R语言入门笔记
文章目录
- 1 R的基本操作
-
- 1.1 R的使用
- 1.2 R的工作界面
- 1.3 R的依赖包
- 2 创建数据集
-
- 2.1 数据集的概念
- 2.2 数据结构
-
- 2.2.1向量
- 2.3 矩阵
-
- 2.3.1创建一个矩阵
- 2.3.2 矩阵索引
- 2.4 数组
- 2.5 数据框
- 2.6 列表
- 2.7 文件的导入
-
- 2.7.1 导入csv文件
- 2.7.2 导入xlsx文件
- 2.7.3 读取txt文本文件
- 2.7.4 导入 SPSS 数据
- 2.7.5 连接MySQL数据库数据
- 3 图形与可视化
-
- 3.1 折线图
-
- 3.1.1 图形的一些参数
- 3.1.2 修改线条与点的类型
- 3.1.3 图形的优化
- 3.1.4 添加标题与设置坐标轴
- 3.1.5 自定义坐标轴绘制多图
- 3.1.6 绘制折线对比图
- 3.1.7 文本标注
- 3.1.8 图形的组合
1 R的基本操作
1.1 R的使用
R是一种区分大小写的解释型语言,R的IDE有RStudio。R中有多种数据类型,包括向量、矩阵、数据框以及列表等。他是一个强大的统计分析软件,在统计学中有广泛的应用。R语句由函数和赋值构成。R使用<-,而不是传统的=作为赋值符号。当然传统的=号也可以进行赋值。
1.2 R的工作界面
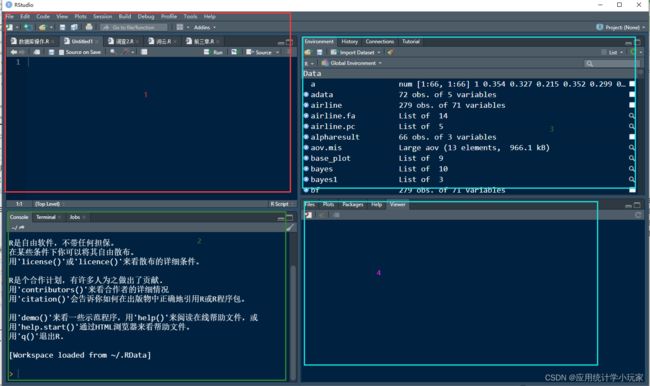
第一个区域表示编译区,也就是编写代码的地方,第二个区域是代码运行的地方,在第一区域编译后的代码会在第二区域显示并得出结果。第三个区域是运行过程中产生数据的框,数据都会保存在这个区域里,第四个区域是绘图区,我们绘制的图形、词云等都在这个区域显示。
1.3 R的依赖包
R提供了大量开箱即用的功能,选模块的下载和安装来实现的。我峨嵋你只需要选择自己i下那个要的依赖包,利用install.package()来下载就可以了。当我们想要调用包时,直接使用library()就可以调用了。
2 创建数据集
2.1 数据集的概念
数据集通常是由数据构成的一个矩形数组,行表示观测,列表示变量。R可以处理的数据类型(模式)包括数值型、字符型、逻辑型(TRUE/FALSE)、复数型(虚数)和原生型(字节)等。
2.2 数据结构
R拥有许多用于存储数据的对象类型,包括标量、向量、矩阵、数组、数据框和列表。
2.2.1向量
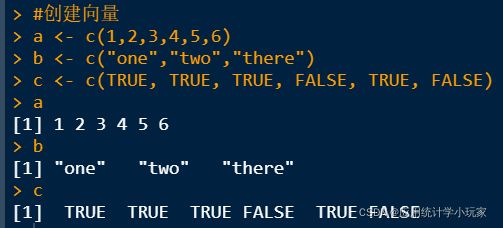
向量是用于存储数值型、字符型或逻辑型数据的一维数组。执行组合功能的函数c()可用来创建向量。
#创建向量
a <- c(1,2,3,4,5,6)
b <- c("one","two","there")
c <- c(TRUE, TRUE, TRUE, FALSE, TRUE, FALSE)
向量的切片
如何找到对应位置的元素我们可以利用[位置]来实现。
#查找a中位于第三个位置的向量
a[3]
#查找第1、3、5位置的元素
a[c(1,3,5)]
#查找2到5的元素
a[2:5]

