Python基于深度学习的手写数字识别
Python基于深度学习的手写数字识别
-
- 1.代码的功能和运行方法
- 2. 网络设计
- 3.训练方法
- 4.实验结果分析
- 5.结论
1.代码的功能和运行方法
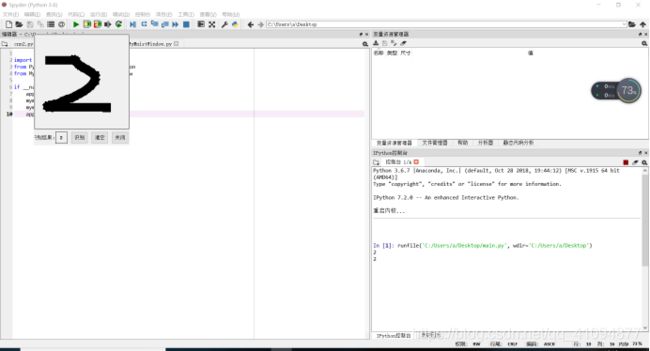
代码可以实现任意数字0-9的识别,只需要将图片载入网络,或者用鼠标绘画,都可以预测其数字。
1.首先下载压缩包所有文件,安装pytorch,pytorch的安装教程可以在pytorch官网找到(https://pytorch.org/)。
2.然后打开编辑器(spyder或者visual studio code或者直接打开cmd进入python模式)
3.载入四个代码文件:cnn2.py网络结构;mnist.py整个训练和评估网络;main.py小应用主程序;MyMnistWindow.py程序框架,内部程序。
4.mnist.py中,两处root改为下载的mnist文件夹所在位置
5.MyMnistWindow.py中,第111行torch.load改为下载的mnist文件夹下minst_cnn_model.pth文件所在位置
6.通过编译器运行mnist.py文件,可以通过mnist训练集训练整个网络
7.通过编译器运行main.py文件,可以实现简单人机交互,手写数字,点击“识别”进行识别。
8.手写数字时尽量写在正中间。
2. 网络设计
2.1 CNN(特征提取网络+分类网络)
随着深度学习的迅猛发展,其应用也越来越广泛,特别是在视觉识别、语音识别和自然语言处理等很多领域都表现出色。卷积神经网络(Convolutional Neural Network,CNN)作为深度学习中应用最广泛的网络模型之一,也得到了越来越多的关注和研究。事实上,CNN作为一项经典的机器学习算法,早在20世纪80年代就已被提出并展开一定的研究。但是,在当时硬件运算能力有限、缺乏有效训练数据等因素的影响下,人们难以训练不产生过拟合情形下的高性能深度卷积神经网络模型。所以,当时CNN的一个经典应用场景就是用于识别银行支票上的手写数字,并且已实际应用。伴随着计算机硬件和大数据技术的不断进步,人们也尝试开发不同的方法来解决深度CNN训练中所遇到的困难,特别是Kizhesky 等专家提出了一种经典的CNN架构,论证了深度结构在特征提取问题上的潜力,并在图像识别任务上取得了重大突破,热起了深度结构研究的浪潮。而卷积神经网络作为一种已经存在的、有一定应用案例的深度结构,也重新回到人们的视野中,得以进一步研究和应用。
而本次实验就是基于CNN实现的。
2.1.1基本架构
卷积神经网络基本架构包括特征抽取器和分类器。特征抽取器通常由若干个卷积层和池化层叠加构成,卷积和池化过程不断将特征图缩小,同时会导致特征图数量的增多。特征抽取器后面一般连接分类器,通常由一个多层感知机构成。特别地,在最后一个特征抽取器后面,将所有的特征图展开并排列成一个向量得到特征向量,并作为后层分类器的输入。本次实验卷积层采用的是四层卷积,两层最大池化,卷积之后用批标准化加快收敛速度,用ReLU激活函数增加非线性,最后用全连接层输出分类得分。
2.1.2卷积层
卷积运算的基本操作是将卷积核与图像的对应区域进行卷积得到一个值,通过在图像上不断移动卷积核和来计算卷积值,进而完成对整幅图像的卷积运算。在卷积神经网络中,卷积层不仅涉及一般的图像卷积,还涉及深度和步长的概念。深度对应于同一个区域的神经元个数,即有几个卷积核对同一块区域进行卷积运算;步长对应于卷积核移动多少个像素,即前后距离的远近程度。
2.1.2.1局部感知
人对外界的认知一般可以归纳为从局部到全局的过程,而图像的像素空间联系也是局部间的相关性强,远距离的相关性弱。因此,卷积神经网络的每个神经元实际上只需关注图像局部的感知,对图像全局的感知可通过更高层综合局部信息来获得,这也说明了卷积神经网络部分连通的思想。类似于生物学中的视觉系统结构,视觉皮层的神经元用于局部接收信息,即这些神经元只响应某些特定区域的刺激,呈现出部分连通的特点。
2.1.2.2参数共享
局部感知过程假设每个神经元都对应100个参数,共106个神经元,则参数共有100×106个,依然是一个很大的数字。如果这106个神经元的100个参数相等,那么参数个数就减少为100,即每个神经元用同样的卷积核执行卷积操作,这将大大降低运算量。因不论隐层的神经元个数有多少,两层间的连接只要100个参数,这也说明了参数共享的意义。
2.1.2.3多核卷积
如果10×10维数的卷积核都相同,那么只能提取图像的一种特征,局限性很明显。可以考虑通过增加卷积核来提高特征类别,例如选择16个不同的卷积核用于学习16种特征。其中,应用卷积核到图像执行卷积操作,可得到图像的不同特征,统称为特征图(Feature Map),所以16个不同的卷积核就有16个特征图,可以视作图像的不同通道。此时,卷积层包含10×10×16=1600个参数。
2.1.3池化层
从理论上来看,经卷积层得到特征集合,可直接用于训练分类器(例如经典的Softmax分类器),但这往往会带来巨大计算量的问题。通过计算图像局部区域上的某特定特征的平均值或最大值等来计算概要统计特征。这些概要统计特征相对于经卷积层计算得到的特征图,不仅达到了降维目的,同时还会提高调练效率,这种特征聚合的操作叫作池化(Pooling).
