人人都能学会数据分析-笔记
第01周 走进数据分析
1-1 互联网数据分析通用课程-导学
课程导学
随着互联网的发展,任何岗位都离不开数据分析
- 互联网 => 数据 => 价值
- 用户 => 网上购物 => 评价、购买量、价格
- 产品 => 设计与优化 => 跟踪用户行为、监测数据
- 运营 => 成交量 => 数据指标、有效营销手段
数据分析师,必须掌握的技能
硬技能 => 硬性数据处理和分析工具的使用
=> 电子表格 Excel
=> 数据库操作语言 SQL
=> 可视化面板 Tableau
=> 大数据处理分析 Python
软技能 => 对事物的认知方式、经验积累
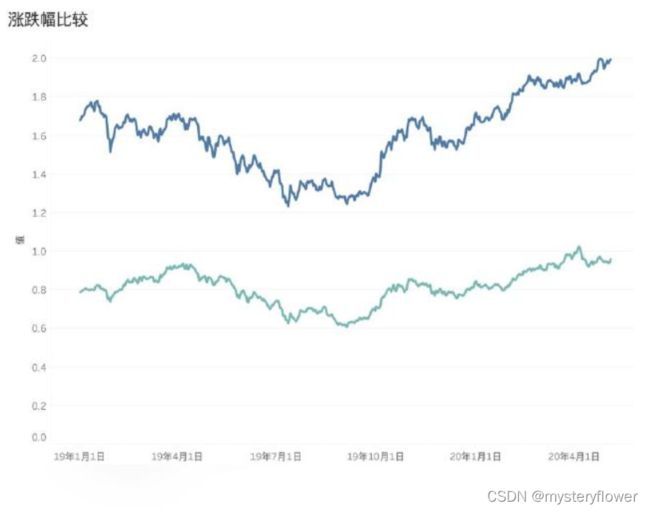
- A的价格比B的价格高
- A的波动大于B,波动大风险就大
- 行情下跌 vs 事件关系
课程优势
普适性
运营、产品、市场或者销售
数据分析的硬技能
互联网行业经验
=> 细分行业、企业、商业模式
运营策略、思维模型、业务指标
实战性
真实的数据、案例
第一阶段:大数据人才需求分析、销售情况分析
第二阶段:用户行为、用户画像、营销渠道分析、留存转化
从0到1
目标确定=>数据获取=>数据清洗=>数据探索=>洞察结论=>数据报告
期待你和我一起,用数据解析世界
1-2 从互联网数据分析说起
什么是互联网数据分析
互联网:
- 信息传输的一种载体
- 通过电子化的方式留存信息
- 与传统线下基于实物的传输方式相对应
纸币、硬币

数字货币

数据分析:
对数据的规律进行总结、提炼
决策
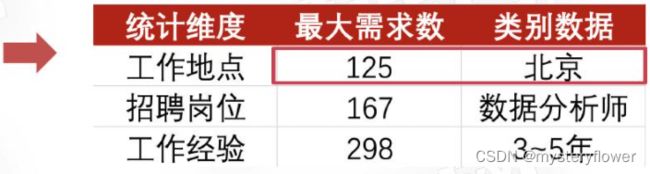
互联网 数据分析岗人才需求 => 线上 线下
招聘信息 => 统计职位数 => 同类比较
数据 => 生产材料
章节回顾
- 互联网 => 线上的传输方式
- 数据分析 => 利用数据规律进行决策
- 互联网数据分析 => 对基于线上产生的数据进行分析
课后作业
以下哪个是基于互联网的数据分析:
A. 统计某产品线下调研结果
B. 分析某课程线上引流效果
2-1 什么是数据
从认识数据开始
认识数据
- 数据分类
- 统计指标
- 分布形态
- 数据分析流程
- 常用数据分析工具
什么是数据
- 数据是对事物的描述和记录


