python 爬虫 一键爬取携程旅游团数据
python 爬虫 一键爬取携程旅游团数据
前言
最近我的好朋友在做期末大作业,需要分析疫情前后对旅游行业的影响。于是,就求助我,想让我帮忙趴取一下携程旅游团的评价数据,包括评价时间、评价内容、评分这三条数据。
源码已上传到GitHub,有需要的伙伴自取:源码地址,如果有帮到你,不要忘记给个小⭐⭐
网站分析
第一步 查看首页数据格式
首先我们打开协程网站,随便搜一个地点,这里我以重庆为例:
地址:https://vacations.ctrip.com/list/whole/d-chongqing-158.html?from=do&startcity=2
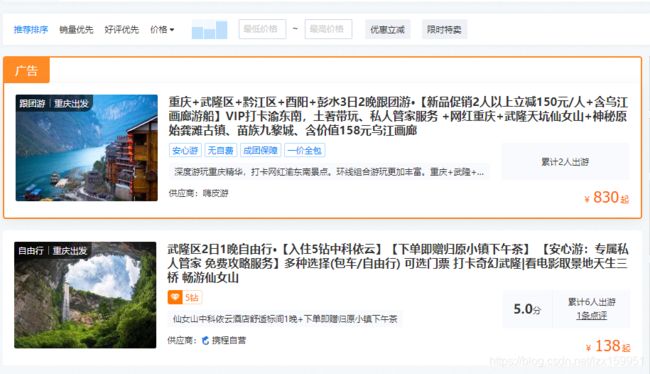
大概就是这么个页面形式,为了减少工作量的同时,获取到更多的数据,我们采用销量优先的筛选模式,对这些参团游进行重新排序。

我们可以看到,排名前几名的都有非常可观的评价数,这里我们就取排名前4的旅游团
我们在当前页面按F12 进入开发者模式,看看当前呈现在我们面前的数据的原貌是什么
这里需要注意一点,进入开发者模式后,我们需要先点击另一个排序模式,再点回销量优先:
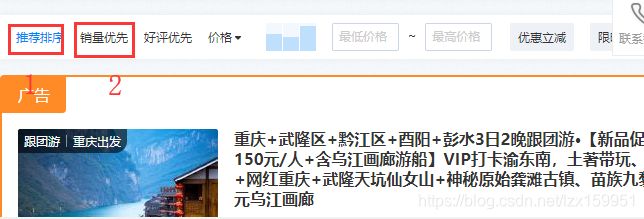
这样做的原因就是单纯的刷新页面,由于有些数据之前已经加载过了,就不会再进行请求了。
对了,在进行第二次点击时,注意点击clear (就在红点旁边),清除一下
这次,我们来看看加载了哪些数据:

这里我们先选择XHR进行筛选,过滤掉图片、js、css等文件。
这么多请求,哪个是我们需要的呢?最好的办法呢,就是一个一个看!
这里我就不给大家演示了,就直接用红色框标出来我们需要的
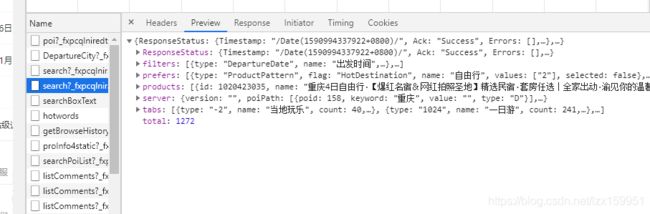
我们将右边的json数据的进行展开,会发现,在products这个里面,就是我们需要的数据:
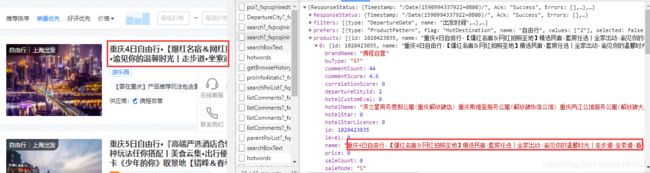
这里我把products种的第一个数据赋值过来大家看看:
{
"id":1020423035,
"name":"重庆4日自由行·【爆红名宿&网红拍照圣地】精选民宿·套房任选丨全家出动·渝见你的温馨时光丨走步道·坐索道·看轻轨·赏夜景·吃火锅·不一样的旅行",
"type":1,
"typeName":"自由行",
"level":0,
"price":0,
"departureCityId":2,
"saleMode":"S",
"brandName":"携程自营",
"saleCount":0,
"commentCount":44,
"commentScore":4.6,
"buType":"GT",
"saleout":false,
"hotelName":"滨之星商务度假公寓(重庆解放碑店) 重庆斯维登服务公寓(解放碑协信公馆) 重庆两江公馆服务公寓(解放碑大唐诺亚店) 重庆渝佳酒店公寓解放碑日月光店 重庆斯维登服务公寓(解放碑大唐诺亚) 重庆大唐诺亚服务公寓 重庆云尚轻奢酒店公寓 重庆解放碑日月光云菲度假公寓 重庆一瓦涧精品民宿酒店 coco北欧小居住宿(重庆解放碑店) 久栖·重庆日月光酒店公寓解放碑店",
"hotelStar":0,
"hotelStarLicence":0,
"hotelCustomEval":0,
"correlationScore":0
