SDMG-R模型学习笔记
商汤出的算法,用于关键信息提取(KIE),集成在mmocr包里,需要搭配mmcv一起使用,本文将结合论文+源码对模型结构进行一个梳理。题外话,mmcv用了hook编程,调试起来还是蛮难的,以后有空再分享下mmcv的框架逻辑。
模型结构

整体结构可分为三个模块:双模态融合模块、图推理模块和分类模块三个。
模型的输入数据由图片、对应文本检测坐标区域、对应文本区域的文本内容构成,如:
{"file_name": "xxxx.jpg", "height": 1191, "width": 1685, "annotations": [{"box": [566, 113, 1095, 113, 1095, 145, 566, 145], "text": "yyyy", "label": 0}, {"box": [1119, 130, 1472, 130, 1472, 147, 1119, 147], "text": "aaaaa", "label": 1}, {"box": [299, 146, 392, 146, 392, 170, 299, 170], "text": "cccc", "label": 2}, {"box": [1447, 187, 1545, 187, 1545, 201, 1447, 201], "text": "dddd", "label": 0},]}
首先是双模态融合模块,视觉特征通过Unet及ROI-Pooling进行提取,语义特征通过Bi-LSTM进行提取,然后多模态特征通过克罗内克积进行融合语义、视觉特征,然后再输入到空间多模态推理模型(图推理模块)提取最终的节点特征,最后通过分类模块进行多分类任务;
双模态融合模块
视觉特征提取详细步骤:
- 输入原始图片,resize到固定输入尺寸(本文512x512);
- 输入到Unet,使用Unet作为视觉特征提取器,获取得到CNN最后一层的特征图;
- 将输入尺寸的文本区域坐标()映射到最后一层CNN特征图,通过ROI-pooling方法进行特征提取,获取对应文本区域图像的视觉特征;
对应的代码:
位置:mmocr\models\kie\extractors\sdmgr.py
def extract_feat(self, img, gt_bboxes):
if self.visual_modality:
# 视觉特征提取
x = super().extract_feat(img)[-1]
feats = self.maxpool(self.extractor([x], bbox2roi(gt_bboxes)))
return feats.view(feats.size(0), -1)
return None
Unet网络:用于图像分割的一个算法
详解:深入理解深度学习分割网络Unet
对应代码位置:mmocr\models\common\backbones\unet.py
ROI-Pooling:是Pooling层的一种,而且是针对RoIs的Pooling,他的特点是输入特征图尺寸不固定,但是输出特征图尺寸固定。
详解:ROI Pooling层解析
文本语义特征提取详细步骤:
- 首先收集字符集表,本文收集了91个长度字符表,涵盖数字(0-9)、字母(a-z,A-Z)、相关任务的特殊字符集(如“/”, “n”, “.”, “$”, “AC”, “ ”, “¥”, “:”, “-”, “*”, “#”等),不在字符表的字符统一标记成“unkown”;
- 然后将文本字符内容映射到32维度的one-hot语义输入的编码形式;
- 然后输入到Bi-LSTM模型中,提取256维度语义特征;
对应的代码:
位置:mmocr\models\kie\heads\sdmgr_head.py
def forward(self, relations, texts, x=None):
node_nums, char_nums = [], []
for text in texts:
node_nums.append(text.size(0))
char_nums.append((text > 0).sum(-1))
max_num = max([char_num.max() for char_num in char_nums])
all_nodes = torch.cat([
torch.cat(
[text,
text.new_zeros(text.size(0), max_num - text.size(1))], -1)
for text in texts
])
embed_nodes = self.node_embed(all_nodes.clamp(min=0).long())
rnn_nodes, _ = self.rnn(embed_nodes)
nodes = rnn_nodes.new_zeros(*rnn_nodes.shape[::2])
all_nums = torch.cat(char_nums)
valid = all_nums > 0
nodes[valid] = rnn_nodes[valid].gather(
1, (all_nums[valid] - 1).unsqueeze(-1).unsqueeze(-1).expand(
-1, -1, rnn_nodes.size(-1))).squeeze(1)
视觉+文本语义特征融合步骤:
多模态特征融合:通过克罗内克积进行特征融合,具体公式如下:

对应代码:
# Block是代码里自定义的一个类, 估计就是写的克罗内克积吧
self.fusion = Block([visual_dim, node_embed], node_embed, fusion_dim)
# 图像特征和文本特征融合
if x is not None:
nodes = self.fusion([x, nodes])
图推理模块
论文中将文档图像作为一个图来看待,最终的节点特征通过多模态图推理模型完成,公式如下:
![]()


节点之间关系编码对应的计算源码如下:
# 这里的boxes是一篇文档里所有的文本框,维度为[文本框个数,8],8是box的4个坐标值,从左到右,从上到下
def compute_relation(boxes, norm: float = 10.):
"""Compute relation between every two boxes."""
