tensorflow2.0基础简介
tensorflow2.0简介
1、tensorflow 2.0基础知识简介
tensorflow2.0是谷歌在2019年3月份发布更新的一款到端开源机器学习平台,其目的在于优化tensorflow1.x版本,使其更灵活和易用性;2.0版本较1.x有较大的更新,具有简易性、更清晰、扩展性三大特征,大大简化1.x 的API,其官方中文文档链接如:https://github.com/geektutu/tensorflow2-docs-zh
它做了如下更新
• 使用 Keras 和 eager execution 轻松构建模型
• 在任意平台上实现稳健的生产环境模型部署。
• 为研究提供强大的实验工具。
• 通过清理废弃的 API 和减少重复来简化 API,规范API
其架构图如下
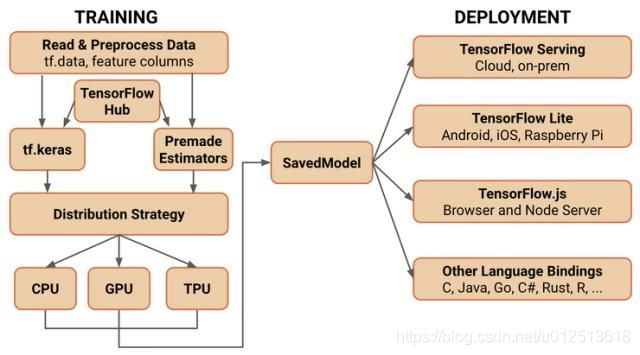
tensorflow2.0版本架构图
注释:
- tf.keras
Keras 的核心数据结构是 model,一种组织网络层的方式。最简单的模型是 Sequential 顺序模型,它由多个网络层线性堆叠。对于更复杂的结构,你应该使用 Keras 函数式 API,它允许构建任意的神经网络图
参考链接 https://keras.io/zh/ - tf.premade Estimators
Premade Estimators 是类似于keras 一样,是一种构建、训练和验证模型的方式
实例参考链接:https://tensorflow.juejin.im/get_started/premade_estimators.html
创建一个有两个隐藏层和每层10个节点的 DNN
classifier = tf.estimator.DNNClassifier(
feature_columns=my_feature_columns,两个隐藏层,每层 10 个节点。
hidden_units=[10, 10],模型必须在 3 个类别中作出选择
n_classes=3) - TensorFlow Hub(需要tensorflow1.7及以上版本提供)
tensorflow hub 的主要目标是为模型提供一种简便的封装方式,同时可以简便地复用已封装的模型,可以说 tf hub 是为迁移学习而生的。hub module 在使用时还能设定为参数可训练或者参数不可训练,这样对于不同的任务就能有更灵活的选择。对于一些训练样本较少的情况,可以冻结底层 module 的参数
embedding = "https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1"
hub_layer = hub.KerasLayer(embedding, input_shape=[],
dtype=tf.string, trainable=True)
hub_layer(train_examples_batch[:3])
# 该层使用预先训练的保存模型将句子映射到其嵌入向量。
# 使用的预训练文本嵌入模型(google/tf2-preview/gnews-swivel-20dim/1)将句子拆分为标记
# 嵌入每个标记然后组合嵌入。生成的维度为:(num_examples, embedding_dimension)。
- TensorFlow Serving
允许模型通过 HTTP/REST 或 GRPC/协议缓冲区提供服务的 TensorFlow 库构建。 - TensorFlow Lite
TensorFlow 针对移动和嵌入式设备的轻量级解决方案提供了在 Android、iOS 和嵌入式系统上部署模型的能力。 - tensorflow.js
支持在 JavaScript 环境中部署模型,例如在 Web 浏览器或服务器端通过 Node.js 部署模型。TensorFlow.js 还支持在 JavaScript 中定义模型,并使用类似于 Kera 的 API 直接在 Web 浏览器中进行训练。
2、tensorflow2.0 工作流示例流程
tensorflow 工作流示例流程如下
1. 用 tf.data 加载数据。
用 tf.data 创建的输入线程读取训练数据。使用 tf.feature_column 描述特征特性,例如分段和特征交叉。还支持从内存数据(例如 NumPy)中方便地输入。
如:
# 输入 Numpy 数据
import numpy as np
train_x = np.random.random((1000, 72))
train_y = np.random.random((1000, 10))
val_x = np.random.random((200, 72))
val_y = np.random.random((200, 10))
model.fit(train_x, train_y, epochs=10, batch_size=100,
validation_data=(val_x, val_y))
# tf.data 输入数据
dataset = tf.data.Dataset.from_tensor_slices((train_x, train_y))
dataset = dataset.batch(32)
dataset = dataset.repeat()
val_dataset = tf.data.Dataset.from_tensor_slices((val_x, val_y))
val_dataset = val_dataset.batch(32)
val_dataset = val_dataset.repeat()
model.fit(dataset, epochs=10, steps_per_epoch=30,
validation_data=val_dataset, validation_steps=3
2. 使用 tf.keras、Premade Estimators 构建、训练和验证模型。
Keras 与 TensorFlow 的其余部分紧密集成,因此你可以随时访问 TensorFlow 的功能。一组标准的打包模型(例如,线性或逻辑回归、梯度提升树、随机森林)也可以直接使用(使用 tf.estimator API 实现)。
