基于TensorRT和onnxruntime下pytorch的Bert模型加速对比实践
写在前面,自从2021年4月19日,跳槽以来,一直在忙于公司的项目和业务,没怎么看论文玩模型了,也没有写博客了。最近一直都在搞elasticsearch相关的东西,以及模型加速方面的工作,觉得很有价值,我也获得了成长,同时试用期也顺利渡过,百忙之中,抽出时间,完成了下面这篇博客。
由于业务需求上来了,需要对bert模型进行推理加速;现有的加速方案有很多,基于模型的压缩方向如模型蒸馏、模型量化、模型剪枝等,还有基于不修改模型结构(或者不需要自己动手修改)的前提下采用TensorRT或者onnxruntime来进行加速。在预研了onnxruntime和TensorRT的加速方法和做了很多实验的基础上,输出了一篇pytorch框架下bert模型加速对比效果,重点在于方案的尝试和实验结果的对比,以及代码的记录,原理上涉及的比较少。
一、onnxruntime和TensorRT简介
1、onnxruntime
ONNXRuntime是微软推出的一款推理框架,用户可以非常便利的用其运行一个onnx模型,进行推理和训练。一般而言,先把其他的模型转化为onnx格式的模型,然后进行session构造,模型加载与初始化和运行。其推理时采用的数据格式是numpy格式,而不是tensor张量,当然onnxruntime可以才GPU上也可以在CPU上运行。
其加速原理采用官网上的一段话:
ONNX Runtime applies a number of graph optimizations on the model graph then partitions it into subgraphs based on available hardware-specific accelerators. Optimized computation kernels in core ONNX Runtime provide performance improvements and assigned subgraphs benefit from further acceleration from each Execution Provider.
主要是对模型图进行优化,同时基于特定的硬件加速器把模型图切分为更小的子图,使用onnxruntime核心进行计算算子的优化。
2、TensorRT
TensorRT是英伟达公司针对自家的GPU产品开发的一个神经网络加速库。它只用于模型在GPU上的推理加速,不支持CPU,一般也不会用于模型的训练。TensorRT加速效果还是比较明显的,一般都是加速几倍、几十倍甚至上百倍。为何它能加速呢?
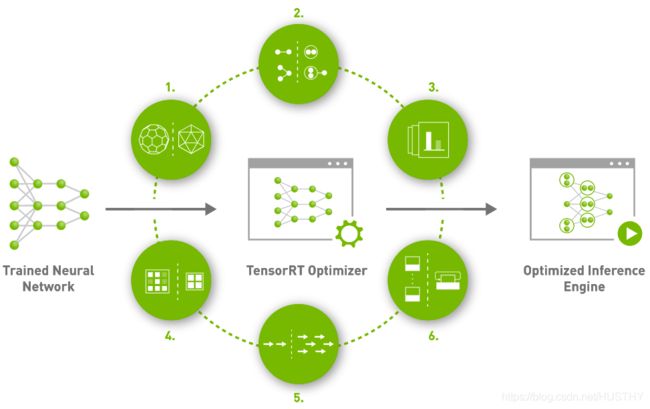
看上面官方给出一一张图:
1、Precision Calibration
精度校准——训练时由于梯度等对于计算精度要求较高,但是inference阶段可以利用精度较低的数据类型加速运算,降低模型的大小,例如FP16,int8,从而加速模型推理速度。
2、Layer & Tensor fusion
层和张量融合——TensorRT中将多个层的操作合并为同一个层,这样就可以一定程度的减少kernel launches和内存读写。比如把主流神经网络的conv、BN、Relu三个层融合为了一个层;把维度相同的张运算组合成另一个大的张量运算。每一层的运算操作都是由GPU完成的——GPU通过启动不同的CUDA(Compute unified device architecture)核心来完成计算的,CUDA核心计算张量的速度是很快的,但是往往大量的时间是浪费在CUDA核心的启动和对每一层输入/输出张量的读写操作上面,这造成了内存带宽的瓶颈和GPU资源的浪费。
3、Kernel Auto-Tuning
计算核心自动调整——TensorRT可以针对不同的算法,不同的网络模型,不同的GPU平台,进行 CUDA核的调整,以保证当前模型在特定平台上以最优性能计算。
4、 Dynamic Tensor Memory
动态张量显存——每个tensor的使用期间,TensorRT会为其指定显存,避免显存重复申请,减少内存占用和提高重复使用效率。
5、Multi-Stream Execution
并行处理多流输入——这个就是GPU底层优化,理解不了。
6、 Time Fusion
时间融合——使用动态生成的算子优化循环神经网络。
以上对为何能加速进行了简单的介绍,详细的原理很难有比较深刻的理解。总体就是量化——降低数据精度、cuda kernel 智能化计算、动态显存管理以及模型结构和张量融合突破GPU带宽瓶颈。
二、pytorch+onnxruntime的bert模型加速效果
onnxruntime要想加速pytorch下的bert模型,首先就需要把pytorch下的bert模型转化为.onnx模型文件,torch自带的框架就能完成这个工作;接下来就是构建session,把转化好的.onnx文件加载进来,喂入数据进行推理。
环境:linux centos、cuda11.2、pytorch1.8、python3.7、3090显卡、onnxruntime-gpu 1.8.1
直接上代码:
torch转化为onnx,并构建InferenceSession推理:
MODEL_ONNX_PATH = "../../onnx/torch_bert_base_fixed_" + str(batch_size) + ".onnx"
torch.onnx.export(model, org_dummy_input, MODEL_ONNX_PATH, verbose=True,
input_names=['input_ids', 'attention_mask'],
output_names=['output'], opset_version=11)
print("Export of torch_model.onnx complete!")