2.1.4 特征提取网络
将特征提取网络的矩阵转换为列向量,然后是全连接层,最后是10个输出节点,实现单热编码输出,一般使用的是Softmax激活函数。
3.训练方法
Delata规则+BP算法+交叉熵代价函数+SGD(随机梯度下降算法)+批标准化
3.1 cnn.py
import torch.nn as nn
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=3),
nn.BatchNorm2d(16),
nn.ReLU(inplace=True))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=3),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.layer3 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=3),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True))
self.layer4 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.fc = nn.Sequential(
nn.Linear(128*4*4, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 128),
nn.ReLU(inplace=True),
nn.Linear(128, 10)
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
3.2 MyMnistWindow.py
import torch
from torch.autograd import Variable
from torchvision import transforms
from PyQt5.QtWidgets import (QWidget, QPushButton, QLabel)
from PyQt5.QtGui import (QPainter, QPen, QFont)
from PyQt5.QtCore import Qt
from PIL import ImageGrab, Image
class MyMnistWindow(QWidget):
def __init__(self):
super(MyMnistWindow, self).__init__()
self.resize(284, 330) # resize设置宽高
self.move(100, 100) # move设置位置
self.setWindowFlags(Qt.FramelessWindowHint) # 窗体无边框
#setMouseTracking设置为False,否则不按下鼠标时也会跟踪鼠标事件
self.setAutoFillBackground(True)
p = self.palette()
p.setColor(self.backgroundRole(), Qt.black)
self.setPalette(p)
#设置背景
self.setMouseTracking(False)
self.pos_xy = [] #保存鼠标移动过的点
# 添加一系列控件
self.label_draw = QLabel('', self)
self.label_draw.setGeometry(2, 2, 280, 280)
self.label_draw.setStyleSheet("QLabel{border:1px solid white;}")
self.label_draw.setAlignment(Qt.AlignCenter)
self.label_result_name = QLabel('识别结果:', self)
self.label_result_name.setGeometry(2, 290, 60, 35)
self.label_draw.setStyleSheet("QLabel{border:1px solid white;}")
self.label_result_name.setAlignment(Qt.AlignCenter)
self.label_result = QLabel(' ', self)
self.label_result.setGeometry(64, 290, 35, 35)
self.label_result.setFont(QFont("Roman times", 8, QFont.Bold))
self.label_result.setStyleSheet("QLabel{border:1px solid white;}")
self.label_result.setAlignment(Qt.AlignCenter)
self.btn_recognize = QPushButton("识别", self)
self.btn_recognize.setGeometry(110, 290, 50, 35)
