kube-scheduler源码分析(1)-初始化与启动分析
kube-scheduler源码分析(1)-初始化与启动分析
kube-scheduler简介
kube-scheduler组件是kubernetes中的核心组件之一,主要负责pod资源对象的调度工作,具体来说,kube-scheduler组件负责根据调度算法(包括预选算法和优选算法)将未调度的pod调度到合适的最优的node节点上。
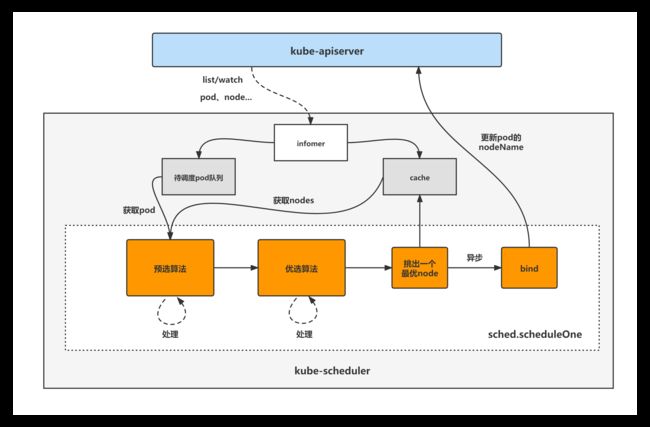
kube-scheduler架构图
kube-scheduler的大致组成和处理流程如下图,kube-scheduler对pod、node等对象进行了list/watch,根据informer将未调度的pod放入待调度pod队列,并根据informer构建调度器cache(用于快速获取需要的node等对象),然后sched.scheduleOne方法为kube-scheduler组件调度pod的核心处理逻辑所在,从未调度pod队列中取出一个pod,经过预选与优选算法,最终选出一个最优node,然后更新cache并异步执行bind操作,也就是更新pod的nodeName字段,至此一个pod的调度工作完成。
kube-scheduler组件的分析将分为两大块进行,分别是:
(1)kube-scheduler初始化与启动分析;
(2)kube-scheduler核心处理逻辑分析。
本篇先进行kube-scheduler组件的初始化与启动分析,下篇再进行核心处理逻辑分析。
1.kube-scheduler初始化与启动分析
基于tag v1.17.4
https://github.com/kubernetes/kubernetes/releases/tag/v1.17.4
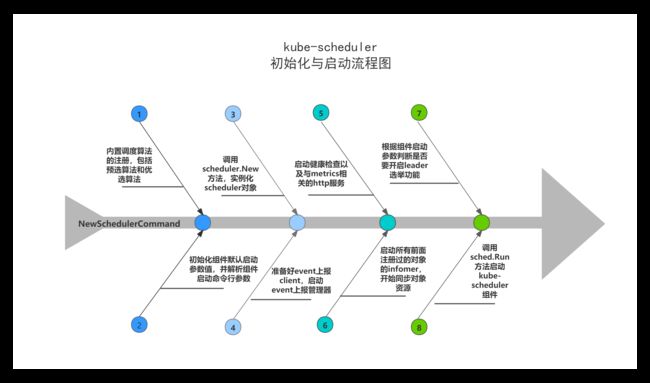
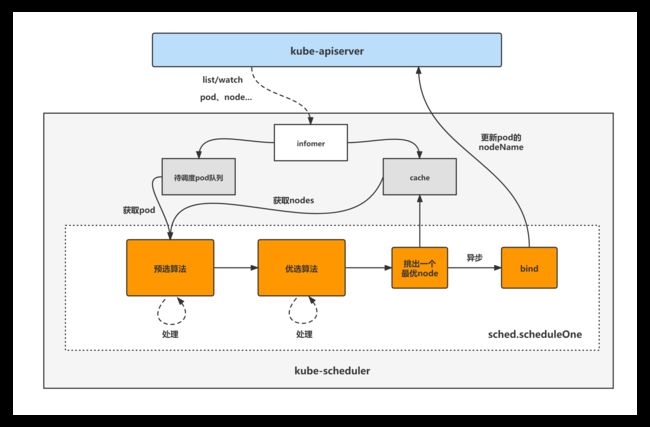
直接看到kube-scheduler的NewSchedulerCommand函数,作为kube-scheduler初始化与启动分析的入口。
NewSchedulerCommand
NewSchedulerCommand函数主要逻辑:
(1)初始化组件默认启动参数值;
(2)定义kube-scheduler组件的运行命令方法,即runCommand函数(runCommand函数最终调用Run函数来运行启动kube-scheduler组件,下面会进行Run函数的分析);
(3)kube-scheduler组件启动命令行参数解析。
// cmd/kube-scheduler/app/server.go
func NewSchedulerCommand(registryOptions ...Option) *cobra.Command {
// 1.初始化组件默认启动参数值
opts, err := options.NewOptions()
if err != nil {
klog.Fatalf("unable to initialize command options: %v", err)
}
// 2.定义kube-scheduler组件的运行命令方法,即runCommand函数
cmd := &cobra.Command{
Use: "kube-scheduler",
Long: `The Kubernetes scheduler is a policy-rich, topology-aware,
workload-specific function that significantly impacts availability, performance,
and capacity. The scheduler needs to take into account individual and collective
resource requirements, quality of service requirements, hardware/software/policy
constraints, affinity and anti-affinity specifications, data locality, inter-workload
interference, deadlines, and so on. Workload-specific requirements will be exposed
through the API as necessary.`,
Run: func(cmd *cobra.Command, args []string) {
if err := runCommand(cmd, args, opts, registryOptions...); err != nil {
fmt.Fprintf(os.Stderr, "%v\n", err)
os.Exit(1)
}
},
}
// 3.组件命令行启动参数解析
fs := cmd.Flags()
namedFlagSets := opts.Flags()
verflag.AddFlags(namedFlagSets.FlagSet("global"))
globalflag.AddGlobalFlags(namedFlagSets.FlagSet("global"), cmd.Name())
for _, f := range namedFlagSets.FlagSets {
fs.AddFlagSet(f)
}
...
}
runCommand
runCommand定义了kube-scheduler组件的运行命令函数,主要看到以下两个逻辑:
(1)调用algorithmprovider.ApplyFeatureGates方法,根据FeatureGate是否开启,决定是否追加注册相应的预选和优选算法;