onnx_session = onnxruntime.InferenceSession(MODEL_ONNX_PATH)
pred_onnx = onnx_session.run(None, {'input_ids': inf_dummy_input[0], 'attention_mask': inf_dummy_input[1]})
完整代码如下:
import torch
import onnxruntime
from transformers import BertModel
import time
import matplotlib.pyplot as plt
from torch.quantization import quantize_dynamic
import sys
sys.path.append("../../")
from codes.dataReader.entity_data_reader import EntityDataReader
from torch.utils.data import DataLoader
import argparse
from tqdm import tqdm
def make_train_dummy_input(dataloader,device):
for batch in dataloader:
batch = [t.to(device) for t in batch]
dummy_input_ids = batch[0]
dummy_attention_masks = batch[1]
del batch
break
return (dummy_input_ids,dummy_attention_masks)
def make_inference_dummy_input(dataloader,device):
for batch in dataloader:
batch = [t.to(device) for t in batch]
inf_input_ids = batch[0]
inf_attention_masks = batch[1]
del batch
break
return (inf_input_ids, inf_attention_masks)
def set_args():
parser = argparse.ArgumentParser(description='train_bert_entity_classification args')
parser.add_argument('--model_path',type=str,default='../../pretrain_models/chinese-bert-wwm-ext')
parser.add_argument('--batch_size',default=128 ,type = int)
parser.add_argument('--test_file_path', default='../../data/data_clean/entity_train.xlsx', type=str)
args = parser.parse_args()
return args
if __name__ == '__main__':
args = set_args()
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
count = 1001
model = BertModel.from_pretrained(args.model_path)
model.to(device)
model.train(False)
test_dataset = EntityDataReader(args.test_file_path, args.model_path)
org_dummy_input = make_train_dummy_input(test_dataloader, device)
org_meantimes = []
onnx_meantimes = []
batch_sizes = [ 2**i for i in range(0,9)]
for batch_size in batch_sizes:
test_dataloader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
#org_dummy_input = make_train_dummy_input(test_dataloader, device)
inf_dummy_input = make_inference_dummy_input(test_dataloader, device)
MODEL_ONNX_PATH = "../../onnx/torch_bert_base_fixed_" + str(batch_size) + ".onnx"
torch.onnx.export(model, org_dummy_input, MODEL_ONNX_PATH, verbose=True,
input_names=['input_ids', 'attention_mask'],
output_names=['output'], opset_version=11)
print("Export of torch_model.onnx complete!")