从结果来看,我们都找到了该位置的元素。
2.3 矩阵
矩阵是一个二维数组,只是每个元素都拥有相同的模式(数值型、字符型或逻辑型)。可通过函数matrix()创建矩阵。
2.3.1创建一个矩阵
#创建一个矩阵
y <- matrix(1:20, nrow=5, ncol=4)
nrow表示行,ncol表示列,1:20表示元素时从1到20一共20个元素,默认取值顺序为向列方向取值。

创建一个有索引的矩阵
#元素为1,2,4,8
cells <- c(1,2,4,8)
#行名为R1,R2
rnames <- c("R1", "R2")
#列名为C1,C2
cnames <- c("C1", "C2")
#byrow=TRUE表示按行取值,没有则按列取值
xhw <- matrix(cells, nrow=2, ncol=2, byrow=TRUE,
dimnames=list(rnames, cnames))

因此我们得到一个2x2的矩阵。
2.3.2 矩阵索引
根据我们上面建立的矩阵y进行索引。
#提取矩阵的行
y[2,]
#提取矩阵的列
y[,2]
#提取第2行第2列
y[2,2]
#提取第一行,第2列到4列的元素
y[1,c(2:4)]
从这里我们可以知道,我们利用所创建的矩阵y来进行提取。

从结果来看,第2行的匀速为 6,7,8,9,10。第2行第2列的值为7。第一行,第2到4列的元素为6,11,16。
2.4 数组
数组(array)与矩阵类似,但是维度可以大于2。数组可通过array函数创建。创建一个数组。
#创建一个数组
dim1 <- c("A1", "A2")
dim2 <- c("B1", "B2", "B3")
dim3 <- c("C1", "C2", "C3", "C4")
array <- array(1:24, c(2, 3, 4),
dimnames=list(dim1, dim2, dim3))
2.5 数据框
由于不同的列可以包含不同模式(数值型、字符型等)的数据,数据框的概念较矩阵来说更为一般。它与你通常在SAS、SPSS等看到的数据集类似。数据框将是你在R中最常处理的数据结构。数据框可通过函数data.frame()创建。
2.6 列表
列表(list)是R的数据类型中最为复杂的一种。一般来说,列表就是一些对象(或成分,component的有序集合。某个列表中可能是若干向量、矩阵、数据框,甚至其他列表的组合。可以使用函数list()来创建列表。
2.7 文件的导入
2.7.1 导入csv文件
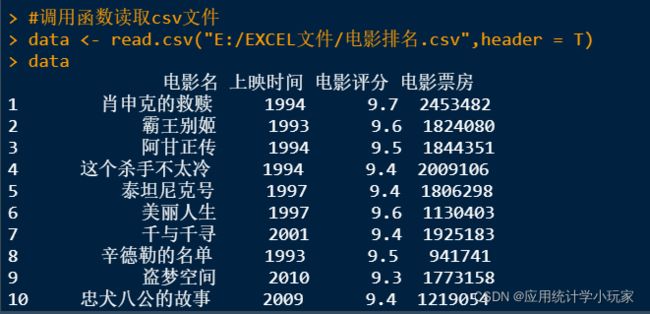
在读取csv文件时需要用到read.csv()函数来读取,里面包括路径,其中header=T表示有表头名,header=F表示没有表头名。现在读取一个存着电影排名的csv测试文件。
#调用函数读取csv文件
data <- read.csv("E:/EXCEL文件/电影排名.csv",header = T)
data
2.7.2 导入xlsx文件
导入xlsx文件需要安装一个readxl程序包,再调用该包进行读取文件。同样进行读取文件猜测试。xlsx与csv文件不同,xlsx不需要加header。
#安装包
install.packages("readxl")
#调用包
library("readxl")
#读取数据
data1 <- read_excel("E:/EXCEL文件/电影排名.xlsx")