(2)调用Run,运行启动kube-scheduler组件。
// cmd/kube-scheduler/app/server.go
// runCommand runs the scheduler.
func runCommand(cmd *cobra.Command, args []string, opts *options.Options, registryOptions ...Option) error {
...
// Apply algorithms based on feature gates.
// TODO: make configurable?
algorithmprovider.ApplyFeatureGates()
// Configz registration.
if cz, err := configz.New("componentconfig"); err == nil {
cz.Set(cc.ComponentConfig)
} else {
return fmt.Errorf("unable to register configz: %s", err)
}
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
return Run(ctx, cc, registryOptions...)
}
1.1 algorithmprovider.ApplyFeatureGates
根据FeatureGate是否开启,决定是否追加注册相应的预选和优选算法。
// pkg/scheduler/algorithmprovider/plugins.go
import (
"k8s.io/kubernetes/pkg/scheduler/algorithmprovider/defaults"
)
func ApplyFeatureGates() func() {
return defaults.ApplyFeatureGates()
}
1.1.1 init
plugins.go文件import了defaults包,所以看defaults.ApplyFeatureGates方法之前,先来看到defaults包的init函数,主要做了内置调度算法的注册工作,包括预选算法和优选算法。
(1)先来看到defaults包中defaults.go文件init函数。
// pkg/scheduler/algorithmprovider/defaults/defaults.go
func init() {
registerAlgorithmProvider(defaultPredicates(), defaultPriorities())
}
预算算法:
// pkg/scheduler/algorithmprovider/defaults/defaults.go
func defaultPredicates() sets.String {
return sets.NewString(
predicates.NoVolumeZoneConflictPred,
predicates.MaxEBSVolumeCountPred,
predicates.MaxGCEPDVolumeCountPred,
predicates.MaxAzureDiskVolumeCountPred,
predicates.MaxCSIVolumeCountPred,
predicates.MatchInterPodAffinityPred,
predicates.NoDiskConflictPred,
predicates.GeneralPred,
predicates.PodToleratesNodeTaintsPred,
predicates.CheckVolumeBindingPred,
predicates.CheckNodeUnschedulablePred,
)
}
优选算法:
// pkg/scheduler/algorithmprovider/defaults/defaults.go
func defaultPriorities() sets.String {
return sets.NewString(
priorities.SelectorSpreadPriority,
priorities.InterPodAffinityPriority,
priorities.LeastRequestedPriority,
priorities.BalancedResourceAllocation,
priorities.NodePreferAvoidPodsPriority,
priorities.NodeAffinityPriority,
priorities.TaintTolerationPriority,
priorities.ImageLocalityPriority,
)
}
registerAlgorithmProvider函数注册 algorithm provider,algorithm provider存储了所有类型的调度算法列表,包括预选算法和优选算法(只存储了算法key列表,不包含算法本身)。
// pkg/scheduler/algorithmprovider/defaults/defaults.go
func registerAlgorithmProvider(predSet, priSet sets.String) {
// Registers algorithm providers. By default we use 'DefaultProvider', but user can specify one to be used
// by specifying flag.
