一年又一年,字节跳动 Lark(飞书) 研发团队又双叒叕开始招新生啦!
【内推码】:GTPUVBA
【内推链接】:https://job.toutiao.com/s/JRupWVj
【招生对象】:20年9月后~21年8月前 毕业的同学
【报名时间】:6.16-7.16(提前批简历投递只有一个月抓住机会哦!)
【画重点】:提前批和正式秋招不矛盾!面试成功,提前锁定Offer;若有失利,额外获得一次面试机会,正式秋招开启后还可再次投递。
点击进入我的博客
字符串操作是计算机程序设计中最常见的行为
13.1 不可变String
String底层是由char[]实现的,是不可变的。
看起来会改变String的方法,实际上都是创建了一个新的String对象,任何指向它的引用都不可能改变它本身的值。
13.2 重载“+”与StringBuilder
重载操作符的意思是,一个操作符被用于不同的类时,被赋予类特殊的含义(String的+和+=是Java中仅有的两个重载过的操作符,而且Java不允许程序员重载操作符)。
由于String的不可变性,如果你通过多个String相加生成一个String的时候,就需要产生多个中间对象,这造成了一定的效率问题。
StringBuilder的好处
- 使用
String对字符串进行操作时,编译器会自动帮你转成StringBuilder来进行操作 - 用
StringBuilder来操作字符串,编译后的代码通常会更加简单,效率更高 - 如果字符串比较简单,可以使用
String让编译器为你构造最终的字符串结果;如果要在循环中使用字符串,那么最好自己创建一个StringBuilder。
13.3 无意识的递归
@Override
public String toString() {
return "Test" + this;
}
上述代码中,由于字符串在拼接的时候会自动调用toString()方法,所以会无意思造成递归。
如果你想打印对象的内存地址,应该调用Object.toString()方法
13.4 String上的操作
略
13.5 格式化输出
13.5.1 System.out.printf()
System.out.printf("%d%n", 123)这种输入方式来自于C,使用特殊的占位符来表示数据将来的位置,这些占位符称作格式修饰符。
13.5.2 System.out.format()
跟System.out.printf()是相同的。
13.5.3 Formatter类
在Java中,所有新的格式化功能都由java.util.Formatter类处理。
Formatter的构造器经过重载可以接受多种输出目的地,不过最常用的还是PrintStream、OutputStream和File。
13.5.4 格式化说明符
%[argument_index$] [flags] [width] [.precision] conversion
- 可选的argument_index是一个十进制整数,用于表明参数在参数列表中的位置。第一个参数由
1$引用,第二个参数由2$引用,依此类推(不要忘记$)。 - 可选flags是修改输出格式的字符集。有效标志集取决于转换类型。
- 可选width是一个非负十进制整数,表明要向输出中写入的最少字符数,不足则用空格代替。默认数据是右对齐,可以通过
-实现左对齐。 - 可选precision是一个非负十进制整数,通常用来限制最大字符数。特定行为取决于转换类型。
- 所需conversion是一个表明应该如何格式化参数的字符。给定参数的有效转换集取决于参数的数据类型。
13.5.5 Formatter转换

13.5.6 String.format()
该方法可以接受Formatter.format()方法一样的参数,但返回一个String对象。
13.6 正则表达式
正则表达式是一种强大而灵活的文本处理工具。使用正则表达式,我们能够以编程的方式,构造复杂的文本模式,并对输入的字符串进行搜索。一旦找到了匹配这些模式的部分,你就能够随心所欲地对它们进行处理。
13.6.1 基础
正则表达式就是以某种方式来描述字符串。
Java和其他语言对反斜线\的处理不同
- 正常反斜线
\:我们需要的就是一个单纯的反斜线,但Java(包括其他语言)中,反斜线也被用来当作转义字符,所以不能直接使用 - 文艺反斜线
\\:第一个反斜线表示转移,第二个表示正常的反斜线 - Java二逼反斜线
\\\\:在正则表达式中,反斜线也需要转义,这是如果要插入一条反斜线这需要这种写法。四个反斜线的作用其实是两两一组,第一组的反斜线作为转义符,第二组的反斜线是正常要插入的反斜线。
String中内建的正则匹配方法
- String#matches()
- String#split()
- String#replaceFirst()
- String#replaceAll()
13.6.2 创建正则表达式
正则表达式完整构造子列表,请参考java.util.regex.Pattern。
字符

