Keras基础
1. Keras基础
1.1 Keras

Keras是一个用Python 编写的高级神经网络API,它能够以TensorFlow,CNTK,或者Theano作为后端运行。Keras的开发重点是支持快速的实验。能够以最小的时延把你的想法转换为实验结果,是做好研究的关键。
●允许简单而快速的原型设计(由于用户友好,高度模块化,可扩展性)。
●同时支持卷积神经网络和循环神经网络,以及两者的组合。
●在CPU和GPU上无缝运行。
1.2 安装Keras
pip install keras#安装Keras
pip install tensorflow#安装后端tensorflow
pip install theano#安装后端theano,比tensorflow轻量级
修改配置文件:keras.json文件

1.3 Keras的张量
在keras中,数据是以张量(tensor) 的形式表示的,张量的形状称之为shape,比如,
一个一阶的张量[1 ,2,3]的shape是(3,);
一个二阶的张量[[1 ,2,3],[4,5,6]]的shape是(2,3); .
一个三阶的张量[1],[2],[1][[4],[5],[6]]]的shape是(2,3,1)。
对于图像样本来说训练数据集的张量是四阶的: shape是
2 DNN的keras实战
2.1 目标案例
2.2 数据读取
#读取数据
import numpy as np
from os import listdir
def img2vector(filename):
returnVect = np.zeros((32,32))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[i,j] = int(lineStr[j])
return returnVect
from keras.utils.np_utils import to_categorical
hwLabels = []
trainingFileList = listdir('trainingDigits')
m = len(trainingFileList)
trainingMat = []
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(to_categorical(classNumStr, 10))#独热编码,从一维变成十维输出
trainingMat.append(img2vector('trainingDigits/%s'%fileNameStr))
trainY=np.array(hwLabels)
trainX=np. array(trainingMat)
a=to_categorical(0,6)2.3 建立模型
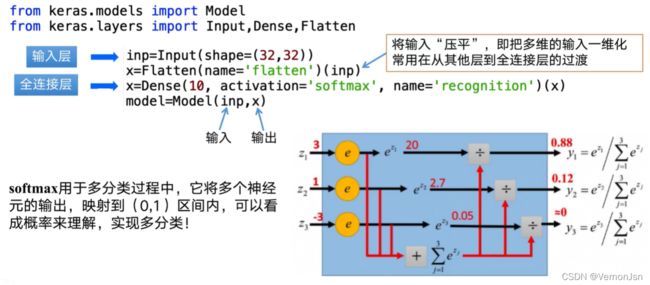
from keras.models import Model
from keras.layers import Input,Dense,Flatten
inp=Input(shape=(32,32))
x=Flatten(name='flatten')(inp)
x=Dense(10,activation='softmax',name='recognition')(x)
model=Model(inp,x)
2.4 模型编译和显示
model.compile(optimizer='adam',loss='mse',metrics= ['accuracy']) model.summary()
optimizer:优化器
SGD:随机梯度下降优化器
RMSprop:均方根传播优化器,通常是训练循环神经网络RNN的不错选择
AdaGrad:适应性梯度优化器,每一个参数保留一-个学习率以提升在稀疏梯度上的性能
Adam:自适应矩估计优化器,同时获得了AdaGrad和RMSProp算法的优点。
loss:损失函数(目标函数)
目标函数有mse、mae、mape、 msle、 squared_ hinge 、hinge 、binary_ _crossentropy、
categorical_ _crossentrop 、sparse_ _categorical_ crossentrop等
mse :均方根误差
metrics:评价指标(评价函数和损失函相似,只不过评价函数的结果不会用于训练过程中)
运行结果:

2.5 模型训练
history=model.fit(trainX,trainY, validation_split=0.1, epochs=100,batch_size=32,) 验证集,就如同高考的模拟考试。不同于高考,模拟考只是你调整自己状态的指示器而已。状态不够满意,你可以继续调整。不能用测试集作为验证集,那是作弊
2.6 模型测试
testFileList = listdir('testDigits')
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList [i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
testVector= []
testVector.append(vectorUnderTest)
testX=np.array(testVector);
classifierResult = np.argmax(model.predict(testX))#argmax获得最大值索引
print ("DNN得到的辨识结果是: %d,实际值是: %d"% (classifierResult, classNumStr))
if (classifierResult != classNumStr): errorCount += 1.0
print ("\n辨识错误数量为: %d" % errorCount)
print ("\n辨识率为: %f %" % ((1-errorCount/float(mTest))*100))2.7 绘制学习曲线
#绘制学习曲线
import matplotlib.pyplot as plt
plt. plot(history. history['loss'])
plt. plot (history. history['val_loss'] )
plt. title( 'Model loss')
plt.ylabel('Loss')
plt. xlabel('Epoch')
plt.legend( ['Train', 'Val'],loc= 'upper left')
plt. show(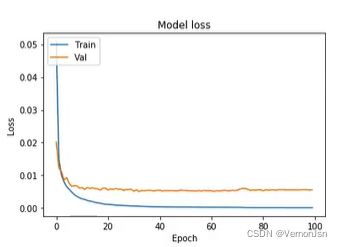
2.8 模型训练复现
深度学习的超参数初始化是随机数,每次结果都不一样
seed = 42
np. random. seed ( seed)
固定随机种子,使得模型训练结果可以复现
2.9 保存和加载模型
将训练过程中表现最好的模型记录下来
#模型保存和加载
from keras.callbacks import ModelCheckpoint
from keras.models import load_model
modelfilepath= 'model.best.hdf5' #模型文件名
checkpoint = ModelCheckpoint (modelfilepath,
monitor='val_accuracy',#验证集精度
verbose=1,#显示保存记录
save_best_only=True,#保留最好的
mode=' max')#取最大的模型保存下来
# testmodel= load_model(modelfilepath)在训模型中添加保存参数:history=model.fit(trainX,trainY, validation_split=0.1, epochs=100,batch_size=32,callbacks= [checkpoint])#模型保存参数
2.10 自动停止训练
#自动停止训练
from keras . callbacks import EarlyStopping
earlyStop=EarlyStopping (monitor='val_ _accuracy',
patience=20, #容忍20次记录不发生改变(精度20次不提高了)
verbose=1, #显示记录
mode='auto')
在训模型中添加保存参数:history=model.fit(trainX,trainY, validation_split=0.1, epochs=100,batch_size=32,callbacks= [checkpoint,earlyStop])#模型保存参数
2.11 学习率的调整
#学习率的调整
from keras.callbacks import ReduceLROnPlateau
reduce_lr = ReduceLROnPlateau( monitor='val_loss', #验证集损失值
factor=0.1,
patience=10, #允许10次不发生改变
verbose=1,
mode='auto', #自动判断
min_delta=0.00001, #每次学习率的变化量不小于0.00001
cooldown=0, #允许经过patience=10次没发生改变后冷静几次
min_lr=0) #最小学习量在训模型中添加保存参数:history=model.fit(trainX,trainY, validation_split=0.1, epochs=100,batch_size=32,callbacks= [checkpoint,reduce_lr,earlyStop])#模型保存参数
2.12 模型讨论——加深网络层数
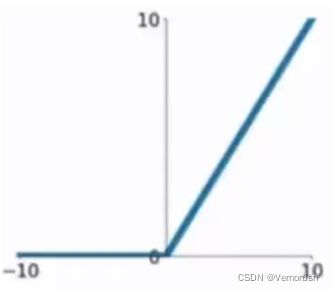
ReLU函数是目前比较火的一一个激活函数,函数公式: f(x)=max(0,x)相比sigmod函数与tanh函数有以下几个优点
●克服梯度消失的问题
●加快训练速度
注:正因为克服了梯度消失问题,训练才会快.
缺点:
●输入负数,则完全不激活,Rel U函数死掉。
●ReLU函数输出要么是0,要么是正数,也就是Rel U函数不是以0为中心的函数
#添加一层神经网络
inp=Input(shape= (32,32))
x=Flatten(name= 'flatten')(inp)
x=Dense(400,activation='relu',name= 'dense-1')(x)
x=Dense(10,activation='softmax',name='recognition')(x)
model=Model(inp,x)构建模型后会显示有两个连接层:

2.12 模型讨论——Dropout
Dropput作用:随机抛出一些网络节点,导致输入过程并非完全的全连接,避免了过拟合现象。
inp=Input(shape= (32,32))
x=Flatten(name= 'flatten')(inp)
x=Dense(400,activation='relu',name= 'dense-1')(x)
x=Dropout(0.2,name = 'dropout-1')(x)
x=Dense(10,activation='softmax',name='recognition')(x)
model=Model(inp,x)
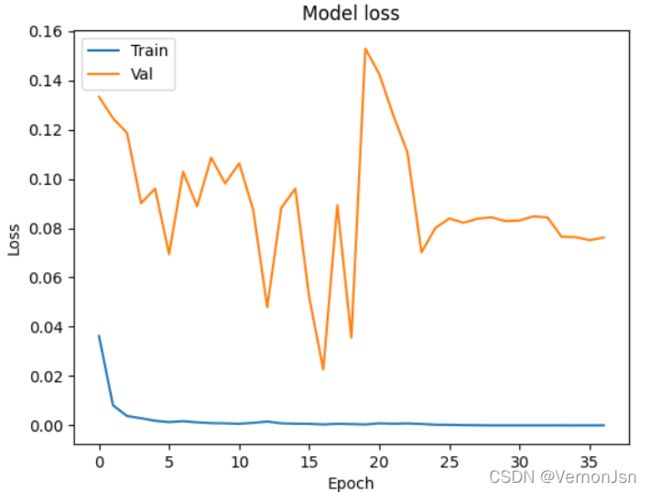
在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象。
在训练神经网络的时候经常会遇到过拟合的问题:
过拟合具体表现在:模型在训练数据上预测准确率越来越高;
但是在测试数据上预测准确率无法提升或反而降低。
模型:

最终结果:辨识错误数量为: 52
辨识率为: 94.503171
3 CNN的Keras实战
3.1 数据处理
由于卷积神经网络是处理图片数据的,因此我们也需要对输入数据进行处理
trainX=np.array(trainingMat)
print(trainX.shape )
trainX=trainX.reshape((trainX.shape[0],
trainX.shape[1],
trainX.shape[2],
1))
#CNN样本数据、宽度、高度、通道数3.2 建立模型
from keras.models import Model
from keras.layers import Input , Dense, Flatten, Dropout , Conv2D , MaxPool2D
inp=Input (shape=(32, 32,1))#宽度、高度、通道数
x=Conv2D(50, (5,5), padding='valid' ,strides=(1,1), activation='relu' , name='conv-1')(inp)
#卷积层 50个神经元、(5,5)是5*5的卷积核大小、padding='valid'是padding为空、strides:步长、activation:激活函数、name:名字
x=MaxPool2D( pool_size=(2,2),strides=(2,2),padding='valid', name='pool-1')(x)
#池化层 pool_size:池化窗口大小,strides:步长
x=Conv2D(50, (3,3), padding= 'valid', strides=(1,1), activation='relu' ,name='conv-2')(x)
x=MaxPool2D(pool_size=(2,2), strides=(2,2), padding = 'valid', name = 'pool-2')(x)
x=Conv2D(30, (3,3), padding= 'valid' ,strides=(1,1), activation='relu' , name='conv-3') (x)
x=MaxPool2D(pool_size=(2,2),strides=(2,2), padding = 'valid', name = 'pool-3')(x)
x=Dropout(0.2,name = 'dropout-1')(x)
x=Flatten(name='flatten')(x)
x=Dense(10, activation='softmax',name='recognition')(x)
model=Model(inp,x)结果:

3.3 模型测试
testFileList = listdir('testDigits')
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList [i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
testVector= []
testVector.append(vectorUnderTest)
testX=np.array(testVector);
textX=testX.reshape((testX.shape[0],
testX.shape[1],
testX.shape[2],
1))
classifierResult = np.argmax(model.predict(testX))#argmax获得最大值索引
print ("DNN得到的辨识结果是: %d,实际值是: %d"% (classifierResult, classNumStr))
if (classifierResult != classNumStr): errorCount += 1.0
print ("\n辨识错误数量为: %d" % errorCount)
print ("\n辨识率为: %f" % ((1-errorCount/float(mTest))*100))结果:辨识错误数量为: 29
辨识率为: 96.934461
