@Author : Roger TX ([email protected])
@Link : https://github.com/paotong999
Python 提供有丰富的文件 I/O 支持,Python 提供了多种方式来读取文件内容,非常简单、灵活。
使用 pathlib 和 os.path 来操作各种路径,提供全局的 open() 函数来打开文件
在 Python 的 os 模块下也包含了大量进行文件 I/O 的函数,使用这些函数来读取、写入文件也很方便
一、Python pathlib模块
pathlib 模块提供了一组面向对象的类,这些类可代表各种操作系统上的路径,程序可通过这些类操作路径。
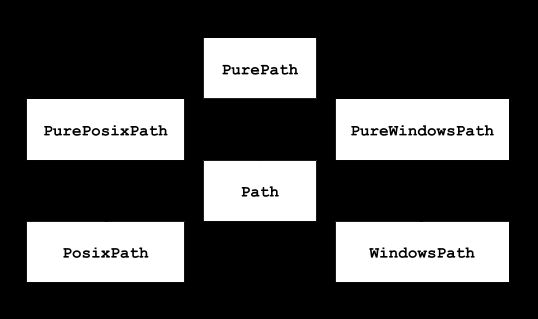
- PurePath 代表并不访问实际文件系统的“纯路径”。简单来说,PurePath 只是负责对路径字符串执行操作,至于该字符串是否对应实际的路径,它并不关心。
- Path 代表访问实际文件系统的“真正路径”。Path 对象可用于判断对应的文件是否存在、是否为文件、是否为目录等。Path 同样有两个子类,即 PosixPath 和 WindowsPath。
PurePath 和 Path 的功能和用法
关于 PurePath 和 Path 不做过多说明,如果需要,可以查看官方文档
PurePath 提供了不少属性和方法,这些属性和方法主要还是用于操作路径字符串。
- PurePath.parts:该属性返回路径字符串中所包含的各部分。
- PurePath.drive:该属性返回路径字符串中的驱动器盘符。
- PurePath.root:该属性返回路径字符串中的根路径。
- PurePath.anchor:该属性返回路径字符串中的盘符和根路径。
- PurePath.parents:该属性返回当前路径的全部父路径。
- PurPath.parent:该属性返回当前路径的上一级路径,相当于 parents[0] 的返回值。
- PurePath.name:该属性返回当前路径中的文件名。
- PurePath.suffixes:该属性返回当前路径中的文件所有后缀名。
- PurePath.suffix:该属性返回当前路径中的文件后缀名。相当于 suffixes 属性返回的列表的最后一个元素。
- PurePath.stem:该属性返回当前路径中的主文件名。
- PurePath.as_posix():将当前路径转换成 UNIX 风格的路径。
- PurePath.as_uri():将当前路径转换成 URI。只有绝对路径才能转换,否则将会引发 ValueError。
- PurePath.is_absolute():判断当前路径是否为绝对路径。
- PurePath.joinpath(*other):将多个路径连接在一起,作用类似于前面介绍的斜杠运算符。
- PurePath.match(pattern):判断当前路径是否匹配指定通配符。
- PurePath.relative_to(*other):获取当前路径中去除基准路径之后的结果。
- PurePath.with_name(name):将当前路径中的文件名替换成新文件名。如果当前路径中没有文件名,则会引发 ValueError。
- PurePath.with_suffix(suffix):将当前路径中的文件后缀名替换成新的后缀名。如果当前路径中没有后缀名,则会添加新的后缀名。
from pathlib import *
pp = PurePath('abc', 'xyz', 'wawa', 'haha') # abc\xyz\wawa\haha
# 转成Unix风格的路径
pp.as_posix() # abc/xyz/wawa/haha
# 判断当前路径是否匹配指定模式
print(PurePath('a/b.py').match('*.py')) # True
print(PurePath('/a/b/c.py').match('b/*.py')) # True
print(PurePath('/a/b/c.py').match('a/*.py')) # False
Path 还包含一个很常用的 iterdir() 方法,该方法可返回 Path 对应目录下的所有子目录和文件
Path 还包含一个 glob() 方法,用于获取 Path 对应目录及其子目录下匹配指定模式的所有文件
from pathlib import *
# 获取当前目录
p = Path('.')
