1. 什么是 spring boot?
Spring Boot提供了一种新的编程范式,能在最小的阻力下开发Spring应用程序。有了它, 你可以更加敏捷地开发Spring应用程序,专注于应用程序的功能,不用在Spring的配置上多花功 夫,甚至完全不用配置。实际上,Spring Boot的一项重要工作就是让Spring配置不再成为你成功路上的绊脚石。
2. 为什么要用 spring boot?
开发快。
Spring Boot使用“习惯优于配置”的理念让项目快速运行起来。使用Spring Boot很容易创建一个独立运行、准生产级别的基于Spring框架的项目,使用Spring Boot你可以不用或则只需要很少的Spring配置。
3. spring boot 核心配置文件是什么?
SpringBoot的核心配置文件有application和bootstarp配置文件。
3.1 用途
- application文件主要用于Springboot自动化配置文件。
- bootstarp文件主要有以下几种用途:
- 使用Spring Cloud Config注册中心时,需要在bootStarp配置文件中添加链接到配置中心的配置属性来加载外部配置中心的配置信息;
- 一些固定的不能被覆盖的属性;
- 一些加密/解密的场景;
3.2 都有什么格式?
- .properties 和 .yml
- .yml采取的是缩进的格式 不支持@PeopertySource注解导入配置,但是可以通过@Value("${}")导入配置
4. spring boot 配置文件有哪几种类型?它们有什么区别?
在 Spring Boot 中有以下两种配置文件
- bootstrap (.yml 或者 .properties)
boostrap 由父 ApplicationContext 加载,比 applicaton 优先加载
boostrap 里面的属性不能被覆盖 - application (.yml 或者 .properties)
应用场景:
application
主要用于 Spring Boot 项目的自动化配置(stg,dev,test)-
bootstrap
- 使用 Spring Cloud Config 配置中心时,这时需要在 bootstrap 配置文件中添加连接到配置中心的配置属性来加载外部配置中心的配置信息;
- 一些固定的不能被覆盖的属性
- 一些加密/解密的场景
5. spring boot 有哪些方式可以实现热部署?
热部署:
大家都知道在项目开发过程中,常常会改动页面数据或者修改数据结构,为了显示改动效果,往往需要重启应用查看改变效果,其实就是重新编译生成了新的 Class 文件,这个文件里记录着和代码等对应的各种信息,然后 Class 文件将被虚拟机的 ClassLoader 加载。
而热部署正是利用了这个特点,它监听到如果有 Class 文件改动了,就会创建一个新的 ClaassLoader 进行加载该文件,经过一系列的过程,最终将结果呈现在我们眼前
Spring boot通过使用 Spring Loaded和使用spring-boot-devtools进行热部署。
6. 什么是 spring cloud?
Spring Cloud是一个微服务框架,相比Dubbo等RPC框架, Spring Cloud提供的全套的分布式系统解决方案。
Spring Cloud对微服务基础框架Netflix的多个开源组件进行了封装,同时又实现了和云端平台以及和Spring Boot开发框架的集成。
Spring Cloud为微服务架构开发涉及的配置管理,服务治理,熔断机制,智能路由,微代理,控制总线,一次性token,全局一致性锁,leader选举,分布式session,集群状态管理等操作提供了一种简单的开发方式。
Spring Cloud 为开发者提供了快速构建分布式系统的工具,开发者可以快速的启动服务或构建应用、同时能够快速和云平台资源进行对接。
7. spring cloud 的核心组件有哪些?
1. Spring Cloud Eureka
我们使用微服务,微服务的本质还是各种API接口的调用,那么我们怎么产生这些接口、产生了这些接口之后如何进行调用那?如何进行管理哪?