字符类

逻辑操作符

边界匹配符

13.6.3 量词
量词:描述了一个模式吸收输入文本的方式:
- 贪婪型:默认设置,贪婪表达式会为所有可能的模式发现尽可能多的匹配,导致此问题的一个经典理由就是假定我们的模式仅能匹配第一个可能的字符组,如果它是贪婪的,那么它会继续往下匹配;
- 勉强型:在贪婪型基础上添加
?,这个量词匹配满足模式所需的最少字符数,又称作最少匹配; - 占有型:在贪婪型基础上添加
+,目前这种类型的量词只有在Java中才可用并且也更高级,当正则表达式被应用于字符串时,它会产生相当多的状态以便在匹配失败时可以回溯,而占有型量词并不保存这些中间状态,因此它们可以防止回溯,它们被用来防止正则表达式失控,因此可以让正则表达式执行起来更有效。
 三种模式对比
三种模式对比
13.6.4 Pattern和Matcher
由于String类功能有限,所以可以通过java.util.regex包下的类实现更加复杂的功能
一般使用方法
// 1.构建Pattern对象
Pattern pattern = Pattern.compile("1[0-9]{10}");
// 2.构建Matcher对象
Matcher matcher = pattern.matcher("18888888888");
// 3.使用Matcher方法
System.out.println(matcher.matches());
Pattern方法
// 构建Pattern对象
Pattern pattern = Pattern.compile(regex);
// 将字符串按照正则表达式分割
pattern.split("18888888888");
// 生成Matcher对象判断是否匹配
pattern.matcher("18888888888");
// 直接验证正则表达式和字符串是否匹配
Pattern.matches("1[0-9]{10}", "18888888888");
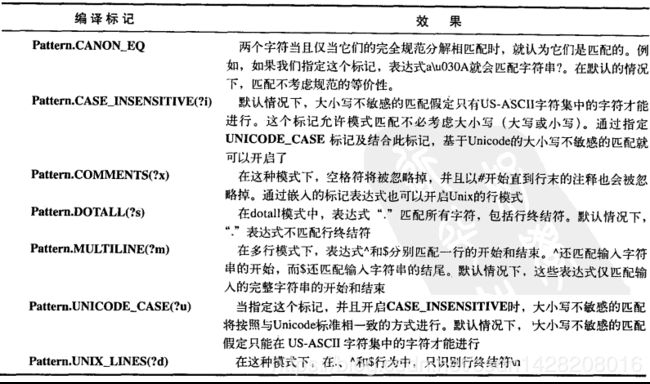
Pattern标记
Pattern类的compile()方法还有另一个版本,它接受一个标记参数数,以调整匹配的行为:
Pattern Pattern.compile(String regex,int flag);。其中的flag来自以下Pattern类中的常量:
Matcher方法
组是用括号划分的正则表达式,可以根据组的编号来引用某个组。组号为0表示整个表达式,组号1表示被第一对括号括起的组,依此类推。因此在下面这个表达式:A(B(C))D中有三个组,组0是ABCD,组1是BC,组2是C。
// 整个字符串是否满足表达式
matcher.matches();
// 判断字符串中是否包含表达式
matcher.lookingAt();
// 遍历字符串
matcher.find();
matcher.find(int start);
// 返回前一次匹配的结果
matcher.group();
matcher.groupCount();
// 返回前一次匹配操作中寻找到的组的起始索引
matcher.start();
// 返回前一次匹配操作中寻找到的组的最后一个字符加一的值
matcher.end();
// 替换所有
matcher.replaceAll();
// 替换第一个
matcher.replaceFirst();
// 渐进式的替换
matcher.appendReplacement();
// 将现在Matcher用于一个新的字符串
matcher.reset();
13.7 扫描输入
到日前为止,从文件或标准输入读取数据还是一件相当痛普的事情。终于,Java SE5新增了Scanner类,它可以大大减轻扫描输入的工作负担。
Scanner有多个重载的构造器,可以接受File、Path、InputStream、String和Readable对象。Readable是Java SE5中新加入的一个接口,表示“具有read()方法的某种东西”。
13.7.1 Scanner的定界符
在默认的情况下,Scanner根据空白字符对输入进行分词,但是你可以用正则表达式指定自己所需的定界符:scanner.useDelimiter();。还有一个delimiter()方法,用来返回当前正在作为定界符使用的Pattern对象。
13.7.2 用正则表达式扫描
Scanner scanner = new Scanner(System.in);
while (scanner.hasNext("(\\d+)@(\\w+)\\.(\\w+)")) {
scanner.next("(\\d+)@(\\w+)\\.(\\w+)");
MatchResult result = scanner.match();
System.out.println("号码:" + result.group(1));
System.out.println("域名:" + result.group(2));
System.out.println("后缀:" + result.group(3));
}
Scanner可以接受Pattern作为参数,可以扫描复杂的数据。
配合正则表达式扫描时要注意:它仅仅针对下一个输入分词进行匹配,如果你的正则表达式中含有定界符,那永远都不可能匹配成功。
13.8 StringTokenizer
已过时!