1.常用函数
(一)函数介绍
事先提供好的一些功能可以直接使用,函数可以在select语句及其子句当中,也可以在update,delete等语句当中。
(二)函数分类
1.字符串函数
1.concat(s1,s2,s3...)
将传入的字符连接成一个字符串,任何字符与null进行连接都是null
select concat('a','b','c');

2.insert(str,x,y,instr)
将字符串str从x位置开始,y个字符长的子串替换为指定的字符
select insert('myxq123',5,3,'lk');
输出:myxqlk
3.left(str,x)和right(str,x)
返回字符串最左边的x个字符,最右边的x个字符,如果第二个参数是null,就不返回任何字符
select left('shanghai',3);
结果:sha
select right('shanghai',3);
结果:hai
4.lpad(str,n,pad)和rpad(str,n,pad)
使用字符串pad对str最左边和最右边的进行填充,直到长度为n个字符长度,一次不够再来一次
select lpad('my',5,123456);
结果:123my
select rpad('my',5,'12345');
结果:my123
select rpad('my',7,123);
结果:my12312
5.trim(str)去掉字符串左右的空隔
select trim(' abcccc ');
结果:abcccc
6.repeat(str,x)
获得str重复x次的结果
select repeat('xyz',4);
结果:xyzxyzxyzxyz
7.replace(str,a,b)
使用字符串b替代字符串str当中的所有字符a
select replace('abcdefg','c','***');
结果:ab***defg
8.substring(str,x,y)/substr(str,x,y)
返回字符串str当中的第x位置起y个字符长度的字符
select substring('abcdefg',3,2);
结果:cd
2.数值函数
1.abs(x)
返回x的绝对值
select abs(-9);
结果:9
2.ceil(x)
向上取整,返回x的顶点值
select ceil(1.2);
结果:2
3.floor(x)
向下取整
select floor(1.6);
结果:1
4.mod(x,y)
f返回x/y的模
select mod(9,2);
结果:1
5.rand()
返回0-1之间的随机值
select rand();
结果:0.6546267295765008
3.日期和时间函数
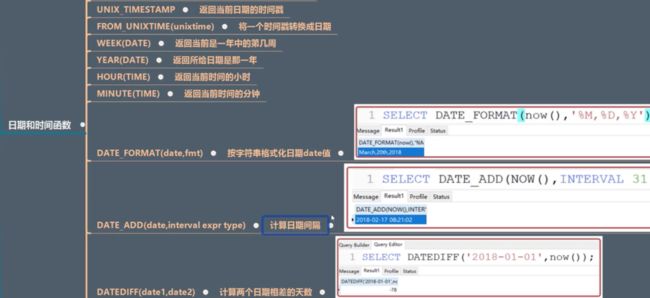
select now();
-- 2019-03-28 16:51:34
select curdate();
-- 2019-03-28
select curtime();
-- 17:09:20
-- 获得unix时间戳
select unix_timestamp();
-- 1553763279
select from_unixtime(1553763279);
-- 2019-03-28 16:54:39
-- 获得当前日期的年月日March,28th,2019
select date_format(now(),'%M,%D,%Y');
-- 当中时间加上256天之后的日期
select date_add(now(),interval 256 day);
select date_add(now(),interval -3 year);
-- 前一个日期减去后一个日期时间差
select datediff('2018-02-05',now());
4.流程函数
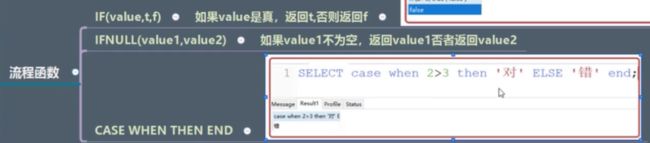
5.其他函数

