智能机器人在生活中随处可见:iPhone里会说话的siri、会下棋的阿法狗、调皮可爱的微软小冰……她们都具有一定的智能,能够和人类进行交互。这些智能机器人非常神奇,看上去离我们也十分遥远,但其实只要我们动动手,便可以造一个属于自己的智能机器人。
本文将教你从零开始造出一个智障,不对是“智能聊天机器人"。
要造一个聊天机器人,首先你需要了解一些相关概念——自然语言处理(NLP),它是一门融语言学、计算机科学、数学于一体的科学,研究让电脑“懂”人类语言的方法。当然,它也包含很多分支:文本朗读、语音识别、句法分析、自然语言生成、人机对话、信息检索、信息抽取、文字校对、文本分类、自动文摘、机器翻译、文字蕴含等等等。
看到这里的朋友,千万别被这些吓跑。既然本文叫《从零开始造一个“智障”聊天机器人》那么各位看官老爷不懂这些也没有关系!跟着我的脚步一步一步做吧。
0x1 基本概念
这里涉及到的原理基础,没兴趣的看官老爷略过即可,不影响后续代码实现。
01|神经网络
人工智能的底层是”神经网络“,许多复杂的应用(比如模式识别、自动控制)和高级模型(比如深度学习)都基于它。学习人工智能,一定是从它开始。
那么问题来了,什么是神经网络呢?简单来说,神经网络就是模拟人脑神经元网络,从而让计算机懂得”思考“。具体概念在这里不再赘述,网络上有很多简单易懂的解释。
本文使用的的是循环神经网络(RNN),我们来看一个最简单的基本循环神经网络:
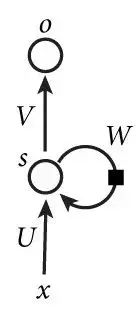
虽然图像看起来很抽象,但是实际很好理解。x、o、s是一个向量,x代表输入层的值,o代表输出层的值,s是隐藏层的值(这里其实有很多节点);U、V是权重矩阵,U代表输入层到隐藏层的权重矩阵,而V则代表隐藏层到输出层的权重矩阵。那么W是什么呢?其实循环神经网络的隐藏层的值s不仅仅由x、U决定,还会由上一次隐藏层的值s,而W就是上一次到隐藏层到这一次的权重矩阵,将其展开就是这样:
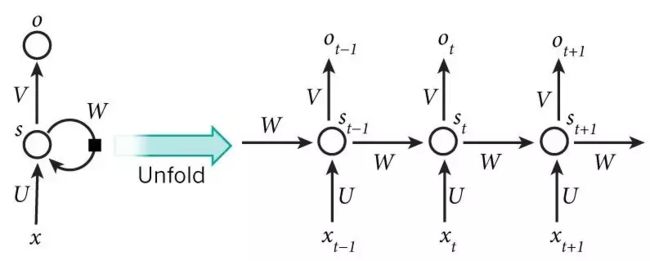
这样逻辑就清晰很多了,这便是一个简单的循环神经网络。而我们的智障,不对是“智能聊天机器人"便是使用循环神经网络,基于自然语言的词法分析、句法分析不断的训练语料,并把语义分析都融入进来做的补充和改进。
02|深度学习框架
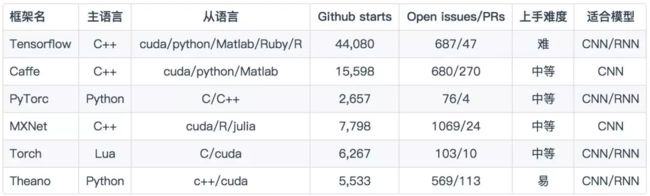
适合RNN的深度学习框架有很多,本文的聊天机器人基于Google开源的Tensorflow,从GayhubGithub的starts数便可以看出,Tensorflow是一个极其火爆的深度学习框架,并且可以轻松地在cpu / gpu 上进行分布式计算,下面罗列了一些目前主流深度学习框架的特性,大家可以凭兴趣选择框架进行研究:
03|seq2seq模型
顾名思义,seq2seq 模型就像一个翻译模型,输入是一个序列(比如一个英文句子),输出也是一个序列(比如该英文句子所对应的法文翻译)。这种结构最重要的地方在于输入序列和输出序列的长度是可变的。
举个例子:
在对话机器中:输入(hello) -> 输出 (你好)。
输入是1个英文单词,输出为2个汉字。我们提(输入)一个问题,机器会自动生成(输出)回答。这里的输入和输出显然是长度没有确定的序列(sequences)
我们再举一个长一点的例子:
我教小黄鸡说“大白天的做什么美梦啊?”回答是“哦哈哈哈不用你管”。
Step1:应用双向最大匹配算法分词:双向分词结果,正向《大白天,的,做什么,美梦,啊》;反向《大白天,的,做什么,美梦,啊》。正向反向都是一样的,所以不需要处理歧义问题。长词优先选择,“大白天”和“做什么”。
Step2:以“大白天”举例,假设hash函数为f(),并设f(大白天)指向首字hash表项[大,11,P]。于是由该表项指向“3字索引”,再指向对应“词表”。
Step3:将结构体<大白天,…>插入队尾。体中有一个Ans域,域中某一指针指向“哦哈哈哈不用你管”。
这便是seq2seq的基本原理,原理和技术我们都有了,下一步就是将它实现出来!
