自学转行学AI人工智能怎么样?
1.我的情况
我本科学工程造价的,后来觉得不想去做工程方面的工作加上兴趣爱好的原因大二开始自学网安,但是那段日子有多枯燥无聊只有我自己知道,加上自己的学习方法不对,东学一点、西看一点,零散的知识难以形成框架体系。
尽管花了很多时间,朋友们打游戏的时候我听课装环境,大家上课的时候我躲在后排看《白帽子讲Web安全》,但是结果并没有得到多少正反馈。
最后还是选择了报培训班,那两个月的培训把我自身所学过的知识梳理成一个完整的体系,还让我结实了很多搞网安的朋友。
我们做自己的公众号,几个月就5000+粉,组建小队在漏洞响应平台挖洞,交过些漏洞报告,我自己也对后续的学习有了自己的打算。
今年考完研,导师说让趁着暑假学一学MatLab,Python。
但是Python我本来就学过了,查了查资料,觉得人工智能这么火热加上导师的方向比较偏向工业智能制造,也就开始了自学人工智能知识的路。
2.学习前景怎么样?
我想你自己心里也有一个答案,不然为什么没有想去转行学其他的,我会从时代背景、政策、薪资三个方面聊聊我的看法。
时代背景
李开复《人工智能》一书中讲到了关于AI的历史,从1950年到2017年,人工智能领域的发展大致分为三个阶段:
理论初现——非智能机器人
这个时候的所谓的“智能”只是利用前后端数据库交互的技巧让计算机看起来智能,大量的文本信息存储在对话库中,当他人说出某个关键词时,机器便回复其特定的话语。
统计学思想替代符号主义
符号主义在工业时代因为标准化流程的需要大放异彩,但是这个时候的机器人只会在人类控制的程序下进行A到B的机械操作。
概率二字在统计学思想中频繁出现,机器在统计学思想的影响下出现了学习的初兆。它可以根据先前输入的数据集去判断验证后序的数据是否符合某些标准:图片里是苹果还是香蕉、如何定义邮箱中那些是垃圾邮件等等。
大数据下的深度学习网络
随着机器硬件和互联网行业的发展,数据的量级不断扩大,存储成本相比过去却下降了,这使得大型的互联网公司具有了深度学习的原始资本。
21世纪是数据的时代,各种外部环境成熟以后,消费级人工智能的产品和应用才开始如雨后春笋般破土而出。
像机器视觉领域:商场的人脸识别、智能交通中车牌识别,像语音交互领域:智能音箱、语音助手等等。
而我们正处在第三次浪潮初起之后不久,与之前两次浪潮不同的是,还有待被开发的海量数据背后蕴藏的价值被商业投资人看重,AI行业的融资情况突飞猛进。

时代背景不容改变,值得我们思考的问题更多的是如何适应时代发展。
我上贪心科技机器学习课程的时候,李文哲老师也说过随着AI的普及速率加快,对于各行业的职场人士来说,如何将自己本来的工作结合AI提高效率是不得不去思考的一个问题,AI的价值在于优化重复性的工作。
就好像对1000张图片分类,交给几个人或是已经建立良好模型的机器所花费的成本和时间不言而喻。

政策和薪资等
政策
前面有师傅聊到过这两个方面,我就再简单的说一下。
我在人民网(网络版的人民日报)上随便搜了一下人工智能四个字,有近10w+的文章。

7月13号,2021世界人工智能大会在上海拉开帷幕,提出了两个概念:行业发展服务与人、技术赋能千行百业。
无可厚非,我国一直不断在推进该产业的发展,产学研深度融合,某些领域建立的完整产业链也在不断创造新的市场和发展机会。
10年前我们可能没有想过如今人工智能在各行各业都有如此深的胶着度,客服、医疗、金融,真的是千行百业。
下一步的政策发展怎么样,我想不用再多说什么,引用上海市委书记李强的一段话:“未来,上海将持续聚焦经济、生活、治理三大数字化转型,围绕制造、商贸、医疗、教育、交通、政务、文体等细分行业,打造一批人工智能示范应用场景,增加智能产品供给。”