答案就是Spring Cloud Eureka,我们可以将自己定义的API 接口注册到Spring Cloud Eureka上,Eureka负责服务的注册于发现,如果学习过Zookeeper的话,就可以很好的理解,Eureka的角色和 Zookeeper的角色差不多,都是服务的注册和发现,构成Eureka体系的包括:服务注册中心、服务提供者、服务消费者。
2. Spring Cloud Ribbon
在上Spring Cloud Eureka描述了服务如何进行注册,注册到哪里,服务消费者如何获取服务生产者的服务信息,但是Eureka只是维护了服务生产者、注册中心、服务消费者三者之间的关系,真正的服务消费者调用服务生产者提供的数据是通过Spring Cloud Ribbon来实现的。
在(1)中提到了服务消费者是将服务从注册中心获取服务生产者的服务列表并维护在本地的,这种客户端发现模式的方式是服务消费者选择合适的节点进行访问服务生产者提供的数据,这种选择合适节点的过程就是Spring Cloud Ribbon完成的。
Spring Cloud Ribbon客户端负载均衡器由此而来。
3. Spring Cloud Feign
上述(1)、(2)中我们已经使用最简单的方式实现了服务的注册发现和服务的调用操作,如果具体的使用Ribbon调用服务的话,你就可以感受到使用Ribbon的方式还是有一些复杂,因此Spring Cloud Feign应运而生。
Spring Cloud Feign 是一个声明web服务客户端,这使得编写Web服务客户端更容易,使用Feign 创建一个接口并对它进行注解,它具有可插拔的注解支持包括Feign注解与JAX-RS注解,Feign还支持可插拔的编码器与解码器,Spring Cloud 增加了对 Spring MVC的注解,Spring Web 默认使用了HttpMessageConverters, Spring Cloud 集成 Ribbon 和 Eureka 提供的负载均衡的HTTP客户端 Feign。
简单的可以理解为:Spring Cloud Feign 的出现使得Eureka和Ribbon的使用更为简单。
4. Spring Cloud Hystrix
我们在(1)、(2)、(3)中知道了使用Eureka进行服务的注册和发现,使用Ribbon实现服务的负载均衡调用,还知道了使用Feign可以简化我们的编码。但是,这些还不足以实现一个高可用的微服务架构。
例如:当有一个服务出现了故障,而服务的调用方不知道服务出现故障,若此时调用放的请求不断的增加,最后就会等待出现故障的依赖方 相应形成任务的积压,最终导致自身服务的瘫痪。
Spring Cloud Hystrix正是为了解决这种情况的,防止对某一故障服务持续进行访问。Hystrix的含义是:断路器,断路器本身是一种开关装置,用于我们家庭的电路保护,防止电流的过载,当线路中有电器发生短路的时候,断路器能够及时切换故障的电器,防止发生过载、发热甚至起火等严重后果
5. Spring Cloud Config
对于微服务还不是很多的时候,各种服务的配置管理起来还相对简单,但是当成百上千的微服务节点起来的时候,服务配置的管理变得会复杂起来。
分布式系统中,由于服务数量巨多,为了方便服务配置文件统一管理,实时更新,所以需要分布式配置中心组件。在Spring Cloud中,有分布式配置中心组件Spring Cloud Config ,它支持配置服务放在配置服务的内存中(即本地),也支持放在远程Git仓库中。在Cpring Cloud Config 组件中,分两个角色,一是Config Server,二是Config Client。
Config Server用于配置属性的存储,存储的位置可以为Git仓库、SVN仓库、本地文件等,Config Client用于服务属性的读取。
6. Spring Cloud Zuul
我们使用Spring Cloud Netflix中的Eureka实现了服务注册中心以及服务注册与发现;而服务间通过Ribbon或Feign实现服务的消费以及均衡负载;通过Spring Cloud Config实现了应用多环境的外部化配置以及版本管理。为了使得服务集群更为健壮,使用Hystrix的融断机制来避免在微服务架构中个别服务出现异常时引起的故障蔓延。
先来说说这样架构需要做的一些事儿以及存在的不足:
1、首先,破坏了服务无状态特点。为了保证对外服务的安全性,我们需要实现对服务访问的权限控制,而开放服务的权限控制机制将会贯穿并污染整个开放服务的业务逻辑,这会带来的最直接问题是,破坏了服务集群中REST API无状态的特点。从具体开发和测试的角度来说,在工作中除了要考虑实际的业务逻辑之外,还需要额外可续对接口访问的控制处理。
2、其次,无法直接复用既有接口。当我们需要对一个即有的集群内访问接口,实现外部服务访问时,我们不得不通过在原有接口上增加校验逻辑,或增加一个代理调用来实现权限控制,无法直接复用原有的接口。
面对类似上面的问题,我们要如何解决呢?下面进入本文的正题:服务网关!