scheduler.RegisterAlgorithmProvider(scheduler.DefaultProvider, predSet, priSet)
// Cluster autoscaler friendly scheduling algorithm.
scheduler.RegisterAlgorithmProvider(ClusterAutoscalerProvider, predSet,
copyAndReplace(priSet, priorities.LeastRequestedPriority, priorities.MostRequestedPriority))
}
最终将注册的algorithm provider赋值给变量algorithmProviderMap(存储了所有类型的调度算法列表),该变量是该包的全局变量。
// pkg/scheduler/algorithm_factory.go
// RegisterAlgorithmProvider registers a new algorithm provider with the algorithm registry.
func RegisterAlgorithmProvider(name string, predicateKeys, priorityKeys sets.String) string {
schedulerFactoryMutex.Lock()
defer schedulerFactoryMutex.Unlock()
validateAlgorithmNameOrDie(name)
algorithmProviderMap[name] = AlgorithmProviderConfig{
FitPredicateKeys: predicateKeys,
PriorityFunctionKeys: priorityKeys,
}
return name
}
// pkg/scheduler/algorithm_factory.go
var (
...
algorithmProviderMap = make(map[string]AlgorithmProviderConfig)
...
)
(2)再来看到defaults包中register_predicates.go文件的init函数,主要是注册了预选算法。
// pkg/scheduler/algorithmprovider/defaults/register_predicates.go
func init() {
...
// Fit is defined based on the absence of port conflicts.
// This predicate is actually a default predicate, because it is invoked from
// predicates.GeneralPredicates()
scheduler.RegisterFitPredicate(predicates.PodFitsHostPortsPred, predicates.PodFitsHostPorts)
// Fit is determined by resource availability.
// This predicate is actually a default predicate, because it is invoked from
// predicates.GeneralPredicates()
scheduler.RegisterFitPredicate(predicates.PodFitsResourcesPred, predicates.PodFitsResources)
...
(3)最后看到defaults包中register_priorities.go文件的init函数,主要是注册了优选算法。
// pkg/scheduler/algorithmprovider/defaults/register_priorities.go
func init() {
...
// Prioritize nodes by least requested utilization.
scheduler.RegisterPriorityMapReduceFunction(priorities.LeastRequestedPriority, priorities.LeastRequestedPriorityMap, nil, 1)
// Prioritizes nodes to help achieve balanced resource usage
scheduler.RegisterPriorityMapReduceFunction(priorities.BalancedResourceAllocation, priorities.BalancedResourceAllocationMap, nil, 1)
...
}
预选算法与优选算法注册的最后结果,都是赋值给全局变量,预选算法注册后赋值给fitPredicateMap,优选算法注册后赋值给priorityFunctionMap。
// pkg/scheduler/algorithm_factory.go
var (
...
fitPredicateMap = make(map[string]FitPredicateFactory)
...
priorityFunctionMap = make(map[string]PriorityConfigFactory)
...
)
1.1.2 defaults.ApplyFeatureGates
主要用于判断是否开启特定的FeatureGate,然后追加注册相应的预选和优选算法。
// pkg/scheduler/algorithmprovider/defaults/defaults.go
func ApplyFeatureGates() (restore func()) {
...