self.btn_recognize.clicked.connect(self.btn_recognize_on_clicked)
self.btn_clear = QPushButton("清空", self)
self.btn_clear.setGeometry(170, 290, 50, 35)
self.btn_clear.clicked.connect(self.btn_clear_on_clicked)
self.btn_close = QPushButton("关闭", self)
self.btn_close.setGeometry(230, 290, 50, 35)
self.btn_close.clicked.connect(self.btn_close_on_clicked)
def paintEvent(self, event):
painter = QPainter()
painter.begin(self)
pen = QPen(Qt.white, 15, Qt.SolidLine)
painter.setPen(pen)
if len(self.pos_xy) > 1:
point_start = self.pos_xy[0]
for pos_tmp in self.pos_xy:
point_end = pos_tmp
if point_end == (-1, -1):
point_start = (-1, -1)
continue
if point_start == (-1, -1):
point_start = point_end
continue
painter.drawLine(point_start[0], point_start[1], point_end[0], point_end[1])
point_start = point_end
painter.end()
def mouseMoveEvent(self, event):
#中间变量pos_tmp提取当前点
pos_tmp = (event.pos().x(), event.pos().y())
#pos_tmp添加到self.pos_xy中
self.pos_xy.append(pos_tmp)
self.update()
def mouseReleaseEvent(self, event):
pos_test = (-1, -1)
self.pos_xy.append(pos_test)
self.update()
def btn_recognize_on_clicked(self):
bbox = (104, 104, 380, 380)
im = ImageGrab.grab(bbox) # 截屏,手写数字部分
im = im.resize((28, 28), Image.ANTIALIAS) # 将截图转换成 28 * 28 像素
im = im.convert('L') # 转换成灰度图
recognize_result = self.recognize_img(im) # 调用识别函数
self.label_result.setText(str(recognize_result)) # 显示识别结果
self.update()
def btn_clear_on_clicked(self):
self.pos_xy = []
self.label_result.setText('')
self.update()
def btn_close_on_clicked(self):
self.close()
def recognize_img(self, img):
loader = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
img = loader(img).unsqueeze(0)#将图片格式转换为pytorch处理对象
#print(img)
model = torch.load('F:\python\mnist/minst_cnn_model.pth')
if torch.cuda.is_available():
model = model.cuda()
if torch.cuda.is_available():#在高性能显卡上运行
img = img.cuda()
else:
img = Variable(img)
out = model(img)
_, pred = torch.max(out, 1)
pred=int(pred)
print(pred)
return pred
3.3 main.py
import sys
from PyQt5.QtWidgets import QApplication
from MyMnistWindow import MyMnistWindow
if __name__ == "__main__":
app = QApplication(sys.argv)
mymnist = MyMnistWindow()
mymnist.show()
app.exec_()
3.4 mnist.py
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import torch.optim as optim