# 遍历当前目录下所有文件和子目录
for x in p.iterdir():
print(x)
# 获取上一级目录
p = Path('../')
# 获取上级目录及其所有子目录下的的py文件
for x in p.glob('**/*.py'):
print(x)
# 获取d:/github/deeptest对应的目录
p = Path('d:/github/deeptest')
# 获取上级目录及其所有子目录下的的py文件
for x in p.glob('**/Path_test1.py'):
print(x)
Path 读写文件
p = Path('a_test.txt')
# 以utf8字符集输出文本内容
result = p.write_text('''有一个美丽的新世界
它在远方等我
那里有天真的孩子
还有姑娘的酒窝''', encoding='utf8')
# 返回输出的字符数
print(result)
# 指定以utf8字符集读取文本内容
content = p.read_text(encoding='utf8')
# 输出读取的文本内容
print(content)
# 读取字节内容
bb = p.read_bytes()
print(bb)
二、os.path模块常见函数
Python内置的os模块也可以直接调用操作系统提供的接口函数
import os
os.name # 操作系统类型
os.uname() # 详细的系统信息,Windows上不可用
os.environ # 环境变量
os.environ.get('PATH') # 获取某个环境变量的值
os.getcwd() # 获取当前目录
os.chdir('../deeptest') # 改变当前目录
os.listdir(path) # 返回 path 对应目录下的所有文件和子目录
os.mkdir(path[, mode]) # 创建一个目录,mode代表权限,比如 0o777
os.makedirs(path[, mode]) # 创建目录以及子目录
os.rmdir(path) # 删掉一个目录
os.rename('test.txt', 'test.py') # 文件重命名
os.remove('test.py') # 删除文件
os.path 模块下提供了一些操作目录的方法,这些函数可以操作系统的目录本身
提供了 exists() 函数判断该目录是否存在
提供了 getctime() 函数来获取该目录的创建时间
提供了 getmtime() 函数来获取该目录的最后一次修改时间
提供了 getatime() 函数来获取该目录的最后一次访问时间
提供了 getsize() 函数来获取指定文件的大小
os.path.abspath('.') # 查看当前目录的绝对路径 '/Users/michael'
os.path.join('/Users/michael', 'testdir') # 目录拼接 '/Users/michael/testdir'
os.path.split('/Users/michael/testdir/file.txt') # 目录拆分 ('/Users/michael/testdir', 'file.txt')
os.path.splitext('/path/to/file.txt') # 获取后缀名 ('/path/to/file', '.txt')
os.path.commonprefix(['/usr/lib', '/usr/local/lib']) # 获取共同前缀 /usr/l
os.path.commonpath(['/usr/lib', '/usr/local/lib']) # 获取共同路径 \usr
os.path.listdir('.') # 获取当前路径下所有文件和目录
os.path.isfile('os.path_test.py') # 判断是否为文件 True
os.path.isdir('os.path_test.py') # 判断是否为目录 False
要列出当前目录下的所有目录,只需要一行代码:
[x for x in os.listdir('.') if os.path.isdir(x)]
['.lein', '.local', '.m2', '.npm', '.ssh', '.Trash', '.vim', 'Applications', 'Desktop', ...]