}
经过英文提示和数据的对比,我们获取我们需要的信息
id:每个旅行项目的编号
saleMode:销售模式,S 表示self 猜测是自营的意思
至于多少人购买,总和评分这些我们不需要,在这里就不说了
找到我们要请求接口了,我们看看需要提交哪些数据吧:

{"contentType":"json","head":{"cid":"09031160411534832517","ctok":"","cver":"1.0","lang":"01","sid":"8888","syscode":"09","auth":"","extension":[]},"version":"80400","client":{"trace":"none","device":"PC","source":"NVacationSearchV2","variables":[{"key":"SHXVERSION","value":"B"}],"cid":"1590973576257.dfu8z"},"poiType":{"poid":158,"type":"D","keyword":"重庆"},"filtered":{"sort":2,"channel":"Online","tab":"A126","saleCity":2,"startCity":2,"pageSize":30,"pageIndex":1,"items":[]},"returnType":{"type":"all","filters":"ProductNewLine,ProductLine,HotDestination,HotScenicSpot,SaleDepartureStat,TravelDays,DepartureDate,Month,ProductPattern,ProductLevel,ADSuitPersons,ProductDistrict,ProviderBrand,PriceRange,Promotion,OnSale","recommendProduct":true}}
这就是一个json形式的数据,然后我们看一下请求地址:https://vacations.ctrip.com/list/restapi/gateway/13561/search?_fxpcqlniredt=09031160411534832517
我们只需要构造请求数据,然后发送到请求地址就可以获取我们想要的数据啦,接着往下看吧
第二步 查看详细页数据格式
前面我们获取了首页的数据,接下来面临一个问题:我们如何通过主页进入到详情页呢?
通常我们都是先在html数据页面获取每个旅行项目详情页的链接,但是,这个项目并不直接给你提供这样的链接,而是通过js进行自行组装(我猜测的)。先不管了,我们先点击看看链接形式是什么样的

地址链接:https://vacations.ctrip.com/tour/detail/p1020423035s2.html
我们再点击第二个旅游项目的详情页:
链接地址:https://vacations.ctrip.com/tour/detail/p2563522s2.html
我们再拿出来前面我们获取的第一个旅游项目的id编号:1020423035
这下我们能够发现,这两个链接只有中间数字上的不同,而且,我们这中间的数字不是别的,就像该旅行项目的id编号。
我们有了详情页的地址,那么获取详情页的数据岂不是轻而易举?
NO NO NO !!!
