2021 ICCV论文分享 | 遮挡边界检测
这篇文章实际上正好解决了我想了好久的多种边界类型判断的问题。创新不大,但是解决问题的角度很好。这篇文章实际上正好解决了我想了好久的多种边界类型判断的问题。而且恰好我目前的数据集是可以做这个的,因此读一下。
文章信息
作者:Mengyang Pu, Yaping Huang, Qingji Guan, Haibin Ling (BJU & SBU)
来源:2021 ICCV
原文:https://openaccess.thecvf.com/content/ICCV2021/papers/Pu_RINDNet_Edge_Detection_for_Discontinuity_in_Reflectance_Illumination_Normal_and_ICCV_2021_paper.pdf
代码、数据和视频:https://github.com/MengyangPu/RINDNet
摘要
作为计算机视觉的基本组成部分,边缘可以根据表面的不连续性分为四种类型——反射率、照明度、表面法线或深度。虽然在检测通用或个别类型的边缘方面取得了很大进展,但综合研究所有四种边缘类型的研究仍然不足。
在本文中,我们提出了一种新的神经网络解决方案 RINDNet,用于联合检测所有四种类型的边缘。考虑到每种边缘的不同属性以及它们之间的关系,RINDNet 为每种边缘学习有效的表示,并分三个阶段工作。
在第一阶段,RINDNet 使用公共主干提取所有边缘共享的特征。
然后在第二阶段,它分支以通过相应的解码器为每种边缘类型准备判别特征。
在第三阶段,每种类型的独立决策负责人聚合前一阶段的特征以预测初始结果。此外,注意模块学习所有类型的注意图以捕获它们之间的潜在关系,并将这些图与初始结果相结合以生成最终的边缘检测结果。
对于训练和评估,我们构建了第一个公共基准 BSDS-RIND,对所有四种类型的边缘进行了仔细注释。在我们的实验中,与最先进的方法相比,RINDNet 产生了有希望的结果。补充材料中提供了额外的分析。
引言
边缘在许多视觉任务中起着重要作用 [33, 40, 43, 46]。虽然通用边缘检测 [14, 23, 41, 44] 已经被广泛研究了几十年,但特定边缘检测最近吸引了越来越多的努力,因为它涉及不同类型的边缘,例如遮挡轮廓 [25, 38 , 39] 或语义边界 [16, 48]。
在他的开创性工作 [27] 中,David Marr 总结了边缘可能出现的四种基本方式:(1) 表面反射不连续性,(2) 照明不连续性,(3) 表面法线不连续性,以及 (4) 深度不连续性,如图所示 图 1. 最近的研究 [33, 40, 43, 46] 表明,上述类型的边缘对下游任务是有益的。例如,路面裂缝检测(反射不连续)是智能交通的一项关键任务[46];阴影边缘(照明不连续)检测是阴影去除和路径检测的先决条件[43];[33] 和 [40] 表明深度边缘和法线边缘表示分别促进了精细的法线和锐利深度估计。此外,[18]同时利用四种类型的线索来提高深度细化的性能。
尽管它们很重要,但细粒度边缘仍未得到充分探索,尤其是与通用边缘相比。通用边缘检测器通常无法区分边缘。而针对特定边缘的现有研究则侧重于单个边缘类型。相比之下,据我们所知,四种基本类型的边缘从未在集成边缘检测框架中进行过探索。
在本文中,我们首次提出同时检测四种类型的边缘,即反射率边缘(RE),照明边缘(IE),正常边缘(NE)和深度边缘(DE)。尽管边缘在图像的强度变化中具有相似的模式,但它们具有不同的物理基础。具体来说,REs 和 IEs 主要与光度学原因有关——REs 是由材料外观的变化(例如纹理和颜色)引起的,而 IEs 是由照明的变化(例如阴影、光源和高光)产生的。相比之下,NEs 和 DEs 反映了物体表面的几何变化或深度不连续性。考虑到所有类型边缘之间的相关性和区别,我们开发了一种基于 CNN 的解决方案,名为 RINDNet,用于联合检测上述四种类型的边缘。RINDNet 分三个阶段工作。