onnx_session = onnxruntime.InferenceSession(MODEL_ONNX_PATH)
totaltime = 0
for i in tqdm(range(count), ncols=50):
t1 = time.time()
output = model(*inf_dummy_input)[0]
if i ==0:
print(output.shape)
del output
t2 = time.time()
if i >0:
totaltime += (t2 - t1)
org_meantime = totaltime / count
print('Bert inference mean time is %.4f' % (totaltime / count))
inf_dummy_input = [t.cpu().numpy() for t in inf_dummy_input]
totaltime = 0
for i in tqdm(range(count), ncols=50):
t1 = time.time()
pred_onnx = onnx_session.run(None, {'input_ids': inf_dummy_input[0], 'attention_mask': inf_dummy_input[1]})
t2 = time.time()
if i == 0:
print(pred_onnx[0].shape)
del pred_onnx
if i >0 :
totaltime += (t2 - t1)
onnx_meantime = totaltime / (count-1)
print('Bert inference by onnxruntime mean time is %.4f' % (totaltime / (count-1)))
onnx_meantimes.append(onnx_meantime*1000)
org_meantimes.append(org_meantime*1000)
del org_dummy_input
del inf_dummy_input
del onnx_session
torch.cuda.empty_cache()
plt.plot(batch_sizes,org_meantimes,color='red',label='bert_base infr time')
plt.plot(batch_sizes, onnx_meantimes, color='blue', label='bert_base onnx infr time')
plt.grid(alpha=0.4, linestyle=':')
plt.legend(loc="upper right")
plt.ylabel("inference time/ms")
plt.xlabel("batch size")
plt.savefig('../../onnx/acceleration_comparsion.png')
plt.show()
结果如下图:
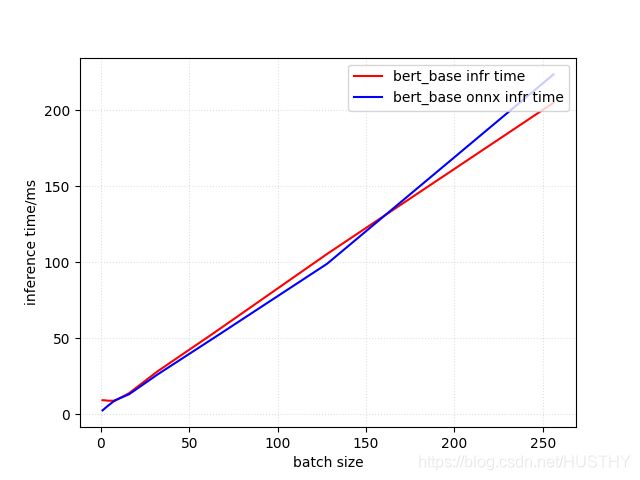
seq_length=100,hidden_state=768 ,可以看到加速效果只有在batch-size小于10以及32-160之间
才有效果,而且是batch_size = 1 的时候比较明显。
seq_length=100,hidden_state=256的时候,结果不一样,如下图(bert-small版本):
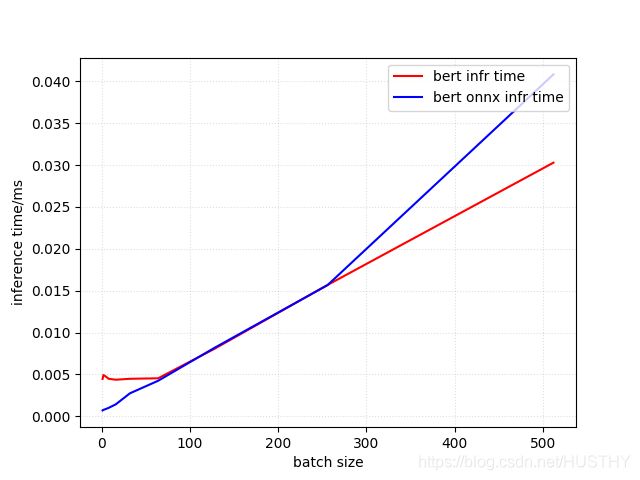
图上的时间单位应该是ms,batch_size = 1的时候加速效果大概是5倍,<64batch_size<256两者差不多,batch_size>256以后3090上纯GPU推理更快。
纯GPU下,可以得出batch_size<某个值的时候,推理时间一样;后面随着batch_size增大线性增加,当然也和hidden_state密切相关。
onnxruntime在小batch_size下还是有一定的加速效果的,相对纯GPU而言。
三、pytorch+onnx+TensorRT的bert模型加速效果
这个技术方案稍微麻烦一点,需要把pytorch转成的onnx模型再转化为tensorrt下的.trt文件,这里又又两种方法(其实是一种,一种需要代码,一种不需要代码);
1、采用TensorRT自带的trtexc把onnx转化为.trt
2、调用tensorrt的API把onnx转化为.trt