2.事物
事物是数据库当中一系列操作的集合,每个事物都是不可分割的整体。事物只对DML语句起作用,对DQL语句不起作用。
(一)事物的ACID
原子性(aotomatic):事物包含的所有操作要么全部成功,要么全部失败回滚。
一致性(consistency):让数据保持一定上的合理性
隔离性(isolation):事物与事物之间是有隔离的,当一个事物操作时,其他事物不能操作。
持久性(durability):事物一旦提交就会将这种状态一致保持,就算断电,数据库崩溃也会保持持久性。
(二)事物的使用
mysql默认事物是开启的,当我们在mysql当中写一条SQL语句(默认一条SQL语句是一个事物),回车之后就默认这条事物完成了,如果我们自己想要去写事物的时候,必须要手动的去开启事物,开启事物之后可以提交和回滚。
1.开启事物,提交事物
一般情况下在MYSQL当中,默认一条SQL语句是一个事物,当我们要让多条SQL语句构成一个事物时,就要开启事物。
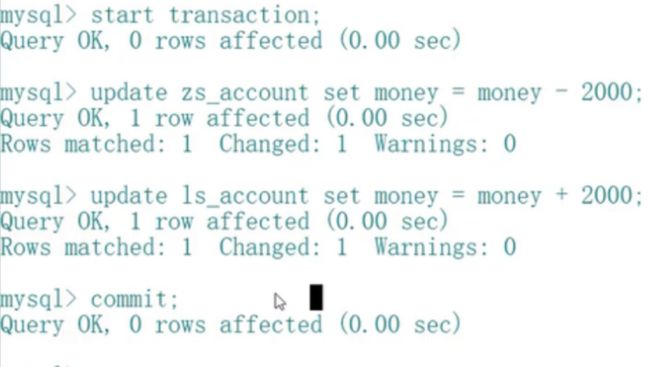
2.事物的回滚
在执行SQL语句的时候出现了错误,可以回滚rollback(当遇到一些突发事件的时候,撤销执行的SQL语句)
(三)事物的并发控制
脏读:读取到另一事物未提交的数据,一般使用read committed
幻读:读取到另一事物添加的数据,一般使用serializable
不可重复读:一个事物范围内两个相同的查询却返回不同的数据(读取到另一事物更新的数据)
(四)事物的隔离级别

read uncommitted
read committed
repeatable read
serializable
(五)查看数据库的隔离级别
********************MAC下********************
select @@global.transaction_isolation,@@transation_isolation;
*********************window下***************************
select @@global.tx_isolation,@@tx_isolation;
(六)设置数据库的隔离级别
set global transaction isolation level 隔离级别;
3.权限操作
(一)权限及权限管理
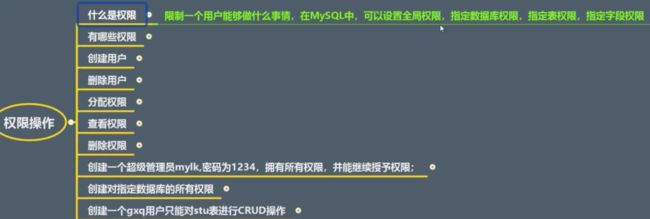
(二)创建删除用户
create user 'mysql1234'@'localhost' identified by '1234';
drop user 'mysql1234'@'localhost'
(三)分配权限

grant 权限(columns) on 数据库对象 to 用户 identified by '密码' with grant option;
-- 创建用户
create user 'mysql1234'@'localhost' identified by '1234';
drop user 'mysql1234'@'localhost';
-- 创建超级管理员mylk,密码1234,拥有所有的权限,并能继续授予权限
create user 'mylk'@'localhost' identified by '1234';
-- all privileges所有的权限,*.*所有数据库当中的所有表,grant option这个用户还可以给其他客户授权
-- mac下
grant all privileges on *.* to mylk@localhost with grant option;
-- window下
grant all privileges on *.* to mylk@localhost identified by '1234' with grant option;
flush privileges;
4.视图操作

视图是一个虚拟表,其内容是查询出来的数据。查询出来的数据组成了视图
(一)创建视图

创建视图时可以指定参数:algorithm
merge:处理方式是替换是,对视图当中的操作会影响基表当中的数据。
temptable:处理方式具化式,由于数据存储在临时表当中,故不可进行更新操作。
undefined:
******************************************************
with check option:检查修改或添加的数据是否符合内查询。
select * from emp where salary>2000;
**********************创建视图***********************
create view emp_salary_view as (select * from emp where salary>2000);
********************视图也是一种表(虚拟表)*****************************
select * from emp_salary_view where job='经理';
(二)修改视图
create or replace view emp_salary_view as (select * from emp );
(三)删除视图
drop view emp_salary_view;
(四)视图机制
select * from emp_salary_view;
替换式:操作视图时,视图名直接被视图定义给替换掉
select * from (select * from emp where salary>2000);
具化式:SQL先获得视图的执行结果,该结果形成一个中间结果暂时村与内存当中,外层select语句就调用了这些中间结果(临时表),即:内层select查询出来的结果以表的形式存储在内存当中,成为虚拟表,外层查询的时候直接查虚拟表视图。
select* from emp_salary_view;
(五)视图不可更改部分