要列出所有的.py文件,只需一行代码:
[x for x in os.listdir('.') if os.path.isfile(x) and os.path.splitext(x)[1]=='.py']
['apis.py', 'config.py', 'models.py', 'pymonitor.py', 'test_db.py', 'urls.py', 'wsgiapp.py']
三、fnmatch模块:用于文件名的匹配
上面介绍的可以进行简单的模式匹配,但 fnmatch 模块可以支持更复杂的匹配
fnmatch 匹配支持如下通配符:
- *:可匹配任意个任意字符。
- ?:可匹配一个任意字符。
- [字符序列]:可匹配中括号里字符序列中的任意字符。该字符序列也支持中画线表示法。
- [!字符序列]:可匹配不在中括号里字符序列中的任意字符。
在该模块下提供了如下函数:
- fnmatch.fnmatch(filename, pattern):判断指定文件名是否匹配指定 pattern。
from pathlib import *
import fnmatch
# 遍历当前目录下所有文件和子目录
for file in Path('.').iterdir():
# 访问所有以_test.py结尾的文件
if fnmatch.fnmatch(file, '*_test.PY'):
print(file)
- fnmatch.fnmatchcase(filename, pattern):该函数与上一个函数的功能大致相同,只是该函数区分大小写。
- fnmatch.filter(names, pattern):该函数对 names 列表进行过滤,返回 names 列表中匹配 pattern 的文件名组成的子集合。
names = ['a.py', 'b.py', 'c.py', 'd.py']
# 对names列表进行过滤
sub = fnmatch.filter(names, '[ac].py')
print(sub) # ['a.py', 'c.py']
- fnmatch.translate(pattern):该函数用于将一个 UNIX shell 风格的 pattern 转换为正则表达式 pattern。如下代码示范了该函数的功能:
print(fnmatch.translate('?.py')) # (?s:.\.py)\Z
print(fnmatch.translate('[ac].py')) # (?s:[ac]\.py)\Z
print(fnmatch.translate('[a-c].py')) # (?s:[a-c]\.py)\Z
四、open函数详解
Python 提供了一个内置的 open() 函数,传入文件名和标示符,用于打开指定文件。
f = open('/Users/michael/test.txt', 'r', True, encoding='utf8', errors='ignore')
- open()函数还可以传入encoding参数,设定编码
- 遇到有些编码不规范的文件,你可能会遇到UnicodeDecodeError,open()函数还接收一个errors参数,表示如果遇到编码错误后如何处理,
f = open('/Users/michael/gbk.txt', 'r', encoding='utf8', errors='ignore') - 使用 open() 函数时,其第三个参数表示是否使用缓冲,如果是 0(或 False),那么该函数打开的文件就是不带缓冲的;如果其第三个参数是 1(或 True),则该函数打开的文件就是带缓冲的,此时程序执行 I/O 将具有更好的性能,也可以使用
buffering=True
如果文件不存在,open()函数就会抛出一个IOError的错误,并且给出错误码和详细的信息告诉你文件不存在
如果文件打开成功,接下来,调用read()方法可以一次读取文件的全部内容
f.read()
- 调用read()会一次性读取文件的全部内容
- 调用read(size)方法,每次最多读取size个字节的内容
- 调用readline()可以每次读取一行内容
- 调用readlines()一次读取所有内容并按行返回list
最后一步是调用close()方法关闭文件,文件使用完毕后必须关闭
f.close()
由于文件读写时都有可能产生IOError,一旦出错,后面的f.close()就不会调用。为了保证能正确地关闭文件,我们可以使用try ... finally来实现:
try:
f = open('/path/to/file', 'r', encoding='utf8')
print(f.read())
finally:
if f:
f.close()
但是每次都这么写实在太繁琐,所以,Python引入了with语句来自动帮我们调用close()方法:
with open('/path/to/file', 'r') as f:
print(f.read())
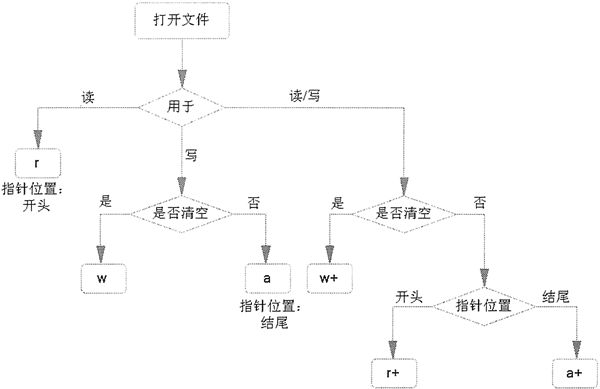
文件打开模式
| 模式 | 意义 |
|---|---|
| r | 只读模式 |
| w | 写模式 |
| a | 追加模式 |
| + | 读写模式,可与其他模式结合使用。比如 r+ 代表读写模式,w+ 也代表读写模式 |
| b | 二进制模式,可与其他模式结合使用。b不能使用 encoding 和 errors |
下面程序使用二进制模式来读取文本文件:
# 指定使用二进制方式读取文件内容
f = open("read_test3.py", 'rb', True)
# 直接读取全部文件,并调用bytes的decode将字节内容恢复成字符串
print(f.read().decode('utf-8'))
f.close()
在调用 open() 函数时,传入了 rb 模式,这表明采用二进制模式读取文件。此时文件对象的 read() 方法返回的是 bytes 对象,程序可调用 bytes 对象的 decode() 方法将它恢复成字符串。