以上方法在转化过程中,bert构建engine的时候,对tensorRt的版本要求比较高,我这里使用的是8.0.1.6,其他的低版本都试过,转化的过程中都会报错,不支持pytorch中bert某些算子,需要修改bert的源码,也是比较麻烦。
当然还有一种更直接的办法就是使用tensorrt的API直接把pytorch下的bert模型构建成一个trt的engine执行推理,这个需要对tensorrt的API非常熟悉,以及bert模型的权重和结构非常熟悉,对代码功底要求也比较高,这个等以后有时间了再来实现,简单的图片分类模型例子可以参考TensorRt 官方github给出的例子——目前没有时间,后面自己一定要实现一遍,对自己很有作用。
环境:linux centos、cuda11.2、pytorch1.8、python3.7、3090显卡、tensorrt8.0.1.6
1、采用TensorRT自带的trtexc把onnx转化为.trt
在linux系统安装好的TensorRT-8.0.1.6,bin目录中,可以看到trtexec:

转化命令:
./trtexec --onnx=onnxModelFilePath --saveEngine=trtEngineFliePath这样就能把一个.onnx模型转化为tensorRT的engine文件
给出一个示例:
./trtexec --onnx=/home/AI_team/yanghuang/competition/onnx/torch_bert_base_fixed_256.onnx --maxBatch=200 --workspace=1000 --fp16 --saveEngine=/home/AI_team/yanghuang/competition/tensorrt_engine/torch_bert_base_fixed_256.trt--onnx:指定onnx模型路径
--maxBatch=200:指定trt最大的batch_size=200
--workspace=1000:指定转化过程中的工作空间是1000M
--fp16:指定采用了fp16精度——半精度,也还可以是int8
--saveEngine:指定trt文件保存的路径
以上就是常用的参数,其中--onnx和--saveEngine是必须的,其他可选(因为有默认选项)
还有很多其他的参数,它们具体是什么有什么作用,需要读者自己去研究了./trtexec --h就可以查看全部的参数。
对于很大的模型不好开启详细的转化日志,不然就要等很久了
转化过程和结果截图:
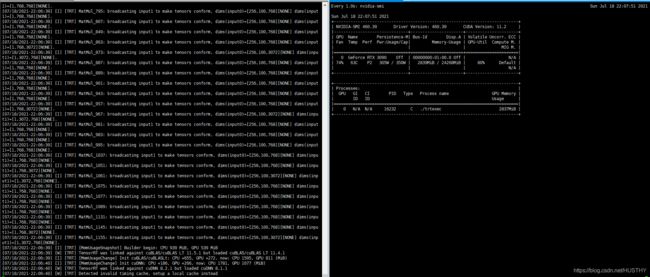
转化过程中,GPU参与运算
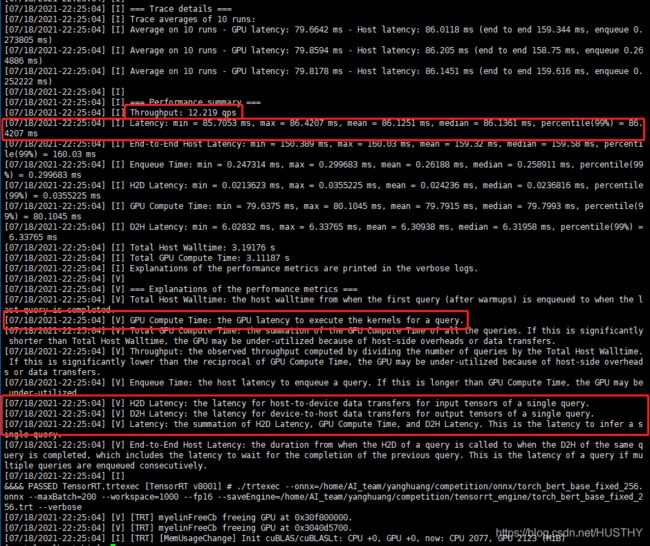
可以看到batch_size = 256的时候,bert_base版本模型推理吞吐量Throughout=12.22,推理平均时间是:86毫秒,也就是截图中的Latency——延迟——GPU计算时间+H2D+D2H处理一个query的时间之和。
2、调用tensorrt的API把onnx转化为.trt
主要的API是
trt.Builder(TRT_LOGGER) as builder创建一个builder
builder.create_network(explicit_batch) as network创建一个空的网络
trt.OnnxParser(network, TRT_LOGGER) as parser创建一个onnx解析器
trt.Runtime(TRT_LOGGER) as runtime创建一个trt的运行环境
config = builder.create_builder_config()创建builder_config
设置一些属性后,就可以直接解析onnx然后转化为trt engine
plan = builder.build_serialized_network(network, config) engine = runtime.deserialize_cuda_engine(plan)
序列化和反序列化engine
完整代码
def get_engine(max_batch_size=1, onnx_file_path="", engine_file_path="", fp16_mode=True, int8_mode=False, save_engine=False):
"""Attempts to load a serialized engine if available, otherwise builds a new TensorRT engine and saves it."""