为了解决上面这些问题,我们需要将权限控制这样的东西从我们的服务单元中抽离出去,而最适合这些逻辑的地方就是处于对外访问最前端的地方,我们需要一个更强大一些的均衡负载器,它就是本文将来介绍的:服务网关。
服务网关是微服务架构中一个不可或缺的部分。通过服务网关统一向外系统提供REST API的过程中,除了具备服务路由、均衡负载功能之外,它还具备了权限控制等功能。Spring Cloud Netflix中的Zuul就担任了这样的一个角色,为微服务架构提供了前门保护的作用,同时将权限控制这些较重的非业务逻辑内容迁移到服务路由层面,使得服务集群主体能够具备更高的可复用性和可测试性

7. Spring Cloud Bus
在(5)Spring Cloud Config中,我们知道的配置文件可以通过Config Server存储到Git等地方,通过Config Client进行读取,但是我们的配置文件不可能是一直不变的,当我们的配置文件放生变化的时候如何进行更新哪?
一种最简单的方式重新一下Config Client进行重新获取,但Spring Cloud绝对不会让你这样做的,Spring Cloud Bus正是提供一种操作使得我们在不关闭服务的情况下更新我们的配置。
Spring Cloud Bus官方意义:消息总线。
当然动态更新服务配置只是消息总线的一个用处,还有很多其他用处
8. spring cloud 断路器的作用是什么?
在微服务架构中,存在着那么多的服务单元,若一个单元出现故障,就会因依赖关系形成故障蔓延,最终导致整个系统的瘫痪,这样的架构相较传统架构就更加的不稳定。为了解决这样的问题,因此产生了断路器模式
断路器模式源于Martin Fowler的Circuit Breaker一文。“断路器”本身是一种开关装置,用于在电路上保护线路过载,当线路中有电器发生短路时,“断路器”能够及时的切断故障电路,防止发生过载、发热、甚至起火等严重后果。
在分布式架构中,断路器模式的作用也是类似的,当某个服务单元发生故障(类似用电器发生短路)之后,通过断路器的故障监控(类似熔断保险丝),向调用方返回一个错误响应,而不是长时间的等待。这样就不会使得线程因调用故障服务被长时间占用不释放,避免了故障在分布式系统中的蔓延。
在Spring Cloud中使用了Hystrix 来实现断路器的功能,Hystrix在运行过程中会向每个commandKey对应的熔断器报告成功、失败、超时和拒绝的状态,熔断器(Circuit Breaker)维护并统计这些数据,并根据这些统计信息来决策熔断开关是否打开。如果打开,熔断后续请求,快速返回。隔一段时间(默认是5s)之后熔断器尝试半开,放入一部分流量请求进来,相当于对依赖服务进行一次健康检查,如果请求成功,熔断器关闭
9. springcloud 和dubbo区别
springcloud为啥默认使用restful 方式,而不是RPC方式
使用Dubbo的RPC来实现服务间调用的一些痛点:
服务提供方与调用方接口依赖方式太强:我们为每个微服务定义了各自的service抽象接口,并通过持续集成发布到私有仓库中,调用方应用对微服务提供的抽象接口存在强依赖关系,因此不论开发、测试、集成环境都需要严格的管理版本依赖,才不会出现服务方与调用方的不一致导致应用无法编译成功等一系列问题,以及这也会直接影响本地开发的环境要求,往往一个依赖很多服务的上层应用,每天都要更新很多代码并install之后才能进行后续的开发。若没有严格的版本管理制度或开发一些自动化工具,这样的依赖关系会成为开发团队的一大噩梦。而REST接口相比RPC更为轻量化,服务提供方和调用方的依赖只是依靠一纸契约,不存在代码级别的强依赖,当然REST接口也有痛点,因为接口定义过轻,很容易导致定义文档与实际实现不一致导致服务集成时的问题,但是该问题很好解决,只需要通过每个服务整合swagger,让每个服务的代码与文档一体化,就能解决。所以在分布式环境下,REST方式的服务依赖要比RPC方式的依赖更为灵活。
