1、DataStream算子转换概览
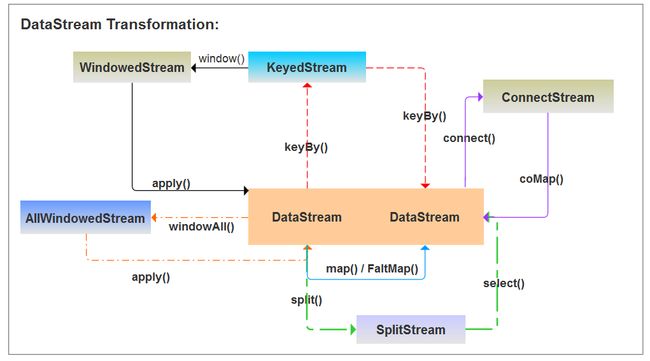
DataStreamFormations
2、DataStream转换算子
(1)Map [DataStream->DataStream]
说明:
- 一对一转换,即一条转换成另一条
- 调 用 用 户 定 义 的 MapFunction 对 DataStream[T] 数 据 进 行 处 理 , 形 成 新 的 Data-Stream[T],其中数据格式可能会发生变化,常用作对数据集内数据的清洗和转换。
样例:
DataStream stream = env.addSource(new SimpleStringGenerator()).setParallelism(1);
stream.map(new MapFunction() {
@Override
public String map(String s) throws Exception {
Thread.sleep(1000);
String tempStr="tmp_"+s; // 单条数据计算
return tempStr;
}
}).print();
(2)FlatMap [DataStream->DataStream]
说明:
- 一行变零到多行
- 该算子主要应用处理输入一个元素产生一个或者多个元素的计算场景,比较常见的是在 经典例子 WordCount 中,将每一行的文本数据切割,生成单词序列如在图所示,对于输入 DataStream[String]通过 FlatMap 函数进行处理,字符串数字按逗号切割,然后形成新的整 数数据集
样例:
DataStream textTemp=stream.flatMap(new FlatMapFunction() {
@Override
public void flatMap(String s, Collector collector) throws Exception {
// 样例数据:"1;50001;0;202001;\"53180093<40100017:53180093:40006212;"
List tempList=Arrays.asList(s.split(";"));
for(String str:tempList){
collector.collect(str);
}
}
})
(3)Filter [DataStream->DataStream]
说明:
- 该算子将按照条件对输入数据集进行筛选操作,将符合条件的数据集输出,将不符合条 件的数据过滤掉。
样例:
DataStream filterStream=stream.filter(new FilterFunction() {
@Override
public boolean filter(String s) throws Exception {
return s.isEmpty();
}
});
(4)KeyBy [DataStream->KeyedStream]
说明:
- 该算子根据指定的 Key 将输入的 DataStream[T]数据格式转换为 KeyedStream[T],也就 是在数据集中执行 Partition 操作,将相同的 Key 值的数据放置在相同的分区中
- 分区结果和KeyBy下游算子的并行度强相关。如下游算子只有一个并行度,不管怎么分,都会分到一起。
样例:
DataStreamSource source = env.fromCollection(Arrays.asList(
new UserInfo("张三", "21", "click"),
new UserInfo("李四", "23", "browse"),
new UserInfo("张三", "31", "click")
));
KeyedStream result = source.keyBy(new KeySelector() {
@Override
public String getKey(UserInfo user) throws Exception {
return user.getName();
}
});
(5)Reduce [KeyedStream->DataStream]
说明:
- 该算子和 MapReduce 中 Reduce 原理基本一致,主要目的是将输入的 KeyedStream 通过 传 入 的 用 户 自 定 义 的 ReduceFunction 滚 动 地 进 行 数 据 聚 合 处 理 , 其 中 定 义 的 ReduceFunciton 必须满足运算结合律和交换律。
样例:
KeyedStream result = source.keyBy(new KeySelector() {
@Override
public String getKey(UserInfo user) throws Exception {
return user.getName();
}
});
DataStream text=result.reduce(new ReduceFunction() {
@Override
public UserInfo reduce(UserInfo userInfo, UserInfo t1) throws Exception {
return userInfo;
}
});
(6)Aggregations[KeyedStream->DataStream]
Aggregations 是 KeyedDataStream 接口提供的聚合算子,根据指定的字段进行聚合操 作,滚动地产生一系列数据聚合结果。其实是将 Reduce 算子中的函数进行了封装,封装的 聚合操作有 等,这样就不需要用户自己定义 Reduce 函数。
(7)Union[DataStream ->DataStream]
