杂碎知识点1
大四开始找工作后遇到的面试题进行汇总,因为之前记录的都是在有道云中,复制到出现格式的问题,大致修补了一下,后续继续上传。
1、Integer缓存池问题
详细:https://www.cnblogs.com/Pjson/p/8777940.html
当给Integer赋值在-128~127之间的时候会从缓存池中获取值,这个时候用==比较俩值是相等的,超过这个范围用==比较就返回false。
2、left join、right join、inner join
3、redis面试相关的问题:
1)缓存雪崩
同一时间内有大量的key过期,导致访问直接经过数据库,使数据库崩溃
- 缓存穿透
缓存穿透是指查询一个一定不存在的数据。由于缓存不命中,并且出于容错考虑,如果从数据库查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,失去了缓存的意义。
3)缓存击穿
同一时间内大量的请求热点数据,但是该热点数据在这个事件过期导致大量的请求走数据库 导致数据库崩溃
4)redis中的哨兵模式(集群中设置哨兵可以实现主节点宕掉后进行快速的切换,配置 sentinel.conf文件 使用命令启动哨兵redis-sentinel sentinel.conf)
5)集群环境中可以使用redis来实现分布式锁
https://mp.weixin.qq.com/s?__biz=MzI4Njg5MDA5NA==&mid=2247484609&idx=1&sn=4c053236699fde3c2db1241ab497487b&chksm=ebd745c0dca0ccd682e91938fc30fa947df1385b06d6ae9bb52514967b0736c66684db2f1ac9&token=177635168&lang=zh_CN#rd
4、消息队列
https://www.zhihu.com/question/54152397?sort=created
5、springBoot实现自动装配的原理
在springboot的启动主方法 必不可少的@SpringBootApplication注解,在这个注解上有个@EnableAutoConfiguration注解,这个注解之上有个@import(AutoConfigurationImportSelector.class)
面试应该怎么说
Spring Boot启动的时候会通过@EnableAutoConfiguration注解找到META-INF/spring.factories配置文件中的所有自动配置类,并对其进行加载,而这些自动配置类都是以AutoConfiguration结尾来命名的,它实际上就是一个JavaConfig形式的Spring容器配置类,它能通过以Properties结尾命名的类中取得在全局配置文件中配置的属性如:server.port,而XxxxProperties类是通过@ConfigurationProperties注解与全局配置文件中对应的属性进行绑定的。
https://www.baidu.com/link?url=SOBm5Fpn7rfUhPna-FM0qJ3-41-D0N3wJqWlyzbLPKqZVr54k6KK1pfJUIjycPN82p2npaEclIWW4K2w4n4IDEGZvGusmLUhEqrSl0mwatK&wd=&eqid=e05faa350002dfdf000000035f4b61ae
6、Ehcache实现缓存
ehcache分为on-heap和off-heap。
on-heap使用jvm内存,可通过JVM的GC管理。
off-heap不使用jvm内存,通过ehcache自行配置管理。
7、java设计模式
http://c.biancheng.net/view/1317.html
8、八种基本类型
byte,sort,int,long,float,double,boolean,char
9、接口和抽象类区别
1.抽象类可以有构造方法,接口中不能有构造方法。
2.抽象类中可以有普通成员变量,接口中没有普通成员变量
3.抽象类中可以包含非抽象的普通方法,接口中的所有方法必须都是抽象的,不能有非抽象的普通方法。
- 抽象类中的抽象方法的访问类型可以是public,protected和(默认类型,虽然
eclipse下不报错,但应该也不行),但接口中的抽象方法只能是public类型的,并且默认即为public abstract类型。
抽象类中可以包含静态方法,接口中不能包含静态方法
抽象类和接口中都可以包含静态成员变量,抽象类中的静态成员变量的访问类型可以任意,但接口中定义的变量只能是public static final类型,并且默认即为public static final类型。
一个类可以实现多个接口,但只能继承一个抽象类。
10、Joinpoint和ProceedingJionpoint
https://blog.csdn.net/qq_15037231/article/details/80624064
/**
* 操作内容和类型
* 难点:执行的方法不同 要获取的操作内容和类型也不同
*
* 通过自定义注解
*
* 获取注解的值 连接点对象
* 1.通过连接点对象获取方法签名对象
* 2 通过方法签名对象 获取方法对象
* 3 获取方法上的注解
*/
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
LogAnnotation annotation = method.getAnnotation(LogAnnotation.class);
cmfzLog.setLogContent(annotation.content());
cmfzLog.setLogType(annotation.type());

Object proceed() throws Throwable //执行目标方法
Object proceed(Object[] var1) throws Throwable //传入的新的参数去执行目标方法
11、线程的创建
https://www.cnblogs.com/songshu120/p/7966314.html
1、实现Runnable接口实现run方法 使用Thread t1 = new Thread(task1); task1就是实现Runnable接口的类
2、继承Thread 类,重写run方法,new 该类 使用start方法
3、通过Callable和Future创建线程
Callable和Runnable区别:https://www.cnblogs.com/baizhanshi/p/6425209.html
12、executors与threadPoolExecutor区别
https://blog.csdn.net/weixin_38852633/article/details/91210491
13、SpringIOC的加载顺序?