服务对平台敏感,难以简单复用:通常我们在提供对外服务时,都会以REST的方式提供出去,这样可以实现跨平台的特点,任何一个语言的调用方都可以根据接口定义来实现。那么在Dubbo中我们要提供REST接口时,不得不实现一层代理,用来将RPC接口转换成REST接口进行对外发布。若我们每个服务本身就以REST接口方式存在,当要对外提供服务时,只要在API网关中配置映射关系和权限控制就可实现服务的复用了。
相信这些痛点也是为什么当当网在dubbox(基于Dubbo的开源扩展)中增加了对REST支持的原因之一。
当然,springcloud 也支持使用RPC,比如gRPC(谷歌开源),https://github.com/yidongnan/grpc-spring-boot-starter/blob/master/README-zh.md;
使用gRpc最大的好处,是其性能非常高(通信采用Netty),会比采用rustful性能高一倍(因为),通过proto文件定义的接口也是非常清晰而又灵活
10. springcloud中,从前端发起一个请求后需要经过哪些组件
这个问题,和springcloud有哪些组件,作用是啥差不多
- Eureka:各个服务启动时,Eureka Client都会将服务注册到Eureka Server,并且Eureka Client还可以反过来从Eureka Server拉取注册表,从而知道其他服务在哪里
- Ribbon:服务间发起请求的时候,基于Ribbon做负载均衡,从一个服务的多台机器中选择一台
- Feign:基于Feign的动态代理机制,根据注解和选择的机器,拼接请求URL地址,发起请求
- Hystrix:发起请求是通过Hystrix的线程池来走的,不同的服务走不同的线程池,实现了不同服务调用的隔离,避免了服务雪崩的问题
- Zuul:如果前端、移动端要调用后端系统,统一从Zuul网关进入,由Zuul网关转发请求给对应的服务
config 服务配置中心
zipkin 服务调用链监控中心
turbine 服务断路器监控


前提条件:服务注册和服务发现
1、微服务A启动时,Eureka client把服务注册到eureka server上;
2、微服务B通过Eurek client到eureka server把与其相关的服务地址表拉取下来
过程:假如是从前端先调用服务B,然后服务B调用服务A
1、zuul,网关,如果前端、移动端要调用后端系统,统一从Zuul网关进入,由Zuul网关转发请求给对应的服务B(经过网关后,可以再经过一个nginx做路由),在zuul中可以配置请求url与微服务的对应关系(通常是这个微服务的名称),然后根据名称从本地注册表找到这个服务所在的地址
2、ribbon,负载均衡,在服务B调用服务A时(服务A部署了多个节点、多个ip),先通过ribbon获取到本次要调用服务A的ip地址
3、feign,动态构建http请求,在通过ribbon获取到服务A的IP地址后,通过feign够建http请求,包括 ip、端口、请求参数、请求方法
4、Hystrix,熔断、隔离、降级,在feign构建好http请求后, 通过Hystrix线程池调用服务A中的接口方法。在hystrix中,可以配置服务熔断规则,以及熔断后的处理方法(也就是所谓降级,通常会做一下日志记录)。
通过hystrix线程池可以隔离不同服务调用;
通过配置熔断规则可以保证在服务不可用或者不稳定时,快速返回结果,而不是每次都等待超时;