同时,它也提供在已有模型的基础上继续训练模型,可通过 TensorFlow Hub 的模块利用迁移学习来训练 Keras 或 Estimator 模型。
tensorflow2.0推荐使用keras构建网络,常见的网络都包含在keras.layer中
3. 用 eager execution 运行和调试,然后在图形上使用 tf.function。
TensorFlow 2.0 默认用 eager execution 运行,以便于轻松使用和顺利调试。此外,tf.function 注释透明地将 Python 程序转换成 TensorFlow 图。这个过程保留了 TensorFlow1.x 基于图形执行的所有优点:性能优化、远程执行,以及序列化、导出和部署的能力,同时增加了用简单 Python 表达程序的灵活性和易用性。
4. 使用分布式策略进行分布式训练。
对于大部分 ML 训练任务来说,Distribution Strategy API 使得在不同的硬件配置上分布和训练模型变得很容易,而无需改变模型定义。由于 TensorFlow 为一系列硬件加速器(如 CPU、GPU、TPU)提供支持,你可以将训练工作负载分配给单节点/多加速器以及多节点/多加速器配置,包括 TPU Pods。尽管这个 API 支持多种群集配置,但提供了在本地或云环境中的 Kubernete 集群上部署训练的模板。
5. 保存模型( SavedModel)。
TensorFlow 将在 SavedModel 上标准化,来作为 TentsorFlow Serving、TensorFlow Lite、TensorFlow.js、TentsorFlow Hub 等的交换格式。(tensorflow1.x 的SavedModels 或存储的 GraphDefs 将向后兼容,用 TensorFlow 1.x 保存的 SavedModels 将继续在 2.x 中加载和执行。然而,2.0 中的更改意味着原始检查点中的变量名可能会更改,所以使用 2.0 之前的检查点而代码已转化为 2.0 时,可能无法保证有效)
3、tensorflow2.0 兼容性和连续性
为了简化向 TensorFlow 2.0 的过渡,将会有一个转化工具来更新 TensorFlow 1.x Python 代码,以使用 TensorFlow 2.0 兼容的 API,或标记代码无法自动转换的情况。但不是所有的变化都可以完全自动化进行。例如,一些被弃用的 API 没有直接的等效物。这也是我们要引入 tensorflow.compat.v1 兼容性模块的原因,该模块支持完整的 TensorFlow 1.x API(包括 tf.contrib)。该模块将会在 TensorFlow 2.x 的时间线内得到维护,并允许用 TensorFlow 1.x 编写的代码保持功能。
此外,SavedModel 和 GraphDef 将向后兼容。用 1.x 版本保存的 SavedModel 格式的模型将继续在 2.x 版本中加载和执行。但是,2.0 版本中的变更将意味着原始检查点中的变量名可能会更改,因此使用 2.0 版本之前的检查点(代码已转换为 2.0 版本)并不能保证正常工作。有关详细信息,请参阅 TensorFlow 2.0 指南。
4、tensorflow 2.0与1.x区别
具体说来:
• 删除 queue runner 以支持 tf.data。
• 删除图形集合。
• 变量处理方式的变化。
• API 符号的移动和重命名。
• tf.contrib 将从核心 TensorFlow 存储库和构建过程中移除
4.1 默认动态图机制
在tensorflow2.0中,动态图默认的是不需要自己主动启动它
import tensorflow as tf
a=tf.constant([1,2,3])
b=tf.constant([2,1,3])
print(a+b)
# tf.Tensor([3,3,6]),shape=(3,0),dtype=int32
有了动态图,大大减少了计算量,再也不需要启动复杂的session和graph;
与此同时,2.0删除了Variable_scopes和tf.get_Variable(),需要用面向对象的方式来处理变量共享
4.2 API 符号的移动和重命名&
具体改动
• summary
tf.histogram_summary(var.op.name, var) 改为 tf.summaries.histogram()
tf.scalar_summary('images', images)改为:tf.summary.scalar('images', images)
tf.image_summary('images', images)改为:tf.summary.image('images', images)
tf.merge_all_summaries()改为:summary_op = tf.summaries.merge_all()
tf.train.SummaryWriter改为:tf.summary.FileWriter
• example loss
cifar10.loss(labels, logits) 改为:cifar10.loss(logits=logits, labels=labels)
• 交叉熵
cross_entropy = tf.nn.softmax_cross_entropy_with_logits( logits,dense_labels, name='cross_entropy_per_example')
改为:
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(
logits=logits, labels=dense_labels, name='cross_entropy_per_example')
• concat
concated = tf.concat(1, [indices, sparse_labels])改为:
concated = tf.concat([indices, sparse_labels], 1)
4.3 弃用collections
tensorflow 1.x 中可以通过集合 (collection) 来管理不同类别的资源。例如使用tf.add_to_collection 函数可以将资源加入一个或多个集合。使用tf.get_collection获取一个集合里面的所有资源。这些资源可以是张量、变量或者运行 Tensorflow程序所需要的资源。我们在训练神经网络时会大量使用集合管理技术。如通过tf.add_n(tf.get_collection(“losses”)获得总损失。