https://blog.csdn.net/qq_34203492/article/details/83865450
14、List线程安全的集合?
Vector、 CopyOnWriteArrayList(读不加锁写加锁)、
HashTable、ConcurrentHashMap (分段锁、Segment对象加锁)
15、redis的数据结构
string list set hash
16、线程池的四种创建方式
https://www.cnblogs.com/lanseyitai1224/p/7895652.html
newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
如何创建线程池?
《阿里巴巴Java开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 new ThreadPoolExecutor 实例的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。

查看源码可知:
queueCapacity的值为int最大值
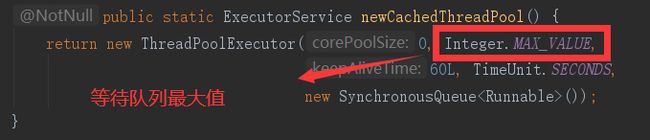
17、线程池的参数
https://www.imooc.com/article/5887
corePoolSize 用于指定核心线程数量
maximumPoolSize 指定最大线程数
keepAliveTime 指定线程空闲后的最大存活时间
线程池参数讲解:https://blog.csdn.net/tryingpfq/article/details/106146578
最大线程数设置:
1、CPU密集型:任务需要强大的运算能力,CPU一直加速运行,设置为CPU核心数 + 1
2、IO密集型(读写请求多的:mysql redis):①、CPU核心数 * 2
②、CPU核心数 / 1- 阻塞系数(0.8~0.9) {适用于IO阻塞的场景}
阻塞队列:
https://blog.csdn.net/u014590757/article/details/80362577

拒绝策略:

18、jvm

19、堆和栈的区别
20、http协议
https://www.cnblogs.com/an-wen/p/11180076.html
工作流程
- 浏览器向 DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;
- 解析出 IP 地址后,根据该 IP 地址和默认端口 80,和服务器建立TCP连接;
- 浏览器发出读取文件(URL 中域名后面部分对应的文件)的HTTP 请求,该请求报文作为 TCP 三次握手的第三个报文的数据发送给服务器;
- 服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;
- 释放 TCP连接;
- 浏览器将该 html 文本并显示内容;
请求协议(请求格式)
1、请求行
2、请求头
3、空行
4、请求数据
21、SpringMVC执行过程

Http 请求到 DispatcherServlet
(1) 客户端请求提交到 DispatcherServlet。
HandlerMapping 寻找处理器
(2) 由 DispatcherServlet 控制器查询一个或多个 HandlerMapping,找到处理请求的 Controller。
调用处理器 Controller
(3) DispatcherServlet 将请求提交到 Controller。
Controller 调用业务逻辑处理后,返回 ModelAndView
(4)(5)调用业务处理和返回结果:Controller 调用业务逻辑处理后,返回 ModelAndView。
DispatcherServlet 查询 ModelAndView
(6)(7)处理视图映射并返回模型: DispatcherServlet 查询一个或多个 ViewResoler 视图解析器, 找到 ModelAndView 指定的视图。
ModelAndView 反馈浏览器 HTTP
(8) Http 响应:视图负责将结果显示到客户端。
22、数据结构
https://www.cnblogs.com/xilin/archive/2012/07/23/2605185.html
常用数据结构 :数组(静态数组、动态数组)、线性表、链表(单向链表、双向链表、循环链表)、队列、栈、树(二叉树、查找树、平衡树、线索、堆)、
图等的定义、存储和操作。
数组(Array)
数组是一种聚合数据类型,它是将具有相同类型的若干变量有序地组织在一起的集合。数组可以说是最基本的数据结构,在各种编程语言中都有对应。一个数组可以分解为多个数组元素,按照数据元素的类型,数组可以分为整型数组、字符型数组、浮点型数组、指针数组和结构数组等。数组还可以有一维、二维以及多维等表现形式。 [5]