import cnn2
定义一些超参数
batch_size = 64
learning_rate = 1e-2
num_epochs = 4
#数据预处理。transforms.ToTensor()将图片转换成PyTorch中处理的对象Tensor,并且进行标准化(数据在0~1之间)
#transforms.Normalize()做归一化。它进行了减均值,再除以标准差。两个参数分别是均值和标准差
#transforms.Compose()函数则是将各种预处理的操作组合到了一起
if __name__ == '__main__':
data_tf = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
# 数据集的下载器,没有通过编译器下载,速度太慢,自行下载数据集后将其导入
train_dataset = datasets.MNIST(
root='F:\python\mnist', train=True, transform=data_tf, download=False)
test_dataset = datasets.MNIST(root='F:\python\mnist', train=False, transform=data_tf)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
#选择模型
#四层卷积,两层最大池化,卷积之后用批标准化加快收敛速度,用ReLU激活函数增加非线性,最后用全连接层输出分类得分。
model = cnn2.CNN()
if torch.cuda.is_available():
model = model.cuda()
#定义损失函数(交叉熵)和优化器(随机梯度下降来优化损失函数)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
#训练模型
epoch = 0
for epoch in range(num_epochs):#训练5轮
for data in train_loader:
img, label = data
# img = img.view(img.size(0), -1)
if torch.cuda.is_available():#在高性能显卡上运行
img = img.cuda()
label = label.cuda()
else:
img = Variable(img)
label = Variable(label)
out = model(img)
loss = criterion(out, label)
print_loss = loss.data.item()
#用于观察训练过程中损失是否在减小
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch+=1
#模型评估
model.eval()
eval_loss = 0
eval_acc = 0
for data in test_loader:
img, label = data
if torch.cuda.is_available():#在高性能显卡上运行
img = img.cuda()
label = label.cuda()
else:
img = Variable(img)
label = Variable(label)
out = model(img)
loss = criterion(out, label)
eval_loss+=loss.data.item()*label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
eval_acc += num_correct.item()
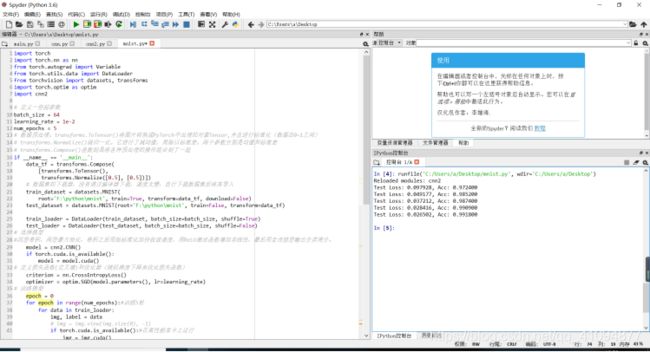
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(
eval_loss / (len(test_dataset)),
eval_acc / (len(test_dataset))
))
torch.save(model,'F:\python\mnist/minst_cnn_model.pth')#保存最后一轮的整个模型的结构信息和参数信
#save(model.state_dict(), 'F:\python\mnist./model state.pth')
4.实验结果分析

5.结论
通过对网络结构,算法,权值的不断调整,获得了目前最好的结果(98%+正确率)。通过对训练后的权值和初始化的权值对比,不断调整其参数,尽量让初始化权值大小和训练后的结果差不多大,这样的训练效果最好。在SGD,小批量,批量中,根据运行的时间和精度不断比较,最终还是选择SGD算法最优。而批标准化对准确率提升不大,但是提升了稳定性,也提高了更新速度。在特征提取网络中,一个隐层足够满足实验想要达到的精确率。而学习速率的步进速率的选取,只能通过一次次实验寻找合适的值。一轮训练效果不够理想,所以进行了多轮训练。我发现节点更多,训练效果会更好一些。最高跑过10轮,可以达到99.31%的准确率。