薪资
不说废话,我们来看看猎聘2019年发布的有关AI领域人才就业报告中的薪资数据。


从上面可以看到,薪资待遇普遍在20k以上,平均月薪达到13k。
毕竟火爆热度的背后一定是需求在作祟。
3.怎么学?
时代背景也好、发展政策也好、薪资待遇也好,这些都是我们影响我们决策的因素,就好像机器学习中的特征变量,对每一个结果都有其影响。
人工智能是一定要学的,但是能学到什么样子就要看你渴望转行的念头有多么强烈了。
我也是在刚刚入门的阶段,就跟你聊聊我现在的学习过程。
因为过去学网安的经历,我一开始还是去找了网课,找了培训机构,因为我知道只是凌乱的学习,难以将知识结构系统化。
我现在在上吴恩达的机器学习课程和贪心科技的机器学习中级课,都是线上网课的形式,我的学习方法就是吴恩达的课做基础,贪心科技的课程做深入。
这两个课我在同时听,进度差不多。吴恩达的课一共是十一周,贪心科技的课程是十八章。
课程框架
课程内容,可以看一下我听课前做的知识框架。


吴恩达的课,可以去随便搜一下,他的课程在机器学习领域算是入门必推。
贪心科技的课程是因为我在 Youtube
上听过李文哲老师讲课,翻过他几篇论文,觉得讲课的方式我还挺喜欢。
从上面的课程框架图可以看出来,Ng的课程,实践的地方比较少,贪心科技的课程除了案例作业以外,每章知识讲解以后还会有一个小案例来回顾已经讲过的知识点。
这里我举一个课程作业的例子给大家分享一下,贪心科技的课程在第二章线性回归结束以后会有一个关于股价预测模型的作业,这个作业需要我们听完逐步分解的任务目标后再去实现。
关于这个问题,李文哲老师分了几个步骤去讲解模型建立的过程:
l 理解数据的意义
l 对数据集进行清洗
l 对数据进行归一化
l 构建模型、参数评估
l 简单可视化
l 分析特征的重要性
详细的步骤划分归入到每一小节进行讲解,其中不仅会阐述解决问题的思路,还会告诉我们如何利用代码去实现。


到了项目练习的部分就是检验自身所学的时候了,我们需要做的事情、需要完成的代码会在项目作业预留的位置标注出来。
比如这个项目作业需要我们完成,数据的排序、去NAN值、提取特征值和预测数据、把数据分为训练数据和测试数据、利用训练数据训练模型等等。

