1. 文章
An overview of gradient descent optimization algorithms
2. 概要
梯度优化算法,作为各大开源库(如Tensorflow,Keras,PyTorch等)中重要的黑盒子,在网络训练中至关重要,拥有很强的魔力(实用性),但官网一般很少介绍各种梯度优化算法变种的原理。作者在这篇文章里,介绍了不同优化算法的基本原理,旨在让读者知道每个优化算法的利弊和适用的场景,也涉及了一些在并行化和分布式下的结构形式。
3. 前言
对于优化神经网络而言,梯度下降是目前最主流、最常见的算法,目前几乎所有的开源库都包含丰富的梯度优化算法,如Adam、Adagrad,SGD,RMSprop等。作者在文章依次介绍了当前常见的算法参数更新原理,并给出了自己的一些见解。
在给定神经网络时,梯度下降被用来最小化目标函数J(θ),通过不断往负梯度方向更新网络参数。学习率η用来确定每次更新多大的梯度步长。换句话说,我们总是沿着目标函数的斜坡往下走,直到到达一个山谷(局部最优解或者最优解)。
4. 梯度下降
4.1 Batch gradient descent
又称Vanilla gradient descent,通过计算整个训练样本的梯度来更新参数θ:
因为我们需要计算所有的训练数据的梯度,进行一次参数更新,因此BGD非常慢,无法处理内存放不下数据的情况,也无法进行在线更新。
for i in range(nb_epochs):
params_grad = evaluate_gradient(loss_function, data, params)
Params = params - learning_rate * params_grad
目前各大框架都支持梯度的自动求导,如果要自己实现求导,最好做一下梯度检查。
4.2 随机梯度下降(Stochastic gradient descent)
随机梯度下降,每次选取一个样本进行参数更新:

BGD存在着梯度冗余计算的问题——在每个参数更新之前,重复计算了相同的样本梯度。SGD通常速度更快一些,可用于在线更新。但是因为SGD每次仅用一个样本进行频繁的参数更新,可能导致目标函数值震荡比较厉害,如下图:

4.3 Mini-Batch gradient descent
MBGD结合了上述两个基本算法的优点,每次借助batch_size个样本进行参数更新:

- 降低了参数跟新的波动方差,保证稳定收敛
- 在计算batch样本的梯度更新参数时,可以借助矩阵运算,非常高效
- batch_size一般在50~256,根据不同的任务取值不同
- batch是很经典的思想,在后文中提到的SGD,均指支持batch的SGD
for i in range(nb_epochs):
np.random.shuffle(data)
for batch in get_batches(data, batch_sizes=50):
params_grad = evaluate_gradient(loss_function, batch, params)
Params = params - learning_rate * params_grad
4.4 存在的挑战
mini-batch梯度下降算法并不能保证能收敛到一个很好解上,主要面临以下几个问题:
- 很难选择一个合适的学习率η。学习率太小则收敛特别慢,学习率太大,会导致在最优解附近震荡,甚至偏离最优解得到局部最优解
- 自适应学习率调度,能够在训练过程不断调整学习率的大小。根据预定义的降级参数,可以训练的不同阶段,递减的降低学习率的大小(衰减因子),但是在何时,以何种尺度衰减学习率,同样是一个难题。
- 此外,所有的参数共享同一学习率η。如果训练数据是稀疏的,特征具有不同的频次,这时我们并不想以同样的步长更新参数,更希望对很少出现的特征对应的参数,进行更大步长的更新。
- 另一个重要问题是,在神经网络里常常是严重非凸的误差函数,如果避免落入局部最优解?Dauphin等人认为局部最优解并不是最棘手问题——鞍点才是,在鞍点处,梯度接近为0,在用SGD时,很难保证能逃离鞍点区域。
5. 优化算法
作者介绍了目前常见的优化算法,这里不讨论在高维数据中无法技术实现的算法,如拟牛顿法。
5.1 动量法(Momentum)
SGD在目标函数的“峡谷”处常出现震荡难以快速收敛的问题,如下图所示,在每一次更新时,损失函数会在峡谷处来回摆动。动量法的思想在于通过阻尼这种往复“摆动”,保持SGD在相对不变方便的动量,以加速收敛速度——抵消峡谷两侧的动量,维护向谷底运动的动量。


γ通常取0.9。实质上,当我们使用动量法时,就像从山上推下一个球,球会逐渐累积往山谷滚的动量,越滚越快。在参数更新中,动量会对指向相同方向的维度对应的参数进行持续更新,约束梯度方向总是改变的维度参数,尽可能引导损失函数向“谷底”收敛。
5.2 Nesterov accelerated gradient(NAG)
但是,让“球”无脑地沿着斜坡向下滚并不总能得到让人满意的解。我们更希望有这样的一个小球,它能够对下一步怎么滚有个基本的“主见“,在滚过斜坡遇到上坡时,能够减速,防止越过最优解。
NAG则在动量法的基础上引入了”预测“的功能。在动量法中,我们用γv_{t-1}更新参数θ。通过计算θ-γv_{t-1}处的梯度,可以对下一个位置的走向做一个初步的预估:



依旧设γ在0.9左右。当动量法第一次计算当前梯度时(短蓝线),并在累积梯度方向上进行了一大步参数更新(长蓝线);NAG是首先在之前的梯度方向上走了一大步(棕色线),然后在此位置上评估一下梯度,最后做出一个相对正确的参数更新(绿线)。这种“先知”更新方法可以避免走过头而逃离了最优解——这在RNN相关的各种任务中收益甚好。
以上的参数更新策略同样可以适用于SGD。
5.3 Adagrad
Adagrad可以自适应的调节学习率:对于很少更新的参数采用较大的学习率,对于频繁更新的参数采取更小的学习率——非常适合处理稀疏的数据。谷歌的Dean等人发现,在使用它训练大规模神经网络时,Adagrad很大程度上提升了SGD的鲁棒性。同时,Penningto等人用它来训练GloVe词嵌入模型,因为低频词相对高频词需要更大的学习步长。
在之前的优化算法中,我们对所有的参数θ采取了相同的学习η。Adagrad在不同训练的step t中,对不同的参数θi应用不同的学习率。我们先看每个参数是怎么更新的,在进行向量表示。为了简要起见,令g(t,i)为在step t下参数θi的梯度:
SGD在每一步t对参数θi的更新:

Adagrad修正了上述的更新量,考虑了历史梯度的信息:
其中Gt是一个对角矩阵,在(i, i)处的元素表示到step t时历史θi的梯度平方和。分母下的常量是平滑因子(一般取1e-8)。值得注意的是,没有平方根运算时,算法性能会很差。
Adagrad的好处在于,它避开了人工调参学习率的问题,绝大部分开源库实现只需要在开始的时候设置η=0.01即可。
主要缺点在于它累积了历史梯度作为分母:因为每一个新梯度平方后都是非负值,在训练过程中,分母会越来越大,导致学习率整体会减小直至最后无限小——意味着算法不再能够学习到新的知识。后续算法会解决这个问题的。
5.4 Adadelta
Adadelta是Adagrad的一种拓展形式——Adadelta仅考虑了一个历史时间窗口w下的累积梯度(在实现上并非存储历史梯度,而是借助衰减因子),避免了Adagrad中学习率总是单调递减的问题。
在t步时的平均梯度,取决于历史累积梯度和当前梯度(衰减因子作为trade-off):

γ值类似之前动量法中的因子,通常取0.9。简单期间,我们重写一下SGD的参数更新公式:


在Adagrad优化算法中,上两式变为:
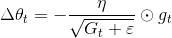
我们把Gt替换为历史梯度的衰减平方:

对于分母,刚好是梯度的均方根误差,则上式变为:

作者指出:the units is this update(as well as in SGD, Momentum, or Adagrad) do not match, i.e. the update should have the same hypothetical units as the paramter. 因此,则定义了另一个指数衰减方式——参数平方更新,而非梯度的平方。

因此,参数更新的的均方根误差为:

但是RMS[delt(θ)t]是未知的,我们借助先前step的参数更新的估计值逼近。则在之前的更新规则中用RMS[delt(θ)t-1]代替学习率:

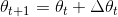
在 Adadelta优化算法中,并不需要我们设置学习率的初始值,η会自动根据更新规则进行估计。
5.5 RMSprop
RMSprop是Hinton在他的Coursera课程上提出的(未公布)的自适应学习率的梯度优化方法。它和Adadelta关注和解决的问题是一样的——学习率的单调递减问题。


Hinton 建议γ设置为0.9,初始学习率建议设置为0.001
5.6 Adam
Adaptive Moment Estimation(Adam),是另一种针对每个参数自适应调整学习率η的优化算法。除了会衰减累积历史的梯度平方和(类似Adadelta, RMSprop),Adam还会保存历史梯度的衰减累积和,类似动量的概念:

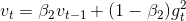
Mt和vt分别是梯度的一阶、二阶估计,并在训练开始时被初始为0,Adam的作者观察到这两值偏置接近0,尤其在初始化前后且两个beta的取值接近1时(衰减率很小)。
计算两个和梯度相关变量的无偏估计值:


进行参数更新:

作者提出beta1的值建议0.9,beta2的值建议0.999,平滑因子设置为1e-8。经验上来讲,在实际使用中Adam相对于其他自适应学习率优化算法,效果要更好一点
5.7 AdaMax
在Adam中vt的更新规则类似于在历史的梯度上应用了L2正则:
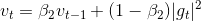
我们可以基于此扩展成Lp正则:
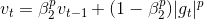
但是p值取得过大可能导致数值不稳定——这也是为什么实际使用中L1和L2才比较常见。但是,当p=无穷大时也具有稳定行为。基于此,作者提出了AdaMax,为了避免与Adam混淆,我们使用ut表示无穷正则约束:

我们将ut代替之前Adam更新公式中vt的平方根:
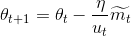
需要指出的是,ut依赖于max操作,因此并不像Adam中的vt和mt那样偏置接近于0,这也是为什么我们不要计算ut的bias correction的原因。建议η=0.002,beta1=0.9,beta2=0.999
5.8 Nadam
正如上述所见,Adam可以看做是RMSprop和动量法的结合,NAG是动量法的高阶版本。而Nadam(Nesterov-accelerated Adaptive Moment Estimation)则可以看做是Adam和NAG的组合版本。为了把NAG整合进Adam里,我们需要修正一下动量mt的计算方式。
首先,我们先回顾下动量法的更新公式:
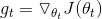


其中,J是目标损失函数,γ是动量衰减因子,η是学习率,上式可以整理为:
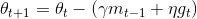
从式子中可以看出,动量法涉及两个部分——历史动量方向一小步和当前梯度方向一小步。NAG考虑了预测信息,能够在当前梯度方向迈出更加精确的一步:
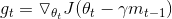

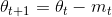
Dozat提出了一种方式修正NAG:相对于应用动量值两次——①更新梯度gt②更新参数θt+1,我们现在应用一个前视(look-ahead)动量直接更新当前参数:


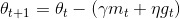
这里,相对于之前利用mt-1的向量,我们使用了当前向量mt做眺望。为了能够把NAG动量加到Adam中,我们替换了先前的动量向量,首先,回忆一下Adam的更新规则:
将mt的表达式带入最后一个公式里:

括号里的第一项是先前步骤的无偏估计,可以替换为:

考虑到look-ahead的动量,将mt-1替换为mt即可得到Nadam的更新规则:

5.9 可视化
所有的优化算法都是同样的初始点出发,可以看出,Adagrad,Adadelta,RMSprop可以很迅速的沿着正确方向收敛,而动量法和NAG开始时会偏离正确收敛方向,但是NAG在后续的step中由于考虑到了预见信息,修正了方向。
在鞍点的表现:SGD,动量法和NAG很难突破鞍点的困境——尽管最后后两者逃离了鞍点。但Adagrad,RMSprop和Adadelta能够很好的快速找到最优负梯度防线,Adadelta拔得头筹。
5.10 如何选择
那么如何选择合适的优化算法呢?
如果数据是稀疏的,你也许可以使用自适应学习率的算法,可帮助你获取更好的性能,而且不需要手动调节学习率参数。
总的来说,RMSprop是Adagrad的扩展——在处理梯度单调衰减问题上。RMSprop,Adadelta,Adam在考虑历史梯度方面,非常相似。目前,Adam是整体最好的选择。
SGD虽然倾向于能找到最小值,但是花费的step要更大一些,对权重初始化比较敏感,不能轻易逃出鞍点,有陷入局部最优解的风险。如果你在训练一个很深很复杂的神经网络,又希望能快速收敛,建议选择上述自适应学习率的优化算法。
6. 并行和分布式下的SGD
TODO
7. 优化SGD的其他技巧
我们讨论一些除了优化算法之外的能提升模型性能的tircks。
7.1 Shuffling and Curriculum Learning
一般情况下,我们在训练模型时,常常会打乱样本的输入顺序——否则,模型可能会捕捉这种顺序信息,最后得到有偏置的模型。
从另一方面来讲,有时候我们目的在于逐渐学习越来越难得问题,这时我们可以先喂给模型相对容易区分学习的样本,然后逐渐提升样本区分难度——这称为Curriculum Learning
7.2 Batch Normalization
为了促进学习过程,我们一般会对模型参数进行零均值单位方差的初始化,在训练过程中,由于参数往不同方向更新,网络层常会损失这种分布,会导致模型收敛较慢,尤其是网络很深的时候。
Batch Normalization会对每个batch的样本重建这种零均值单位方差的数据分布,同时随着反向传播进行适应改变。可以将BN作为网络单独的一层,这样我们可以用更大的学习率而不用太过关心参数初始化问题。BN可以认为是一种正则手段,一般不和dropout一起使用。
7.3 Early Stopping
Hinton言:Early stopping is beautiful free lunch. 如果在训练过程中,你的validation error不再下降时,就应该考虑终止训练。
7.4 Gradient Noise
Neelakantan等人在每个梯度更新中添加了高斯噪音:

并对方差进行了退火处理:
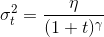
他们指出通过添加高斯噪声能够提高模型在初始化不好时的鲁棒性,帮助训练复杂的网络,认为高斯噪声能够帮助模型逃离局部最优解。
8. 小结
作者在这篇文章中,介绍了各种梯度下降优化算法的变种——动量法,NAG,Adagrad,Adadelta,RMSprop,Adam,Nadam,Adamax等。
作者:Silence_Dong
链接:https://www.jianshu.com/p/0e561f62e64f
来源:
著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。