当视图当中有字段不是来自基表,就不能修改。
select avg(salary) from emp ;
create algorithm=merge view a_s_e as (select avg(salary) from emp);
5.存储过程
(一)什么是存储过程:
存储过程是一组可编程的函数,是为了完成特定功能的SQL语句集。
存储过程就是具有名字的一段代码,用来完成一个特定的功能。
创建的存储过程保存在数据库的数据字典当中。
(二)为什么要使用存储过程
将重复性很高的一些操作封装到一个存储过程当中:werer zs,where ls
批量处理
统一接口,确保数据的安全性:对插入的数据进行校验,符合条件才可以插入
相对与oracle来说,mysql的存储过程使用较少,功能较弱。
(三)存储过程的调用和创建
delimiter的作用:将标准分隔符';'修改为指定的分隔符。

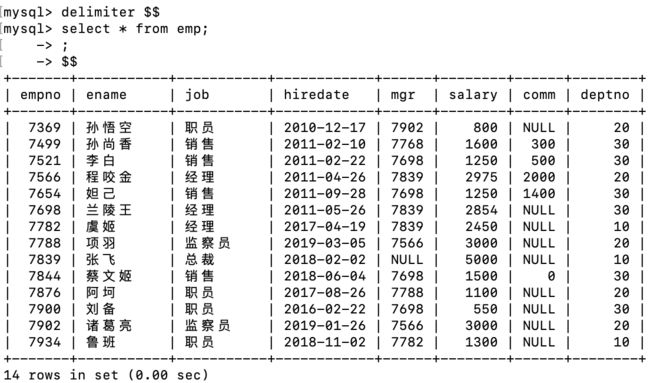
-- 修改标准分隔符
-- 创建存储过程
delimiter $$
create procedure show_emp()
begin
select * from emp;
end $$
-- 使用存储过程
delimiter ;
call show_emp();
call show_emp;
-- 查看和删除的时候不要加存储过程名字的'()'
show procedure status where db='my_test';
show create procedure show_emp;
drop procedure show_emp;

(四)存储过程变量

CREATE PROCEDURE test ()
BEGIN
-- 申明变量
DECLARE res VARCHAR (255) DEFAULT '';
DECLARE x,y INT DEFAULT 0;
-- 在存储过程当中更改变量值要使用set
set x=3;
set y=4;
declare avgRes double default 0;
-- 将查询出来的值赋值给avgRes
SELECT avg(salary) into avgRes FROM emp;
END;
(五)存储过程参数
三种类型:in,out,inout
-- 根据传入的名称,获取对应的信息
create procedure getName(in name varchar(255))
begin
select * from emp where ename=name;
end;
call getName('鲁班');
**********************************************************
-- 给我一个名字,我可以把他的薪水给你,out表示里面查询出的语句返回一个值,用out后面的参数接受
create procedure getSalary(in name varchar(255),out salary1 int)
begin
select salary into salary1 from emp where ename=name;
end;
call getSalary('鲁班',@s);
select @s from dual;
***********************************************************
create procedure test1(inout num int ,in inc int)
begin
set num=num+inc;
end;
set @num1=20;
call test1(@num1,10);
select @num1;
(六)存储过程语句

