C++学习笔记(矿大计算机学院C++学习笔记)(入门级)
前言:本文绝大多数源自课本内容,但本人会在重要和晦涩的地方加入批注帮助初学者理解。花费精力制作这篇文章的目的在于让初学者能在我比较稚嫩的语言下更好地入门,也可在考试前查漏补缺。有错误的地方欢迎指出。
C++高级语言概述
C++是在C语言基础上开发的一种集面向对象编程、泛型编程和过程化编程于一体的编程语言,是C语言的超集。 对于初学者来说,对C++有个初步概念即可。传统的C语言是过程化编程语言,对于生活中的问题有着较强的解决方法,而C++是在C语言的基础上扩充了面向对象机制而形成的面向对象程序设计语言,它除了继承C语言的全部优点和功能外,还支持面向对象的程序设计。与其他程序设计语言相比较,C++语言简洁、紧凑、功能丰富,表达能力强,使用灵活方便,运行效率高,可移植性好。同时C++程序设计采用面向对象的程序设计思想,把握了程序设计的发展潮流和方向,有利于方便、灵活、高效地解决实际问题。
基本数据类型与运算符
C++数据类型
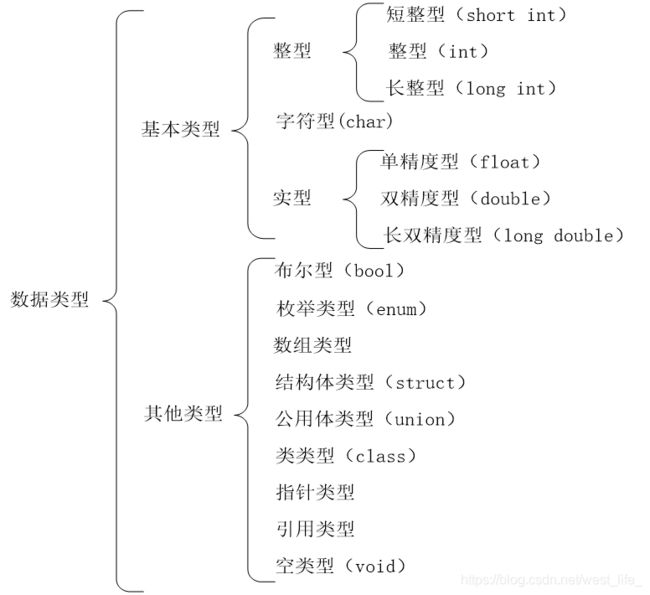
数据类型的字节数和数值范围
常量
一旦被声明(声明的同时被赋值)就不能再改变,也就是说不允许在程序中通过赋值等方式改变它的数值。
1. 数值型常量
#整型常量:整数就是没有小数部分的数字。一般来说,整型常量的类型默认是int,当字面数值超出int型的表示范围时,就用long类型表示,即开始定义变量时直接使用long类型对变量进行定义。但另外一种办法是可以在整型变量的末尾添加后缀符号,强制将字面数值整数常量的类型转换为unsigned long int或long或unsigned long类型。在数值后面加L(或者小写l,写的时候区别于数字1)可指定常量为long类型,在数值后面加U(或u)可指定常量为unsigned类型,在数值后面同时加L和U可指定常量为unsigned long类型,例如:
128U //unsigned
1024UL //unsigned long
1L //long
8LU //unsigned long
//注意数值与后缀符号之间不能有空格
#实型常量:就是浮点数(即小数) C++编译系统把浮点数按双精度(double)型处理,内存占8B。若在实数的数字之后加字母F或f,表示此数为单精度浮点数,内存占4B。
实型常量的指数形式一般为:<数符>数字部分E指数部分
(E或e表示其后的数是以10为底的幂),例如:
3.1415926E0 //表示3.1415926
0.31415926E1 //表示3.14115926
2. 字符常量
普通字符:用一对单引号括起来的单个字符就是字符常量。如‘a',’A‘,’@‘,’9‘都是合法的字符常量。字符常量在内存中占1B。(普通的字符常量只包含一个字符,故’10‘并不代表任何字符,是不合法的。同时大小写’a‘和’A‘表示不同的字符)
转义字符:
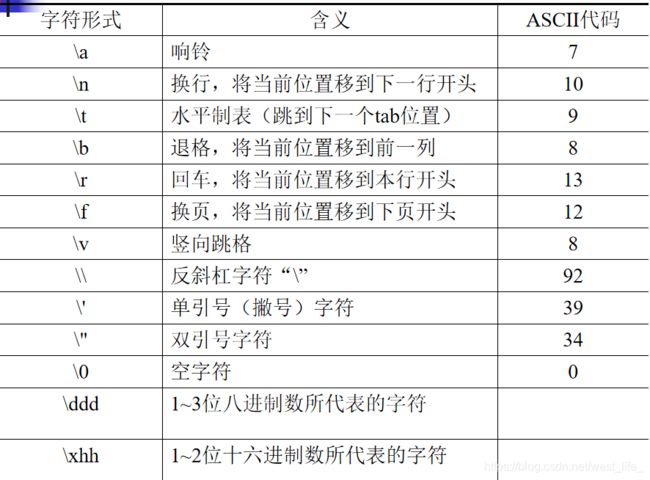
转义字符只表示一个字符,在内存当中之占1B