0x2 语料准备
了解完一些前置基础,我们话不多说,直接进入造智能聊天机器人的阶段。首先我们需要准备相关训练的语料。
01|语料整理
本次训练的语料库是从Github上下载的(Github用于对话系统的中英文语料:https://github.com/candlewill/Dialog_Corpus)。我们下载其中的xiaohuangji50w_fenciA.conv(小黄鸡语料)进行我们的训练。
当我们下载完后打开发现,它这个语料库是这样的:
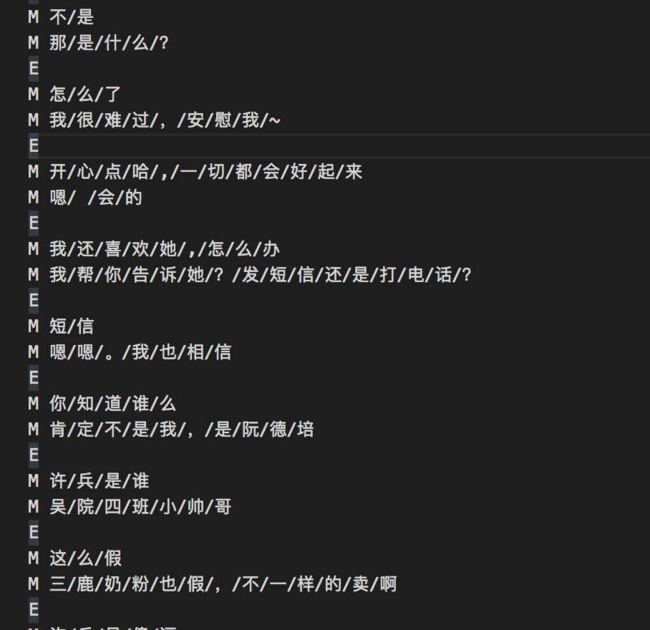
虽然这里面的文字、对话我们都能看懂,但是这些E、M、/都是些什么鬼?其实从图来看很容易理解,M即代表这句话,而E则代表一段对话的开始与结束。
如果对于人工智能有相同兴趣,或者技术上的交流可以加我QQ进行讨论:425851955
我们拿到这些语料后,用代码将其按照问/答分为两类"Question.txt"、"Answer.txt":
1importre
2importsys
3defprepare(num_dialogs=50000):
4withopen("xhj.conv")asfopen:
5# 替换E、M等
6reg = re.compile("EnM (.*?)nM (.*?)n")
7match_dialogs = re.findall(reg, fopen.read())
8# 使用5W条对话作为训练语料
9ifnum_dialogs >= len(match_dialogs):
10dialogs = match_dialogs
11else:
12dialogs = match_dialogs[:num_dialogs]
13questions = []
14answers = []
15forque, ansindialogs:
16questions.append(que)
17answers.append(ans)
18# 保存到data/文件夹目录下
19save(questions,"data/Question.txt")
20save(answers,"data/Answer.txt")
21defsave(dialogs, file):
22withopen(file,"w")asfopen:
23fopen.write("n".join(dialogs))
最终我们得到5W条问题与回答数据:
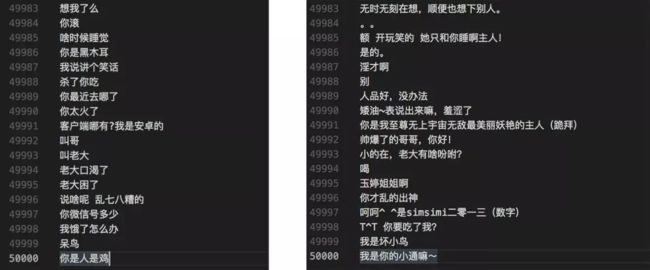
02|向量表映射建立
到这里,大家可能会问,那么这个"智能"聊天机器人是不是就是将我们输入的问题匹配Question.txt里面的问题,然后再从Answer.txt找到相应回答进行输出?
