爬虫(三)—— python 爬虫小试
一、基本概念
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
二、python 爬虫函数解析
2.1 requests 请求网页
requests库的7个主要的方法
| 函数 | |
|---|---|
| requests.request() | 构造一个请求,支撑一下各方法的基本方法 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head() | 获取HTML网页头信息的方法,对应于HTTP的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() | 向HTML网页提交局部修改请求,对应于HTTP的PATCT |
| requests.delete() | 向HTML网页提交删除请求,对应于HTTP的DELETE |
2.2 request参数说明
method: 支持 GET, OPTIONS, HEAD, POST, PUT, PATCH, or DELETE.
url: str类型
params: (可选) Dict, list of tuples or bytes to send.
params={'q': 'python', 'cat': '1001'}
data: (可选) Dictionary, list of tuples, bytes, or file-like
requests默认使用application/x-www-form-urlencoded对POST数据编码
data={'form_email': '[email protected]', 'form_password': '123456'}
json: (可选) 如果要传递JSON数据,可以直接传入json参数:
params = {'key': 'value'}
requests.request(method="post", url="", json=params) # 内部自动序列化为JSON
headers: (可选) dict
cookies: (可选) dict
cs = {'token': '12345', 'status': 'working'}
requests.request(method="get", url="", cookies=cs)
files: (可选) 上传文件需要更复杂的编码格式,但是requests把它简化成files参数
在读取文件时,注意务必使用’rb’即二进制模式读取,这样获取的bytes长度才是文件的长度
upload_files = {'file': open('report.xls', 'rb')}
requests.request(method="post", url="", files=upload_files)
auth: (可选) Auth tuple to enable Basic/Digest/Custom HTTP Auth.
timeout: (可选) 访问超时, float(wait for server to send data ) or tuple(connect timeout, read timeout)
allow_redirects: (可选) 重定向:Boolean. 默认为true。 Enable/disable GET/OPTIONS/POST/PUT/PATCH/DELETE/HEAD redirection.
proxies: (可选) 设置代理,可抓取所有http和https请求
proxies = {
'http': 'http://10.100.57.47:8001',
'https': 'http://10.100.57.47:8001',
}
requests.get('https://testerhome.com/', proxies=proxies)
verify: (可选) Boolean,控制是否验证,默认为True。当verify为True时, 如果想解析https内容,需在Cert参数中添加证书路径
stream: (可选) 如果为``False’’,则将立即下载响应内容。
cert: (可选) string 或 元组
string: 为ssl客户端证书文件(.pem)的路径
元组:(“证书”,“密钥”)配对
2.3 response参数说明
返回状态码:r.status_code
Response Body:
str: r.text
Bytes: r.content
Dict: r.json()
Response Header(Dict): r.headers
自动检测编码:r.encoding
响应时间: int(r.elapsed.microseconds/1000) 毫秒
2.4 BeautifulSoup解析网页
Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。官方解释如下:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
我们使用Beautiful Soup对获取的网页进行解析,然后解析目标字段即可。
三、实践:爬取数据
3.1 选择某家为目标网站,爬取房价信息

3.2 分析网页,对相应的字段进行解析
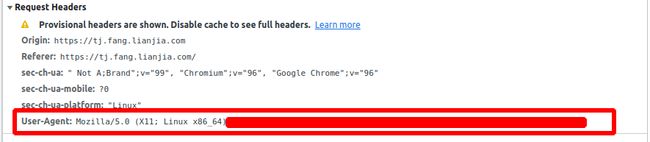
按F12打开后台数据 3.3 查询自己的header
3.3 查询自己的header
按F12然后点network,之后再按F5,然后就会看到“name”这里,我们点击name里面的任意文件即可。
之后右边有一个headers,点击headers找到request headers,这个就是浏览器的请求报头了
然后复制其中的user-agent,其他的cookie还有Accept可以要也可以不要,主要是伪装成浏览器,所以我就用了user-agent
完整代码如下:
from bs4 import BeautifulSoup
import numpy as np
import requests
from requests.exceptions import RequestException
import pandas as pd
def decode_page(url, page):
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36"}
html1 = requests.request("GET", url, headers=headers, timeout=10)
html1.encoding = 'utf-8' # 加编码,重要!转换为字符串编码,read()得到的是byte格式的
html = html1.text
except RequestException: # 其他问题
print('第{0}读取网页失败'.format(page))
return None
html = str(html)
if html is not None:
soup = BeautifulSoup(html, 'lxml')
houses = soup.select('.resblock-list-wrapper li') # 房子列表
for j in range(len(houses)): # 遍历每一个房子
house = houses[j]
"名字"
recommend_project = house.select('.resblock-name a.name')
recommend_project = [i.get_text() for i in recommend_project]
recommend_project = ' '.join(recommend_project)
"类型"
house_type = house.select('.resblock-name span.resblock-type')
house_type = [i.get_text() for i in house_type] # 写字楼,底商...
house_type = ' '.join(house_type)
"房形"
house_com = house.select('.resblock-room span')
house_com = [i.get_text() for i in house_com] # 2室 3室
house_com = ' '.join(house_com)
"面积"
house_area = house.select('.resblock-area span')
house_area = [i.get_text() for i in house_area] # 2室 3室
house_area = ' '.join(house_area)
"销售状态"
sale_status = house.select('.resblock-name span.sale-status')
sale_status = [i.get_text() for i in sale_status] # 在售,在售,售罄,在售...
sale_status = ' '.join(sale_status)
"大地址"
big_address = house.select('.resblock-location span')
big_address = [i.get_text() for i in big_address] #
big_address = ''.join(big_address)
"具体地址"
small_address = house.select('.resblock-location a')
small_address = [i.get_text() for i in small_address] #
small_address = ' '.join(small_address)
"优势。"
advantage = house.select('.resblock-tag span')
advantage = [i.get_text() for i in advantage] #
advantage = ' '.join(advantage)
"均价:多少1平"
average_price = house.select('.resblock-price .main-price .number')
average_price = [i.get_text() for i in average_price] # 16000,25000,价格待定..
average_price = ' '.join(average_price)
"总价,单位万"
total_price = house.select('.resblock-price .second')
total_price = [i.get_text() for i in total_price] # 总价400万/套,总价100万/套'...
total_price = ' '.join(total_price)
information = [recommend_project, house_type, house_com, house_area, sale_status, big_address,
small_address, advantage,
average_price, total_price]
information = np.array(information)
information = information.reshape(-1, 10)
information = pd.DataFrame(information,
columns=['名称', '类型', '大小', '主要面积', '销售状态', '大地址', '具体地址', '优势', '均价',
'总价'])
information.to_csv('天津房价.csv', mode='a+', index=False, header=False) # mode='a+'追加写入
print('第{0}页存储数据成功'.format(page))
else:
print('解析失败')
if __name__ == '__main__':
for i in range(1,150):
url = "https://tj.fang.lianjia.com/loupan/pg" + str(i) + "/"
decode_page(url, i)
time.sleep(0.01)
爬取结果:

可能遇到的问题:
- 看到返回结果,需要打开后台数据后进行刷新即可
- 爬取其他城市只需修改相应的网址即可
- 遇到过于频繁的爬取,会触发人机认证的反扒机制,手动认证后即可继续进行
enjoy!