字符串常量:用一对双引号括起来的若干个字符序列,其中可以包含用转义字符表示的字符,也可以不包含任何字符,即空字符串常量。也就是说字符串常量就是多个字符构成的常量,上述所说的’10‘是不合法的,但如果使用双引号,“10”表示字符串10,是合法的。在后续学习中,可使用字符串常量来向屏幕中输出文字(多字符)如:
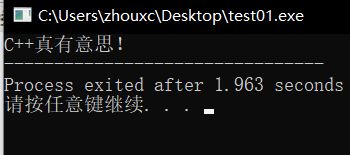
cout<<“C++真有意思!”;
屏幕输出如下:
PS:另外需要强调的一点是,系统会自动在字符串的结尾处添加一个空字符'\0',用于标识一个字符串的终结。因此字符串实际所占据的内存单元要比字符串的长度多1B。(后续对此知识点的了解会更加深入,此处只需了解字符串在系统中实际占据的内存会多一个空字符),例如:
字符常量'0':占1B空间;
字符串常量"0":占2B空间;
整型常量0:占4B空间 (长整型占8B)
变量
与常量相对,在程序运行期间其值可以改变的量称为变量。变量具有变量类型、变量名、变量值和变量地址等多种属性。
变量的定义(一般形式)
[存储类型] 数据类型 变量名1[=初值1] [,变量名2=[初值2],......]
格式中用“[ ]”括起来的部分表示可选项,省略号“···”表示可重复多次。如下:
int a; //定义整型变量a,没有进行初始化
float b=3.0; //定义单精度浮点型变量b并对其进行初始化
static int c=12,d=30,e; //定义静态整型变量c、d、e,并对c和d进行初始化
其中存储类型即为auto、register、static、extern(后续会有对此的详细讲解)规定了变量在程序中的存储方式,若不标明存储类型,则编译器默认变量为auto型。即下列两种形式等价
int a;
auto int a;
标识符的命名规则
变量名是一种标识符,后续内容中涉及的函数名、数据名和类名等都是标识符。(学习标识符的命名规则掌握变量名、函数名等标识符的命名规则)
在C++中,标识符可以由字母、数字和下划线(_)三种字符组成,必须以字母和下划线开头,后面接若干个字母、下划线和数字,字母区分大小写,除此之外不能包含其他类型的字符,否则该变量名非法。 (斜体字每句话在此处都是重点理解内容,后续很多地方需要自己编写变量名,掌握这些是为了让自己写的变量名合法)
有关变量名的说明:
- C++一般用小写字母来表示变量名。(习惯上的写法也是程序员的普遍认同的写法,为的是区别函数名等其他标识符)由于区分大小写字母,因此sum和Sum是两个不同的变量名。
- C++本身没有限制变量名的长度,但考虑到阅读和修改代码的方便性,变量名不宜太长。
- 变量名不能与C++的关键字相同。(C++的关键字全集可自行百度)
C++PrimerPlus补充:
int int; //非法操作,变量名不可以用关键字int
int poodle; //合法操作
int Poodle; //合法操作,区别于poodle,是一个新变量
Int terriers; //非法,必须是int
int double; //非法,变量名不能用关键字命名