数据的特性
根据计量层次,进一步对数据进行分类
黄瓜、番茄、森林、书本,无法计算比较,计量层次低
1,2,3,4,5,这些数据可以计算比较,那么计量层次就高
定类数据
颜色:红色、白色、黄色
性别:男性、女性
职位:数据产品经理、数据运营、市场营销运营
按照类别属性进行分类,各类别之间是平等并列关系
这种数据不带数量信息,并且不能在各类别间进行排序
主要数值运算,计算每一类别中的项目的频数和频率
定序数据
受教育程度:小学、初中、高中、大学、硕士、博士
季度:春、夏、秋、冬
等级:合格、良好、优秀
定序数据之间可以进行排序、比较优劣
通过将编码进行排序,可以表示之间的高低差异
定距数据
温度:20、50、100
成绩:50、65、70、100
年龄:8、25、40、60
具有一定单位的实际测量值
定距数据的精确性比定类数据和定序数据更高
可以计算出各变量之间的实际差距(加、减)
定比数据
利润:10万、20万、30万
薪酬:3000、6000、9000、12000
用户数:210、3500、49000
可以比较大小,进行加、减、乘、除运算
定距尺度中,0表示数值,定比尺度中,0表示"没有"
定比数据中是存在绝对零点的,而定距数据不存在
定性、定量数据
定性数据(定类数据、定序数据)
是一组表示事物性质、规定事物类别的文字表述型
定类数据(定距数据、定比数据)
指以数量形式存在着的属性,并因此可以对其进行
数据矩阵/二维数据表
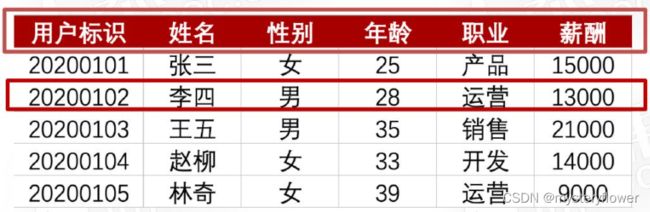
- 数据属性、维度
- 观测值、记录
章节回顾
什么是数据
数据的类型
定类数据 => 定性数据
定序数据 => 定性数据
定距数据 => 定量数据
定比数据 => 定量数据
数据矩阵是怎么组成的
课后作业
对应的是什么数据类型

定性:姓名、性别、职业
定量:用户标识、年龄、薪酬2-2 什么是统计指标
为什么要学习统计指标

- 技能
- 薪酬水平
- 工作年限
- 业务背景
- 汇总
- 处理
- 计算
什么是统计指标
- 体现总体数量特征的概念和数值
- 根据数据分析的目的不同,统计指标也会变化
房屋设计:建筑面积、竣工面积、技术装备率
提升用户转化率:网站浏览量、着陆页、跳失率
选择理财产品:往期业绩、风险系数、年化收益
总量指标
GDP(国内生产总值)
总人口 => 总和(SUM)
销售总额
- 特定条件下的总规模、总水平或工作总量
- 是一种最基本的统计指标
平均指标
用一个数字显示其一般水平
=> 集中趋势指标
相对指标


- 两个有联系的现象数值相比得到的比率
- 描述的是相对关系,而不是总体情况
比例、比率、倍数

- 比例 = 各数据/总比 %
- 1:2:3:...:10:11:12
- 比率 = 数据项:数据项
- 年末/年初 = 12
- 倍数 突出上升、增长幅度
环比、同比
近2个月的销售情况?
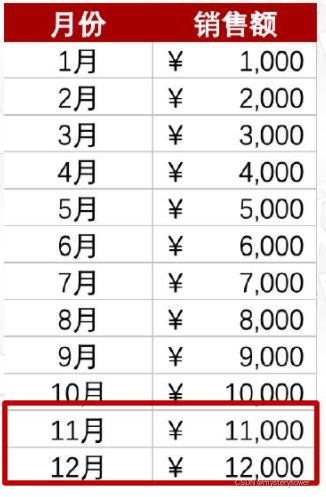
环比增长率:
(本期数-上期数)/上期数*100%
(12000-11000)/11000 = 9.09%
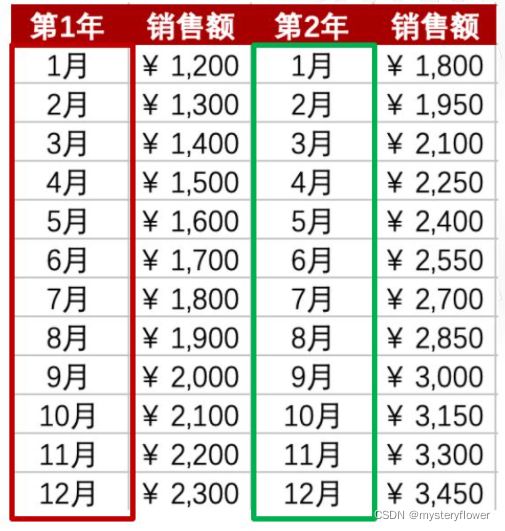
- 同比增长率:
- (本期数-同期数)/同期数*100%
- (3450-2300)/2300 = 50%
环比更注重短期的涨幅表现
同比更注重长期的
章节回顾
- 总量指标:描述总体估摸的
- 相对指标:部分与整体关系
- 平均指标(集中趋势):数据一般水平
课后作业

