概述
后端业务平台经常遇到数据导出报表的需求,常用的方案是使用 excel.js + FileSaver.js处理。excel.js 支持在 node.js 服务端使用,也支持在浏览器端使用。在浏览器端使用时,数据量少的情况下,使用 workbook.xlsx.writeBuffer 可以轻松构建 Blob 数据,但数据量一旦增多,这个方法就会导致浏览器卡顿,甚至崩溃。但实际使用中,一旦数据量超过2万,浏览器崩溃的概率就大大增加了。
回到根源,正确的做法肯定是解析一段数据,创建一段 Blob,excel.js 不支持,我们也只能另谋出路了。
CSV(Comma-Separated Values),又称为“逗号分隔值文件格式”,大部分的 Excel 软件都支持解析该格式的文件。他的语法类似下面这样:
姓名,年龄,职位
张三,30,前端工程师
李四,31,产品经理
王五,30,JAVA工程师
其中,第一行为表头,后面的为每行数据,使用 Excel 软件打开效果如下:

所以,我们可以使用 CSV 格式导出数据。
方案思路
我们将按照下面的步骤实现数据 Excel 导出:
- 第一步,把数据按照一定的数量拆分为若干数据片段:我们暂称之为“分片”,如:1000000 条数据,单次处理 10000 条,则可以拆分为 100 个分片。拆分的意义在于,我们可以控制单次处理的数据量,确保浏览器不会因为处理过多数据而卡死;
- 第二步,创建一个
cvsArray = []的变量,用以存放将来生成的 csv 片段,该变量将存储一行一行的字符串,字符串的格式如:李四,31,产品经理\n; - 第三步,创建表头行,内容如:
姓名,年龄,职位\n; - 第四部,遍历分片:遍历时,我们通常需要格式化数据(如:格式转换、千分位修正等),这一步将把每个分片转换为 CSV 片段;
- 第五步,创建 Blob 对象,语法为:
const blob = new Blob([String.fromCharCode(0xfeff), ... cvsArray], { type: "text/plain;charset=utf-8"}); - 第六步,保存为 CSV 格式的文件:
FileSaver.saveAs(blob, '导出.csv');
实现代码
示例代码为 Vue.js 工程,需要使用到 mockjs 和 file-saver 两个 package。
首先,我们创建一个生成指定长度数据的方法,该方法用于模拟后端接口返回数据:
import Mock from 'mockjs';
// 创建指定数量的数据(模拟后端接口)
export const getData = async (limit) => {
return new Promise((resolve, reject) => {
try {
const Random = Mock.Random;
// 创建指定个数的随机数据
const data = new Array(limit).fill('').map((_, index) => {
return {
id: `200820-${index}`,
username: Random.cname(),
url: Random.url('http'),
price: Random.float(0, 110000, 0, 2),
createAt: Random.datetime('yyyy-MM-dd HH:mm:ss'),
};
});
resolve(data);
} catch (error) {
reject(error);
}
});
};
然后是导出代码:
// 导出数据为 CSV 格式
export const exportCsv = async (total = 0, size = 1000, onProcess = () => {}) => {
try {
if (!total) throw '无数据';
// 分片
const step = Math.ceil(total / size);
// CSV 缓存
let cvsArray = [];
// 创建表头[一般表头由外部传入]
cvsArray.push(['编号', '用户名', '官网', '报价', '创建日期'].join() + '\n');
// 遍历分片
for (let i = 0; i < step; i++) {
await new Promise(async (resolve, reject) => {
try {
// 创建指定个数的随机数据
const data = await getData(size);
// 格式化为 CSV 字符串
const csv = data.map(row => {
cvsArray.push(Object.values(row).join() + '\n');
});
// 统计进度
const process = (i / step) * 100;
console.log(`进度 ${Math.round(process)}%`);
onProcess(process);
// 适当暂停,避免页面无法执行渲染
await new Promise((_resolve) => {
setTimeout(() => _resolve(true), 50);
});
resolve(true);
} catch (error) {
reject(error);
}
});
}
// 遍历完成时,固定进度为 100%
onProcess(100);
const blob = new Blob([String.fromCharCode(0xfeff), ...cvsArray], {
type: "text/plain;charset=utf-8"
});
await FileSaver.saveAs(blob, 'file.csv');
return true;
} catch (error) {
return Promise.reject(error);
}
};
页面上会添加一个按钮,点击按钮执行导出:
//
// 创建模拟数据
async exportCsv() {
try {
this.pending = true;
await app.exportCsv(10000 * 120, 2000, (process) => {
// 进度条更新
this.csvProcess = process;
});
} catch (error) {
alert(error);
} finally {
this.pending = false;
}
},
上面的代码将导出 120万条数据,单次处理 2000 条数据。
测试验证

导出耗时 72866.2348 毫秒,约 72.87 秒。

由于数据字段比较少,生成的文件体积并不是很大。
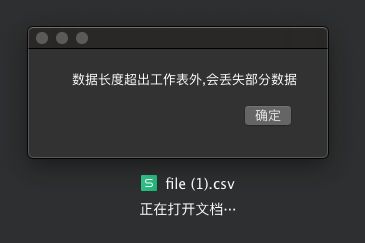
很遗憾的是,使用的 WPS 软件无法打开超过这个数量级的数据。选择【确定】,最大只能显示 104 万 8 千条数据。

注意:
1、CSV 格式可能导致某些数字以科学计数法显示(如:银行卡号、身份证号等),做法是,为数据添加 \t 之类的不可见字符;
2、导出的单元格是没有宽度的,这个知道如何处理的大神可以指教下;
总结
- Blob 对象的性能的确很赞,处理大数据时也不会卡死;
- 应该适当小的划分数据片段,减少单位时间内浏览器的负荷;
- 这种数据导出,个人感觉应使用串行调用,意义在于:① 可以避免过多的分片导致接口响应超时;② 可以保证浏览器同一时间不用处理过多的数据;