事情没那么简单,这里我不带大家验证了,直接告诉大家,用户评价的数据是通过js后续请求加载进来的,直接通过请求htm地址页面,无法获取,除非你使用一些其他高级的手段,比如使用selenium工具包进行真实浏览器访问。扯远了 ,我们接下来还是通过F12控制台寻找数据
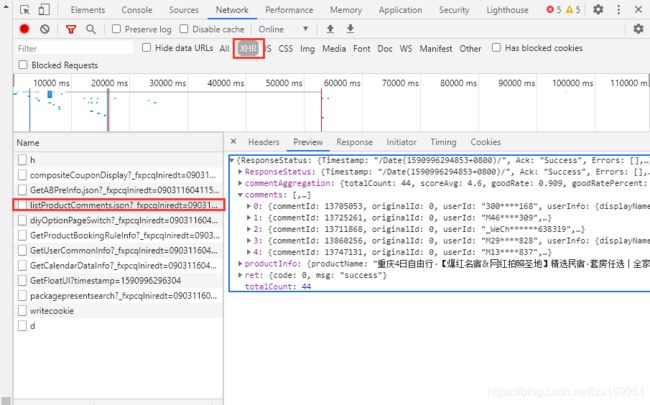
老样子,XHR 筛选数据,通过一个一个查找以及英文提示,我们很快的就能找到我们所需要的数据:
{
"commentId":13705053,
"originalId":0,
"userId":"300****168",
"userInfo":{
"displayName":"300****168",
"avatarUrl":"https://dimg04.c-ctrip.com/images/t1/headphoto/646/318/109/a865fe5f5465407d8befd5dc487a8554.jpg",
"curLevelCode":"10",
"curLevelName":"黄金贵宾"
},
"content":"难忘的一次旅行,走了几个经典路线,喜欢上重庆这座城市!重庆独特的城市文化,令人震撼的自然景观,都给我留下了深刻的印象!感谢导游小潘,幺妹儿热情,民宿老板娘热情周到的服务!",
"commentTime":1579774408793,
"score":5,
"essential":false,
......
这里我们只是comments下的第一条数据,我们需要以下这几个数据:
content:评论内容
commentTime: 评论时间 这里是时间戳 需要转化为正常的时间格式
score:评分
老规矩,接下来看看请求地址和请求数据:
请求地址:https://vacations.ctrip.com/tour/restapi/online/15656/listProductComments.json?_fxpcqlniredt=09031160411534832517
请求数据(同样是一段json数据):
{"ChannelCode":0,"Version":"810000","Locale":"zh-CN","head":{"cid":"09031160411534832517","ctok":"","cver":"1.0","lang":"01","sid":"8888","syscode":"09","auth":"","extension":[]},"productId":1020423035,"paging":{"pageSize":5,"pageNo":1},"sortType":2,"tagTerms":[],"PlatformId":4,"contentType":"json"}
这里我们需要注意几个数据:
pageNo:1 第几页
productId:1020423035 产品编号 也就是旅行项目编号
为什么只需要注意这几个数据呢,是因为不同旅行项目详情页productId 值不一样,查看所有评论
好了 分析就到此结束了
代码实操:
一、获取旅行项目的名字和id
def test1(destination):
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
'Cookie':'_abtest_userid=d778cf10-b380-4da2-977a-b3fd72a9934d; _RF1=120.216.170.214; _RSG=xQKVBUHW1u6FBqc9suTio8; _RDG=28014134c27fb82c9e1cd0973a907c8ce8; _RGUID=6e018117-8b7d-46bb-8cac-778d899b42cf; Session=smartlinkcode=U130026&smartlinklanguage=zh&SmartLinkKeyWord=&SmartLinkQuary=&SmartLinkHost=; Union=AllianceID=4897&SID=130026&OUID=&createtime=1590973579&Expires=1591578378915; MKT_CKID=1590973578972.3e60b.vtue; MKT_CKID_LMT=1590973578973; MKT_Pagesource=PC; _ga=GA1.2.776587014.1590973579; _gid=GA1.2.428582162.1590973579; StartCity_Pkg=PkgStartCity=2; GUID=09031160411534832517; appFloatCnt=1; manualclose=1; _jzqco=%7C%7C%7C%7C%7C1.1607786070.1590973578966.1590975682555.1590976896014.1590975682555.1590976896014.0.0.0.8.8; __zpspc=9.1.1590973578.1590976896.8%232%7Cwww.baidu.com%7C%7C%7C%7C%23; _bfa=1.1590973576257.dfu8z.1.1590973576257.1590973576257.1.31; _bfs=1.31; _bfi=p1%3D104317%26p2%3D104317%26v1%3D31%26v2%3D30; _gat=1',
'origin':'https://vacations.ctrip.com',
'x-req-src':'{"appId":"100020727","from":"vacations.ctrip.com/list/whole/d-chongqing-158.html","version":"8300.103","os":"PC","platform":"Online"}',
'content-type':'application/json'}
