除了对本地文件系统进行读写以外,Spark还支持很多常见的文件格式(文本文件、JSON)和文件系统(HDFS)和数据库(MySQL、Hive、Hbase)。
1.文件系统的数据读写
1.1本地文件系统的数据读写
在本机上的/usr/local/spark/spark-2.2.0-bin-hadoop2.7/examples/src/main/resources 目录下新建一个TXT文件。文件内容如下:
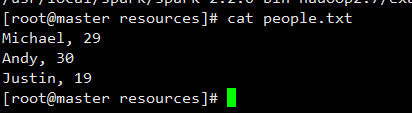
要加载本地文件,必须采用“file:///”开头的这种格式。执行上上面这条命令以后,并不会马上显示结果,因为,Spark采用惰性机制,只有遇到“行动”类型的操作,才会从头到尾执行所有操作。
通过SparkContext的textFile方法逐行加载文件中的数据,然后以
,作为分隔符,将每一行的字符串切分为一个只包含两个元素(分别代表name和age)的字符串数组。
#加载本地文件
var file = sc.textFile("file:///usr/local/spark/spark-2.2.0-bin-hadoop2.7/examples/src/main/resources/people.txt")
#取第一行的数据
file.first()

#将file变量内容保存在另一个文件中
file.saveAsFile("file:///usr/local/spark/spark-2.2.0-bin-hadoop2.7/examples/src/main/resources/user.txt")
1.2分布式文件系统HDFS的数据读写
首先要启动HDFS文件系统
nohup hive --service metastore > metastore.log 2>&1 &
然后进入/usr/local/hadoop/hadoop-2.8.2/bin 创建HDFS文件路径
#user为指定目录,root为登录Linux系统的用户名
#hdfs://master:9000/user/root
hdfs dfs -mkdir -p /user/root
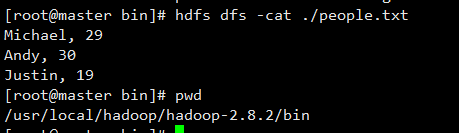
将people.txt 文件上传到HDFS文件系统中(放到root用户下)
#上传文件
hdfs dfs -put /usr/local/spark/spark-2.2.0-bin-hadoop2.7/examples/src/main/resources/people.txt
#查看文件系统中的文件
hdfs dfs -ls .
#查看文件内容
hdfs dfs -cat ./people.txt
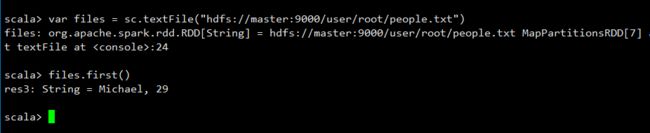
现在,让我们切换回到spark-shell窗口,编写语句从HDFS中加载people.txt文件,并显示第一行文本内容:
#加载数据
var files = sc.textFile("hdfs://master:9000/user/root/people.txt")
files.first()
需要注意的是,sc.textFile(“hdfs://master:9000/user/hadoop/word.txt”)中,“hdfs://master:9000/”是前面介绍Hadoop安装内容时确定下来的端口地址9000
2.不同文件格式的读写
2.1文本文件
和上面的例子相同。
#加载本地文件
var file = sc.textFile("file:///usr/local/spark/spark-2.2.0-bin-hadoop2.7/examples/src/main/resources/people.txt")
#取第一行的数据
file.first()
2.2JSON格式
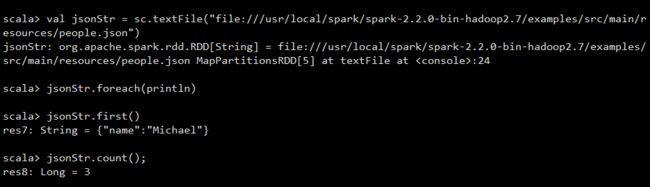
Spark提供了一个JSON样例数据文件,存放在“/usr/local/spark/examples/src/main/resources/people.json”中。
#加载JSON数据源
val jsonStr = sc.textFile("file:///usr/local/spark/spark-2.2.0-bin-hadoop2.7/examples/src/main/resources/people.json")
#打印出来
jsonStr.first()
2.3CSV格式
CSV格式文件也称为逗号分隔值(Comma-Separated Values),CSV文件由任意数目的记录组成,记录间以某种换行符分隔,每条记录有字段组成,字段间的分隔符是其它字符或者字符串,最常见的是逗号或制表符。
参考于databricks官方文档
Scala版本
./bin/spark-shell --packages com.databricks:spark-csv_2.11:1.0.3
val data =spark.read.format("com.databricks.spark.csv")#格式说明
.option("header","true")#如果在CSV文件第一行有属性的话,就为true,没有就是false
.option("inferSchema",true)#这里是自动推断属性列的数据类型
.load("/home/zhoujian/spark/test")#文件路径
#用表格显示出来
display(data)
#显示字段类型
data.printSchema
Python版本
diamonds = sqlContext.read.format('csv').options(header='true', inferSchema='true').load('/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv')
display(diamonds)
diamonds.printSchema()
3.参考资料
Apache spark 中文官方文档
Transformations(转换)
下表列出了一些 Spark 常用的 transformations(转换). 详情请参考 RDD API 文档 (Scala, Java, Python, R) 和 pair RDD 函数文档 (Scala, Java).