说明:
- Union 算子主要是将两个或者多个输入的数据集合并成一个数据集,需要保证两个数据 集的格式一致,输出的数据集的格式和输入的数据集格式保持一致。
** 样例:**
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource source = env.fromCollection(Arrays.asList(
new UserInfo("张三", "21", "click"),
new UserInfo("李四", "23", "browse"),
new UserInfo("张三", "31", "click")
));
DataStreamSource sourceTwo = env.fromCollection(Arrays.asList(
new UserInfo("Ton", "21", "click"),
new UserInfo("java", "23", "browse"),
new UserInfo("flink", "31", "click")
));
DataStream unionStream=source.union(sourceTwo);
unionStream.print();
(8)Connect,CoMap,CoFlatMap[DataStream ->ConnectedStream->DataStream]
说明:
- Connect 算子主要是为了合并两种或者多种不同数据类型的数据集,合并后会保留原来 数据集的数据类型。
样例:
DataStreamSource source = env.fromCollection(Arrays.asList(
new UserInfo("张三", "21", "click"),
new UserInfo("李四", "23", "browse"),
new UserInfo("张三", "31", "click")
));
DataStreamSource sourceTwo = env.fromCollection(Arrays.asList("1,2,3,4,5,6".split(",")));
// connect 算子进行两个流的拼接合并
ConnectedStreams connectStream=source.connect(sourceTwo);
DataStream text=connectStream.map(new CoMapFunction() {
@Override
public String map1(UserInfo userInfo) throws Exception {
return userInfo.toString();
}
@Override
public String map2(String s) throws Exception {
return s;
}
});
text.print();
输出结果:
10> 2
2> 6
11> 3
1> 5
12> 4
9> 1
12> UserInfo{name='张三', age='31', desc='click'}
11> UserInfo{name='李四', age='23', desc='browse'}
10> UserInfo{name='张三', age='21', desc='click'}
流转换流程:

connectedStream转换流程
(9)Split 和 select [DataStream->SplitStream->DataStream]
说明:
- Split 算子是将一个 DataStream 数据集按照条件进行拆分,形成两个数据集的过程, 也是 union 算子的逆向实现。每个接入的数据都会被路由到一个或者多个输出数据集中。
- select 算子是选择指定标识的流。
样例:
DataStreamSource source = env.fromCollection(Arrays.asList(
new UserInfo("张三", "21", "click"),
new UserInfo("李四", "23", "browse"),
new UserInfo("张三", "31", "click")
));
SplitStream splitStream = source.split(new OutputSelector() {
@Override
public Iterable select(UserInfo userInfo) {
List list = new ArrayList<>();
if (userInfo.getName().equals("张三")) {
list.add("success");
} else {
list.add("error");
}
return list;
}
});
DataStream successStream = splitStream.select("success");
successStream.print("success-");
DataStream errorStream = splitStream.select("error");
errorStream.print("error-");
输出结果:
success-:3> UserInfo{name='张三', age='31', desc='click'}
success-:2> UserInfo{name='张三', age='21', desc='click'}
error-:9> UserInfo{name='李四', age='23', desc='browse'}
流转换流程:
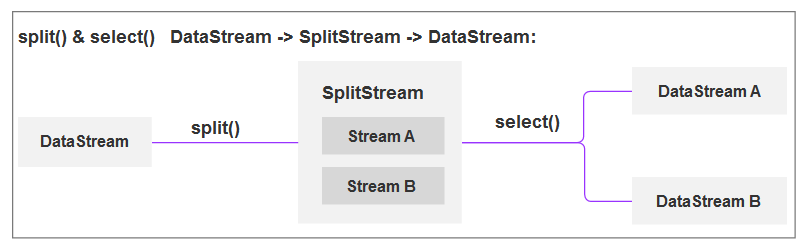
split()&select()