在第一阶段,它从主干网络中提取所有边缘的一般特征和空间线索。
然后,在第二阶段,它使用四个独立的解码器进行。具体来说,低层特征首先通过权重层(WL)在高层提示的指导下进行整合,然后馈入 RE-Decoder 和 IE-Decoder 分别为 RE 和 IE 生成特征。同时,NE/DE-Decoder 以高层特征为输入,探索有效特征。
之后,这些特征和准确的空间线索被转发到第三阶段的四个决策头,以预测初始结果。最后,通过捕获所有类型之间的潜在关系的注意力模块 (AM) 获得的注意力图与初始结果聚合以生成最终预测。所有这些组件都是可区分的,使 RINDNet 成为一个端到端的架构,可以共同优化四种边缘的检测。
为所有四种类型的边缘训练和评估边缘检测器请求所有这些边缘都被注释的图像。在本文中,我们通过仔细标记来自 BSDS [2] 基准的图像(见图 1),创建了第一个已知的此类数据集,名为 BSDS-RIND。BSDS-RIND 允许对所有四种类型的边缘检测进行首次全面评估。所提出的 RINDNet 在数量和质量上都比以前的边缘检测器具有明显的优势。
通过上述努力,我们的研究有望激发沿线的进一步研究,并通过丰富的边缘线索使更多的下游应用受益。我们的贡献总结如下:
(1)我们开发了一种新颖的端到端边缘检测器 RINDNet,以联合检测四种类型的边缘。RINDNet 旨在有效地调查不同边缘之间的共享信息(例如,通过特征共享),同时灵活地建模它们之间的区别(例如,通过边缘感知注意力)。
(2) 我们提出了第一个公共基准 BSDSRIND,致力于同时研究四种边缘类型,即反射边缘、照明边缘、正常边缘和深度边缘。
(3) 在我们的实验中,提出的 RINDNet 显示出明显优于现有技术的优势。
相关工作
边缘检测算法。早期的边缘检测器 [5, 19, 42] 直接基于对图像辐射的分析获得边缘。相比之下,基于学习的方法 [11,21,28] 利用响应特征变化的不同低级特征,然后训练分类器以生成边缘。
基于 CNN 的边缘检测器 [3, 4, 9, 10, 17, 20, 24, 26, 31, 36, 45] 不依赖手工制作的特征并获得更好的性能。结合多尺度和多级特征,[14,23,31,44] 在通用边缘检测方面取得了显着进展。[41] 中还提出了一种新的细化架构,使用自上而下的反向细化路径来生成清晰的边缘。
最近的作品 [1,47,49,50] 更加关注特殊类型的边缘。在 [13] 中,通用对象检测器与自下而上的轮廓相结合以推断对象轮廓。CASENet [48] 采用嵌套架构来解决语义边缘检测问题。为了更好地预测,DFF [16] 学习自适应权重以生成每个语义类别的特定特征。对于遮挡边界检测,DOC [39]将任务分解为遮挡边缘分类和遮挡方向回归,然后使用两个子网络分别执行上述两项任务。
DOOBNet [38] 使用编码器解码器结构来获得多尺度和多层次的特征,并与两个分支共享主干特征。OFNet [25] 考虑了遮挡边缘和方向的相关性和区别,因此它共享遮挡两个子网络之间的线索。
边缘数据集。 已经提出了许多用于研究边缘的数据集。BSDS [2] 是一个流行的边缘数据集,用于检测包含 500 个 RGB 自然图像的通用边缘。尽管每个图像都由多个用户注释,但他们通常会关注与对象相关的显着边缘。BIPED [29] 旨在探索更全面和密集的边缘,并包含 250 个户外图像。NYUD [37] 包含 1, 449 个 RGB-D 室内图像,并且缺少与室外场景相关的边缘类型。值得注意的是,Multicue [29] 在边界检测期间考虑了几个视觉线索(亮度、颜色、立体、运动)之间的相互作用。