通过设置服务熔断之后的处理方法,来进行服务降级;
11. Spring cloud 项目中遇到的问题
https://blog.csdn.net/zhangjq520/article/details/89448901
https://www.cnblogs.com/dgcjiayou/articles/9591253.html
问题一:用户充值记录有时候莫名其妙存在充值后的重复数据记录。
原因:Ribbon重试
负载均衡Ribbon发现远程请求实例不可到达之后,去重试其他实例的过程。那么当有些服务在执行过程中由于各种原因导致超时,feign client的重试就会导致接口重复执行;所有只有查询可以重试,但是其他的可以能带来幂等性问题的接口是要关闭重试的
问题二:Eureka注册服务慢
原因:心跳为30S
解决方式:修改心跳时间(开发环境可以使用,生产环境推荐使用默认值)
服务注册涉及到周期性心跳,默认30秒一次(通过客户端配置的serviceUrl)。只有当实例、服务器端和客户端的本地缓存中的元数据都相同时,服务才能被其他客户端发现(所以可能需要3次心跳)
问题三:已停止的微服务节点注销慢或者不注销
在开发测试环境下,常常希望Eureka server能迅速有效地注销已停止的微服务实例,然而由于Eureka Server清理无效节点周期长(默认90s),以及自我保护模式等,可能会遇到已停止的微服务节点注销慢或者甚至不注销的问题
解决办法:
- Eureka Server端:关闭自我保护,并且按需配置清理无效节点的时间间隔(默认90s)
- Eureka Client端:开启健康检查,并按需配置续约更新时间和到期时间(默认都是30s)
注意:这些配置仅建议在开发或者测试使用,生产环境还是坚持使用默认值。
问题四:Ribbon/Feign整合Hystrix后首次请求失败
在某些场景下,Feign或Ribbon整合Hystrix后,会出现首次调用失败的问题
原因:Hystrix默认的超时时间是一秒,如果在1秒内得不到响应,就会进入fallback逻辑。由于Spring的懒加载机制,首次请求往往会比较慢,因此在某些机器(特别是配置低的机器)上,首次请求需要的时间可能就会大于1秒。
解决办法:(一)延长Hystrix的超时时间 (二):禁用Hystrix的超时
12. Eureka原理,底层实现
12.1 架构:
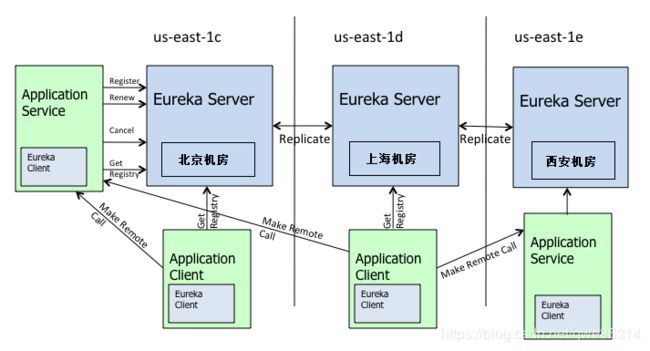 image.png
image.png
从图中可以看出 Eureka Server 集群相互之间通过 Replicate 来同步数据,相互之间不区分主节点和从节点,所有的节点都是平等的。在这种架构中,节点通过彼此互相注册来提高可用性,每个节点需要添加一个或多个有效的 serviceUrl 指向其他节点。
如果某台 Eureka Server 宕机,Eureka Client 的请求会自动切换到新的 Eureka Server 节点。当宕机的服务器重新恢复后,Eureka 会再次将其纳入到服务器集群管理之中。当节点开始接受客户端请求时,所有的操作都会进行节点间复制,将请求复制到其所知的所有Eureka Server节点中。
另外 Eureka Server 的同步遵循着一个非常简单的原则:只要有一条边将节点连接,就可以进行信息传播与同步。所以,如果存在多个节点,只需要将节点之间两两连接起来形成通路,那么其它注册中心都可以共享信息。每个 Eureka Server 同时也是 Eureka Client,多个 Eureka Server 之间通过 P2P 的方式完成服务注册表的同步。