1、今年销售总额
2、每月占总销售的比例
3、平均每月销售额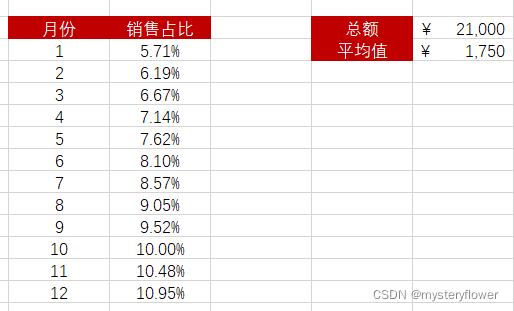
2-3 统计指标:集中趋势
集中趋势指标的特点
哪个营销渠道引流效果最佳?
什么岗位的薪酬水平最高? => 平均值
哪个产品最受欢迎?
…… => 初步结论
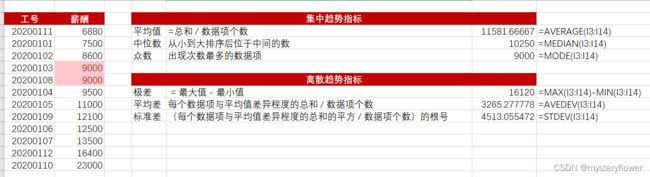
什么是集中趋势指标
- 用于体现数据一般水平的指标
- 最快速了解样本数据的概况
- 最常用的集中趋势指标就是平均值
平均值
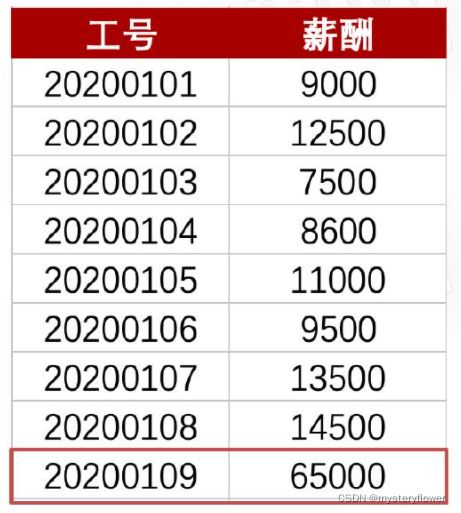
- = 所有数据相加/数据的个数
- 加和:151100
- 平均值:16789
- 去除异常值:10762
- 差异:6026
- 具有一定误导性,对异常数不敏感
中位数
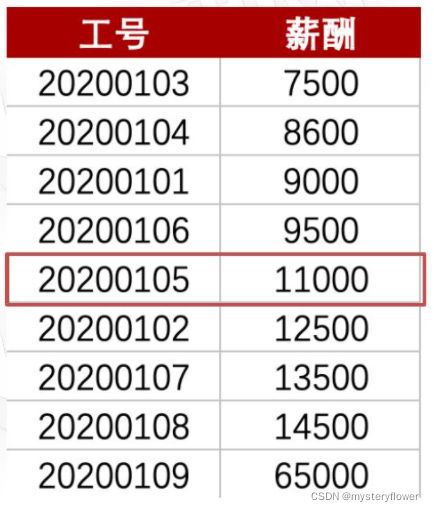
- 按顺序排列后,居于中间位置的数
- 奇数:位于(n+1)/2位置的数
- 偶数:最中间的两位数相加/2
- 更具有代表性
众数
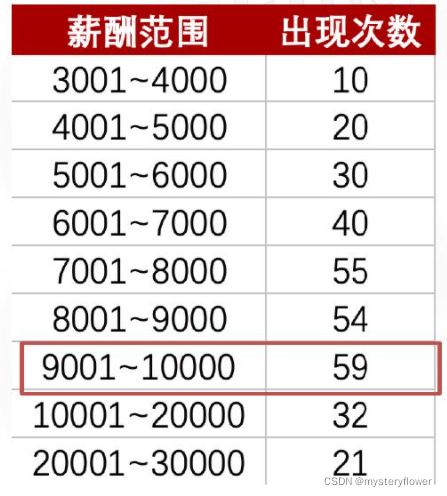
- 出现次数最多的数值
- 反应的是局部特征、密集度
- 众数可以有多个
章节回顾