由于collection控制变量很不友好,在TensorFlow2.0中,弃用了collections,这样代码会更加清晰。
tensorflow2.0非常依赖Keras API(弃用tf.layers),因此如果你使用tf.keras,每个层都会处理自己的变量,当你需要获取可训练变量的列表,可直接查询每个层。
如:
from tensorflow import keras
from tensorflow.keras import Sequential
model = Sequential([
keras.layers.Dense(100,activation="relu",input_shape=[2]),
keras.layers.Dense(100,activation="relu"),
keras.layers.Dense(1)
])
可通过model.weights,就可以查询每一层的可训练的变量。结果如下面这种形式。
<tf.Variable'dense/kernel:0' shape=(2,100),dtype=float32,numpy=array([[...]]),dtype=float32)>,
参考链接:
[1] TensorFlow2.0 / TF2.0 Tutorial 入门教程实战案例- https://zhuanlan.zhihu.com/p/72194796
[2] tensorflow hub 预训练实例 https://blog.csdn.net/markmin214/article/details/90812605
[3] tensorflow2.0 简介 https://baijiahao.baidu.com/s?id=1622717828293482437&wfr=spider&for=pc
[4] tensorflow2.0 官方文档 https://github.com/geektutu/tensorflow2-docs-zh
二、实例
1.简单实例
import tensorflow as tf
from tensorflow.keras import layers
print(tf.__version__)
print(tf.keras.__version__)
#模型堆叠
最常见的模型类型是层的堆叠:tf.keras.Sequential 模型
model = tf.keras.Sequential()
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
## 网络配置
#tf.keras.layers 中网络配置:
#activation:设置层的激活函数。此参数由内置函数的名称指定,或指定为可调用对象。默认情况下,系统不会应用任何激活函数。
#kernel_initializer 和 bias_initializer:创建层权重(核和偏差)的初始化方案。此参数是一个名称或可调用对象,默认为 "Glorot uniform" 初始化器。
#kernel_regularizer 和 bias_regularizer:应用层权重(核和偏差)的正则化方案,例如 L1 或 L2 正则化。默认情况下,系统不会应用正则化函数。
layers.Dense(32, activation='sigmoid')
layers.Dense(32, activation=tf.sigmoid)
layers.Dense(32, kernel_initializer='orthogonal')
layers.Dense(32, kernel_initializer=tf.keras.initializers.glorot_normal)
layers.Dense(32, kernel_regularizer=tf.keras.regularizers.l2(0.01))
layers.Dense(32, kernel_regularizer=tf.keras.regularizers.l1(0.01))
#训练和评估
## 设置训练流程
### 构建好模型后,通过调用 compile 方法配置该模型的学习流程:
model = tf.keras.Sequential()
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss=tf.keras.losses.categorical_crossentropy,
metrics=[tf.keras.metrics.categorical_accuracy])
# 输入 Numpy 数据
import numpy as np
train_x = np.random.random((1000, 72))
train_y = np.random.random((1000, 10))
val_x = np.random.random((200, 72))
val_y = np.random.random((200, 10))
model.fit(train_x, train_y, epochs=10, batch_size=100,
validation_data=(val_x, val_y))
# tf.data 输入数据
dataset = tf.data.Dataset.from_tensor_slices((train_x, train_y))
# from_tensor_slices 把第一维数据切开,切成 1000 个 72*10的张量切片
dataset = dataset.batch(32)
dataset = dataset.repeat()
val_dataset = tf.data.Dataset.from_tensor_slices((val_x, val_y))
val_dataset = val_dataset.batch(32)
val_dataset = val_dataset.repeat()
model.fit(dataset, epochs=10, steps_per_epoch=30,
