什么是 Seq2Seq ?
Seq2Seq 是一个 Encoder-Decoder 结构的神经网络,它的输入是一个序列(Sequence),输出也是一个序列(Sequence),因此而得名 “Seq2Seq”。在 Encoder 中,将可变长度的序列转变为固定长度的向量表达,Decoder 将这个固定长度的向量转换为可变长度的目标的信号序列。*

最基础的 Seq2Seq模型 包含了三个部分(上图有一部分没有显示的标明),即 Encoder、Decoder 以及连接两者的中间状态向量 C,Encoder通过学习输入,将其编码成一个固定大小的状态向量 C(也称为语义编码),继而将 C 传给Decoder,Decoder再通过对状态向量 C 的学习来进行输出对应的序列。
Basic Seq2Seq 是有很多弊端的,首先 Encoder 将输入编码为固定大小状态向量(hidden state)的过程实际上是一个“信息有损压缩”的过程。如果信息量越大,那么这个转化向量的过程对信息造成的损失就越大。同时,随着 sequence length的增加,意味着时间维度上的序列很长,RNN 模型也会出现梯度弥散。最后,基础的模型连接 Encoder 和 Decoder 模块的组件仅仅是一个固定大小的状态向量,这使得Decoder无法直接去关注到输入信息的更多细节。由于 Basic Seq2Seq 的种种缺陷,随后引入了 Attention 的概念以及 Bi-directional encoder layer 等,能够取得更好的表现。
基本的Attention原理。
https://zhuanlan.zhihu.com/p/137578323
单纯的Encoder-Decoder 框架并不能有效的聚焦到输入目标上,这使得像 seq2seq 的模型在独自使用时并不能发挥最大功效。比如说在上图中,编码器将输入编码成上下文变量 C,在解码时每一个输出 Y 都会不加区分的使用这个 C 进行解码。而注意力模型要做的事就是根据序列的每个时间步将编码器编码为不同 C,在解码时,结合每个不同的 C 进行解码输出,这样得到的结果会更加准确,如下所示:

近几年来,深度学习与视觉注意力机制结合的研究工作,大多数是集中于使用掩码(mask)来形成注意力机制。掩码的原理在于
通过另一层新的权重,将图片数据中关键的特征标识出来,通过学习训练,让深度神经网络学到每一张新图片中需要关注的区域,也就形成了注意力。
这种思想,进而演化成两种不同类型的注意力,一种是软注意力(soft attention),另一种则是强注意力(hard attention)。
软注意力
的关键点在于,这种注意力更关注区域[4]或者通道[5],
而且软注意力是确定性的注意力,学习完成后直接可以通过网络生成,
最关键的地方是软注意力是可微的,这是一个非常重要的地方。可以微分的注意力就可以通过神经网络算出梯度并且前向传播和后向反馈来学习得到注意力的权重[6]。
强注意力[7]
与软注意力不同点在于,首先强注意力是更加关注点,也就是图像中的每个点都有可能延伸出注意力,
同时强注意力是一个随机的预测过程,更强调动态变化。
当然,最关键是强注意力是一个不可微的注意力,训练过程往往是通过增强学习(reinforcement learning)来完成的。
为了更清楚地介绍计算机视觉中的注意力机制,这篇文章将从注意力域(attention domain)的角度来分析几种注意力的实现方法。其中主要是三种注意力域,空间域(spatial domain),通道域(channel domain),混合域(mixed domain)。还有另一种比较特殊的强注意力实现的注意力域,时间域(time domain),但是因为强注意力是使用reinforcement learning来实现的,训练起来有所不同,所以之后再详细分析。
软注意力的注意力域
每篇文章的介绍分为两个部分,首先从想法上来介绍模型的设计思路,然后深入了解模型结构(architecture)部分。
3.1 空间域(Spatial Domain)