int 4ever; //非法,不能以数字开头定义变量
int honey-tonk;//非法,使用了非法字符“-”,只能使用下划线“_"
赋值和算术运算符
赋值运算符和赋值运算表达式
赋值运算符“=”的作用是将右边操作数的值(右值)赋给左边操作数(左值) 其结果是将一个新的数值存放在左操作数所占用的内存空间中,因此,左值只能是变量,不能是常量或者函数。
可以看出,赋值运算符的运算次序是从右到左进行的
a=3; //将数值3赋给变量a
b=a; //将变量a所处内存空间的数值赋给变量b,此时b的值也为3
int var1,var2,var3; //定义三个整型变量
var1=(var2=var3=10)+20; //结果是var1的值为30,var2和var3的值为10;
想了一下还是在插入说明一下吧
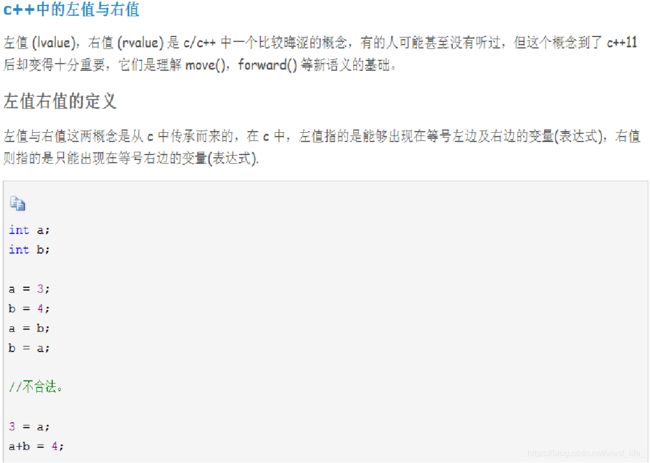
算术运算符
用于操作变量或表达式的算术运算。类似于数学中的先乘除后加减,C++也对其操作符进行了优先级分组。一元操作符优先级最高,其次是乘除操作,接着是二元的加减法操作符。这些算术操作符都是左结合,意味着当操作符的优先级相当时,这些操作符从左向右依次与操作数结合。
(所谓一元二元即该算术运算符发挥作用所需的操作数个数,如正值和负值运算符,只需要在后面添加一个操作数就可以表示正负,而加减法需要两个数才能相加或者相减,因此+和-为双目运算符。另外,C++中存在唯一一个三目运算符:“? :” 用法后续介绍)
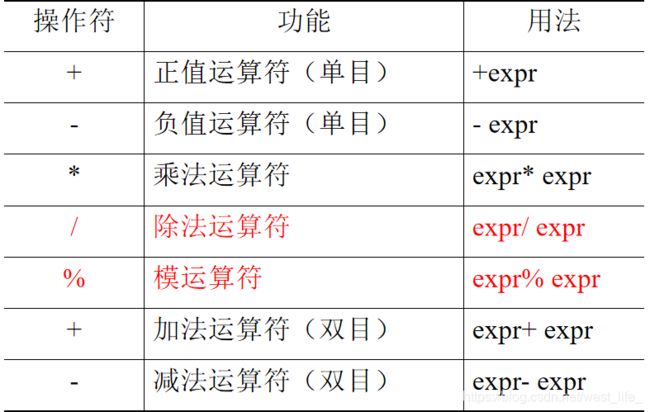
这里需要着重强调除法运算符和模运算符(需要理解且后续使用次数较多的运算符!!)
除法运算符:两个整数相除的结果仍然是整数,若被除数不能被除数整除,则相除的结果将被取整,小数部分将被略去。如28/4的结果为7,32/5的结果为6。如果除数或被除数之一为实数(含有小数部分),则结果也为实数,即32/5.0的结果为6.4。
模运算符:也称为求余运算,要求操作数都为整型数,结果也为整型数,值为两数相除的余数。如35%7结果为0,13%3结果为1(因为3x4=12,余数为1)
自增与自减运算符(单目运算符)
自增(++)和自减(–)操作符为变量加1或者减1操作提供了方便简洁的实现方式。
它们有前置(++i)和后置(i++)两种使用形式。(i为变量)当使用后置用法(例如 i++)时,程序首先对该操作数进行引用,再对其自身进行加1或减1;当使用前置用法(例如++i)时,程序首先对操作数进行加1或减1,再对该操作数进行引用。
直接上例子:
int i=1,j;
j=++i;
因为++i是前置自增,所以i先自己加1后,再将结果赋给 j。因此 i 的值是2,j 的值也是2。
int i=1,j;
j=i++;
因为i++是后置自增,所以 i 先引用自己的原值赋给 j ,再自己加1、因此 i 的值为2,j 的值为1。
(同理可推至自减符号的运用)
简单来说,自增自减运算符的运算对象是紧跟着的操作数(上例中操作数为 i),与其他变量无关,前后置的区别仅在于对操作数的引用是先还是后。