validation_data=val_dataset, validation_steps=3)
# 评估与预测
test_x = np.random.random((1000, 72))
test_y = np.random.random((1000, 10))
model.evaluate(test_x, test_y, batch_size=32)
test_data = tf.data.Dataset.from_tensor_slices((test_x, test_y))
test_data = test_data.batch(32).repeat()
model.evaluate(test_data, steps=30)
# predict
result = model.predict(test_x, batch_size=32)
print(result)
- 张量切片 from_tensor_slices
train_imgs = tf.constant(['train/img1.png', 'train/img2.png',
'train/img3.png', 'train/img4.png',
'train/img5.png', 'train/img6.png'])
train_labels = tf.constant([0, 0, 0, 1, 1, 1])
tr_data = Dataset.from_tensor_slices((train_imgs, train_labels))
输出:
(b'train/img1.png', 0)
(b'train/img2.png', 0)
(b'train/img3.png', 0)
(b'train/img4.png', 1)
(b'train/img5.png', 1)
(b'train/img6.png', 1)
- batch repeat shuffle
– dataset.batch: 作用是读取batch_size大小的数据
– dataset.repeat: 作用是将数据集重复多少次,即epoch
– dataset.shuffle: 作用是将数据打乱
这里有两种使用情况:
情况一:
dataset.shuffle(3)
dataset.batch(4)
dataset.repeat(2)
将数据取完一个epoch后,再取一个epoch。因此每一个epoch中,最后一个batch大小可能小于等于batch size。
情况二:
dataset.repeat(2)
dataset.shuffle(3)
dataset.batch(4)
先将数据重复2次,成为一个大的数据,最后一个batch大小可能小于等于batch size 。而且一个batch_size中的数据可能会有重复。
参考链接:https://blog.csdn.net/YQMind/article/details/82901442
2.函数式编程
# 构建高级模型
## 函数式 api
###tf.keras.Sequential 模型是层的简单堆叠,无法表示任意模型。使用 Keras 函数式 API 可以构建复杂的模型拓扑,例如:
#多输入模型,
#多输出模型,
#具有共享层的模型(同一层被调用多次),
#具有非序列数据流的模型(例如,残差连接)。
#使用函数式 API 构建的模型具有以下特征:
#层实例可调用并返回张量。
#输入张量和输出张量用于定义 tf.keras.Model 实例。
#此模型的训练方式和 Sequential 模型一样。
input_x = tf.keras.Input(shape=(72,))
hidden1 = layers.Dense(32, activation='relu')(input_x)
hidden2 = layers.Dense(16, activation='relu')(hidden1)
pred = layers.Dense(10, activation='softmax')(hidden2)
model = tf.keras.Model(inputs=input_x, outputs=pred)
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss=tf.keras.losses.categorical_crossentropy,
metrics=['accuracy'])
model.fit(train_x, train_y, batch_size=32, epochs=5)
#模型子类化
#通过对 tf.keras.Model 进行子类化并定义您自己的前向传播来构建完全可自定义的模型。
#在 init 方法中创建层并将它们设置为类实例的属性。
#在 call 方法中定义前向传播
class MyModel(tf.keras.Model):
def __init__(self, num_classes=10):
super(MyModel, self).__init__(name='my_model')
self.num_classes = num_classes
self.layer1 = layers.Dense(32, activation='relu')
self.layer2 = layers.Dense(num_classes, activation='softmax')
def call(self, inputs):
h1 = self.layer1(inputs)
out = self.layer2(h1)
return out
def compute_output_shape(self, input_shape):
shape = tf.TensorShapej(input_shape).as_list()
shape[-1] = self.num_classes
return tf.TensorShape(shape)
model = MyModel(num_classes=10)
model.compile(optimizer=tf.keras.optimizers.RMSprop(0.001),
loss=tf.keras.losses.categorical_crossentropy,
metrics=['accuracy'])
model.fit(train_x, train_y, batch_size=16, epochs=5)