explicit_batch = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)#这句一定需要加上不然会报错
def build_engine(max_batch_size, save_engine):
"""Takes an ONNX file and creates a TensorRT engine to run inference with"""
with trt.Builder(TRT_LOGGER) as builder, \
builder.create_network(explicit_batch) as network, \
trt.OnnxParser(network, TRT_LOGGER) as parser, \
trt.Runtime(TRT_LOGGER) as runtime:
print(network.num_layers)
print(network.num_inputs)
print(network.num_outputs)
print(network.name)
config = builder.create_builder_config()
config.max_workspace_size = 1 << 30 # 256MiB
builder.max_batch_size = max_batch_size
if fp16_mode:
config.set_flag(trt.BuilderFlag.FP16)
elif int8_mode:
config.set_flag(trt.BuilderFlag.INT8)
else:
config.set_flag(trt.BuilderFlag.REFIT)
flag = builder.is_network_supported(network,config)
print('flag',flag)
# Parse model file
if not os.path.exists(onnx_file_path):
quit('ONNX file {} not found'.format(onnx_file_path))
print('Loading ONNX file from path {}...'.format(onnx_file_path))
with open(onnx_file_path, 'rb') as model:
print('Beginning ONNX file parsing')
# print(type(model.read()))
parser.parse(model.read())
# parser.parse_from_file(onnx_file_path)
assert network.num_layers > 0, 'Failed to parse ONNX model.Please check if the ONNX model is compatible '
# last_layer = network.get_layer(network.num_layers - 1)
# network.mark_output(last_layer.get_output(0))
print('Building an engine from file {}; this may take a while...'.format(onnx_file_path))
plan = builder.build_serialized_network(network, config)
engine = runtime.deserialize_cuda_engine(plan)
print("Completed creating Engine")
if save_engine:
with open(engine_file_path, "wb") as f:
f.write(plan)
return engine
if os.path.exists(engine_file_path):
# If a serialized engine exists, load it instead of building a new one.
print("Reading engine from file {}".format(engine_file_path))
with open(engine_file_path, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:
return runtime.deserialize_cuda_engine(f.read())
else:
return build_engine(max_batch_size, save_engine)注意——
explicit_batch = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
这句代码一定需要指定,不然会报错。
3、tensorrt进行推理加速
使用tensorrt进行推理加速稍微有点麻烦,总结起来步骤就是:
a、获取engine,建立上下文
engine = get_engine(engine_model_path)
context = engine.create_execution_context()b、从engine中获取inputs, outputs, bindings, stream的格式以及分配缓存
inputs, outputs, bindings, stream = common.allocate_buffers(engine)
class HostDeviceMem(object):
def __init__(self, host_mem, device_mem):
self.host = host_mem
self.device = device_mem
def __str__(self):
return "Host:\n" + str(self.host) + "\nDevice:\n" + str(self.device)
def __repr__(self):
return self.__str__()
# Allocates all buffers required for an engine, i.e. host/device inputs/outputs.
def allocate_buffers(engine):
inputs = []
outputs = []
bindings = []
stream = cuda.Stream()
for binding in engine:
size = trt.volume(engine.get_binding_shape(binding)) * engine.max_batch_size
dtype = trt.nptype(engine.get_binding_dtype(binding))
# Allocate host and device buffers
host_mem = cuda.pagelocked_empty(size, dtype)
device_mem = cuda.mem_alloc(host_mem.nbytes)
# Append the device buffer to device bindings.
bindings.append(int(device_mem))
# Append to the appropriate list.
if engine.binding_is_input(binding):
inputs.append(HostDeviceMem(host_mem, device_mem))
else:
outputs.append(HostDeviceMem(host_mem, device_mem))
return inputs, outputs, bindings, streamc、输入数据填充
在第二步从engine得到了输入输出的数据格式以及分配了缓存,要使用其他的推理数据,就要把新的数据填充进去
inputs, outputs, bindings, stream = common.allocate_buffers(engine)
inf_dummy_inputs_all = []
for i in tqdm(range(count),ncols=50):
inf_dummy_inputs = make_inference_dummy_input(test_dataloader,device)
inf_dummy_inputs_all.append(inf_dummy_inputs)
for input,inf_dummy_input in zip(inputs,inf_dummy_inputs):
temp = inf_dummy_input.view(-1).numpy().astype(np.int32)