栈( Stack)
栈是一种特殊的线性表,它只能在一个表的一个固定端进行数据结点的插入和删除操作。栈按照后进先出的原则来存储数据,也就是说,先插入的数据将被压入栈底,最后插入的数据在栈顶,读出数据时,从栈顶开始逐个读出。栈在汇编语言程序中,经常用于重要数据的现场保护。栈中没有数据时,称为空栈。 [5]
队列(Queue)
队列和栈类似,也是一种特殊的线性表。和栈不同的是,队列只允许在表的一端进行插入操作,而在另一端进行删除操作。一般来说,进行插入操作的一端称为队尾,进行删除操作的一端称为队头。队列中没有元素时,称为空队列。 [5]
链表( Linked List)
链表是一种数据元素按照链式存储结构进行存储的数据结构,这种存储结构具有在物理上存在非连续的特点。链表由一系列数据结点构成,每个数据结点包括数据域和指针域两部分。其中,指针域保存了数据结构中下一个元素存放的地址。链表结构中数据元素的逻辑顺序是通过链表中的指针链接次序来实现的。 [5]
树( Tree)
树是典型的非线性结构,它是包括,2个结点的有穷集合K。在树结构中,有且仅有一个根结点,该结点没有前驱结点。在树结构中的其他结点都有且仅有一个前驱结点,而且可以有两个后继结点,m≥0。 [5]
图(Graph)
图是另一种非线性数据结构。在图结构中,数据结点一般称为顶点,而边是顶点的有序偶对。如果两个顶点之间存在一条边,那么就表示这两个顶点具有相邻关系。 [5]
堆(Heap)
堆是一种特殊的树形数据结构,一般讨论的堆都是二叉堆。堆的特点是根结点的值是所有结点中最小的或者最大的,并且根结点的两个子树也是一个堆结构。 [5]
散列表(Hash)
散列表源自于散列函数(Hash function),其思想是如果在结构中存在关键字和T相等的记录,那么必定在F(T)的存储位置可以找到该记录,这样就可以不用进行比较操作而直接取得所查记录。 [5]
23、SQL的执行顺序
https://www.cnblogs.com/yuanshuo/p/11549251.html
https://jingyan.baidu.com/article/d5c4b52b97ea50da570dc510.html
(1)from
(3) join
(2) on
(4) where
(5)group by(开始使用select中的别名,后面的语句中都可以使用)
(6) avg,sum....
(7)having
(8) select
(9) distinct
(10) order by
24、volatile关键字的作用
https://www.cnblogs.com/zhengbin/p/5654805.html
1、可见性:是指线程之间的可见性,一个线程修改的状态对另一个线程是可见的。
2、非原子性:原子是世界上的最小单位,具有不可分割性。
3、禁止指令重排:在java代码编译器可能会出现指令重排的情况,volital可以禁止
25、sleep和wait的区别
https://blog.csdn.net/qq_40531768/article/details/89306532
1、wait() 方法属于Object类,sleep属于Thread类
2、wait() 方法释放同步锁,sleep方法不会释放同步锁
3、wait() 方法一半与notify() 和notifyAll() 一块使用
4、sleep() 方法需要捕获异常,而wait() 、notify() 、notifyAll() 不用捕获
26、多态的几种写法
三种:方法的重载,继承或实现接口,父类引用指向子类对象
27、端口号
oracle:1521
mysql:3306
redis:6379
ES:9200http端口,9300服务端口
hdfs:9000
haddop namenode:50070web浏览器的访问端口
28、事务的隔离级别
https://blog.csdn.net/zhouym_/article/details/90381606
29、单例的代码实现


30、什么情况回造成死锁
https://blog.csdn.net/Crazypokerk_/article/details/89534641?utm_medium=distribute.pc_relevant.none-task-blog-OPENSEARCH-1.add_param_isCf&depth_1-utm_source=distribute.pc_relevant.none-task-blog-OPENSEARCH-1.add_param_isCf
循环等待的时候回造成死锁
死锁的产生
首先,明确概念性问题,什么是 死锁(DeadLock)?