#自定义层
#通过对 tf.keras.layers.Layer 进行子类化并实现以下方法来创建自定义层:
#build:创建层的权重。使用 add_weight 方法添加权重。
#call:定义前向传播。
#compute_output_shape:指定在给定输入形状的情况下如何计算层的输出形状。
# 或者,可以通过实现 get_config 方法和 from_config 类方法序列化层。
class MyLayer(layers.Layer):
def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(MyLayer, self).__init__(**kwargs)
def build(self, input_shape):
shape = tf.TensorShape((input_shape[1], self.output_dim))
self.kernel = self.add_weight(name='kernel1', shape=shape,
initializer='uniform', trainable=True)
super(MyLayer, self).build(input_shape)
def call(self, inputs):
return tf.matmul(inputs, self.kernel)
def compute_output_shape(self, input_shape):
shape = tf.TensorShape(input_shape).as_list()
shape[-1] = self.output_dim
return tf.TensorShape(shape)
def get_config(self):
base_config = super(MyLayer, self).get_config()
base_config['output_dim'] = self.output_dim
return base_config
@classmethod
def from_config(cls, config):
return cls(**config)
model = tf.keras.Sequential(
[
MyLayer(10),
layers.Activation('softmax')
])
model.compile(optimizer=tf.keras.optimizers.RMSprop(0.001),
loss=tf.keras.losses.categorical_crossentropy,
metrics=['accuracy'])
model.fit(train_x, train_y, batch_size=16, epochs=5)
# 回调
callbacks = [
tf.keras.callbacks.EarlyStopping(patience=2, monitor='val_loss'),
tf.keras.callbacks.TensorBoard(log_dir='./logs')
]
model.fit(train_x, train_y, batch_size=16, epochs=5,
callbacks=callbacks, validation_data=(val_x, val_y))
#保持和恢复
# 权重保存
model = tf.keras.Sequential([
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax')])
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])
model.save_weights('./weights/model')
model.load_weights('./weights/model')
model.save_weights('./model.h5')
model.load_weights('./model.h5')
#保存网络结构
#序列化成json
import json
import pprint
json_str = model.to_json()
pprint.pprint(json.loads(json_str))
fresh_model = tf.keras.models.model_from_json(json_str)
# 保持为yaml格式 #需要提前安装pyyaml
yaml_str = model.to_yaml()
print(yaml_str)
fresh_model = tf.keras.models.model_from_yaml(yaml_str)
# 保存整个模型
model = tf.keras.Sequential([
layers.Dense(10, activation='softmax', input_shape=(72,)),
layers.Dense(10, activation='softmax')
])
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_x, train_y, batch_size=32, epochs=5)
model.save('all_model.h5')
model = tf.keras.models.load_model('all_model.h5')
# 将 keras 用于 Estimator
# Estimator API 用于针对分布式环境训练模型。它适用于一些行业使用场景,例如用大型数据集进行分布式训练并导出模型以用于生产
model = tf.keras.Sequential([layers.Dense(10,activation='softmax'),
layers.Dense(10,activation='softmax')])
model.compile(optimizer=tf.keras.optimizers.RMSprop(0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])
estimator = tf.keras.estimator.model_to_estimator(model)