# Get minimal axis-aligned bounding boxes for each of the boxes
# yapf: disable
bboxes = np.concatenate(
[boxes[:, 0::2].min(axis=1, keepdims=True),
boxes[:, 1::2].min(axis=1, keepdims=True),
boxes[:, 0::2].max(axis=1, keepdims=True),
boxes[:, 1::2].max(axis=1, keepdims=True)],
axis=1).astype(np.float32)
# yapf: enable
x1, y1 = boxes[:, 0:1], boxes[:, 1:2]
x2, y2 = boxes[:, 4:5], boxes[:, 5:6]
w, h = np.maximum(x2 - x1 + 1, 1), np.maximum(y2 - y1 + 1, 1)
dx = (x1.T - x1) / norm
dy = (y1.T - y1) / norm
xhh, xwh = h.T / h, w.T / h
whs = w / h + np.zeros_like(xhh)
relation = np.stack([dx, dy, whs, xhh, xwh], -1).astype(np.float32)
# bboxes = np.concatenate([x1, y1, x2, y2], -1).astype(np.float32)
return relation, bboxes
随后,将文本节点之间的信息嵌入到边的权重之中,具体按照下面公式,该部分对应源码主要位于GNNLayer类中。:
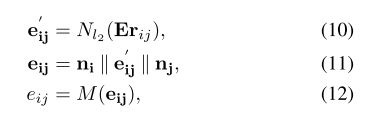
论文中提到该部分主要是以迭代的方式来逐步优化节点特征,详细参见论文中公式(13~14):
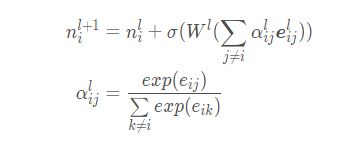
# 图推理模块
# 公式10
all_edges = torch.cat(
[rel.view(-1, rel.size(-1)) for rel in relations])
embed_edges = self.edge_embed(all_edges.float())
embed_edges = F.normalize(embed_edges)
for gnn_layer in self.gnn_layers:
nodes, cat_nodes = gnn_layer(nodes, embed_edges, node_nums)
class GNNLayer(nn.Module):
def __init__(self, node_dim=256, edge_dim=256):
super().__init__()
self.in_fc = nn.Linear(node_dim * 2 + edge_dim, node_dim)
self.coef_fc = nn.Linear(node_dim, 1)
self.out_fc = nn.Linear(node_dim, node_dim)
self.relu = nn.ReLU()
def forward(self, nodes, edges, nums):
start, cat_nodes = 0, []
for num in nums:
sample_nodes = nodes[start:start + num]
cat_nodes.append(
torch.cat([
sample_nodes.unsqueeze(1).expand(-1, num, -1),
sample_nodes.unsqueeze(0).expand(num, -1, -1)
], -1).view(num**2, -1))
start += num
# 公式11
cat_nodes = torch.cat([torch.cat(cat_nodes), edges], -1)
# 公式12-13
cat_nodes = self.relu(self.in_fc(cat_nodes))
coefs = self.coef_fc(cat_nodes)
# 公式14
start, residuals = 0, []
for num in nums:
residual = F.softmax(
-torch.eye(num).to(coefs.device).unsqueeze(-1) * 1e9 +
coefs[start:start + num**2].view(num, num, -1), 1)
residuals.append(
(residual *
cat_nodes[start:start + num**2].view(num, num, -1)).sum(1))
start += num**2
nodes += self.relu(self.out_fc(torch.cat(residuals)))
return nodes, cat_nodes
多分类模块
该部分就是两个Linear层,一个Linear对应节点,一个Linear对应边:
self.node_cls = nn.Linear(node_embed, num_classes)
self.edge_cls = nn.Linear(edge_embed, 2)
# edge_cls shape is [node_num*2,2]
node_cls, edge_cls = self.node_cls(nodes), self.edge_cls(cat_nodes)
源代码:
class SDMGRHead(BaseModule):
def __init__(self,
num_chars=92,
visual_dim=64,
fusion_dim=1024,
node_input=32,
node_embed=256,
edge_input=5,
edge_embed=256,
num_gnn=2,
num_classes=26,
loss=dict(type='SDMGRLoss'),