所谓死锁是指多个进程因竞争资源而造成的一种僵局(互相等待),若无外力作用,这些进程都将无法向前推进。死锁产生的4个必要条件:
- 互斥条件:进程要求对所分配的资源(如打印机)进行排他性控制,即在一段时间内某 资源仅为一个进程所占有。此时若有其他进程请求该资源,则请求进程只能等待。
- 不剥夺条件:进程所获得的资源在未使用完毕之前,不能被其他进程强行夺走,即只能 由获得该资源的进程自己来释放(只能是主动释放)。
- 请求和保持条件:进程已经保持了至少一个资源,但又提出了新的资源请求,而该资源 已被其他进程占有,此时请求进程被阻塞,但对自己已获得的资源保持不放。
- 循环等待条件:存在一种进程资源的循环等待链,链中每一个进程已获得的资源同时被 链中下一个进程所请求。
面试时的典型回答:
死锁是一种特定的程序状态,在实体之间,由于循环依赖导致彼此一直处于等待之中,没有任何个体可以继续前进。死锁不仅仅是在线程之间会发生,存在资源独占的进程之间同样也可能出现死锁。通常来说,我们大多是聚焦在多线程场景中的死锁,指两个或多个线程之间,由于互相持有对方需要的所,而永久处于阻塞的状态。
java怎么定位死锁:
1、首先使用jps -l(该命令和linux和ps -ef | grep 很像 java ps)查看当前运行的java程序,得出程序的进程号
2、再使用(jstack 进程号) 命令查看结果找到如下的内容:
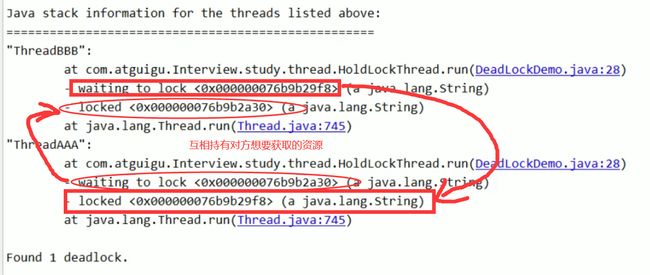
31、为什么java中IO的缓存区可以提高读写效率
https://blog.csdn.net/weixin_30706507/article/details/95891286
调用I\O操作的时候,实际上还是一个一个的读或者写,关键就在,CPU只有一个,不论是几个核心。CPU在系统调用时,会不会还要参与主要操作?参与多次就会花更多的时间。
系统调用时,若不用缓冲,CPU会酌情考虑使用 中断。此时CPU是主动地,每个周期中都要花去一部分去询问I\O设备是否读完数据,这段时间CPU不能做任何其他的事情(至少负责执行这段模块的核不能)。所以,调用一次读了一个字,通报一次,CPU腾出时间处理一次。而设置缓冲,CPU通常会使用 DMA 方式去执行 I\O 操作。CPU 将这个工作交给DMA控制器来做,自己腾出时间做其他的事,当DMA完成工作时,DMA会主动告诉CPU“操作完成”。
这时,CPU接管后续工作。在此,CPU 是被动的。DMA是专门 做 I\O 与 内存 数据交换的,不仅自身效率高,也节约了CPU时间,CPU在DMA开始和结束时做了一些设置罢了。
所以,调用一次,不必通报CPU,等缓冲区满了,DMA 会对C PU 说 “嘿,伙计!快过来看看,把他们都搬走吧”。综上,设置缓冲,就建立了数据块,使得DMA执行更方便,CPU也有空闲,而不是呆呆地候着I\O数据读来。从微观角度来说,设置缓冲效率要高很多。尽管,不能从这个程序上看出来。 几万字的读写\就能看到差距。
32、SQL查询常见练习
https://mp.weixin.qq.com/s?src=11×tamp=1603019683&ver=2652&signature=LcdPMgbbtjJmiOTEwxHgBDMZmQUaHcytasol0ZuYaUNr7HRRuiuTTrIfy2PqSi5HoIHaM-I7uBYEx3sEveXTVaXtuJqt9vO4v6eBrTDejO2hgmDgKQUH4QdJIDwi&new=1
33、Mysql中的回表和索引覆盖
InnoDB 索引:
https://blog.csdn.net/u013308490/article/details/83001060