data={"contentType":"json","head":{"cid":"09031160411534832517","ctok":"","cver":"1.0","lang":"01","sid":"8888","syscode":"09","auth":"","extension":[]},"version":"80400","client":{"trace":"none","device":"PC","source":"NVacationSearchV2","variables":[{"key":"SHXVERSION","value":"B"}],"cid":"1590973576257.dfu8z"},"poiType":{"poid":158,"type":"D","keyword":destination},"filtered":{"sort":2,"channel":"Online","tab":"A126","saleCity":2,"startCity":2,"pageSize":30,"pageIndex":1,"items":[]},"returnType":{"type":"all","filters":"ProductNewLine,ProductLine,HotDestination,HotScenicSpot,SaleDepartureStat,TravelDays,DepartureDate,Month,ProductPattern,ProductLevel,ADSuitPersons,ProductDistrict,ProviderBrand,PriceRange,Promotion,OnSale","recommendProduct":True}}
url="https://vacations.ctrip.com/list/restapi/gateway/13561/search?fxpcqlniredt=09031160411534832517"
data = json.dumps(data)
re = requests.post(url,headers=headers,data=data)
jsondata = re.json()
listdata=[]
for i in range(4):
listdata.append([jsondata['products'][i]['name'],jsondata['products'][i]['id']])
#print(jsondata['products'][i]['name'],jsondata['products'][i]['id'],)
return listdata
-
这里首先我们构造请求头 其中就包括 Cookie、User-Agent、origin、x-req-src
-
构造一个data数据,这个数据就是之前咱们提到的第一个json数据,这里面有一个destination 参数,代表的是地名,比如重庆、广州、山东这些等。
-
我们通过json 进行将数据转化为json,即时有时不需要这样转化,但是还是建议大家去做,因为有时候回报 无效json 的错误。
-
通过requests.post 进行请求访问,for循环4次获取前四个旅游项目的姓名和id,这里我存到了list列表中。
二、获取详情页数据:
def test2(id):
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
'Cookie':'_abtest_userid=d778cf10-b380-4da2-977a-b3fd72a9934d; _RF1=120.216.170.214; _RSG=xQKVBUHW1u6FBqc9suTio8; _RDG=28014134c27fb82c9e1cd0973a907c8ce8; _RGUID=6e018117-8b7d-46bb-8cac-778d899b42cf; Session=smartlinkcode=U130026&smartlinklanguage=zh&SmartLinkKeyWord=&SmartLinkQuary=&SmartLinkHost=; Union=AllianceID=4897&SID=130026&OUID=&createtime=1590973579&Expires=1591578378915; MKT_CKID=1590973578972.3e60b.vtue; MKT_CKID_LMT=1590973578973; MKT_Pagesource=PC; _ga=GA1.2.776587014.1590973579; _gid=GA1.2.428582162.1590973579; StartCity_Pkg=PkgStartCity=2; GUID=09031160411534832517; appFloatCnt=1; manualclose=1; _jzqco=%7C%7C%7C%7C%7C1.1607786070.1590973578966.1590975682555.1590976896014.1590975682555.1590976896014.0.0.0.8.8; __zpspc=9.1.1590973578.1590976896.8%232%7Cwww.baidu.com%7C%7C%7C%7C%23; _bfa=1.1590973576257.dfu8z.1.1590973576257.1590973576257.1.31; _bfs=1.31; _bfi=p1%3D104317%26p2%3D104317%26v1%3D31%26v2%3D30; _gat=1',
'origin':'https://vacations.ctrip.com',
'x-req-src':'{"appId":"100007656","from":"vacations.ctrip.com/tour/detail/p1020423035s2.html","version":"8300.103","os":"PC","platform":"Online"}',