最近,SBD [13] 被提出用于检测语义轮廓,使用来自 PASCAL VOC 挑战 [12] 的图像。Cityscapes [7] 提供专注于道路场景的对象或语义边界。为了推理对象之间的遮挡关系,[34] 中的数据集由 200 张图像组成,其中边界分配有图形/地面标签。此外,PIOD [39] 包含 10, 000 张图像,每张图像都有两个注释:二进制边缘图表示边缘像素和连续值遮挡方向图。[33] 中的最新数据集注释了用于评估遮挡边界重建的 NYUD 测试集。
我们的工作受到上述先驱研究的启发,但在两个方面做出了新的贡献:据我们所知,提出的 RINDNet 是第一个联合检测所有四种类型边缘的边缘检测器,而提出的 BSDS-RIND 是注释了所有四种类型的边缘的第一个基准。
问题形式化以及benchmark
将边界分为4种类型,以及数据集构建方法。
RINDNet
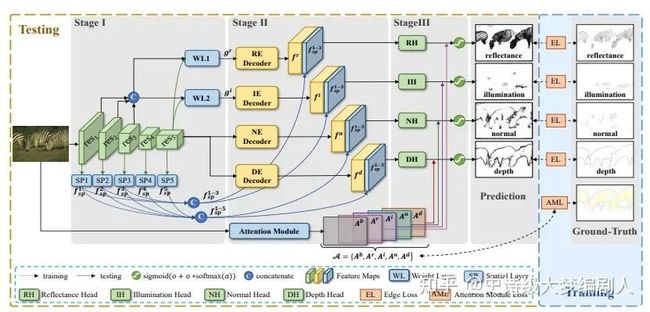
图 3. RINDNet 的三阶段架构。s1:输入图像被输入到主干中以提取与所有边缘类型共享的特征。s2:不同层次的特征通过权重层(WL)融合,并转发到四个解码器:RE/IE/NE/DE-Decoder。s3:四个决策器预测四型的初始结果。此外,注意力模块学习到的注意力图被整合到最终的预测中。
第一阶段:提取所有边缘的共同特征。我们首先使用主干来提取所有边缘的共同特征,因为这些边缘在图像的强度变化中具有相似的模式。主干遵循 ResNet-50 [15] 的结构,由五个重复的构建块组成。具体来说,来自 ResNet-50 [15] 的上述五个块的特征图分别表示为 res1、res2、res3、res4 和 res5。然后,我们从上述特征生成空间线索。众所周知,不同层的 CNN 特征编码不同级别的外观/语义信息,并对不同的边缘类型做出不同的贡献。具体来说,底层特征图 res1-3 更多地关注低级线索(例如,颜色、纹理和亮度),而顶层图 res4-5 更关注对象感知信息。因此,从特征图的不同层捕获多级空间响应是有益的。给定多个特征图 res1-5,我们得到空间响应图:
![]()
其中空间响应

由一个卷积层和一个反卷积层组成的空间层 学习。
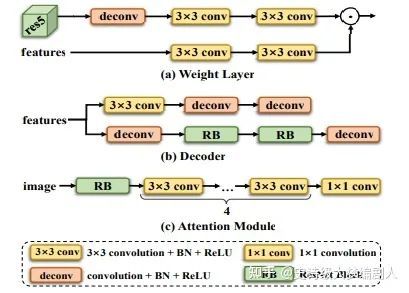
图4 网络模块具体实现
第二阶段:为 RE/IE 和 NE/DE 准备独特的功能。之后,RINDNet 在第二阶段通过相应的解码器分别学习每种边缘类型的特定特征。受 [25] 的启发,我们设计了具有两个流的解码器来恢复精细的位置信息,如图 4(b)所示。双流解码器可以协同工作,并从所提出架构的不同视图中学习更强大的特征。虽然四个解码器的结构相同,但针对不同类型的边缘提出了一些特殊的设计,我们将在下面进行详细说明。为了合理区分每种边缘类型并更好地描述我们的工作,我们接下来将四种边缘类型聚类为两组,即 REs/IE 和 NEs/DE,分别为它们准备特征。
RE 和 IE。 在实践中,低级特征(例如 res1-3)捕获通常反映在 RE 和 IE 中的详细强度变化。此外,REs 和 IEs 与由高级特征(例如 res5)提供的全局上下文和周围对象相关。因此,希望语义提示可以在转发到解码器之前给出正确的指导以感知强度变化。此外,值得注意的是,由于参数数量的增加,简单地连接低级和高级特征可能在计算上过于昂贵。
因此,我们提出了权重层(WL)以一种可学习的方式自适应地融合低级特征和高级提示,而不增加特征的维度。如图 4 (a) 所示,WL 包含两条路径:第一条路径通过反卷积层接收高级特征 res5 以恢复高分辨率,然后使用 Batch Normalization (BN) 和 ReLU 挖掘两个 3×3 卷积层自适应语义提示;另一条路径实现为具有 BN 和 ReLU 的两个卷积层,对低级特征 res1-3 进行编码。之后,它们通过元素乘法融合。形式上,给定低级特征 res1-3 和高级提示 res5,我们分别生成 RE 和 IE 的融合特征,
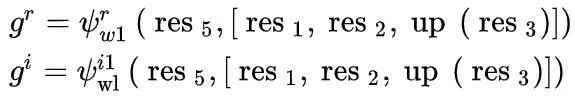