因为在前面小节中已经有过较详细的介绍,所以整体的代码实现并不是很难。
这个作业当时我先在自己的服务器上跑了一下。
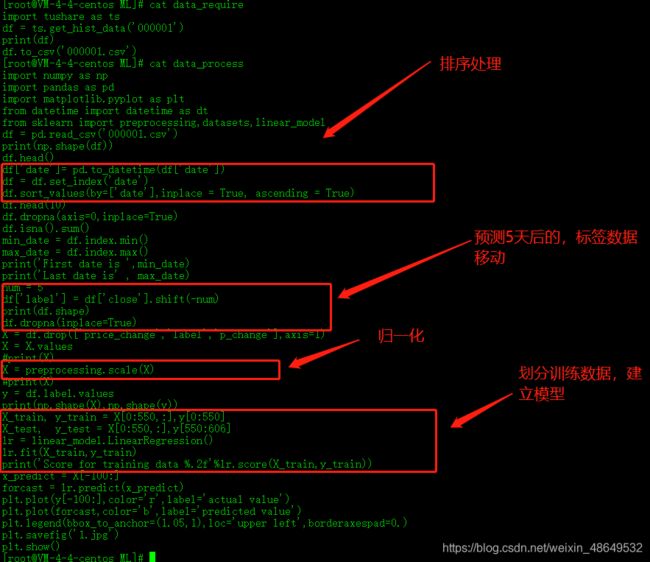
最后按照每步的需求,在官网提交了作业代码,期间也遇到了些问题,但是我又翻着前面的课程看了几遍,不会的地方还是因为自己听课不认真导致的。
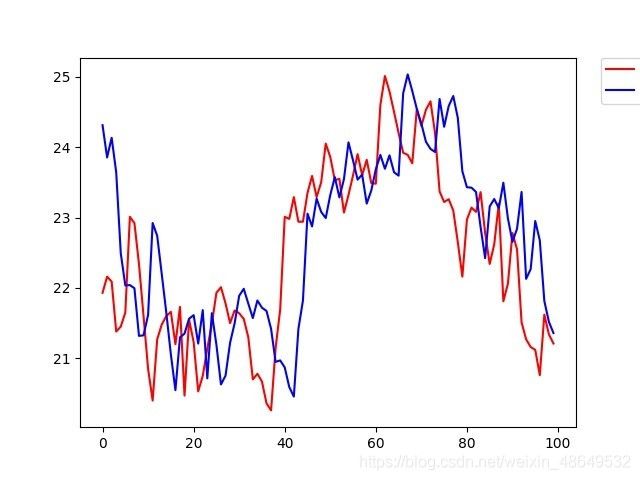
其实只要认真的听课然后去梳理李文哲老师讲授的知识,写出来是没有问题的,最后看着输出的可视化图会很有成就感。
教学语言
吴恩达的课褒贬不一,但是赞誉偏多,我听了两周,觉得是如大众所言偏基础,现在也庆幸多听了贪心科技的机器学习课程,Ng的课里面涉及到线性回归、矩阵的知识很浅,也可能是因为我刚经过了考研数一的洗礼?
吴恩达的课全英,视频中的题目和课后的测验都是英文,讲课虽然有中文字幕,但是有很多章节音频对不上,我一度听得很费解,
只能倒回去多听几遍,浪费了很多时间,我的六级已经过了,但是很多专业术语还是听不太懂,这也是效率低的一个原因。
贪心科技的课程是李文哲老师的授课视频,友好中文,专业的术语或者某些介绍还是会用英文来描述,但是会给出中文翻译,我听的很舒服。

李文哲老师是南加州大学的博士,研究的领域是自然语言处理、知识图谱、机器学习,也做过美国亚马逊、高盛的资深工程师,他讲课的时候总是说些自己对人工智能领域的看法,被动接受的过程就变得好像两个人在闲聊一样,只是文哲老师的知识渊博,我以倾听为主。
课程定位
其实对比起来说的话两个课程的定位是不同的,吴恩达的课程更多的在帮助希望了解机器学习领域的人构建一个全新领域的概念框架,而贪心科技的课程毕竟是以就业为目的,对于某些概念的推导,贪心科技的课程显得更细致深入。
就好像下面线性回归目标函数的推导,李文哲老师是从最初开始一步一步的带着去进行化简整理的,贪心科技的课程不仅需要你听的明白,还需要你能够知道为什么。


编程环境
此外就是关于需要实操编程方面的不同。同样是线上课程,贪心科技机器学习课程的官网上可以直接进行代码编写和运行,吴恩达的课推荐使用的是
Octave,第二周他花了近一个小时在介绍 Octave 中如何操作数据集,说实话我听得有点乏味。


自学本来就是一个枯燥的过程,每天的精力有限,如果花费很多的时间安装配置开发环境会大大降低自身的的学习兴趣。
不过我建议你可以像我一样,将这两个课程放在一起学习,先听一周吴恩达的课程,完成上面的教学任务。
然后去听贪心科技的作为更深层次的学习,贪心科技每章节后面都有实操案例,像线性回归之后的股价预测、逻辑回归之后的银行客户分析等等,这样做的话,知识就不会只停在我学了这一层上。
吴恩达的课程内容较少,在时间上一定会比贪心科技的课程先结束,这样在你已经有了一个整体框架的基础上再加上贪心科技课程中的不断代码实战和最后的聊天机器人项目作业,我想入门就够了。
而后你可以选择继续去听贪心科技其他高级班课程,也可以选择结合自己的兴趣做某方面更深度的学习研究。

4.总结
用李文哲老师的话做一个总结吧。
“每个人都是有目标的,有了目标你才有一个行动的动力,你不断的沿着这个目标去前进,最后才能变得与过去的自己不同。”
有时候你问怎么样的时候,其实心里已经有了答案,去做就好了!