2.7.3 读取txt文本文件
读取txt文件时,用到的是read.table()函数,其中中文开头时会乱码。
#读取文本文件
data2 <- read.table("E:/TXT文件/多元线性.txt",header = F)
data2

2.7.4 导入 SPSS 数据
读取spss文件时,需要安装一个依赖函数包:haven,再使用函数read.sav()来读取sav文件。现在我们进行一个sav文件的读入。
library("haven")
data <- read_sav("D:/桌面文件/问卷/源数据.sav")
data

2.7.5 连接MySQL数据库数据
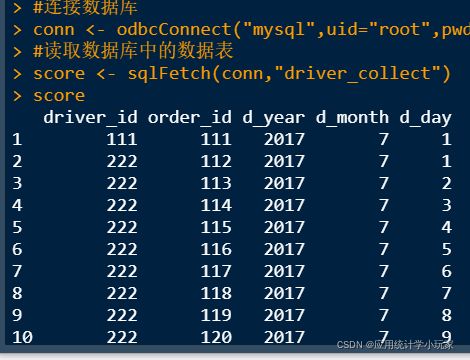
读取MySQL文件时需要安装一个mysql的数据源与驱动器,再调用一个RODBC依赖包进行读取。读取函数为odbcConnect()。uid表示用户名,pwd表示密码。
#加载包
library("RODBC")
#连接数据库
conn <- odbcConnect("mysql",uid="root",pwd = " ")
#读取数据库中的数据表
score <- sqlFetch(conn,"driver_collect")
score
3 图形与可视化
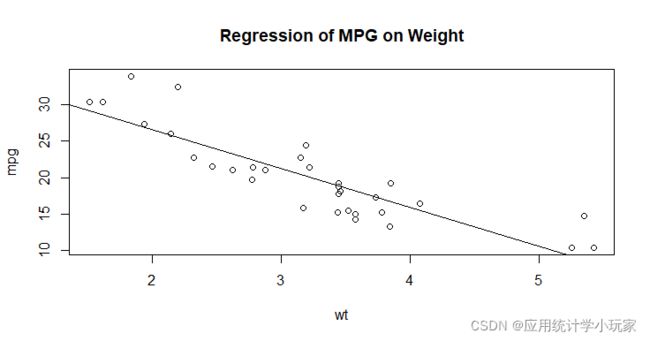
这里使用R的内置数据集mtcars中的wt与mpg两个数据。attach()用来连接数据集,detach()用来删除连接的数据集。
#连接R的内置数据mtcars
attach(mtcars)
#绘制散点图
plot(wt, mpg)
#添加趋势线
abline(lm(mpg~wt))
#添加标题
title("Regression of MPG on Weight")
#删除连接的数据
detach(mtcars)
3.1 折线图
折线图以来还是用plot()函数来绘制。
#输入自变量与因变量的值
x <- c(20, 30, 40, 45, 60)
y <- c(16, 20, 27, 40, 60)
#type为折线图的类型
plot(x,y,type="o")
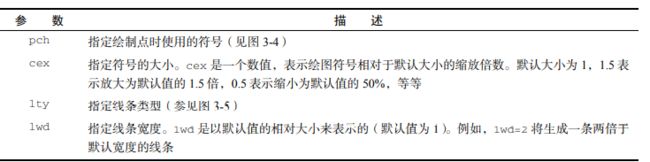
修改图形的参数可以绘制不同类型的折线图,其中lty为线的类型,pch为点的形状。
3.1.1 图形的一些参数