回表索引覆盖:
https://www.cnblogs.com/yanggb/p/11252966.html
34、常见算法
https://www.cnblogs.com/flyingdreams/p/11161157.html
35、java中的类加载器
36、异常的分类,什么异常需要try catch
https://www.cnblogs.com/lulipro/articles/7504267.html
https://blog.csdn.net/yongbutingxide/article/details/82861746
检查时异常需要被try catch(SQL异常,IO异常)
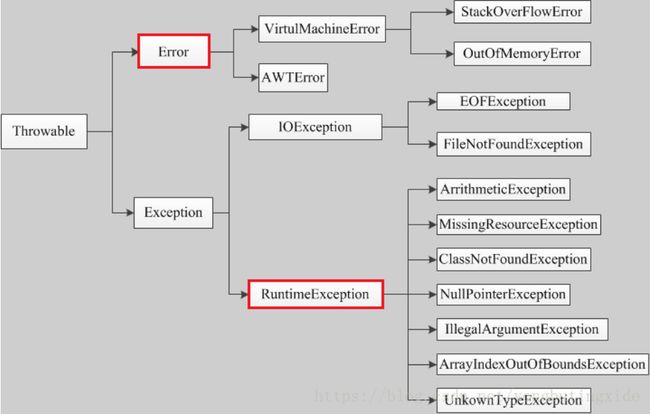
37、synchronized实现原理和lock的一些高级用法
①、synchronized的实现:是java关键字属于JVM层面的
monitorenter:底层是通过monitor对象来完成,其实wai t/notify等方法也依赖Fimoni tor对象只有在同步块或方法中才能漏wait/notify等方法。
monitorexit:退出

②、Lock是具体类( java. util. concurrent. locks. Lock )是api层面的锁,必须手动释放锁
2 使用方法
synchronized不需要用户去手动释放锁,当synchronized 代码执行完后系统会自动让线程释放对锁的占用
ReentrantLock则需要用户去手动释放锁若没有主动释放锁,就有可能导致出现死锁现象。
需要Lock()和unLock()方法配合try/finally语句块来完成。
3 等待是否可中断
synchronized不可中断,除非抛出异常或者正常运行完成
ReentrantLock可中断, 1.设置超时方法tryLock(long timeout, TimeUnit unit)
2. lockInterruptibly()放代码块中,调用interrupt() 方法可中断
4 加锁是否公平
synchronized非公平锁
ReentrantLock两者都可以,默认非公平锁,构造方法可以传入boolean值, true 为公平锁,false为 非公平锁
5 锁绑定多个条件Condition
synchronized没有
ReentrantLock用来实现分组唤醒需要唤醒的线程们,可以精确唤醒,而不是像synchronized.要么随机唤醒一个线程要 么唤醒全部线程。
synchronizedsynchronized对不同对象加锁的区别:
https://blog.csdn.net/oman001/article/details/105059069
lock锁的一些常用方法:https://blog.csdn.net/hccc1/article/details/94160293
java中各种锁:
公平和非公平锁
可重入锁(又名递归锁)
自旋锁——SpinLockDemo团
独占锁(写锁)/共享锁(读锁)/互斥锁——ReentrantReadWriteLock lock.
38、IO 模型的形象举例
https://blog.csdn.net/szxiaohe/article/details/81542605
BIO:创建线程池,如果有请求来处理就使用一个线程来处理请求,如果线程都被占用则放入等待队列中,这种IO模型属于伪异步IO模型
NIO:使用Selecter(多路复用器)和channal
39、树的遍历
https://www.pianshen.com/article/7106254596/
树的遍历也就是根据根节点的先后顺序来定义的