// Only register EvenPodsSpread predicate & priority if the feature is enabled
if utilfeature.DefaultFeatureGate.Enabled(features.EvenPodsSpread) {
klog.Infof("Registering EvenPodsSpread predicate and priority function")
// register predicate
scheduler.InsertPredicateKeyToAlgorithmProviderMap(predicates.EvenPodsSpreadPred)
scheduler.RegisterFitPredicate(predicates.EvenPodsSpreadPred, predicates.EvenPodsSpreadPredicate)
// register priority
scheduler.InsertPriorityKeyToAlgorithmProviderMap(priorities.EvenPodsSpreadPriority)
scheduler.RegisterPriorityMapReduceFunction(
priorities.EvenPodsSpreadPriority,
priorities.CalculateEvenPodsSpreadPriorityMap,
priorities.CalculateEvenPodsSpreadPriorityReduce,
1,
)
}
// Prioritizes nodes that satisfy pod's resource limits
if utilfeature.DefaultFeatureGate.Enabled(features.ResourceLimitsPriorityFunction) {
klog.Infof("Registering resourcelimits priority function")
scheduler.RegisterPriorityMapReduceFunction(priorities.ResourceLimitsPriority, priorities.ResourceLimitsPriorityMap, nil, 1)
// Register the priority function to specific provider too.
scheduler.InsertPriorityKeyToAlgorithmProviderMap(scheduler.RegisterPriorityMapReduceFunction(priorities.ResourceLimitsPriority, priorities.ResourceLimitsPriorityMap, nil, 1))
}
...
}
1.2 Run
Run函数主要是根据配置参数,运行启动kube-scheduler组件,其核心逻辑如下:
(1)准备好event上报client,用于将kube-scheduler产生的各种event上报给api-server;
(2)调用scheduler.New方法,实例化scheduler对象;
(3)启动event上报管理器;
(4)设置kube-scheduler组件的健康检查,并启动健康检查以及与metrics相关的http服务;
(5)启动所有前面注册过的对象的infomer,开始同步对象资源;
(6)调用WaitForCacheSync,等待所有informer的对象同步完成,使得本地缓存数据与etcd中的数据一致;
(7)根据组件启动参数判断是否要开启leader选举功能;
(8)调用sched.Run方法启动kube-scheduler组件(sched.Run将作为下面kube-scheduler核心处理逻辑分析的入口)。
// cmd/kube-scheduler/app/server.go
func Run(ctx context.Context, cc schedulerserverconfig.CompletedConfig, outOfTreeRegistryOptions ...Option) error {
// To help debugging, immediately log version
klog.V(1).Infof("Starting Kubernetes Scheduler version %+v", version.Get())
outOfTreeRegistry := make(framework.Registry)
for _, option := range outOfTreeRegistryOptions {
if err := option(outOfTreeRegistry); err != nil {
return err
}
}
// 1.准备好event上报client,用于将kube-scheduler产生的各种event上报给api-server
// Prepare event clients.
if _, err := cc.Client.Discovery().ServerResourcesForGroupVersion(eventsv1beta1.SchemeGroupVersion.String()); err == nil {
cc.Broadcaster = events.NewBroadcaster(&events.EventSinkImpl{Interface: cc.EventClient.Events("")})
cc.Recorder = cc.Broadcaster.NewRecorder(scheme.Scheme, cc.ComponentConfig.SchedulerName)
} else {
recorder := cc.CoreBroadcaster.NewRecorder(scheme.Scheme, v1.EventSource{Component: cc.ComponentConfig.SchedulerName})
cc.Recorder = record.NewEventRecorderAdapter(recorder)
}
// 2.调用scheduler.New方法,实例化scheduler对象
// Create the scheduler.
sched, err := scheduler.New(cc.Client,
cc.InformerFactory,
cc.PodInformer,
cc.Recorder,
ctx.Done(),
scheduler.WithName(cc.ComponentConfig.SchedulerName),
scheduler.WithAlgorithmSource(cc.ComponentConfig.AlgorithmSource),
scheduler.WithHardPodAffinitySymmetricWeight(cc.ComponentConfig.HardPodAffinitySymmetricWeight),
scheduler.WithPreemptionDisabled(cc.ComponentConfig.DisablePreemption),
scheduler.WithPercentageOfNodesToScore(cc.ComponentConfig.PercentageOfNodesToScore),
scheduler.WithBindTimeoutSeconds(cc.ComponentConfig.BindTimeoutSeconds),
scheduler.WithFrameworkOutOfTreeRegistry(outOfTreeRegistry),
scheduler.WithFrameworkPlugins(cc.ComponentConfig.Plugins),
scheduler.WithFrameworkPluginConfig(cc.ComponentConfig.PluginConfig),
scheduler.WithPodMaxBackoffSeconds(cc.ComponentConfig.PodMaxBackoffSeconds),
scheduler.WithPodInitialBackoffSeconds(cc.ComponentConfig.PodInitialBackoffSeconds),
)
if err != nil {
return err
}
// 3.启动event上报管理器
// Prepare the event broadcaster.