- 平均值:黄线
- 中位数:绿线
- 众数:蓝线
课后作业

1、计算平均值、中位数、众数
2、哪一组薪酬水平更高

2-9 本章小结
数据的基本特征
什么是数据
- 数据类型
- 集中趋势 分布形态
- 离散趋势 异常值
数据分析有哪些内容
数据分析流程

数据分析技能

2-4 统计指标:离散趋势
什么是离散趋势指标

- A(蓝线):10.22 ~ 10.88
- B(橙线):10.22 ~ 11.43
- 股票B比股票A更离散
体现内部差异度的指标
- 极差
- 平均差
- 标准差
极差
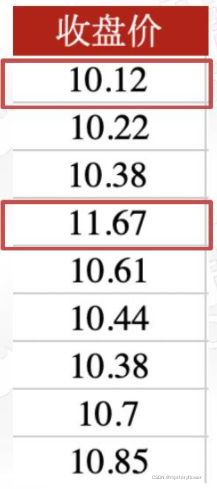

- 相距最远的两个点之间的距离
- 极差 = 最大值 - 最小值 = 1.55
- 数据内部最大的差异情况

平均差
- 一组数据与平均值差异
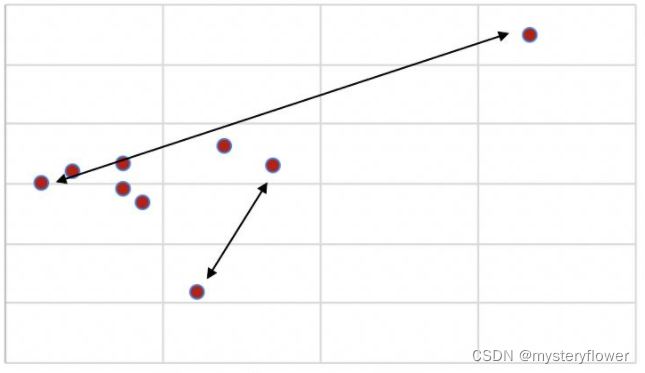


- 数据项与平均值的差距越大
- 数据越分散,反之越集中

- 股东回购、政策利好、供需失衡
- 事件驱动型的数据,在样本量较小的时候,容易导致误差
- 对离散值更敏感
标准差

- 优化过的更能代表离散程度的指标

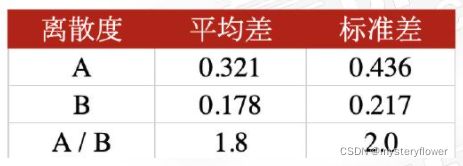
- 更直观的了解差异程度
- 最常用的离散指标
章节回顾
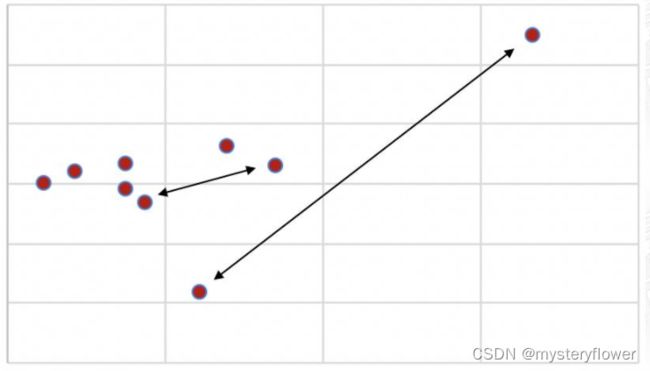
- 极差
- 平均差
- 标准差
课后作业
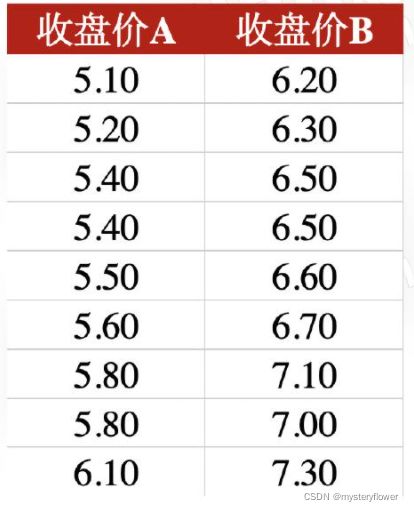
- 1、计算极差、平均差、标准差
- 2、判断哪只股票的风险更高
- 提示:标准差越大,风险越高