//这里强调区别前后置是在操作数自增或者自减以后仍然需要运算或赋值的情况,如果操作数自增或自减以后就没有任何操作了,那前后置的作用是一致的,仅对操作数加1而已(即在后续介绍的for循环语句中i++和++i作用相同,也就是说在使用for循环时前置或者后置都可以)
附加说明(选读):
- 前置自增或者自减表达式的结果是返回对象本身,所以仍然是一个左值,而后置自增或自减表达式的结果则是右值。
- 自增或自减运算符是两个“++”或两个“–”的一个整体,中间不能有空格。如果有多于两个“++”或两个“–”连写的情况,编译时会首先识别自增或自减运算符。例如 a+++b表示为(a++)+b而不是a+(++b)。
- 在cout语句中的自增或自减运算中,不同编译器的处理方式可能不同。在调用函数时,实参的求值顺序一般为自右向左。
例如:
int a=1;
cout<
逻辑运算符和关系运算符
逻辑常量和逻辑变量
C语言中没有提供逻辑型常量,关系表达式的真和假分别用数值1和0代表。C++中增加了逻辑性数据。逻辑型常量只有两个 ,即true(真)和false(假)。逻辑型变量要用类型标识符bool来定义,他的值只能是true 或者是false之一。 如:
bool found,flag=false; //定义逻辑型变量found和flag,并使flag的初值为false
found=true; //将逻辑常量true赋给逻辑变量 found
如果此时该内容看不懂也没关系,你只需要知道:定义逻辑型变量的时候和一般的变量定义一样,只不过它的值不能是数字或者其他的值,只能是true和false两个值。
由于逻辑变量是用关键字bool来定义的,因此又称为布尔变量。逻辑型常量也称为布尔常量。
逻辑运算符和逻辑表达式
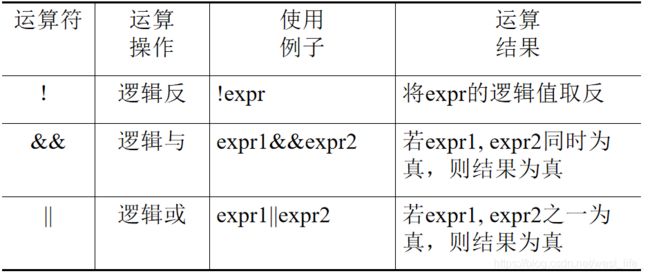
注意:C++中0被看做是逻辑假,而其他的非零值均被视为逻辑真。
bool start=-100; // start被赋初值true
bool end=0; //end被赋初值false
可用数学中的或、且、非来理解。
在一个逻辑运算中如果包含多个逻辑运算符,按以下的优先次序:
!(非)-> &&(与)-> ||(非)
即“!”为三者中优先次序最高的。直接上例子:
- 若a=5,则! a的值为0。因为a的值为非零,被认为是“真”,对它进行“非”运算,结果为“假”(0)
- 若a=4,b=5,则a&&b 的值为1。因为a和b均为非0,所以认为结果是“真”。
- 若a=4,b=-5,则(a-b)||(a+b)的值为1,。因为a-b和a+b的值均为非零值。
- 若a=4,b=5,则! a||b的值为1,因为!a 的值为0。
关系运算符和关系表达式
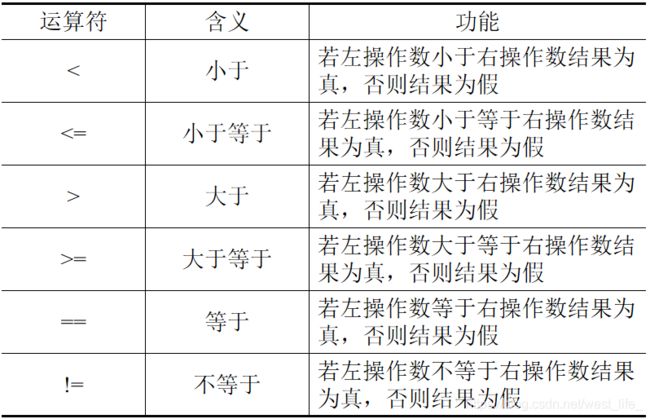
注意:
- 前四种关系运算符的优先级相同且比后面两种运算符的优先级高。
- C++中,通常把“真”表示为1,将“假”表示为0,而任何非0 的数都被认为是“真”,0被认为是“假”。