3.1.2 修改线条与点的类型
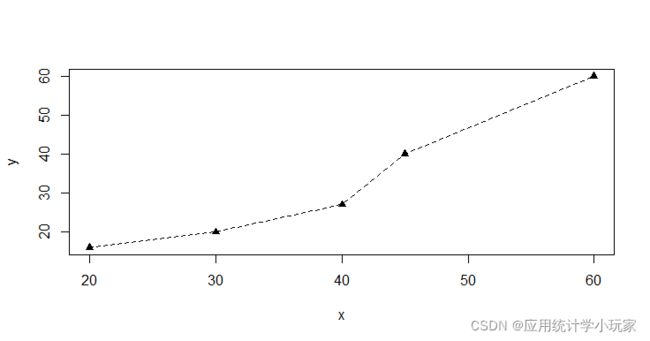
x <- c(20, 30, 40, 45, 60)
y <- c(16, 20, 27, 40, 60)
#设置虚线连接,点为三角形形状的折线图
par(lty=2, pch=17)
plot(x,y,type="o")
plot(dose, drugA, type="b", lty=3, lwd=3, pch=15, cex=2)

3.1.3 图形的优化
对图形进行美化。分别对图形的窗口,尺寸,以及连线类型,坐标轴,图形颜色等进行了美化。pin 以英寸表示的图形尺寸(宽和高),
#自变量与因变量
x <- c(20, 30, 40, 45, 60)
y1 <- c(16, 20, 27, 40, 60)
y2 <- c(15, 18, 25, 31, 40)
#设置图形窗口
par(mfrow=c(1,2))
#设置图形尺寸
par(pin=c(2, 3))
#设置连线类型与线放大的倍数
par(lwd=2, cex=1.5)
#设置坐标轴文字倍数,坐标轴文字字体样式
par(cex.axis=.75, font.axis=3)
#设置颜色绘制图形
plot(x, y1, type="b", pch=19, lty=2, col="red")
plot(x, y2, type="b", pch=23, lty=6, col="blue", bg="green")

3.1.4 添加标题与设置坐标轴
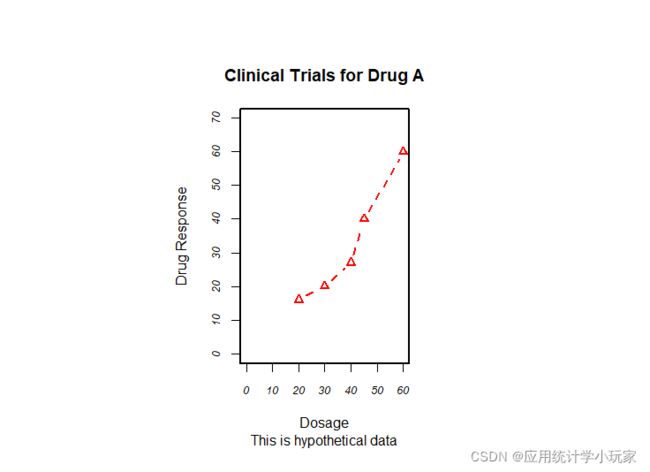
除了图形参数,许多高级绘图函数(例如plot、hist、boxplot)也允许自行设定坐标轴和文本标注选项。举例来说,以下代码在图形上添加了标题(main)、副标题(sub)、坐标轴标签(xlab、ylab)并指定了坐标轴范围(xlim、ylim)。
#添加标题与设置坐标轴
plot(x, y1, type="b",
col="red", lty=2, pch=2, lwd=2,
main="Clinical Trials for Drug A",
sub="This is hypothetical data",
xlab="Dosage", ylab="Drug Response",
xlim=c(0, 60), ylim=c(0, 70))
3.1.5 自定义坐标轴绘制多图
创建自定义坐标轴时,你应当禁用高级绘图函数自动生成的坐标轴。
#给定自变量因变量,建立函数关系
x <- c(1:10)
y <- x
z <- 10/x
#增加边界
par(mar=c(5, 4, 4, 8) + 0.1)
plot(x, y, type="b",pch=21, col="red",
yaxt="n", lty=3, ann=FALSE)
#添加x对y的趋势线
lines(x, z, type="b", pch=22, col="blue", lty=2)
#自定义坐标轴
axis(2, at=x, labels=x, col.axis="red", las=2)
axis(4, at=z, labels=round(z, digits=2),
col.axis="blue", las=2, cex.axis=0.7, tck=-.01)
#添加标题
mtext("y=1/x", side=4, line=3, cex.lab=1, las=2, col="blue")
title("An Example of Creative Axes",
xlab="X values", ylab="Y=X")

