引言
JDK 1.4 之后引入了NIO(New IO或 Non Blocking IO),我觉的可以称其为New IO,因为NIO基本重写所有标准IO的API,完全可以替代标准的Java IO API。并且NIO支持面向缓冲区(Buffer)的、基于通道(Channel)的IO操作,可以以更加高效的方式进行文件的读写操作。
NIO的核心主要包括3部分
- Buffer 缓冲区
- Channel 通道
- 文件通道
- Socket通道
- Selector 选择器
本篇文章会对NIOBuffer缓冲区的使用及实现原理做分析
体系
Java NIO 提供了以下几种Buffer类型可供使用
- ByteBuffer
- MappedByteBuffer
- CharBuffer
- DoubleBuffer
- FloatBuffer
- IntBuffer
- LongBuffer
- ShortBuffer
这些Buffer的名字已经非常清晰的指明了这些Buffer所各自承载的不同数据类型
下面的分析我都将以ByteBuffer为例子
基本使用
ByteBuffer的使用比较简单,但若不理解其内部实现原理,也非常容易搞混。我们先来介绍其简单的使用
创建缓冲区
创建缓冲区主要有两种常用方式
- allocate 开辟指定大小的缓冲区
- wrap 使用字节数组开辟新的缓冲区,对缓冲区的修改将导致数组被修改。新缓冲区的容量(position)和限制(limit)将为该数组的长度
// 通过 allocate 创建
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
// 通过 wrap 创建
byte [] buf = new byte[1024];
ByteBuffer.wrap(buf);
读写数据
使用ByteBuffer读写数据比较简单
写数据
往Buffer中写数据只需要调用put方法,该方法有多个重载,可以以不同的方式写数据
这里只列举3个
- put(byte b) 在当前位置将给定字节写入此缓冲区
- put(int i, byte b) 在指定位置将给定字节写入此缓冲区
- put(byte[] src, int offset, int length) 将字节从给定源数组传输到此缓冲区。如果从数组复制的字节比数大于剩余的缓冲区容量,会抛出
BufferOverflowException异常
读数据
从Buffer中读取数据只需要调用get方法,该方法同样有多个重载,可以以不同的方式读数据
- get() 获取当前位置的单个字节
- get(int i) 获取指定位置的单个字节
- get(byte[] dst, int offset, int length) 从此缓冲区中获取字节并传输到给定的目标数组中,如果缓冲区中的剩余字节少于满足请求所需的字节数,会抛出
BufferUnderflowException异常
下面是一个抛出BufferUnderflowException的例子
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
String s = "hello";
byteBuffer.put(s.getBytes());
byteBuffer.flip(); // 翻转 下文会提到
byte [] bufs = new byte[9]; // 缓冲区实际只有5个字节大小,大于此大小就会抛出异常
byteBuffer.get(bufs); // 抛出异常
flip 方法
上文抛出BufferUnderflowException的例子,不知道大家有没发现,我们的代码在读写转换时用了flip方法来进行读写操作的转换,缓冲区在进行读写转换的时候必须调用flip方法,那么为何要这么做呢?下面我将会对flip方法的内部实现原理进行分析,在分析之前,我们有必要先认识一下Buffer的capacity position limit mark四个变量属性
- capacity 表示缓冲区的容量,大小不可变且不可为负
- position 下一个要读取或写入的元素的位置索引
- limit 下一个不应该被读取或写入的元素的位置索引
- mark 标记位,可以通过这个标记位返回此位置
四者的大小关系 mark <= position <= limit <= capacity
知道了这四个变量的含义之后,我们再来根据例子来看看一步一步往下分析吧
一. 首先,我们通过ByteBuffer.allocate(6)开辟一个大小为6的缓冲区
// 通过allocate 开辟缓冲区