- !!!千万不要把赋值运算符“=” 作为关系运算符“==”来使用。
- 关系运算符的两个操作数可以使任何基本数据类型。
其他运算符
复合赋值运算符
C++中可使用的10中复合运算符,分别为:
+=,-=,*=,/=,%=,<<=,>>=,&=,^=,|=。
举一个栗子:
a+=10;
等价于
a=a+10; //相当于将a的值加上10,赋给a自己,也就是a自己的值加上10
sizeof()运算符
sizeof()不是函数,而是一种单目运算符。操作数可以是一个表达式或类型名,它给出操作数在内存中所占空间的字节数。(相当于提供一个工具让你查看操作数在内存中占的字节数)
cout<<sizeof(int)<<endl; //整型数据在内存中占的字节数为4
cout<<sizeof(35.0)<<endl; //double型数据在内存中占的字节数为8
cout<<sizeof(35); //整型数据占4字节
结果为
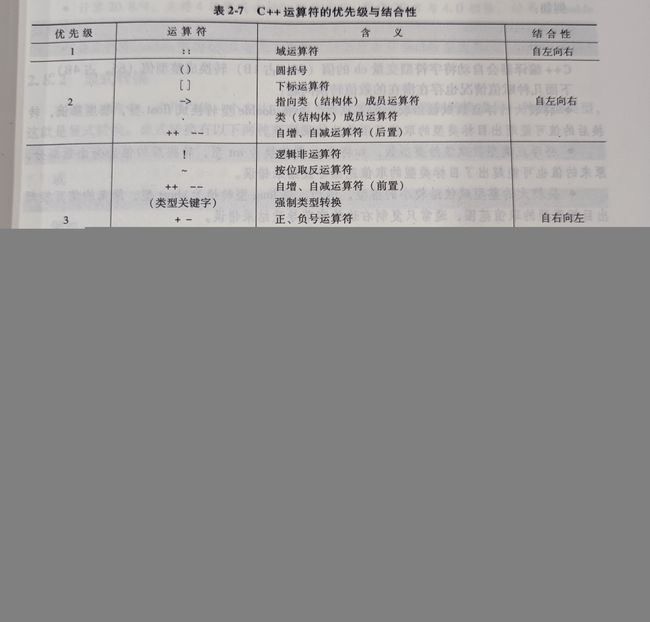
运算符的优先级与结合性
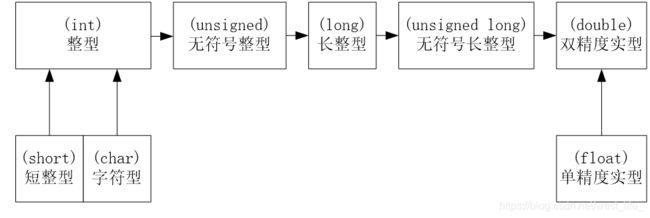
数据类型的转换
不同类型的数据在进行混合运算时,必须先转换成同一类型,然后再进行运算。C++采取两种方法对数据类型进行转换:隐式转换(也称自动转换)和显式转换(也称强制转换)。
- 表达式中的类型转换
2. 赋值时的类型转换
例如:
char ch='A';
int i=ch;
C++编译器会自动将字符型变量ch的值(65,占1B)(参照ASCAII码表)转换成整型值(65, 占4B)。
(类型转换相对好理解,可自行翻看课本详解)
程序控制
(从本章开始将要学习C/C++中十分重要的程序控制语句,经过前面的学习我们了解了这门语言的一些“汉字”和“潜规则”,那本章开始就要学习语言当中的“修辞手法”,这是我们初学者在提升自己代码水平的最有效的工具,务必重点学习!!!)
选择结构
选择结构就是根据给定的表达式判断下一步要执行程序的哪个分支。C++支持两种类型的选择语句:if 和switch 语句。另外,在特定的情况下,条件运算符“? :”被看做是if 语句的另一种表达形式。(待会可以详细讲讲它了)
if 语句
if 语句是最基本也最常用的流程控制语句。(因为实在是太好用了!也十分好理解)
if 语句的两种基本表达形式:
if(表达式)语句
//理解:表达式就是需要判断的条件
//如果程序跑到这一步,某些数据等满足括号里的条件,那么就执行紧跟后面的语句
//不然就不执行
//无论是 if 语句还是 if else 语句,一般为了书写规范和美观,我们会换行书写语句,如:
if(表达式)
语句
或者
if(表达式)语句1
else 语句2
//理解:上面讲到 if 表达式不满足的条件下会直接跳过 if 语句
//那么 if else 语句就是又多提供了一种选择
//如果满足表达式的条件,则执行语句1,否则就执行语句2
//可以看出在这种形式下,语句1和语句2只能执行其中之一,而不会两者同时执行