Eureka Server 集群之间的状态是采用异步方式同步的,所以不保证节点间的状态一定是一致的,不过基本能保证最终状态是一致的。
12.2 工作流程:
- 1、Eureka Server 启动成功,等待服务端注册。在启动过程中如果配置了集群,集群之间定时通过 Replicate 同步注册表,每个 Eureka Server 都存在独立完整的服务注册表信息
- 2、Eureka Client 启动时根据配置的 Eureka Server 地址去注册中心注册服务
- 3、Eureka Client 会每 30s 向 Eureka Server 发送一次心跳请求,证明客户端服务正常
- 4、当 Eureka Server 90s 内没有收到 Eureka Client 的心跳,注册中心则认为该节点失效,会注销该实例
- 5、单位时间内 Eureka Server 统计到有大量的 Eureka Client 没有上送心跳,则认为可能为网络异常,进入自我保护机制,不再剔除没有上送心跳的客户端
- 6、当 Eureka Client 心跳请求恢复正常之后,Eureka Server 自动退出自我保护模式
- 7、Eureka Client 定时全量或者增量从注册中心获取服务注册表,并且将获取到的信息缓存到本地
- 8、服务调用时,Eureka Client 会先从本地缓存找寻调取的服务。如果获取不到,先从注册中心刷新注册表,再同步到本地缓存
- 9、Eureka Client 获取到目标服务器信息,发起服务调用
- 10、Eureka Client 程序关闭时向 Eureka Server 发送取消请求,Eureka Server 将实例从注册表中删除
12.3 Eureka 与 Zookeeper区别
Eureka Server 各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而 Eureka Client 在向某个 Eureka 注册时,如果发现连接失败,则会自动切换至其它节点。只要有一台 Eureka Server 还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性)。
cureka是AP,zookeeper是CP;
12.4 Eureka 实现最终一致性——消息广播
-
- Eureka Server 管理了全部的服务器列表(PeerEurekaNodes)。
-
- 当 Eureka Server 收到客户端的注册、下线、心跳请求时,通过 PeerEurekaNode 向其余的服务器进行消息广播,如果广播失败则重试,直到任务过期后取消任务,此时这两台服务器之间数据会出现短暂的不一致。
注意: 虽然消息广播失败,但只要收到客户端的心跳,仍会向所有的服务器(包括失联的服务器)广播心跳任务。
-
- 如果网络恢复正常,收到了其它服务器广播的心跳任务,此时可能有三种情况:
一是脑裂很快恢复,一切正常;
二是该实例已经自动过期,则重新进行注册;
三是数据冲突,出现不一致的情况,则需要发起同步请求,其实也就是重新注册一次,同时踢除老的实例。
总之,通过集群之间的消息广播可以实现数据的最终一致性。
- 如果网络恢复正常,收到了其它服务器广播的心跳任务,此时可能有三种情况:
12.5 自我保护机制
默认情况下,如果 Eureka Server 在一定的 90s 内没有接收到某个微服务实例的心跳,会注销该实例。但是在微服务架构下服务之间通常都是跨进程调用,网络通信往往会面临着各种问题,比如微服务状态正常,网络分区故障,导致此实例被注销。
固定时间内大量实例被注销,可能会严重威胁整个微服务架构的可用性。为了解决这个问题,Eureka 开发了自我保护机制,那么什么是自我保护机制呢?