- 极差:MAX(A2:A10)-MIN(A2:A10)
- 平均差:AVEDEV(A2:A10)
- 标准差:STDEVP(A2:A10)
- 平均值:AVERAGE(A2:A10)
2-5 统计指标:分布形态
什么是分布形态
数据 => 点线面
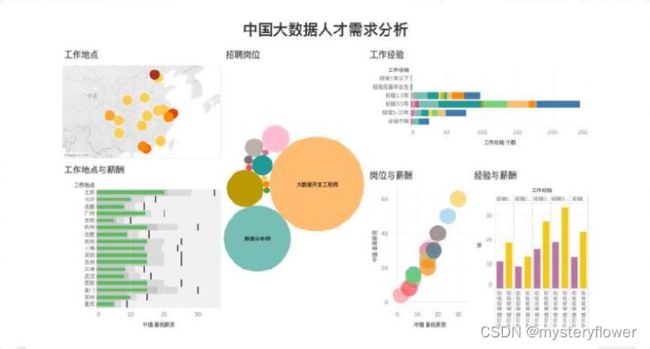
数据相关的工作
企业对工作经验有什么要求
- 应届毕业生
- 经验1年以下、经验1-3年
- 经验3-5年、经验5-10
- 经验不限
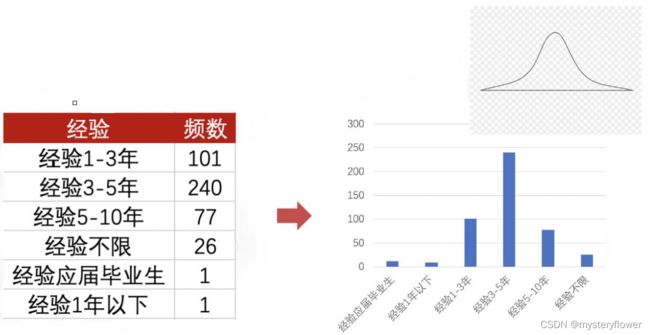
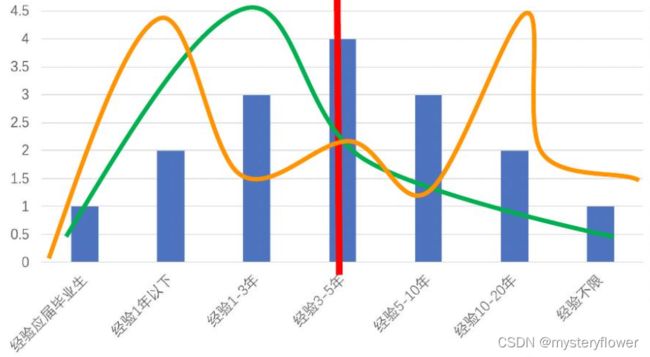
- 平均值: 红线
- 中位数
- 众数
- 极差
- 平均差
- 标准差
数据分析岗位 vs 大数据开发

高度 => 一般水平:均值
宽度 => 离散程度

分布形态的具体体现

章节回顾
- 分布形态:图表化后呈现出来的形态
- 常见形态:左偏分布、右偏分布、正态分布
课后作业
1、判断数据样本的分布形态
2、计算均值、中位数以及众数,能发现什么规律吗


2-6 识别异常值
为什么要学习异常值
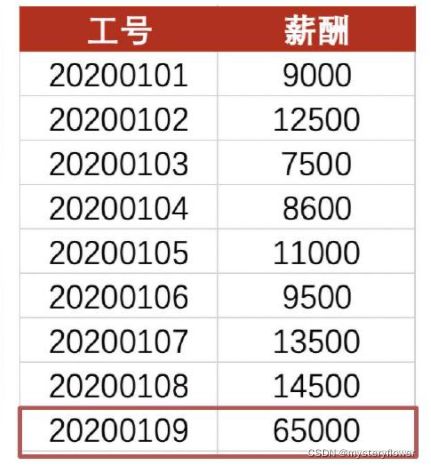
- =所有数据相加/数据的个数
- 加和:151100
- 平均值:16789 差异:6026
- 去除异常值:10762
- 具有一定误导性,对异常数不敏感
什么是异常值