if cc.Broadcaster != nil && cc.EventClient != nil {
cc.Broadcaster.StartRecordingToSink(ctx.Done())
}
if cc.CoreBroadcaster != nil && cc.CoreEventClient != nil {
cc.CoreBroadcaster.StartRecordingToSink(&corev1.EventSinkImpl{Interface: cc.CoreEventClient.Events("")})
}
// 4.设置kube-scheduler组件的健康检查,并启动健康检查以及与metrics相关的http服务
// Setup healthz checks.
var checks []healthz.HealthChecker
if cc.ComponentConfig.LeaderElection.LeaderElect {
checks = append(checks, cc.LeaderElection.WatchDog)
}
// Start up the healthz server.
if cc.InsecureServing != nil {
separateMetrics := cc.InsecureMetricsServing != nil
handler := buildHandlerChain(newHealthzHandler(&cc.ComponentConfig, separateMetrics, checks...), nil, nil)
if err := cc.InsecureServing.Serve(handler, 0, ctx.Done()); err != nil {
return fmt.Errorf("failed to start healthz server: %v", err)
}
}
if cc.InsecureMetricsServing != nil {
handler := buildHandlerChain(newMetricsHandler(&cc.ComponentConfig), nil, nil)
if err := cc.InsecureMetricsServing.Serve(handler, 0, ctx.Done()); err != nil {
return fmt.Errorf("failed to start metrics server: %v", err)
}
}
if cc.SecureServing != nil {
handler := buildHandlerChain(newHealthzHandler(&cc.ComponentConfig, false, checks...), cc.Authentication.Authenticator, cc.Authorization.Authorizer)
// TODO: handle stoppedCh returned by c.SecureServing.Serve
if _, err := cc.SecureServing.Serve(handler, 0, ctx.Done()); err != nil {
// fail early for secure handlers, removing the old error loop from above
return fmt.Errorf("failed to start secure server: %v", err)
}
}
// 5.启动所有前面注册过的对象的informer,开始同步对象资源
// Start all informers.
go cc.PodInformer.Informer().Run(ctx.Done())
cc.InformerFactory.Start(ctx.Done())
// 6.等待所有informer的对象同步完成,使得本地缓存数据与etcd中的数据一致
// Wait for all caches to sync before scheduling.
cc.InformerFactory.WaitForCacheSync(ctx.Done())
// 7.根据组件启动参数判断是否要开启leader选举功能
// If leader election is enabled, runCommand via LeaderElector until done and exit.
if cc.LeaderElection != nil {
cc.LeaderElection.Callbacks = leaderelection.LeaderCallbacks{
OnStartedLeading: sched.Run,
OnStoppedLeading: func() {
klog.Fatalf("leaderelection lost")
},
}
leaderElector, err := leaderelection.NewLeaderElector(*cc.LeaderElection)
if err != nil {
return fmt.Errorf("couldn't create leader elector: %v", err)
}
leaderElector.Run(ctx)
return fmt.Errorf("lost lease")
}
// 8.调用sched.Run方法启动kube-scheduler组件
// Leader election is disabled, so runCommand inline until done.