bidirectional=False,
train_cfg=None,
test_cfg=None,
init_cfg=dict(
type='Normal',
override=dict(name='edge_embed'),
mean=0,
std=0.01)):
super().__init__(init_cfg=init_cfg)
# 文本与视觉信息融合模块
self.fusion = Block([visual_dim, node_embed], node_embed, fusion_dim)
self.node_embed = nn.Embedding(num_chars, node_input, 0)
hidden = node_embed // 2 if bidirectional else node_embed
# 单层lstm
self.rnn = nn.LSTM(
input_size=node_input,
hidden_size=hidden,
num_layers=1,
batch_first=True,
bidirectional=bidirectional)
# 图推理模块
self.edge_embed = nn.Linear(edge_input, edge_embed)
self.gnn_layers = nn.ModuleList(
[GNNLayer(node_embed, edge_embed) for _ in range(num_gnn)])
# 分类模块
self.node_cls = nn.Linear(node_embed, num_classes)
self.edge_cls = nn.Linear(edge_embed, 2)
self.loss = build_loss(loss)
def forward(self, relations, texts, x=None):
# relation是节点之间关系编码,shape为[batch,文本框个数,文本框个数,5],其中这个5是固定的,代表上文的公式7-9对应的值
# texts是文本信息,shape为[batch,文本框个数,文本框中字符最大值]
# x是图特征
node_nums, char_nums = [], []
for text in texts:
node_nums.append(text.size(0))
char_nums.append((text > 0).sum(-1))
# 取出一批数据中的最长文本的长度
max_num = max([char_num.max() for char_num in char_nums])
# 进行padding操作
all_nodes = torch.cat([
torch.cat(
[text,
text.new_zeros(text.size(0), max_num - text.size(1))], -1)
for text in texts
])
# 编码文本信息
embed_nodes = self.node_embed(all_nodes.clamp(min=0).long())
rnn_nodes, _ = self.rnn(embed_nodes)
nodes = rnn_nodes.new_zeros(*rnn_nodes.shape[::2])
all_nums = torch.cat(char_nums)
valid = all_nums > 0
nodes[valid] = rnn_nodes[valid].gather(
1, (all_nums[valid] - 1).unsqueeze(-1).unsqueeze(-1).expand(
-1, -1, rnn_nodes.size(-1))).squeeze(1)
# 视觉特征和文本特征融合
if x is not None:
nodes = self.fusion([x, nodes])
# 图推理模块
# 根据输入的两个文本框之间的空间位置关系,对边关系进行编码(重要影响)
all_edges = torch.cat(
[rel.view(-1, rel.size(-1)) for rel in relations])
embed_edges = self.edge_embed(all_edges.float())
embed_edges = F.normalize(embed_edges)
for gnn_layer in self.gnn_layers:
# 这里输入虽然是batch,但是输出的时候把batch的结果拼接到一起了
# nodes.shape = [sum(batch_box_num),256]
# cat_nodes.shape = [sum(batch_box_num^2),256]
nodes, cat_nodes = gnn_layer(nodes, embed_edges, node_nums)
# 多分类模块
# node_cls.shape = [sum(batch_box_num),label_num]
# edge_cls .shape = [sum(batch_box_num^2),2]
node_cls, edge_cls = self.node_cls(nodes), self.edge_cls(cat_nodes)
return node_cls, edge_cls
模型应用
- 适用于版式相对固定的单据
- 视觉模块是可以关闭的,在配置文件中声明就行
model = dict(
type='SDMGR',
backbone=dict(type='UNet', base_channels=16),
bbox_head=dict(
# 这里的num_chars是字典
type='SDMGRHead', visual_dim=16, num_chars=123, num_classes=23, num_gnn=4),
visual_modality=False, # 这个参数,控制是否使用视觉模块
train_cfg=None,
test_cfg=None,
class_list=f'{data_root}/../class_list.txt')
自问自答
- 数据集里的边的关系是如何初始化的?