当然不会是这么简单,本质上聊天机器人是基于问句的上下文环境产生一个新的回答,而非是从数据库中拿出一条对应好的回答数据。
那么机器怎么知道该回答什么呢?此处借用一下谷歌的seq2seq原理图:
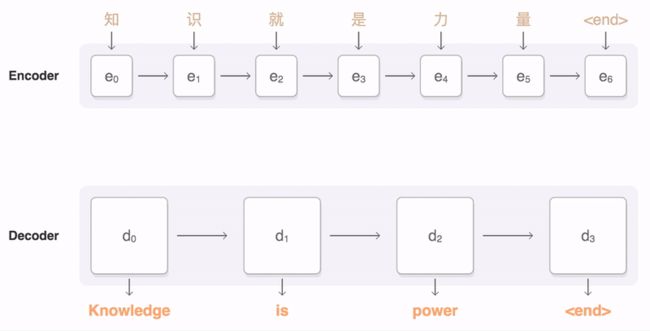
简单来说就是:我们输入的每一句话,都会被机器拆成词并向量化;这些词作为输入层的向量,与权重矩阵进行计算后到隐藏层,隐藏层输出的向量再与权重矩阵进行计算,得到最终向量。我们再将此向量映射到词向量库时,便可得到我们想要的结果。
在代码上实现比较简单,因为复杂底层逻辑的都由Tensorflow帮我们完成了,我们将词汇表进行最终的梳理:
1defgen_vocabulary_file(input_file, output_file):
2vocabulary = {}
3withopen(input_file)asf:
4counter =0
5forlineinf:
6counter +=1
7tokens = [wordforwordinline.strip()]
8forwordintokens:
9# 过滤非中文 文字
10ifu'u4e00'<= word <=u'u9fff':
11ifwordinvocabulary:
12vocabulary[word] +=1
13else:
14vocabulary[word] =1
15vocabulary_list = START_VOCABULART + sorted(vocabulary, key=vocabulary.get, reverse=True)
16# 取前3500个常用汉字,vocabulary_size = 3500
17iflen(vocabulary_list) > vocabulary_size:
18vocabulary_list = vocabulary_list[:vocabulary_size]
19print(input_file +" 词汇表大小:", len(vocabulary_list))
20withopen(output_file,"w")asff:
21forwordinvocabulary_list:
22ff.write(word +"n")
23ff.close
0x3 开始训练
01|训练
在我们的语料准备好之后,便可以开始我训练,其实训练本身是很简单的,其核心是调用Tensorflow的Seq2SeqModel,不断的进行循环训练。下面是训练的核心代码与参数设置:
1# 源输入词表的大小
2vocabulary_encode_size =3500
3# 目标输出词表的大小
4vocabulary_decode_size =3500
5#一种有效处理不同长度的句子的方法
6buckets = [(5,10), (10,15), (20,25), (40,50)]
7# 每层单元数目
8layer_size =256
9# 网络的层数。
10num_layers =3
11# 训练时的批处理大小
12batch_size =64
13# max_gradient_norm:表示梯度将被最大限度地削减到这个规范
14# learning_rate: 初始的学习率
15# learning_rate_decay_factor: 学习率衰减因子
16# forward_only: false意味着在解码器端,使用decoder_inputs作为输入。例如decoder_inputs 是‘GO, W, X, Y, Z ’,正确的输出应该是’W, X, Y, Z, EOS’。假设第一个时刻的输出不是’W’,在第二个时刻也要使用’W’作为输入。当设为true时,只使用decoder_inputs的第一个时刻的输入,即’GO’,以及解码器的在每一时刻的真实输出作为下一时刻的输入。
17model = seq2seq_model.Seq2SeqModel(source_vocab_size=vocabulary_encode_size, target_vocab_size=vocabulary_decode_size,buckets=buckets, size=layer_size, num_layers=num_layers, max_gradient_norm=5.0,batch_size=batch_size, learning_rate=0.5, learning_rate_decay_factor=0.97, forward_only=False)
18
19config = tf.ConfigProto()
20config.gpu_options.allocator_type ='BFC'# 防止 out of memory
21
22withtf.Session(config=config)assess:
23# 恢复前一次训练
24ckpt = tf.train.get_checkpoint_state('.')