sched.Run(ctx)
return fmt.Errorf("finished without leader elect")
}
1.2.1 scheduler.New
scheduler对象的实例化分为3个部分,分别是:
(1)实例化pod、node、pvc、pv等对象的infomer;
(2)调用configurator.CreateFromConfig,根据前面注册的内置调度算法(或根据用户提供的调度策略),实例化scheduler;
(3)给infomer对象注册eventHandler;
// pkg/scheduler/scheduler.go
func New(client clientset.Interface,
informerFactory informers.SharedInformerFactory,
podInformer coreinformers.PodInformer,
recorder events.EventRecorder,
stopCh <-chan struct{},
opts ...Option) (*Scheduler, error) {
stopEverything := stopCh
if stopEverything == nil {
stopEverything = wait.NeverStop
}
options := defaultSchedulerOptions
for _, opt := range opts {
opt(&options)
}
// 1.实例化node、pvc、pv等对象的infomer
schedulerCache := internalcache.New(30*time.Second, stopEverything)
volumeBinder := volumebinder.NewVolumeBinder(
client,
informerFactory.Core().V1().Nodes(),
informerFactory.Storage().V1().CSINodes(),
informerFactory.Core().V1().PersistentVolumeClaims(),
informerFactory.Core().V1().PersistentVolumes(),
informerFactory.Storage().V1().StorageClasses(),
time.Duration(options.bindTimeoutSeconds)*time.Second,
)
registry := options.frameworkDefaultRegistry
if registry == nil {
registry = frameworkplugins.NewDefaultRegistry(&frameworkplugins.RegistryArgs{
VolumeBinder: volumeBinder,
})
}
registry.Merge(options.frameworkOutOfTreeRegistry)
snapshot := nodeinfosnapshot.NewEmptySnapshot()
configurator := &Configurator{
client: client,
informerFactory: informerFactory,
podInformer: podInformer,
volumeBinder: volumeBinder,
schedulerCache: schedulerCache,
StopEverything: stopEverything,
hardPodAffinitySymmetricWeight: options.hardPodAffinitySymmetricWeight,
disablePreemption: options.disablePreemption,
percentageOfNodesToScore: options.percentageOfNodesToScore,
bindTimeoutSeconds: options.bindTimeoutSeconds,
podInitialBackoffSeconds: options.podInitialBackoffSeconds,
podMaxBackoffSeconds: options.podMaxBackoffSeconds,
enableNonPreempting: utilfeature.DefaultFeatureGate.Enabled(kubefeatures.NonPreemptingPriority),
registry: registry,
plugins: options.frameworkPlugins,
pluginConfig: options.frameworkPluginConfig,
pluginConfigProducerRegistry: options.frameworkConfigProducerRegistry,
nodeInfoSnapshot: snapshot,
algorithmFactoryArgs: AlgorithmFactoryArgs{
SharedLister: snapshot,
InformerFactory: informerFactory,
VolumeBinder: volumeBinder,
HardPodAffinitySymmetricWeight: options.hardPodAffinitySymmetricWeight,
},
configProducerArgs: &frameworkplugins.ConfigProducerArgs{},
}
metrics.Register()
// 2.调用configurator.CreateFromConfig,根据前面注册的内置调度算法(或根据用户提供的调度策略),实例化scheduler
var sched *Scheduler
source := options.schedulerAlgorithmSource
switch {
case source.Provider != nil:
// Create the config from a named algorithm provider.
sc, err := configurator.CreateFromProvider(*source.Provider)
if err != nil {
return nil, fmt.Errorf("couldn't create scheduler using provider %q: %v", *source.Provider, err)
}
sched = sc
case source.Policy != nil:
// Create the config from a user specified policy source.
policy := &schedulerapi.Policy{}
switch {
case source.Policy.File != nil:
if err := initPolicyFromFile(source.Policy.File.Path, policy); err != nil {
return nil, err
}
case source.Policy.ConfigMap != nil:
if err := initPolicyFromConfigMap(client, source.Policy.ConfigMap, policy); err != nil {
return nil, err
}
}
sc, err := configurator.CreateFromConfig(*policy)
if err != nil {
return nil, fmt.Errorf("couldn't create scheduler from policy: %v", err)
}
sched = sc
default:
return nil, fmt.Errorf("unsupported algorithm source: %v", source)
}
// Additional tweaks to the config produced by the configurator.
sched.Recorder = recorder
sched.DisablePreemption = options.disablePreemption
sched.StopEverything = stopEverything
sched.podConditionUpdater = &podConditionUpdaterImpl{client}
sched.podPreemptor = &podPreemptorImpl{client}
sched.scheduledPodsHasSynced = podInformer.Informer().HasSynced
// 3.给infomer对象注册eventHandler
AddAllEventHandlers(sched, options.schedulerName, informerFactory, podInformer)
return sched, nil
}
总结
kube-scheduler简介
kube-scheduler组件是kubernetes中的核心组件之一,主要负责pod资源对象的调度工作,具体来说,kube-scheduler组件负责根据调度算法(包括预选算法和优选算法)将未调度的pod调度到合适的最优的node节点上。
kube-scheduler架构图
kube-scheduler的大致组成和处理流程如下图,kube-scheduler对pod、node等对象进行了list/watch,根据informer将未调度的pod放入待调度pod队列,并根据informer构建调度器cache(用于快速获取需要的node等对象),然后sched.scheduleOne方法为kube-scheduler组件调度pod的核心处理逻辑所在,从未调度pod队列中取出一个pod,经过预选与优选算法,最终选出一个最优node,然后更新cache并异步执行bind操作,也就是更新pod的nodeName字段,至此一个pod的调度工作完成。
kube-scheduler初始化与启动分析流程图