论文地址
译文地址
为什么要读这篇论文?
数据库里的最终一致性,写任一副本(上一章spanner 讲了读任一副本)
和BAYOU一样,有冲突消解策略。支持地理分散的(多数据中心)
一个让人耳目一新的设计。
他是一个真实的系统:用来支持购物车的服务在AMAZON。
比PNUTS, Spanner, FB Mysql 更加可靠,同时也一致性级别也比他们低。
Canssandra 受他启发。
他们的目标是: 99.9 的延迟少于300MS,同时容忍数据中心的灾难问题,永远可写。

数据放在哪?

整个系统在一个特定的环形运算空间,我们称为Ring。运算空间的大小可自己定义,例如,该空间范围取值为[0, 2**32 - 1],而之所以称为环形空间是当超出该值后继续归零。
对存储系统中的每个节点的特征值在该空间内进行运算,例如,取节点的特征为其IP地址,对其ip地址进行hash运算,然后在运算空间内取模,得到其在环形运算空间上的值。如上图,A~G每个节点根据其运算得到的值而位于该Ring上的不同位置。
写入对象数据时,首先根据对象key(一般是对象名)在运算空间内计算其特征值,然后在该Ring上沿着顺时针方向查找与其特征值最接近的节点。例如上图的对象K,计算其特征值位于A、B节点之间,根据规则,那K应该被存储在节点B上。
这种方法看似完美,一次计算即可得出其存储节点最终位置。但可能带来以下的致命问题:
- 新增一个节点,原本存储在Ring上与其相邻节点的数据现在落在了该新增节点上,那势必需要进行数据迁移;
- 移除一个节点,那原本由该节点负责的数据接下来要由其相邻节点负责,也会带来数据的迁移。
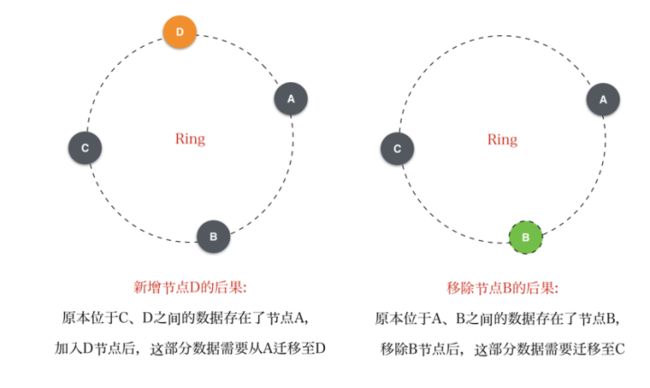
由于计算式数据定位的天然特性,数据迁移的问题根本无法避免。但是上面的方案的问题是数据迁移发生在两个相邻节点之间,如果每个节点存储的数据量很大,那数据迁移带来的压力势必会影响参与迁移的节点正常的请求,导致不可用。
既然无法避免,那就尽量缓解。Dynamo设计中引入了虚拟节点(partition)。所谓的虚拟节点其实就是在一个物理节点(如上面的A/B/C/D)上虚拟出多个逻辑节点。例如A-1、A-2、A-3 ……,将这些虚拟节点参与环形运算空间的计算,如下图:
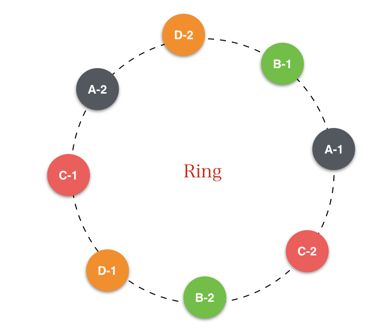
上图中每个物理节点虚拟出了两个逻辑节点,定位时,首先根据对象key计算其所在的虚拟节点,最后查表知道该虚拟节点位于的物理节点。相当于是一个二级映射函数。
这样做法的好处时,在新增或者移除节点时,会有更多的节点参与到数据迁移过程中,提升迁移效率,但是却无法从根本上避免数据迁移。

从理论分析就知道数据迁移过程参与的节点更多了,效率自然就提升了。
而物理节点如何划分虚拟节点,个人感觉根据实际的使用场景来决定。例如,jedis就使用虚拟ip(真实ip后加上节点编号)。
在存储系统中,物理节点其实抽象的是磁盘,虚拟节点其实就是代表了磁盘上的某个目录(经常称之为Partition)。而一般虚拟节点的数目固定,为2**N个。这样,对象key与虚拟节点的映射关系就可以保持固定,改变的是虚拟节点至物理节点的映射关系。
这种二级映射带来的好处是:
- 一级映射时增加节点移动的数据单位是单个对象,扫描计算哪些对象需要移动时代价太大;
- 二级映射时节点变化只影响虚拟节点的情况,新增或者移除节点(磁盘设备)时只需要迁移虚拟节点的数据即可,管理的成本大大减少。
引入虚拟节点后,典型的数据定位流程是:
- 根据对象名计算MD5,并取MD5的低N位得到虚拟节点编号(这也是为什么虚拟节点数目最好选择2的N次方的原因);
- 查表获得虚拟节点所在的物理节点
一致性HASH的好处有可以自然的均衡,同时不需要一个MASTER去集中化管理,避免了单点的诸多问题。
坏处就是很难去主动控制数据的存放比如有一个KEY特别火爆,就很难调整。其次节点加入和离开,都需要SHIFT DATA。而这DATA也是RANDOM(论文之后提到了优化手段。)
容错
如果一个节点暂时不可用,那么数据会被临时存放到另一个节点,同时会有一个handoff机制来保证,当节点恢复后。数据又会被送回来。