设计思路:
Spatial Transformer Networks(STN)模型[4]通过注意力机制,将原始图片中的空间信息变换到另一个空间中并保留了关键信息。
这篇文章的思想非常巧妙,因为卷积神经网络中的池化层(pooling layer)直接用一些max pooling 或者average pooling 的方法,将图片信息压缩,减少运算量提升准确率。这篇文章认为之前pooling的方法太过于暴力,直接将信息合并会导致关键信息无法识别出来,所以提出了一个叫空间转换器(spatial transformer)的模块,将图片中的的空间域信息做对应的空间变换,从而能将关键的信息提取出来与池化层不同,在池化层中,接收fields是固定的和局部的,空间转换器模块是一种动态机制,可以通过为每个输入样本生成适当的变换来主动对图像(或特征图)进行空间变换。
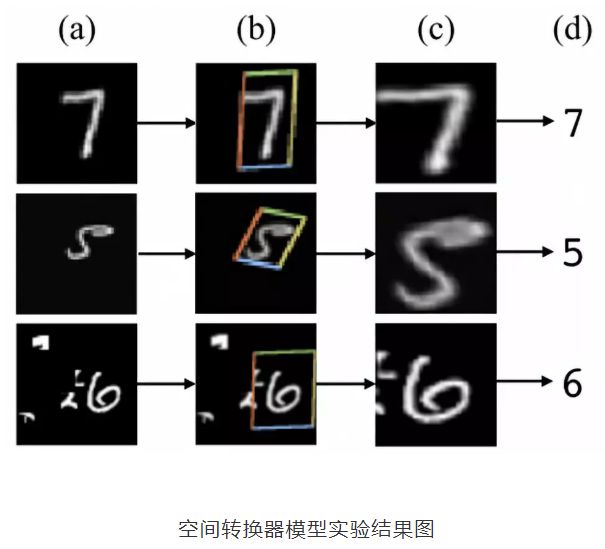
(a)列是原始的图片信息,其中第一个手写数字7没有做任何变换,第二个手写数字5,做了一定的旋转变化,而第三个手写数字6,加上了一些噪声信号;
(b)列中的彩色边框是学习到的spatial transformer的框盒(bounding box),每一个框盒其实就是对应图片学习出来的一个spatial transformer;
(c)列中是通过spatial transformer转换之后的特征图,可以看出7的关键区域被选择出来,5被旋转成为了正向的图片,6的噪声信息没有被识别进入。
最终可以通过这些转换后的特征图来预测出(d)列中手写数字的数值。

这是空间变换网络(spatialtransformer network)中最重要的空间变换模块,这个模块可以作为新的层直接加入到原有的网络结构,比如ResNet中。
来仔细研究这个模型的输入: 神经网络训练中使用的数据类型都是张量(tensor),H是上一层tensor的高度(height),W是上一层tensor的宽度(width),而C代表tensor的通道(channel),比如图片基本的三通道(RGB),或者是经过卷积层(convolutional layer)之后,不同卷积核(kernel)都会产生不同的通道信息。 之后这个输入进入两条路线,一条路线是信息进入定位网络(localisation net),另一条路线是原始信号直接进入采样层(sampler)。其中定位网络会学习到一组参数,而这组参数就能够作为网格生成器(grid generator)的参数,生成一个采样信号,这个采样信号其实是一个变换矩阵,与原始图片相乘之后,可以得到变换之后的矩阵
就是变换之后的图片特征了,变换之后的矩阵大小是可以通过调节变换矩阵来形成缩放的。

通过这张转换图片,可以看出空间转换器中产生的采样矩阵是能够将原图中关键的信号提取出来,(a)中的采样矩阵是单位矩阵,不做任何变换,(b)中的矩阵是可以产生缩放旋转变换的采样矩阵
![\left(\begin{array}{c}{x_{i}^{s}} \\ {y_{i}^{s}}\end{array}\right)=\mathcal{T}_{\theta}\left(G_{i}\right)=\mathrm{A}_{\theta}\left(\begin{array}{c}{x_{i}^{t}} \\ {y_{i}^{t}} \\ {1}\end{array}\right)=\left[\begin{array}{ccc}{\theta_{11}} & {\theta_{12}} & {\theta_{13}} \\ {\theta_{21}} & {\theta_{22}} & {\theta_{23}}\end{array}\right]\left(\begin{array}{c}{x_{i}^{t}} \\ {y_{i}^{t}} \\ {1}\end{array}\right)](https://math.jianshu.com/math?formula=%5Cleft(%5Cbegin%7Barray%7D%7Bc%7D%7Bx_%7Bi%7D%5E%7Bs%7D%7D%20%5C%5C%20%7By_%7Bi%7D%5E%7Bs%7D%7D%5Cend%7Barray%7D%5Cright)%3D%5Cmathcal%7BT%7D_%7B%5Ctheta%7D%5Cleft(G_%7Bi%7D%5Cright)%3D%5Cmathrm%7BA%7D_%7B%5Ctheta%7D%5Cleft(%5Cbegin%7Barray%7D%7Bc%7D%7Bx_%7Bi%7D%5E%7Bt%7D%7D%20%5C%5C%20%7By_%7Bi%7D%5E%7Bt%7D%7D%20%5C%5C%20%7B1%7D%5Cend%7Barray%7D%5Cright)%3D%5Cleft%5B%5Cbegin%7Barray%7D%7Bccc%7D%7B%5Ctheta_%7B11%7D%7D%20%26%20%7B%5Ctheta_%7B12%7D%7D%20%26%20%7B%5Ctheta_%7B13%7D%7D%20%5C%5C%20%7B%5Ctheta_%7B21%7D%7D%20%26%20%7B%5Ctheta_%7B22%7D%7D%20%26%20%7B%5Ctheta_%7B23%7D%7D%5Cend%7Barray%7D%5Cright%5D%5Cleft(%5Cbegin%7Barray%7D%7Bc%7D%7Bx_%7Bi%7D%5E%7Bt%7D%7D%20%5C%5C%20%7By_%7Bi%7D%5E%7Bt%7D%7D%20%5C%5C%20%7B1%7D%5Cend%7Barray%7D%5Cright))
最右边式子左边的θ矩阵就是对应的采样矩阵。
这个模块加进去最大的好处就是能够对上一层信号的关键信息进行识别(attention),并且该信息矩阵是一个可以微分的矩阵,因为每一个目标(target)点的信息其实是所有源(source)点信息的一个组合,这个组合可以是一个线性组合,复杂的变换信息也可以用核函数(kernel)来表示:
![V_{i}^{c}=\sum_{n}^{H} \sum_{m}^{W} U_{n m}^{c} k\left(x_{i}^{s}-m ; \Phi_{x}\right) k\left(y_{i}^{s}-n ; \Phi_{y}\right) \forall i \in\left[1 \ldots H^{\prime} W^{\prime}\right] \forall c \in[1 \ldots C]](https://math.jianshu.com/math?formula=V_%7Bi%7D%5E%7Bc%7D%3D%5Csum_%7Bn%7D%5E%7BH%7D%20%5Csum_%7Bm%7D%5E%7BW%7D%20U_%7Bn%20m%7D%5E%7Bc%7D%20k%5Cleft(x_%7Bi%7D%5E%7Bs%7D-m%20%3B%20%5CPhi_%7Bx%7D%5Cright)%20k%5Cleft(y_%7Bi%7D%5E%7Bs%7D-n%20%3B%20%5CPhi_%7By%7D%5Cright)%20%5Cforall%20i%20%5Cin%5Cleft%5B1%20%5Cldots%20H%5E%7B%5Cprime%7D%20W%5E%7B%5Cprime%7D%5Cright%5D%20%5Cforall%20c%20%5Cin%5B1%20%5Cldots%20C%5D)
V是转换后的信息,U是转换前的信息,k是一个核函数。
理论上来说,这样的模块是可以加在任意层的,因为模块可以同时对通道信息和矩阵信息同时处理。但是由于文章提出对所有的通道信息进行统一处理变换,我认为这种模块其实更适用于原始图片输入层之后的变化,因为卷积层之后,每一个卷积核(filter)产生的通道信息,所含有的信息量以及重要程度其实是不一样的,都用同样的transformer其实可解释性并不强。也由此,我们可以引出第二种注意域的机制——通道域(channel domain)注意力机制。