其中REs和IEs的WL分别表示为
![]()
和 , 是 REs/IEs 的融合特征,[·]是连接。请注意,res3 的分辨率小于 res1 和 res2,因此在 res3 上使用一次上采样操作 up(·) 以在特征连接之前提高分辨率。接下来,融合特征被送入相应的解码器,分别为 IE 和 RE 生成具有准确位置信息的特定特征,
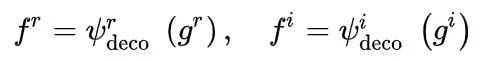
其中 ψr deco 和 ψ i deco 分别表示 REs 和 IEs 的解码器,f r /f i 是 REs/IE 的解码特征图。
NE 和 DE。由于高级特征(例如 res5)表达了通常在 NE 和 DE 中集中体现的强语义响应,我们利用 res5 来获取 NE 和 DE 的特定特征,
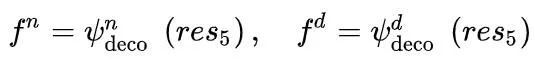
其中NE-Decode和DE-Decoder分别表示为ψn deco和ψd deco,fn/fd是NEs/DEs的解码特征。由于 DE 和 NE 通常共享一些相关的几何线索,我们共享 NE-Decoder 和 DE-Decoder 的第二个流的权重来学习协作几何线索。同时,NE-Decoder 和 DE-Decoder 的第一个流分别负责学习 REs 和 DEs 的特定特征。
第三阶段:产生初步结果。我们在最后阶段通过相应的决策头预测每种类型边缘的初始结果。前阶段的特征,包含丰富的边缘位置信息,可用于预测边缘。具体来说,我们将解码后的特征
![]()
与空间线索 连接起来以预测 REs/IEs,

其中 Or/Oi 是 REs/IEs 的初始预测。REs 和 IEs 的决策头,分别命名为 ψrh 和 ψih,被建模为 3×3 卷积层和 1×1 卷积层。请注意,RE 和 IE 不直接依赖于顶层提供的位置线索,因此空间线索 f4-5sp 不用于它们。相比之下,所有空间线索 f1-5sp 都与解码后的特征相连接,分别为 NE 和 DE 生成初始结果,
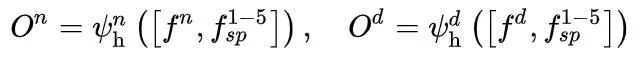
注意力模块。 最后,RINDNet 将初始结果与注意力模块 (AM) 获得的注意力图相结合以生成最终结果。由于不同类型的边缘反映在不同的位置,所以在预测每种类型的边缘时,需要更加关注相关的位置。幸运的是,边缘注释提供了每个位置的标签。因此,所提出的 AM 可以通过注意力机制通过逐像素监督来推断多个标签之间的空间关系。注意力图可用于激活相关位置的响应。形式上,给定输入图像 X,AM 学习空间注意力图
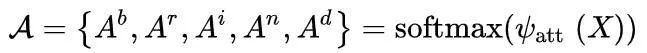
其中 A 是通过 softmax 函数归一化的注意力图,Ab, Ar, Ai, An, Ad ∈ [0, 1]W×H 是分别对应于背景、REs、IEs、NEs 和 DEs 的注意力图。显然,如果一个标签被标记到一个像素上,那么这个像素的位置应该被赋予更高的注意力值。AM ψatt 由 ResNet 的第一个构建块、四个 3×3 卷积层(每层后面是 ReLU 和 BN 操作)和一个 1×1 卷积层实现,如图 4(c)所示。
最后,将初始结果与注意力图相结合,生成最终结果 Y,
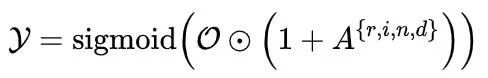
损失函数
边缘损失。我们使用 [38] 中提出的损失函数来监督我们的边缘预测的训练:

其中 Y = {Yr, Y i, Y n, Y d} 是最终预测,E ={Er, Ei, En, Ed} 是对应的真实标签,Ei,j /Yi,j 是 ( i, j) 矩阵 E/Y 的第一个元素。此外,α1 = |E-|/|E| 和 1 - α1 = |E+|/|E|,其中 E- 和 E+ 分别表示非边缘和边缘真实标签集。此外,γ1 和 β 是超参数。
注意力模块损失。 由于逐像素边缘标注提供了空间标签,因此很容易获得注意力的基本事实。令