所谓的HandOff机制是对Dynamo可用性的进一步提升手段。如同我们上面说到,正常情况下,客户的写入数据会被复制到ring上的N个节点。但是一旦出现异常时,写入的节点不可达,这时候可能就会出错,如下:

假如数据应该被写入至节点A并复制到B和C,但是此时假如A节点异常,可能就会导致数据不可写。
Dynamo的做法是引入Handoff节点,例如这里的D作为A的Handoff,A节点不可写的时候,数据会被写入D,但是在D上这些数据会被存储在特殊位置并且有元数据信息描述该数据的原始位置(A)。一旦D检测到A节点恢复,就会将该本来不属于自己的数据迁移至原本的位置(A)。
如果节点长期不可用的话。就会需要创建一个新的副本来复制这个节点全部的数据。这时需要ADMIN手动去下线上线节点。Dynamo本身是把所有失败都当做临时的。
如何实现永远可写?
没有MASTER,所以只要找到一个活的节点,就可以确保先写到这个节点上。如果有失败发生,为了确保数据的可持久性。那么就需要sloppy quorums。 同时还需要冲突消解策略。
sloppy quorum
quorum的目标有3个。1. 不要在没响应的节点上阻塞。 2. 写应该不会失败 3. 读有很大概率看到最新的写。
一共发送N个请求,同步等待R个读,W个写,根据鸽笼原理,会至少在一个SERVER上有交集。同时可以减少长尾效应,以及容忍一些节点失效。
这里的N是N个再preference list里的可达节点。每个节点都会去发送PING看他的后继者是否还在。 "sloppy" quorum因为节点可能在可达的问题上不一致,所以读和写可能不一定有交集。
流程是,当coordinator 收到写请求,他会发送同样的写请求给N个可达的节点并行的。然后等待W个写。同样如果是读请求,同样的写请求给N个可达的节点并行的。然后等待R个读的结果回来。开始验证版本,如果有版本冲突,则会把多个版本冲突的结果返回给客户端。
如果里面失败很疯狂,读可能看不到最新的写。
除了上述的HandOff机制,后台还有一个"merkle tree" sync的程序,去同步不一样的KEY RANGE。
同时最终一致性是怎么来的呢? 因为要接受多个写在任一副本上,那么在失效情况下就会有分叉的副本。所以需要允许读到冲突的或者过期的数据。这个冲突和过期,会被修复。其中客户端会显示的合并冲突,这个合并策略由客户端提供。如果数据有几个副本落后,会在读时进行修复。
什么时候R/W没有交集呢?当R + W > N
N=3 R=2 W=2
shopping cart, starts out empty ""
preference list n1, n2, n3, n4
client 1 wants to add item X
get() from n1, n2, yields ""
n1 and n2 fail
put("X") goes to n3, n4
n1, n2 revive
client 2 wants to get Y
get() from n1, n2 yields ""
reply client ""
then get() receive n3,n4 yield "X" with higher version, repair n1,n2
什么时候会发生版本冲突呢?
N=3 R=2 W=2
shopping cart, starts out empty ""
preference list n1, n2, n3, n4
client 1 wants to add item X
get() from n1, n2, yields ""
n1 and n2 fail
put("X") goes to n3, n4
n1, n2 revive
client 3 wants to add Y
get() from n1, n2 yields ""
put("Y") to n1, n2
client 3 wants to display cart
get() from n1, n3 yields two values!