| Transformation(转换) | Meaning(含义) |
|---|---|
| map(func) | 返回一个新的 distributed dataset(分布式数据集),它由每个 source(数据源)中的元素应用一个函数 func 来生成. |
| filter(func) | 返回一个新的 distributed dataset(分布式数据集),它由每个 source(数据源)中应用一个函数 func 且返回值为 true 的元素来生成. |
| flatMap(func) | 与 map 类似,但是每一个输入的 item 可以被映射成 0 个或多个输出的 items(所以 func 应该返回一个 Seq 而不是一个单独的 item). |
| mapPartitions(func) | 与 map 类似,但是单独的运行在在每个 RDD 的 partition(分区,block)上,所以在一个类型为 T 的 RDD 上运行时 func 必须是 Iterator |
| mapPartitionsWithIndex(func) | 与 mapPartitions 类似,但是也需要提供一个代表 partition 的 index(索引)的 interger value(整型值)作为参数的 func,所以在一个类型为 T 的 RDD 上运行时 func 必须是 (Int, Iterator |
| sample(withReplacement, fraction, seed) | 样本数据,设置是否放回(withReplacement), 采样的百分比(fraction)、使用指定的随机数生成器的种子(seed). |
| union(otherDataset) | 反回一个新的 dataset,它包含了 source dataset(源数据集)和 otherDataset(其它数据集)的并集. |
| intersection(otherDataset) | 返回一个新的 RDD,它包含了 source dataset(源数据集)和 otherDataset(其它数据集)的交集. |
| distinct([numTasks])) | 返回一个新的 dataset,它包含了 source dataset(源数据集)中去重的元素. |
| groupByKey([numTasks]) | 在一个 (K, V) pair 的 dataset 上调用时,返回一个 (K, IterablereduceByKey 或 aggregateByKey 来计算性能会更好. Note: 默认情况下,并行度取决于父 RDD 的分区数。可以传递一个可选的 numTasks 参数来设置不同的任务数. |
| reduceByKey(func, [numTasks]) | 在 (K, V) pairs 的 dataset 上调用时, 返回 dataset of (K, V) pairs 的 dataset, 其中的 values 是针对每个 key 使用给定的函数 func 来进行聚合的, 它必须是 type (V,V) => V 的类型. 像 groupByKey 一样, reduce tasks 的数量是可以通过第二个可选的参数来配置的. |
| aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) | 在 (K, V) pairs 的 dataset 上调用时, 返回 (K, U) pairs 的 dataset,其中的 values 是针对每个 key 使用给定的 combine 函数以及一个 neutral "0" 值来进行聚合的. 允许聚合值的类型与输入值的类型不一样, 同时避免不必要的配置. 像 groupByKey 一样, reduce tasks 的数量是可以通过第二个可选的参数来配置的. |
| sortByKey([ascending], [numTasks]) | 在一个 (K, V) pair 的 dataset 上调用时,其中的 K 实现了 Ordered,返回一个按 keys 升序或降序的 (K, V) pairs 的 dataset, 由 boolean 类型的 ascending 参数来指定. |
| join(otherDataset, [numTasks]) | 在一个 (K, V) 和 (K, W) 类型的 dataset 上调用时,返回一个 (K, (V, W)) pairs 的 dataset,它拥有每个 key 中所有的元素对。Outer joins 可以通过 leftOuterJoin, rightOuterJoin 和 fullOuterJoin 来实现. |
| cogroup(otherDataset, [numTasks]) | 在一个 (K, V) 和的 dataset 上调用时,返回一个 (K, (IterablegroupWith. |
| cartesian(otherDataset) | 在一个 T 和 U 类型的 dataset 上调用时,返回一个 (T, U) pairs 类型的 dataset(所有元素的 pairs,即笛卡尔积). |