![]()
为注意力的真实标签,其中 指定非边缘像素。如果第 (i, j) 个像素位于非边缘/背景上,则 ,否则 。 表示 REs、IE、NEs 和 DEs 的注意力标签, 分别由 E = {Er, Ei, En, Ed} 得到,
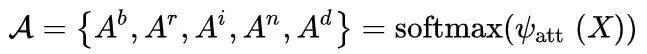
其中 k 表示边缘的类型,Tki,j 和 Eki,j 分别表示第 (i, j) 个像素的注意标签和边缘标签。如果一个像素只分配了一种类型的边缘标签,则注意力标签等于边缘标签,或者如果一个像素有多种类型,它将被标记为 255,在训练期间将被忽略。需要注意的是,在为每种类型的边缘训练四个决策头时使用多标记边缘,并且仅在训练 AM 时排除。AM的损失函数Latt表示为:
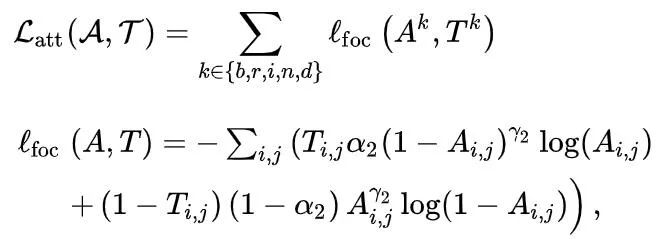
其中
![]()
表示Focal Loss [22],A是注意模块的输出。请注意,α2 和 γ2 分别是平衡重量和聚焦参数。
最后,将整个网络的损失定义如下:
![]()
其中,
![]()
是两部分 loss 的平衡因子。
实验与评估
一般论文实验部分实际上除了效果用来评价方法外基本可以快速掠过,但是这篇文章其中一部分还是可以引发思考的。因为文章在语义边界问题上引入了用于图像分割的网络进行边缘检测,那么实际上所有的语义分割网络本身都可以进行语义边界检测。
十个对比网络:
-
通用边界检测器(单类型):HED [44], RCF [23], CED [41], DexiNed [31], BDCN [14];
-
语义边界检测器(多类型):DeepLabV3+ [6], CASENet [48] DFF[16];
-
遮挡边界检测器(单类型):DOOBNet [38], OFNet [25
metrics:
-
fixed contour threshold (ODS)
-
per-image best threshold (OIS)
-
average precision (AP)
与现有技术的比较。为了同时适应四种边缘类型的现有检测器,它们通过两种方式进行修改:(1)输出
![]()
更改为 。特别是对于专注于分割的 DeepLabV3+,DeepLabV3+ 的输出层被替换为一条边路径(与 DOOBNet [38] 和 OFNet [25] 相同,包含四个 3×3 卷积块和一个 1×1 卷积层的序列) 来预测边缘图。
如表 1 所示,十个比较模型分别表示为 HED、RCF、CED、DexiNed、BDCN、CASENet、DFF、DeepLabV3+、DOOBNet 和 *OFNet。(2) DeepLabV3+、DOOBNet和OFNet只提供了一个边缘预测分支,没有适合多类预测的结构,因此我们提供了第二个修改:最后一个边缘预测分支扩展为四个,每个分支预测一种类型的边缘。修改类似于我们模型的预测方法,旨在探索这些模型的能力。它们分别被符号化为 DeepLabV3+、DOOBNet 和 OFNet。
个人总结:这篇文章在网络结构上创新并不明显,使用的backbone还是比较常见的Resblock,实际上创新主要在于使用了单编码器多解码器的结构。还有就是spatial layer的结构进行求解,之后使用attention map进行融合。
对于深度估计任务中使用的边界,实际上是有价值的,因为很多时候法线估计收到光线和颜色影响,最后才影响到了深度的重建。
作者:史诗级大梦编剧人
|关于深延科技|
深延科技成立于2018年1月,中关村高新技术企业,是拥有全球领先人工智能技术的企业AI服务专家。以计算机视觉、自然语言处理和数据挖掘核心技术为基础,公司推出四款平台产品——深延智能数据标注平台、深延AI开发平台、深延自动化机器学习平台、深延AI开放平台,为企业提供数据处理、模型构建和训练、隐私计算、行业算法和解决方案等一站式AI平台服务。