3.2 通道域(Channel Domain)
通道域[5]的注意力机制原理很简单,我们可以从基本的信号变换的角度去理解。信号系统分析里面,任何一个信号其实都可以写成正弦波的线性组合,经过时频变换<一般是使用傅里叶变换,也是卷积变化>之后,时域上连续的正弦波信号就可以用一个频率信号数值代替了。

在卷积神经网络中,每一张图片初始会由(R,G,B)三通道表示出来,之后经过不同的卷积核之后,每一个通道又会生成新的信号,比如图片特征的每个通道使用64核卷积,就会产生64个新通道的矩阵(H,W,64),H,W分别表示图片特征的高度和宽度。每个通道的特征其实就表示该图片在不同卷积核上的分量,类似于时频变换,而这里面用卷积核的卷积类似于信号做了傅里叶变换,从而能够将这个特征一个通道的信息给分解成64个卷积核上的信号分量。
既然每个信号都可以被分解成核函数上的分量,产生的新的64个通道对于关键信息的贡献肯定有多有少,如果我们给每个通道上的信号都增加一个权重,来代表该通道与关键信息的相关度的话,这个权重越大,则表示相关度越高,也就是我们越需要去注意的通道了。
模型结构:
论文[5]中提出了一个非常重要的SENet的模型结构,靠着这个模型获得了ImageNet的冠军,这个模型是非常有创造力的设计。

首先最左边是原始输入图片特征X,然后经过变换,比如卷积变换 ,产生了新的特征信号U。U有C个通道,我们希望通过注意力模块来学习出每个通道的权重,从而产生通道域的注意力。中间的模块就是SENet的创新部分,也就是注意力机制模块。这个注意力机制分成三个部分:挤压(squeeze),激励(excitation),以及注意(attention)。
挤压函数 :
很明显这个函数做了一个全局平均值,把每个通道内所有的特征值相加再平均,也是全局平均池化(global average pooling)的数学表达式。
激励函数 :
函数是ReLU,而是一个sigmoid激活函数。W1和W2的维度分别是
尺度函数 :
这一步其实就是一个放缩的过程,不同通道的值乘上不同的权重,从而可以增强对关键通道域的注意力。
3.3 混合域
了解前两种注意力域的设计思路后,简单对比一下。首先,空间域的注意力是忽略了通道域中的信息,将每个通道中的图片特征同等处理,这种做法会将空间域变换方法局限在原始图片特征提取阶段,应用在神经网络层其他层的可解释性不强。
而通道域的注意力是对一个通道内的信息直接全局平均池化,而忽略每一个通道内的局部信息,这种做法其实也是比较暴力的行为。所以结合两种思路,就可以设计出混合域的注意力机制模型[8]。
设计思路:
[8]这篇文章中提出的注意力机制是与深度残差网络(Deep Residual Network)相关的方法,基本思路是能够将注意力机制应用到ResNet中,并且使网络能够训练的比较深。
文章中注意力的机制是软注意力基本的加掩码(mask)机制,但是不同的是,这种注意力机制的mask借鉴了残差网络的想法,不只根据当前网络层的信息加上mask,还把上一层的信息传递下来,这样就防止mask之后的信息量过少引起的网络层数不能堆叠很深的问题。
正如之前说的,[8]中提出的注意力mask,不仅仅只是对空间域或者通道域注意,这种mask可以看作是每一个特征元素(element)的权重。通过给每个特征元素都找到其对应的注意力权重,就可以同时形成了空间域和通道域的注意力机制。
很多人看到这里就会有疑问,这种做法应该是从空间域或者通道域非常自然的一个过渡,怎么做单一域注意力的人都没有想到呢?原因有:
- 如果你给每一个特征元素都赋予一个mask权重的话,mask之后的信息就会非常少,可能直接就破坏了网络深层的特征信息;
- 另外,如果你可以加上注意力机制之后,残差单元(Residual Unit)的恒等映射(identical mapping)特性会被破坏,从而很难训练。
首先,使用mask重复地从0到1的点产生会降低深层特征的值。其次,软mask可能会破坏主干分支的良好特性,例如残差单元的相同映射。