Eureka Server 在运行期间会去统计心跳失败比例在 15 分钟之内是否低于 85%,如果低于 85%,Eureka Server 即会进入自我保护机制。Eureka Server 触发自我保护机制后,页面会出现提示。
Eureka Server 进入自我保护机制,会出现以下几种情况:
(1 Eureka 不再从注册列表中移除因为长时间没收到心跳而应该过期的服务
(2 Eureka 仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上(即保证当前节点依然可用)
(3 当网络稳定时,当前实例新的注册信息会被同步到其它节点中
Eureka 自我保护机制是为了防止误杀服务而提供的一个机制。当个别客户端出现心跳失联时,则认为是客户端的问题,剔除掉客户端;当 Eureka 捕获到大量的心跳失败时,则认为可能是网络问题,进入自我保护机制;当客户端心跳恢复时,Eureka 会自动退出自我保护机制。
如果在保护期内刚好这个服务提供者非正常下线了,此时服务消费者就会拿到一个无效的服务实例,即会调用失败。对于这个问题需要服务消费者端要有一些容错机制,如重试,断路器等。
通过在 Eureka Server 配置参数,开启或者关闭保护机制,生产环境建议打开。
13. Hystrix原理,底层实现
13.1 Hystrix设计目标
- 对来自依赖的延迟和故障进行防护和控制——这些依赖通常都是通过网络访问的
- 阻止故障的连锁反应
- 快速失败并迅速恢复
- 回退并优雅降级
- 提供近实时的监控与告警
13.2 Hystrix如何实现这些设计目标
- 使用命令模式将所有对外部服务(或依赖关系)的调用包装在HystrixCommand或HystrixObservableCommand对象中,并将该对象放在单独的线程中执行;
- 每个依赖都维护着一个线程池(或信号量),线程池被耗尽则拒绝请求(而不是让请求排队);
- 记录请求成功,失败,超时和线程拒绝。
- 服务错误百分比超过了阈值,熔断器开关自动打开,一段时间内停止对该服务的所有请求。
- 请求失败,被拒绝,超时或熔断时执行降级逻辑。
- 近实时地监控指标和配置的修改。
13.3 Hystrix处理流程
 image.png
image.png
Hystrix整个工作流如下:
-
- 构建Hystrix的Command对象, 调用执行方法.
-
- Hystrix检查当前服务的熔断器开关是否开启, 若开启, 则执行降级服务getFallback方法.
-
- 若熔断器开关关闭, 则Hystrix检查当前服务的线程池是否能接收新的请求, 若超过线程池已满, 则执行降级服务getFallback方法.
-
- 若线程池接受请求, 则Hystrix开始执行服务调用具体逻辑run方法.
-
- 若服务执行失败, 则执行降级服务getFallback方法, 并将执行结果上报HystrixCommandMetrics(HystrixCircuitBreaker断路器中参数)更新服务健康状况.
-
- 若服务执行超时, 则执行降级服务getFallback方法, 并将执行结果上报HystrixCommandMetrics(HystrixCircuitBreaker断路器中参数)更新服务健康状况.
-
- 若服务执行成功, 返回正常结果.
-
- 若服务降级方法getFallback执行成功, 则返回降级结果.
-
- 若服务降级方法getFallback执行失败, 则抛出异常.
14. 分布式配置——Spring Cloud Config原理
作为一个开发而言,知道每个项目都有其需要维护的配置文件,如果项目量小而言,以人力尚可以接受。项目量一但增多,传统的维护方式就变的困难,所以需要一个统一的配置中心来维护所有服务的配置文件。再言,传统的项目配置文件配置数据发生改变,需要重启服务使其生效,spring cloud config 可以不需要进行重启对应的服务。
Spring Cloud Config用来为分布式系统中的基础设施和微服务应用提供集中化的外部配置支持。
服务端:分布式配置中心,独立的微服务应用,用来连接配置仓库(GIT)并为客户端提供获取配置信息、加密/解密等访问接口。、
客户端:微服务架构中各个微服务应用和基础设施,通过指定配置中心管理应用资源与业务相关的配置内容,启动时从配置中心获取和加载配置信息
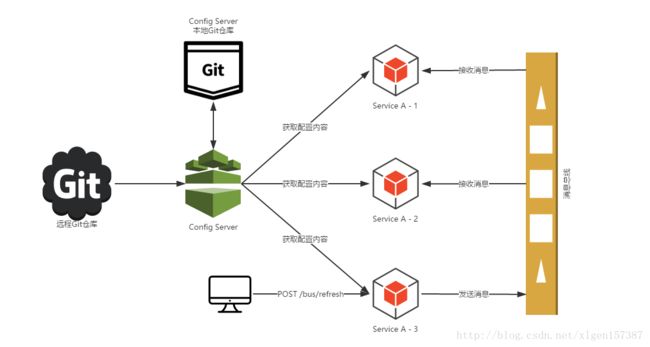
14.1 架构

架构模块介绍
远程GIT仓库:用来存储配置文件的地方;
Config Server:分布式配置中心,微服务中指定了连接仓库的位置以及账号密码等信息;