25ifckpt !=None:
26print(ckpt.model_checkpoint_path)
27model.saver.restore(sess, ckpt.model_checkpoint_path)
28else:
29sess.run(tf.global_variables_initializer())
30
31train_set = read_data(train_encode_vec, train_decode_vec)
32test_set = read_data(test_encode_vec, test_decode_vec)
33
34train_bucket_sizes = [len(train_set[b])forbinrange(len(buckets))]
35train_total_size = float(sum(train_bucket_sizes))
36train_buckets_scale = [sum(train_bucket_sizes[:i +1]) / train_total_sizeforiinrange(len(train_bucket_sizes))]
37
38loss =0.0
39total_step =0
40previous_losses = []
41# 一直训练,每过一段时间保存一次模型
42whileTrue:
43random_number_01 = np.random.random_sample()
44bucket_id = min([iforiinrange(len(train_buckets_scale))iftrain_buckets_scale[i] > random_number_01])
45
46encoder_inputs, decoder_inputs, target_weights = model.get_batch(train_set, bucket_id)
47_, step_loss, _ = model.step(sess, encoder_inputs, decoder_inputs, target_weights, bucket_id,False)
48
49loss += step_loss /500
50total_step +=1
51
52print(total_step)
53iftotal_step %500==0:
54print(model.global_step.eval(), model.learning_rate.eval(), loss)
55
56# 如果模型没有得到提升,减小learning rate
57iflen(previous_losses) >2andloss > max(previous_losses[-3:]):
58sess.run(model.learning_rate_decay_op)
59previous_losses.append(loss)
60# 保存模型
61checkpoint_path ="chatbot_seq2seq.ckpt"
62model.saver.save(sess, checkpoint_path, global_step=model.global_step)
63loss =0.0
64# 使用测试数据评估模型
65forbucket_idinrange(len(buckets)):
66iflen(test_set[bucket_id]) ==0:
67continue
68encoder_inputs, decoder_inputs, target_weights = model.get_batch(test_set, bucket_id)
69_, eval_loss, _ = model.step(sess, encoder_inputs, decoder_inputs, target_weights, bucket_id,True)
70eval_ppx = math.exp(eval_loss)ifeval_loss <300elsefloat('inf')
71print(bucket_id, eval_ppx)
02|实际问答效果
如果我们的模型一直在训练,那么机器怎么知道在什么时候停止训练呢?这个停止训练的阀值又靠什么去衡量?在这里我们引入一个语言模型评价指标——Perplexity。
① Perplexity是什么:
PPL是用在自然语言处理领域(NLP)中,衡量语言模型好坏的指标。它主要是根据每个词来估计一句话出现的概率,并用句子长度作normalize,公式为 :
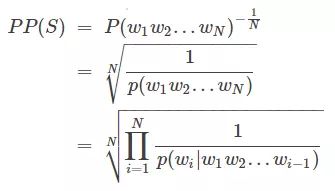
S代表sentence,N是句子长度,p(wi)是第i个词的概率。第一个词就是 p(w1|w0),而w0是START,表示句子的起始,是个占位符。
这个式子可以这样理解,PPL越小,p(wi)则越大,一句我们期望的sentence出现的概率就越高。
还有人说,Perplexity可以认为是average branch factor(平均分支系数),即预测下一个词时可以有多少种选择。别人在作报告时说模型的PPL下降到90,可以直观地理解为,在模型生成一句话时下一个词有90个合理选择,可选词数越少,我们大致认为模型越准确。这样也能解释,为什么PPL越小,模型越好。
对于我们的训练,其最近几次的Perplexity如下:
如果对于人工智能有相同兴趣,或者技术上的交流可以加我QQ进行讨论:425851955

截止发文时,此模型已经训练了27h,其Perplexity仍然比较难收敛,所以模型的训练真的需要一些耐心。如果有条件使用GPU进行训练,那么此速度将会大大提高。
我们使用现阶段的模型进行一些对话,发现已经初具雏形:

至此,我们的“智能聊天机器人”已经大功告成!但不难看出,这个机器人还是在不断的犯傻,很多问题牛头不对马嘴,所以我们又称其为“智障机器人”。
0x4 结语
至此我们就从无到有训练了一个问答机器人,虽然它还有点”智障“不太理解更多的词汇,但是整体流程已经跑通,并且具有一定的效果。后面的工作就是不断的完善其中的算法、参数与语料了。其中语料是特别关键的部分,大概会占用到50%-70%的工作量,因为本文使用的是互联网上已经处理好的语料,省去了不少时间。事实上大部分开发人员的时间都在进行语料预处理:数据清洗、分词、词性标注、去停用词等方面。