input.host = temp注意这里输入的数据格式是np的int32,不是张量也不是int64。
d、tensorrt推理
细节在代码中有详细的注释
# This function is generalized for multiple inputs/outputs.
# inputs and outputs are expected to be lists of HostDeviceMem objects.
def do_inference(context, bindings, inputs, outputs, stream, batch_size=1):
# Transfer input data to the GPU.
[cuda.memcpy_htod_async(inp.device, inp.host, stream) for inp in inputs]
# Run inference.
context.execute_async(batch_size=batch_size, bindings=bindings, stream_handle=stream.handle)
# Transfer predictions back from the GPU.
[cuda.memcpy_dtoh_async(out.host, out.device, stream) for out in outputs]
# Synchronize the stream
stream.synchronize()
# Return only the host outputs.
return [out.host for out in outputs]完整的tensorrt推理和纯GPU效果对比代码:
import torch
from transformers import BertModel
import time
import logging # 引入logging模块
logging.basicConfig(level=logging.DEBUG,format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s')
import sys
sys.path.append('../../')
logging.info('{}'.format(sys.path))
from codes.dataReader.entity_data_reader import EntityDataReader
import codes.onnx_trt.common as common
from torch.utils.data import DataLoader
import argparse
from tqdm import tqdm
import tensorrt as trt
TRT_LOGGER = trt.Logger() # This logger is required to build an engine
import random
import numpy as np
def make_train_dummy_input(dataloader,device):
for batch in dataloader:
batch = [t.to(device) for t in batch]
dummy_input_ids = batch[0]
dummy_attention_masks = batch[1]
break
return (dummy_input_ids,dummy_attention_masks)
def make_inference_dummy_input(dataloader,device):
for batch in dataloader:
batch = [t.to(device) for t in batch]
inf_input_ids = batch[0]
inf_attention_masks = batch[1]
break
return (inf_input_ids, inf_attention_masks)
def set_args():
parser = argparse.ArgumentParser(description='train_bert_entity_classification args')
parser.add_argument('--model_path',type=str,default='../../pretrain_models/chinese-bert-wwm-ext')
parser.add_argument('--batch_size',default=256 ,type = int)
parser.add_argument('--test_file_path', default='../../data/data_clean/entity_train.xlsx', type=str)
args = parser.parse_args()
return args
def get_engine(engine_file_path):
print("Reading engine from file {}".format(engine_file_path))
with open(engine_file_path, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:
return runtime.deserialize_cuda_engine(f.read())
def create_random_sample(batch_size):
batch = []
for i in range(batch_size):
t = [2]
for j in range(98):
t.append(random.randint(0, 14467))
t.append(3)
batch.append(t)
input_ids = torch.tensor(batch, dtype=torch.long)
token_type_ids = torch.zeros((batch_size, 100), dtype=torch.long)
attention_mask = torch.ones((batch_size, 100), dtype=torch.long)
return (input_ids, token_type_ids, attention_mask)
if __name__ == '__main__':
args = set_args()
test_dataset = EntityDataReader(args.test_file_path, args.model_path)