3.1.6 绘制折线对比图
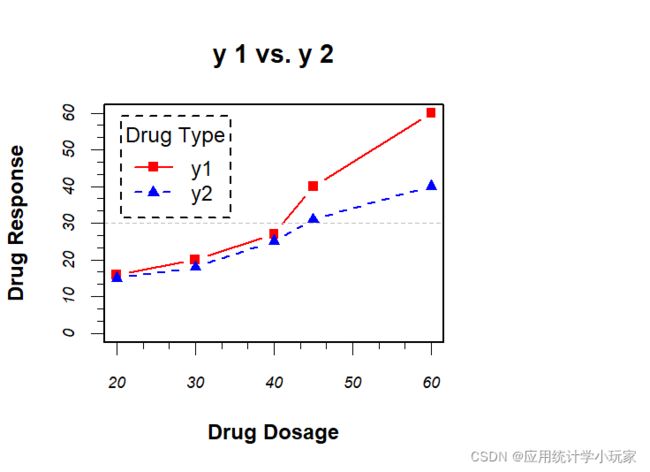
一次绘制x对y1与y2的影响情况。
#自变量与因变量
x <- c(20, 30, 40, 45, 60)
y1 <- c(16, 20, 27, 40, 60)
y2 <- c(15, 18, 25, 31, 40)
#增加线条,文本,符号等的大小
par(lwd=2, cex=1.5, font.lab=2)
#绘制图形
plot(x, y1, type="b",
pch=15, lty=1, col="red", ylim=c(0, 60),
main="y 1 vs. y 2",
xlab="Drug Dosage", ylab="Drug Response")
#添加趋势线
lines(x, y2, type="b",
pch=17, lty=2, col="blue")
#添加参考线
abline(h=c(30), lwd=1.5, lty=2, col="gray")
library("Hmisc")
minor.tick(nx=3, ny=3, tick.ratio=0.5)
#添加图列解释
legend("topleft", inset=.05, title="Drug Type", c("y1","y2"),
lty=c(1, 2), pch=c(15, 17), col=c("red", "blue"))
3.1.7 文本标注
我们可以通过函数text()和mtext()将文本添加到图形上。text()可向绘图区域内部添加文本,而mtext()则向图形的四个边界之一添加文本。使用格式分别为:text(location, “text to place”, pos, …) ,mtext(“text to place”, side, line=n, …)。依然使用mtcars数据集。
#文本标注
attach(mtcars)
plot(wt, mpg,
main="Mileage vs. Car Weight",
xlab="Weight", ylab="Mileage",
pch=18, col="blue")
text(wt, mpg, row.names(mtcars),
cex=0.6, pos=4, col="red")
detach(mtcars)

数学标注与数学运算符号

3.1.8 图形的组合
在R中使用函数par()或layout()可以容易地组合多幅图形为一幅总括图形。现在创建了四幅图形并将其排布在两行两列中。依然使用R1的内置数据集mtcars。
attach(mtcars)
par(mfrow=c(2,2))
plot(wt,mpg, main="Scatterplot of wt vs. mpg")
plot(wt,disp, main="Scatterplot of wt vs. disp")
#绘制条形图
hist(wt, main="Histogram of wt")
#绘制箱线图
boxplot(wt, main="Boxplot of wt")
detach(mtcars)

再绘制一个3x1的总图
attach(mtcars)
#设置图窗
par(mfrow=c(3,1))
#直方图
hist(wt)
hist(mpg)
hist(disp)
detach(mtcars)

R语言自学笔记。仅作为笔记。参考资料:R语言实战第二版。