所以该文章的注意力机制的创新点在于提出了残差注意力学习(residual attention learning),不仅只把mask之后的特征张量作为下一层的输入,同时也将mask之前的特征张量作为下一层的输入,这时候可以得到的特征更为丰富,从而能够更好的注意关键特征。
模型结构:

文章中模型结构是非常清晰的,整体结构上,是三阶注意力模块(3-stage attention module)。每一个注意力模块可以分成两个分支(看stage2),上面的分支叫主分支(trunk branch),是基本的残差网络(ResNet)的结构。而下面的分支是软掩码分支(soft mask branch),而软掩码分支中包含的主要部分就是残差注意力学习机制。通过下采样(down sampling)和上采样(up sampling),以及残差模块(residual unit),组成了注意力的机制。
模型结构中比较创新的残差注意力机制是:
H是注意力模块的输出,F是上一层的图片张量特征,M是软掩码的注意力参数。这就构成了残差注意力模块,能将图片特征和加强注意力之后的特征一同输入到下一模块中。F函数可以选择不同的函数,就可以得到不同注意力域的结果:
是对图片特征张量直接sigmoid激活函数,就是混合域的注意力;
是对图片特征张量直接做全局平均池化(global average pooling),所以得到的是通道域的注意力(类比SENet[5]);
是求图片特征张量在通道域上的平均值的激活函数,类似于忽略了通道域的信息,从而得到空间域的注意力。
4 时间域注意力
这个概念其实比较大,因为计算机视觉只是单一识别图片的话,并没有时间域这个概念,但是[7]这篇文章中,提出了一种基于递归神经网络(Recurrent Neural Network,RNN)的注意力机制识别模型。
RNN模型比较适合的场景是数据具有时序特征,比如使用RNN产生注意力机制做的比较好的是在自然语言处理的问题上。因为自然语言处理的是文本分析,而文本产生的背后其实是有一个时序上的关联性,比如一个词之后还会跟着另外一个词,这就是一个时序上的依赖关联性。
而图片数据本身,并不具有天然的时序特征,一张图片往往是一个时间点下的采样。但是在视频数据中,RNN就是一个比较好的数据模型,从而能够使用RNN来产生识别注意力。
特意将RNN的模型称之为时间域的注意力,是因为这种模型在前面介绍的空间域,通道域,以及混合域之上,又新增加了一个时间的维度。这个维度的产生,其实是基于采样点的时序特征。
Recurrent Attention Model [7]中将注意力机制看成对一张图片上的一个区域点的采样,这个采样点就是需要注意的点。而这个模型中的注意力因为不再是一个可以微分的注意力信息,因此这也是一个强注意力(hard attention)模型。这个模型的训练是需要使用增强学习(reinforcementlearning)来训练的,训练的时间更长。
这个模型更需要了解的并不是RNN注意力模型,因为这个模型其实在自然语言处理中介绍的更详细,更需要了解的是这个模型的如何将图片信息转换成时序上的采样信号的:

这个是模型中的关键点,叫Glimpse Sensor,我翻译为扫视器,这个sensor的关键点在于先确定好图片中需要关注的点(像素),这时候这个sensor开始采集三种信息,信息量是相同的,一个是非常细节(最内层框)的信息,一个是中等的局部信息,一个是粗略的略缩图信息。
这三个采样的信息是在 位置中产生的图片信息,而下一个时刻,随着 的增加,采样的位置又开始变化,至于 随着 该怎么变化,这就是需要使用增强学习来训练的东西了。
有关RNN做attention的,还是应该去了解自然语言处理,如机器翻译中的做法,这里就不再继续深入介绍,想深入了解的,推荐阅读Attention模型方法综述。
HAN的原理(Hierarchical Attention Networks)。
利用Attention模型进行文本分类。
https://zhuanlan.zhihu.com/p/31547842