"X" and "Y"
neither supersedes the other -- the put()s conflicted
客户端收到了多个版本的读的值之后,比如是购物车服务,可能会使用union的方式来merge, 然后把MERGE的结果写回DYNAMO
API:
- get(k) may return multiple versions, along with "context"
- put(k, v, context)
版本向量
如何在多个数据副本之间判断谁的数据更新?
Dynamo使用向量时钟来解决该问题。简单来说,接受客户端写请求的副本会为该数据的本次更新增加一个逻辑时间戳,该时间戳为一个二元组
updater:更新的执行者
version:本次更新的版本号
例如,A本地对象object的当前版本为
假如该对象有另外一个副本位于节点B,B上该对象的版本依然为

上图演示了对于一个对象的两次更新过程,第二次中原来的主副本和客户端之间出现了网络不连通的问题,导致客户端选择出了新的主副本。
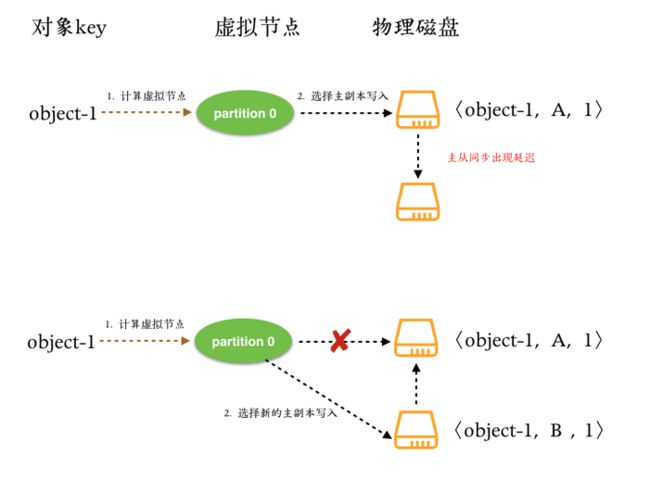
上图演示了在主从同步出现延迟的情况下客户端的连续数据更新导致数据版本的冲突问题。
客户端读数据时,会根据R的设置从多个副本中读出数据,然后对比副本数据的向量时钟的版本,选择最新的数据版本返回给客户端。但是有可能出现无法合并的情况,例如上面的A节点上数据版本为
再考虑下面这种并发更新的情况:
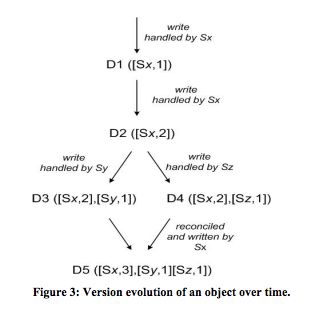
系统当前是三副本,某个partition的三个副本分别为Sx,Sy,Sz,且R=2, W=2。按照下面的顺序进行数据更新:
- 数据在Sx节点写入,产生数据的新版本为
- 数据在Sx节点更新,产生数据新版本为
,并同步至Sy,Sz; - 截止目前,Sx,Sy,Sz三个节点的数据版本均为
- 由于某种原因,A客户端选择了Sy节点对数据进行更新,而此时A客户端看到的数据版本为
- 在4进行的过程中,客户端B选择了Sz节点对数据进行更新,此时B客户端看到的数据版本也是
- 接下来数据主从同步的过程中,无论是Sy将自己的数据同步至Sz,还是Sz将数据同步至Sy,都会发现他们之间的数据其实是存在冲突的,而且存储系统自身是无法解决这种冲突的,于是,继续保存这种冲突数据,但是在Sy(或者Sz)向Sx同步数据的时候是没问题的,因为通过向量时钟比对发现Sx的版本无论比Sy还是Sz都要更小;
- 接下来,客户端发起对数据的读请求,因为存在冲突,冲突的版本都会被发送至客户端,于是客户端看到的数据版本是{
如何节点很多,版本向量只会越来越大?
