象object的所有关联对象
void objc_removeAssociatedObjects(id object)
{
if (object && object->hasAssociatedObjects()) {
_object_remove_assocations(object);
}
}
objc_removeAssociatedObjects函数内部调用的是_object_remove_assocations函数
// 移除对象object的所有关联对象
void _object_remove_assocations(id object) {
// 声明了一个vector
vector< ObjcAssociation,ObjcAllocator > elements;
{
AssociationsManager manager;
AssociationsHashMap &associations(manager.associations());
// 如果map size为空,直接返回
if (associations.size() == 0) return;
// 获取对象的DISGUISE值
disguised_ptr_t disguised_object = DISGUISE(object);
AssociationsHashMap::iterator i = associations.find(disguised_object);
if (i != associations.end()) {
// copy all of the associations that need to be removed.
ObjectAssociationMap *refs = i->second;
for (ObjectAssociationMap::iterator j = refs->begin(), end = refs->end(); j != end; ++j) {
elements.push_back(j->second);
}
// remove the secondary table.
delete refs;
associations.erase(i);
}
}
// the calls to releaseValue() happen outside of the lock.
for_each(elements.begin(), elements.end(), ReleaseValue());
}
上述源码可以看出_object_remove_assocations函数将object对象向对应的所有关联对象全部删除。