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}
// HeapByteBuffer 初始化
HeapByteBuffer(int cap, int lim) { // package-private
// 这里前四个参数依次是 mark position limit capacity
super(-1, 0, lim, cap, new byte[cap], 0);
}
通过查看allocate方法的源码,可知其内部初始结构如下图(Buffer内部其实是数组实现,下标从0开始)
- mark = -1
- position = 0
- limit = capacity = 6

二. 然后我们现在通过put方法加入1个字节数据
此时的内部结构如下图
- mark = -1
- position = 1
- limit = capacity = 6
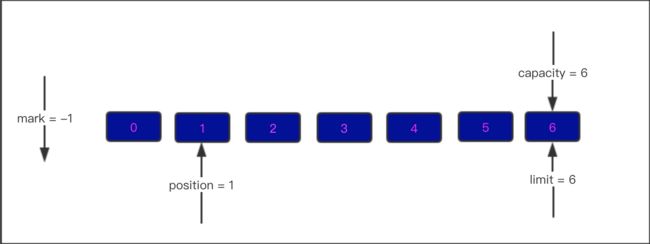
三. 加一个太少了,我们再添加3个字节数据至缓冲区中
此时的内部结构如下图
- mark = -1
- position = 4
- limit = capacity = 6
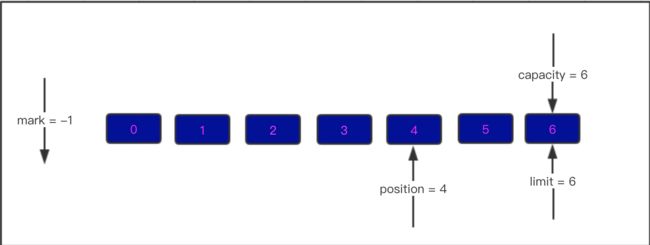
四. 现在数据已经全部加完了,我们准备读数据了,必须要调用flip方法
先来看看flip方法的内部实现
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
flip内部其实是将 position的值赋给了limit,并将position位置归0,如下图显示
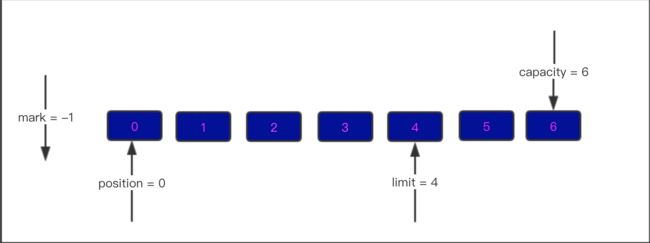
五. 成功翻转之后,就可以往外读数据了,假设往外读4个数据
此时内部结构如下图,并且 position = limit了,达到了最大可读字节数
- mark = -1
- position = 4
- limit = 4
-
capacity = 6
 image.png
image.png
通过上面这个例子,对flip方法的翻转逻辑已经进行了非常详细的分析,并且可以得出结论capacity的是绝对不变的,不会随着读写操作而改变。mark变量的值会在下文reset mark 方法中用到
reset mark 方法
顾名思义,mark就是打标记的意思,reset表示重置的意思。这两个操做是紧密联系的,由mark()方法在当前position位置做标记,然后在需要重置到标记位置的时候,调用reset方法重置
看一下这两个方法的内部实现
public final Buffer mark() {
mark = position;
return this;
}
public final Buffer reset() {
int m = mark;
if (m < 0)
throw new InvalidMarkException();
position = m;
return this;
}
方法的内部实现非常简单,通过对变量mark的编辑来标记当前位置,在需要重置的时候,把变量mark的值赋给当前下标索引position来达到重置的目的。
clear
clear方法比较简单,将position = 0,limit = capacity,mark = -1。有点类似初始化时的操作
compact
最后再来介绍一下compact方法,首先我们先来看一个场景
while (in.read(buf) >= 0 || buf.position != 0) {
buf.flip();
out.write(buf);
buf.clear();
}
上面这个例子,在非阻塞模式下是会有问题的,因为write方法我们并不知道一次性可以写多少个字节,所以有可能还有未写入的字节数据,这时候我们却又重新读取了新的数据,就会导致覆盖了原有还未写入的数据。
只需要改成以下的方式即可,该方法的作用是将position与limit之间的数据复制到buffer的开始位置,复制后position = limit -position,limit = capacity
while (in.read(buf) >= 0 || buf.position != 0) {
buf.flip();
out.write(buf);
buf.compact();
}
总结
本编文章比较详细的分析了Java NIOBuffer的基本使用及内部实现原理。Buffer的内部实现其实比较简单,需要着重理解的其实就是capacity position limit mark这四个变量属性。
博客原文地址戳这里