是的,但是这个变大的过程很缓慢,因为KEY基本上是被固定的N个节点服务的。
Dynamo会删除LRU的ENTRY,当VV 超过10个元素。
这样会带来不必要的merge,
put@b: [b:4]
put@a: [a:3, b:4]
forget b:4: [a:3]
now, if you sync w/ [b:4], looks like a merge is required
忘记最旧的是聪明的,因为如果忘记新的话,会造成最近的版本区别会被消除。可能造成了错误的包含关系,而丢失了更新。比如有个新的 [c : 1, a : 10]被抹除成了 [a : 10], 那边有个[a : 11],这样结果就以[a : 11]为准了,丢失了C的这个更新。
让CLIENT 做MERGE也不是万能的。比如是个计数器,要在X上加2,B 加了1次1,C加了一次1. 其实应该就是,2。如果客户端看到2个不同的版本都是1,就以为是1就错了。
一个问题
Suppose Dynamo server S1 is perfectly healthy with a working network connection. By mistake, an administrator instructs server S2 to remove S1 using the mechanisms described in 4.8.1 and 4.9. It takes a while for the membership change to propagate from S2 to the rest of the system (including S1), so for a while some clients and servers will think that S1 is still part of the system. Will Dynamo operate correctly in this situation? Why, or why not?
被删除的server S1, 可能会丢失一些PUT,在GET的时候,同时加入的SERVER可能会丢失一些PUT,因为那时不知道coordinator。当然加入的SERVER也会服务GET()在还没有完全初始化好的时候。Quorum 会使得get 可以看到最新的数据,尽管有一些是旧的。同时副本的SYNC也会修复这些旧数据的GET。所以大概率Dynamo还是会做正确的事。
如何解决KEY RANGE随机变化造成的性能问题

在原先的版本里虽然引入virtual node但是当有节点加入的时候,还是随机散到这个环上,所以要分过去的KEY RANGE 也是随机,大概率不得不扫描原来NODE上的整个KEY RANGE 把要分过去的数据给找出来。策略2把整个环的区域等分成Q分,因为Q非常大,所以每个节点可能会拥有很多分KEY RANGE的文件。Q远大于 T(每个节点的TOKEN数) * S(系统中节点数)。 现在因为KEY RANGE 固定了,所以可以每个RANGE存一份文件。然后以RANGE的最右侧 向后顺时针找到的NODE,就是负责存这个RANGE文件的NODE。此时TOKEN还是随机分配,随机散的了,只是RANGE被固定住了。所以再发送数据的时候,会把整个文件发过去了。上面解决了传输的问题,但是因为TOKEN随机撒,可能有些TOKEN拿到200个文件,有些只拿到2个文件,会不均匀。同时节点出去进来也会不均匀。
那么策略3就是TOKEN也不随机散了。每个节点比如Q为100, S为5. 那么每个节点就有20个TOKEN,是均匀的防止在100个环上的等比例切分的点上的。这样把不均匀的问题也给解决了。
总结
Dynamo 有最终一致性,需要CLIENT来消解写冲突,同时在失败的情况下系统依然可以写。
这个模型因为会延迟读和需要客户端提供MERGE,在某些场景上不太适合。
是一种得到高可用并且不阻塞在WAN上的好方式。
但是最终一致性在存储系统上是否是好的,还有争议。
FAQ
Q:Dynamo 如何从一个节点的永久的失效里恢复,Merkle trees反熵是什么?
A:在本文中,反熵是同步两个副本的核心。 为了确定两个副本之间的区别,Dynamo遍历了两个副本的Merkle Tree。 如果root节点匹配,则Dynamo不会下降该分支。 如果树中的一个节点不匹配,则将新版本的分支复制到旧版本。 使用Merkle树使作者只能复制树中不同的部分。最小化了同步时需要转移的数据量,减少了逆熵过程中 读取磁盘的次数。 维基百科上有一张图片来说明:https://en.wikipedia.org/wiki/Merkle_tree。
这种方案的缺点是:每当有节点加入或离开系统时,一些 key range 会变,因此对应的 tree 需要重新计算。采用了上面提到的策略3之后会解决这个问题。
Q : Dynamo 会使用DHT来scale吗?
A :现在,人们已经非常了解如何构建可扩展到大量节点的DHT,甚至是O(1)DHT(例如,请参见http://www.news.cs.nyu.edu/~jinyang/pub/nsdi05-accordion.pdf)。 所描述的Dynamo解决方案是具有良好可伸缩性的O(1)DHT。 我认为作者认为,一旦他们实际遇到缩放问题,他们将使用文献中的解决方案。
Q : 什么是gossip-based protocol?
A : 任何不具有掌握系统中所有参与者的 master的系统,通常都会有一个协议来查找其他成员。 通常将此类协议称为八卦协议,因为参与者需要八卦(从其他节点收集信息)来确定谁是系统的一部分。 更一般地,八卦是指通过成对的计算机交换他们知道的信息而在整个系统中传播的信息。 您可以从Wikipedia了解更多有关八卦协议的信息:https://en.wikipedia.org/wiki/Gossip_protocol。