| pipe(command, [envVars]) | 通过使用 shell 命令来将每个 RDD 的分区给 Pipe。例如,一个 Perl 或 bash 脚本。RDD 的元素会被写入进程的标准输入(stdin),并且 lines(行)输出到它的标准输出(stdout)被作为一个字符串型 RDD 的 string 返回. |
| coalesce(numPartitions) | Decrease(降低)RDD 中 partitions(分区)的数量为 numPartitions。对于执行过滤后一个大的 dataset 操作是更有效的. |
| repartition(numPartitions) | Reshuffle(重新洗牌)RDD 中的数据以创建或者更多的 partitions(分区)并将每个分区中的数据尽量保持均匀. 该操作总是通过网络来 shuffles 所有的数据. |
| repartitionAndSortWithinPartitions(partitioner) | 根据给定的 partitioner(分区器)对 RDD 进行重新分区,并在每个结果分区中,按照 key 值对记录排序。这比每一个分区中先调用 repartition 然后再 sorting(排序)效率更高,因为它可以将排序过程推送到 shuffle 操作的机器上进行. |
Actions(动作)
下表列出了一些 Spark 常用的 actions 操作。详细请参考 RDD API 文档 (Scala, Java, Python, R)
和 pair RDD 函数文档 (Scala, Java).
| Action(动作) | Meaning(含义) |
|---|---|
| reduce(func) | 使用函数 func 聚合 dataset 中的元素,这个函数 func 输入为两个元素,返回为一个元素。这个函数应该是可交换(commutative )和关联(associative)的,这样才能保证它可以被并行地正确计算. |
| collect() | 在 driver 程序中,以一个 array 数组的形式返回 dataset 的所有元素。这在过滤器(filter)或其他操作(other operation)之后返回足够小(sufficiently small)的数据子集通常是有用的. |
| count() | 返回 dataset 中元素的个数. |
| first() | 返回 dataset 中的第一个元素(类似于 take(1). |
| take(n) | 将数据集中的前 n 个元素作为一个 array 数组返回. |
| takeSample(withReplacement, num, [seed]) | 对一个 dataset 进行随机抽样,返回一个包含 num 个随机抽样(random sample)元素的数组,参数 withReplacement 指定是否有放回抽样,参数 seed 指定生成随机数的种子. |
| takeOrdered(n, [ordering]) | 返回 RDD 按自然顺序(natural order)或自定义比较器(custom comparator)排序后的前 n 个元素. |
| saveAsTextFile(path) | 将 dataset 中的元素以文本文件(或文本文件集合)的形式写入本地文件系统、HDFS 或其它 Hadoop 支持的文件系统中的给定目录中。Spark 将对每个元素调用 toString 方法,将数据元素转换为文本文件中的一行记录. |
| saveAsSequenceFile(path) (Java and Scala) | 将 dataset 中的元素以 Hadoop SequenceFile 的形式写入到本地文件系统、HDFS 或其它 Hadoop 支持的文件系统指定的路径中。该操作可以在实现了 Hadoop 的 Writable 接口的键值对(key-value pairs)的 RDD 上使用。在 Scala 中,它还可以隐式转换为 Writable 的类型(Spark 包括了基本类型的转换,例如 Int, Double, String 等等). |
| saveAsObjectFile(path) (Java and Scala) | 使用 Java 序列化(serialization)以简单的格式(simple format)编写数据集的元素,然后使用 SparkContext.objectFile() 进行加载. |
| countByKey() | 仅适用于(K,V)类型的 RDD 。返回具有每个 key 的计数的 (K , Int)pairs 的 hashmap. |
| foreach(func) | 对 dataset 中每个元素运行函数 func 。这通常用于副作用(side effects),例如更新一个 Accumulator(累加器)或与外部存储系统(external storage systems)进行交互。Note:修改除 foreach()之外的累加器以外的变量(variables)可能会导致未定义的行为(undefined behavior)。详细介绍请阅读 Understanding closures(理解闭包) 部分. |