是一个[box_num,box_num]的矩阵,除了自己与自己外为-1,其他都为1,源代码位置:mmocr\datasets\kie_dataset.py中的list_to_numpy函数
if labels is not None:
labels = np.array(labels, np.int32)
edges = ann_infos.get('edges', None)
if edges is not None:
labels = labels[:, None]
edges = np.array(edges)
edges = (edges[:, None] == edges[None, :]).astype(np.int32)
if self.directed:
edges = (edges & labels == 1).astype(np.int32)
np.fill_diagonal(edges, -1)
labels = np.concatenate([labels, edges], -1)
- edge_pred的用处?
在loss里进行了计算,与初始化之后的edge_gold进行了交叉熵的运算,返回了loss_edge与acc_edge,需要注意的是,acc_edge在运算时,没有把自己与自己的关系值算进去,acc_edge一直是100%,loss_edge则把自己与自己的关系loss算了进去,因此有值,但是相对于loss_node来说值很小,最终的loss是loss_node+loss_edge,相关代码如下:
位置:mmocr\models\kie\losses\sdmgr_loss.py
# 细分loss推理
def forward(self, node_preds, edge_preds, gts):
node_gts, edge_gts = [], []
for gt in gts:
node_gts.append(gt[:, 0])
edge_gts.append(gt[:, 1:].contiguous().view(-1))
node_gts = torch.cat(node_gts).long()
edge_gts = torch.cat(edge_gts).long()
node_valids = torch.nonzero(
node_gts != self.ignore, as_tuple=False).view(-1)
edge_valids = torch.nonzero(edge_gts != -1, as_tuple=False).view(-1)
return dict(
loss_node=self.node_weight * self.loss_node(node_preds, node_gts),
loss_edge=self.edge_weight * self.loss_edge(edge_preds, edge_gts),
acc_node=accuracy(node_preds[node_valids], node_gts[node_valids]),
acc_edge=accuracy(edge_preds[edge_valids], edge_gts[edge_valids]))
位置:mmdet\models\detectors\base.py 中的_parse_losses函数
def _parse_losses(self, losses):
"""Parse the raw outputs (losses) of the network.
Args:
losses (dict): Raw output of the network, which usually contain
losses and other necessary infomation.
Returns:
tuple[Tensor, dict]: (loss, log_vars), loss is the loss tensor \
which may be a weighted sum of all losses, log_vars contains \
all the variables to be sent to the logger.
"""
log_vars = OrderedDict()
for loss_name, loss_value in losses.items():
if isinstance(loss_value, torch.Tensor):
log_vars[loss_name] = loss_value.mean()
elif isinstance(loss_value, list):
log_vars[loss_name] = sum(_loss.mean() for _loss in loss_value)
else:
raise TypeError(
f'{loss_name} is not a tensor or list of tensors')
# loss相加
loss = sum(_value for _key, _value in log_vars.items()
if 'loss' in _key)
log_vars['loss'] = loss
for loss_name, loss_value in log_vars.items():
# reduce loss when distributed training
if dist.is_available() and dist.is_initialized():
loss_value = loss_value.data.clone()
dist.all_reduce(loss_value.div_(dist.get_world_size()))
log_vars[loss_name] = loss_value.item()
return loss, log_vars
参考资料
- 论文笔记
- 论文原文
- 论文解读