test_dataloader = DataLoader(test_dataset, batch_size=args.batch_size, shuffle=False)
device = 'cpu'
count = 10
trt_results = []
nue_results = []
# batch_size = 100
nue_gpu_totaltime = 0
nue_trt_totaltime = 0
engine_model_path = "../../tensorrt_engine/torch_bert_base_fixed_256.trt"
engine = get_engine(engine_model_path)
context = engine.create_execution_context()
inputs, outputs, bindings, stream = common.allocate_buffers(engine)
inf_dummy_inputs_all = []
for i in tqdm(range(count),ncols=50):
inf_dummy_inputs = make_inference_dummy_input(test_dataloader,device)
inf_dummy_inputs_all.append(inf_dummy_inputs)
for input,inf_dummy_input in zip(inputs,inf_dummy_inputs):
temp = inf_dummy_input.view(-1).numpy().astype(np.int32)
input.host = temp
t1 = time.time()
output = common.do_inference(context, bindings=bindings, inputs=inputs, outputs=outputs, stream=stream)
t2 = time.time()
nue_trt_totaltime += (t2-t1)
output[0] = output[0].reshape(args.batch_size, -1)
if i==0:
print('output[0].shape',output[0].shape)
del output
torch.cuda.empty_cache()
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
nue_model = BertModel.from_pretrained(args.model_path)
nue_model.to(device)
nue_model.eval()
with torch.no_grad():
for i in tqdm(range(count),ncols=50):
inf_dummy_inputs = inf_dummy_inputs_all[i]
inf_dummy_inputs = [t.to(device) for t in inf_dummy_inputs]
t1 = time.time()
logits = nue_model(*inf_dummy_inputs)[0]
nue_results.append(logits.detach().cpu().numpy())
t4 = time.time()
if i==0:
print('logits.shape',logits.shape)
nue_gpu_totaltime += (t4 - t1)
del inf_dummy_inputs
del logits
torch.cuda.empty_cache()
print("bert inference by 3090GPU with tensorrt per batch time is %.4f"%(nue_trt_totaltime/count))
print("bert inference by 3090GPU per batch time is %.4f" % (nue_gpu_totaltime / count))上面的代码有一个值得注意的点就是——
common.do_inference(context, bindings=bindings, inputs=inputs, outputs=outputs, stream=stream)
推理的代码do_inference运行之前不要设置device为GPU上的cuda,不然就会出现错误
[TensorRT] ERROR: 1: [slice.cu::launchNaiveSliceImpl::148] Error Code 1: Cuda Runtime (invalid resource handle)

最终对比结果如下:
a、采用./trtexec得到的trt engine
engine_model_path = "../../tensorrt_engine/torch_bert_base_fixed_256.trt"
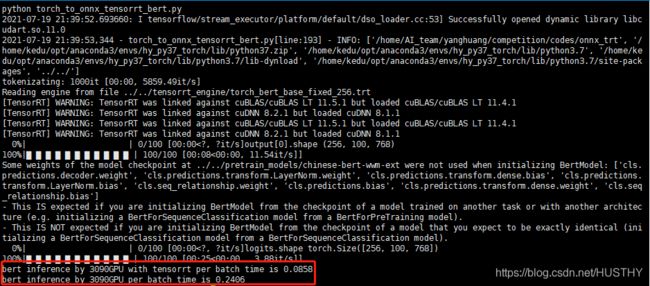
采用tensorrt使用3090来推理batch_size=256,fp16用时85.8ms;纯GPU模式下240.6ms,提升3倍,这里和./trtexec转化onnx为trt过程中给出的推理时间是一致的
b、采用tensorRT API得到的trt engine
engine_model_path = "../../tensorrt_engine/torch_bert_base_fixed_256_api.trt"
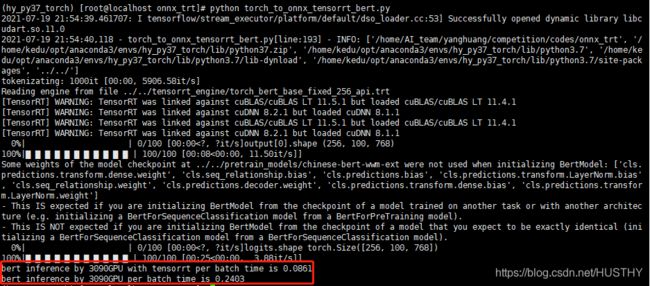
采用tensorrt使用3090来推理batch_size=256,fp16用时86.1ms;纯GPU模式下240.3ms,提升3倍,这里和./trtexec转化onnx为trt过程中给出的推理时间也是一致的,和上面的a方案也是一致的,本次实验应该是正确无误的。
加速效果还是比较明显的,当然这里可能有一点点精度损失,在不采用fp16的情况下,我们的业务模型的精度是99.72%。
以上就是这段时间预研tensorrt的收获,算是能走通流程,能搭建一定的任务了。
关于int8模式没有去研究,套路应该是一样的,不过比较麻烦的应该是需要一个精度校准器Calibrator,后面有需要或者有空的时候可以研究一下,应该不会花太多时间。
参考文章
TensorRT-优化-原理
PyTorch模型转TensorRT是怎么实现的?
onnxruntime官网
英伟达TensorRT官网
tensorrt的API文档