6.自定义函数
(一)自定义函数
-- 自定义函数
-- 随机生成一个指定个数的字符串
create function random_str(n int) returns varchar(255)
-- 不加下面的一个不知道为啥报1418错误
DETERMINISTIC
begin
-- 声明一个str,52个字母
declare str varchar(100) default 'sfegrbbckbsfjglkdfdf';
-- 记录当前是第几个
declare i int default 0;
-- 生成的结果
declare res_str varchar(255) default '';
while i(二)存储过程构建千万条数据
create table emp1(
id int,
name varchar(255),
age int
);
create table emp2(
id int,
name varchar(255),
age int
);
create procedure insert_emp1(in startNum int ,in max_num int)
begin
-- 定义一个变量记录当前的是第几条数据
declare i int default 0;
set autocommit=0;-- 设置不让它自动提交
repeat
insert into emp1 values(startNum+i,random_str(5),floor(10+rand()*30));
set i=i+1;
until i=max_num
end repeat;
commit;-- 提交上面所有的sql语句
end;
create procedure insert_emp2(in startNum int ,in max_num int)
begin
-- 定义一个变量记录当前的是第几条数据
declare i int default 0;
repeat
insert into emp1 values(startNum+i,random_str(5),floor(10+rand()*30));
set i=i+1;
until i=max_num
end repeat;
end;
call insert_emp1(100,10000000);
插入10000000条数据大概花费:
7.索引
索引用于快速查找出某个列当中有一特定值的行
不使用索引的时候,mysql会进行全表扫描
表越大,查询数据所花费的时间越久
如果表当中查询的列有一个索引,mysql就可以快速到达某个位置然后去索引数据文件,而不必查询所有的数据,会节约很多时间。
(一)索引的优劣
优势:
索引类似于大学图书馆建书目录,提高数据检索效率,降低数据库的IO成本,通过索引对数据库进行了排序,降低数据排序的成本,降低了cpu的消耗。
劣势:
实际上索引也是一张表,该表保存了主键于索引字段,并指向实体表的记录,所以索引列也是要占空间的,虽然索引大大提高了查询速度,但同时会降低更新表的速度,如对表进行insert,update,delete
(二)索引的分类
单值索引:一个索引只包含单个列,一个表可以有多个单值索引。
唯一索引:索引列的值必须唯一,允许为空值。
复合索引:一个索引可以包含多个列,index multildx(id,name,age)
全文索引:只有在mysql引擎上才能使用,只有char,varchar,text类型字段上才可以使用全文索引
空间索引:空间索引是对空间数据类型的字段建立的索引。
(三)索引操作
创建索引
删除索引
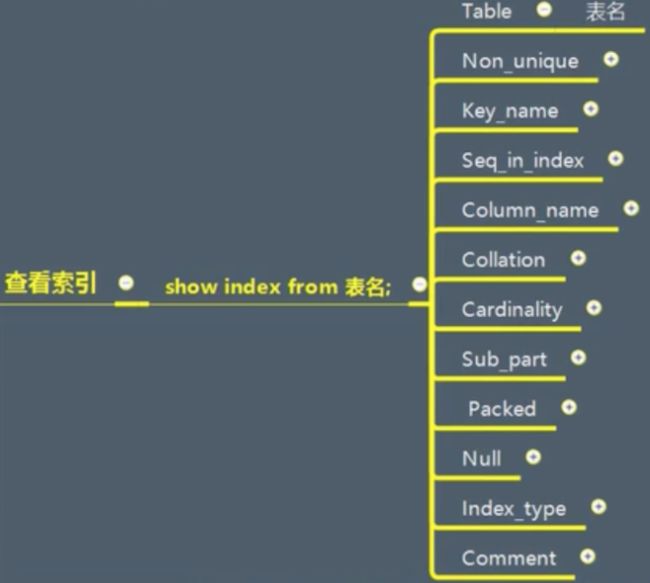
查看索引
自动创建索引
1.创建索引
create index 索引名字 on table(column);
create index index_salary on table emp(salary);
2.删除索引
drop index 索引名 on 表名;
3.查看索引
show index from 表名;
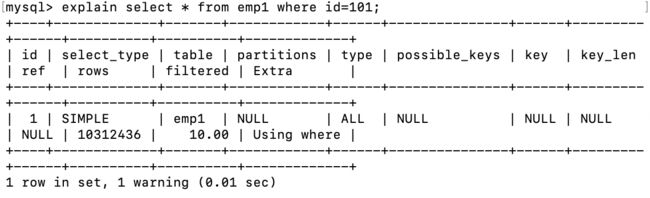
explain select * from emp1 where id=101;

4.自动创建索引
当在表上面创建了主键之后,会自动创建一个对应的唯一索引,在表上定义了一个外键之后,会自动创建一个普通索引,需要注意的是自动创建的索引,在navicat当中查看索引式看不到。
(四)索引结构(索引的内部实现机制)
在添加索引之后,会创建索引构成的二维表,其中的数据会先进行排序
当数据库引擎采用Innodb时,索引方法只能是B+树索引,因为Innodb不支持hash索引。
hash索引:采用一定的hash算法,把键值转换为新的hash值(hashcode),检索时不需要像B+索引那样,从根节点到枝节点,然后才能访问到页面节点这样进行多次的IO操作,所以hash索引的查询效率远远高于B-tree索引。Hash索引是作用在memory引擎上的。
(五)那些情况需要创建/不创建索引
**********************需要创建索引****************************
主键自动创建唯一索引,外键自动作为普通索引
频繁作为查询条件的字段应该创建索引
查询当中排序的字段,若加索引,会大大提升排序的速度
查询当中要分组或者统计的字段可以添加所以
**********************无需创建索引****************************
频繁更新的字段不适合建立索引,因为每次更新不仅仅更新了表还更新了索引
where条件里面用不到的字段不需要创建索引。
表里面的记录太少
经常要增删改的表
如果某个列当中包含大量重复的内容(gender),为它建立索引就没有太大的效果