'content-type':'application/json'}
for i in range(1,10):
try:
pagenum = i
data={"ChannelCode":0,"Version":"810000","Locale":"zh-CN","head":{"cid":"09031160411534832517","ctok":"","cver":"1.0","lang":"01","sid":"8888","syscode":"09","auth":"","extension":[]},"productId":id,"paging":{"pageSize":5,"pageNo":pagenum},"sortType":2,"tagTerms":[],"PlatformId":4,"contentType":"json"}
url="https://vacations.ctrip.com/tour/restapi/online/15656/listProductComments.json?_fxpcqlniredt=09031160411534832517"
data = json.dumps(data)
re = requests.post(url,headers=headers,data=data)
jsondata = re.json()
for i in range(5):
print("\n-----------------------")
print("评论内容:",jsondata['comments'][i]['content'])#获取评论数据
print("评分:",jsondata['comments'][i]['score'])#获取评分
datatime = str(jsondata['comments'][i]['commentTime'])[:-3]
times = time.localtime(int(datatime))
datatime = time.strftime("%Y-%m-%d %H:%M:%S",times)
print("日期:",datatime)#获取日期
print("-----------------------\n")
time.sleep(2)
except:
break
-
还是构造headers 和data数据,这里面data中有两个参数,一个是id 项目编码,另一个pagenum 是当前评价页面。这里我做了一个处理,只取前9也得评价,如果评价不够9页怎么办,没有关系,会直接出发报错,运行break 跳出循环。
-
紧接着for循环5次,是因为一个页面有五条评论数据
-
获取到的时间数据是时间戳,这里时间戳是13位,平常python中处理的时间戳是10位,是不包括毫秒的,这里我们先转化为字符串,截取前10个字符,再转化为整型。
-
通过time.localtime 和 time.strftime 方法将时间戳转化为年-月-日 时:分:秒的格式。
-
为了爬取太过于频繁,我们设置一个2s的休息时间 time.sleep(2)
三、总方法
def mainfun():
traveldestination = ['重庆','广州','郑州','三亚','上海','杭州','北京','成都']#这里是添加旅游地点
for i in range(len(traveldestination)):
listdata = test1(traveldestination[i])
print("地点:",traveldestination[i],end='\n')
for data in listdata:
print(data[0])
test2(data[1])
- 我们可以往列表 traveldestination中添加我们想爬取的地点
- 通过循环不断地获取评价数据
四、可改进地方
- 使用多线程加快爬取速度,并且多线程有同步机制,输出数据时也不会出现混乱
- 考虑地情况不足,比如旅行团有非自营的
五、执行结果
地点: 重庆
重庆4日自由行·【爆红名宿&网红拍照圣地】精选民宿·套房任选丨全家出动·渝见你的温馨时光丨走步道·坐索道·看轻轨·赏夜景·吃火锅·不一样的旅行
-----------------------
评论内容: 难忘的一次旅行,走了几个经典路线,喜欢上重庆这座城市!重庆独特的城市文化,令人震撼的自然景观,都给我留下了深刻的印象!感谢导游小潘,幺妹儿热情,民宿老板娘热情周到的服务!
评分: 5
日期: 2020-01-23 18:13:28
-----------------------
-----------------------
评论内容: 一瓦涧精品民宿
老板非常热情周到!有缘让我们相识,感谢这几天对我们的关照,给我们做早餐发红包。实在不好意思[害羞]。真是倍感亲切,有朋友来就让她们直接去找你哦。期待下次我们再相聚[亲亲][好的]
当地一日游任师傅服务热情讲解到位,引领出行深入重庆了解感受当地民风民俗。很满意谢谢!
评分: 4
日期: 2020-01-27 11:24:14
-----------------------
-----------------------
评论内容: 在携程上搜的自由行套餐,行程安排的很好,导游也不错,最棒的是一瓦涧民宿,老板娘很热情,服务很周到,房间有暖气,老板娘给放了很多水果和坚果,还邀请我们一起吃早饭,介绍好玩的好吃的地方,房间很舒服,环境也很棒,位置出行也很方便,非常赞的一次旅行
评分: 5
日期: 2020-01-24 15:45:09
-----------------------
-----------------------
评论内容: 很好的旅行体验。
评分: 5
日期: 2020-03-17 01:38:15
-----------------------
上述时部分执行数据,有了这些数据,就可以做一些数据分析了
总结
原本以为非常简单的事情,还是花了一上午时间,所以,我们还是多去实际动手做一些东西,尽管有些东西非常简单,但是中间可能也会出现一些动态性的错误。如果有需要完整代码的话,可以在评论中留言。