本地GIT仓库:在Config Server文件系统中,客户单每次请求获取配置信息时,Config Server从GIT仓库获取最新配置到本地,然后在本地GIT仓库读取并返回。当远程仓库无法获取时,直接将本地仓库内容返回;
ServerA/B:具体的微服务应用,他们指定了Config Server地址,从而实现外部化获取应用自己想要的配置信息。应用启动时会向Config Server发起请求获取配置信息进行加载;
消息中心:上述架构图是基于消息总线spring cloud bus的方式,依赖的外部的MQ组件,目前支持kafka、rabbitmq。通过Config Server配置中心提供的/bus/refresh endpoint作为生产者发送消息,客户端接受到消息通过http接口形式从Config Server拉取配置;
服务注册中心:可以将Config Server注册到服务注册中心上比如Eureka,然后客户端通过服务注册中心发现Config Server服务列表,选择其中一台Config Server来完成健康检查以及获取远端配置信息;
14.2 Spring Cloud Config客户端加载流程
客户端应用从配置管理中获取配置执行流程:
1、应用启动时,根据bootstrap.yml中配置的应用名{application}、环境名{profile}、分支名{label},向Config Server请求获取配置信息;
2、Config Server根据自己维护的GIT仓库信息与客户端传过来的配置定位去查找配置信息;
3、通过git clone命令将找到的配置下载到Config Server的文件系统(本地GIT仓库);
4、Config Server创建Spring的ApplicationContext实例,并从GIT本地仓库中加载配置文件,最后读取这些配置内容返回给客户端应用;
5、客户端应用在获取外部配置内容后加载到客户端的ApplicationContext实例,该配置内容优先级高于客户端Jar包内部的配置内容,所以在Jar包中重复的内容将不再被加载;
15. Zuul原理
zuul 是netflix开源的一个API Gateway 服务器, 本质上是一个web servlet应用。
Zuul 在云平台上提供动态路由,监控,弹性,安全等边缘服务的框架。Zuul 相当于是设备和 Netflix 流应用的 Web 网站后端所有请求的前门。

一个请求过来后,经过DispatchServlet,zuulHadlerMapping,ZuulController(调用ZuulServlet,在ZuulServlet中加载过滤器),
在pre类型Filters中的PriDecorationFilter中把源请求url转换拼接(路由)为目标url,然后经过Routing类型的Filters请求目标url。
zuul配置文件中设置path和serverId后,zuul启动后是加载到map中的。
15.1 过滤器
zuul的核心是一系列的filters, 其作用可以类比Servlet框架的Filter,或者AOP。
zuul把Request route到 用户处理逻辑 的过程中,这些filter参与一些过滤处理,比如Authentication,Load Shedding等。

Zuul的过滤器是由Groovy写成,这些过滤器文件被放在Zuul Server上的特定目录下面,Zuul会定期轮询这些目录,修改过的过滤器会动态的加载到Zuul Server中以便过滤请求使用。
Zuul大部分功能都是通过过滤器来实现的。Zuul中定义了四种标准过滤器类型,这些过滤器类型对应于请求的典型生命周期。
PRE:这种过滤器在请求被路由之前调用。我们可利用这种过滤器实现身份验证、在集群中选择请求的微服务、记录调试信息等。
ROUTING:这种过滤器将请求路由到微服务。这种过滤器用于构建发送给微服务的请求,并使用Apache HttpClient或Netfilx Ribbon请求微服务。
POST:这种过滤器在路由到微服务以后执行。这种过滤器可用来为响应添加标准的HTTP Header、收集统计信息和指标、将响应从微服务发送给客户端等。
ERROR:在其他阶段发生错误时执行该过滤器。
16. Ribbon 架构,是怎么实现负载均衡的
Eureka与Ribbon整合工作原理
16.1 LoadBalancer--负载均衡器的核心
LoadBalancer 的职能主要有三个:
- 维护Sever实例列表的数量(新增、更新、删除等)
- 维护Server实例列表的状态(状态更新)
- 当请求Server实例时,通过负载均衡规则IRule返回最合适的Server实例