- 与平均值偏差极大或极小的值
- 也叫离群点
- 取决于分析的业务对象
- 周期性产业
如何识别异常值

观察检测值与整体数据的差异度
- 计算与平均值的倍数
- 更多检测方法:Tableau、Python
异常值的附加信息
基金业绩走势


章节回顾
- 异常值的基本定义
- 如何识别异常值
- 异常值的附加价值
课后作业
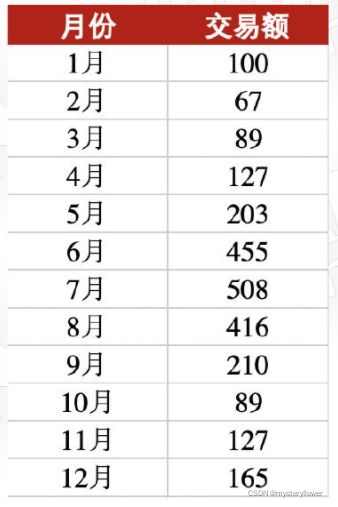
1、是否存在异常值
2、你是如何检测的
3、分析下可能的成因,
提示:旅游业为周期性行业
* 海南三亚交易额数据,单位:亿元

2-7 处理异常值
异常值的处理
检测/识别 => 判定 => 处理
判定异常值
1. 错误记录:修改正确

2. 错误添加:删除
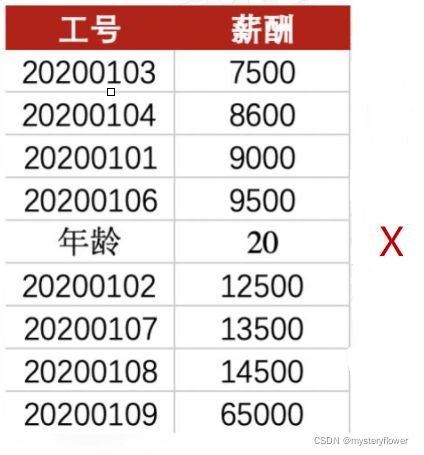
3. 正确、真实
3.1 是否反映特殊事件:修改、调整
3.2 周期性数据:不做处理


处理异常值
1. 错误数据
填充空值
填充样本平均值

2. 正确、真实,需要做调整的数据
根据实际情况调整:数值*需调整比率
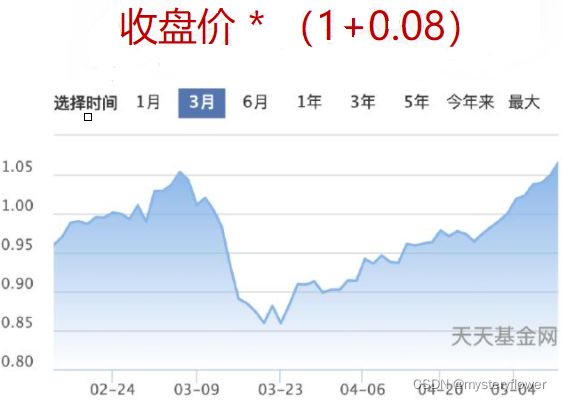
章节回顾
检测/识别:与总体差异度
判定:是否需要处理
处理:调整方式
课后作业
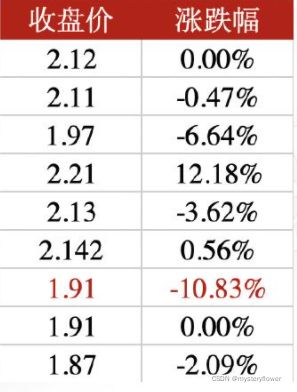
1. 标红数据是否为异常值
2. 猜测产生的原因
3. 假设当天分红导致净值下跌3%,如何调整数值使其恢复正常水平

2-8 数据分析流程
数据分析的流程
- 目标确定
- 数据获取
- 数据清洗
- 数据整理
- 描述分析
- 洞察结论
- 撰写报告
目标确定
- 解决什么问题?达到什么目的?
- 描述性分析:针对现有情况分析
- 预测性分析:基于现状,预测未来情况
描述性分析

预测性分析

数据获取
字段设计
- 平均销售额、销售总额、增减幅度
- 基础数据:订单号、交易日期、交易金额
数据提取
- 销售管理软件,导入导出
- 互联网企业,使用SQL从数据库提取
数据清洗
异常值:异常值的识别、判定、处理
空白值、无效值、重复值 => 修正、平均值填补、删除
数据整理
格式化:日期的处理、行列格式化
指标计算:基础的计算,如平均值、总额
描述分析
数据描述
- 数据的基本情况
- 数据总数、时间跨度、数据来源等
指标统计
- 分析实际情况的数据指标
- 变化、分布、对比、预测
变化:随着时间变动而增减近期销售额表现
分布:不同层次上的表现,地域分布、人群分布

对比:数据项之间的对比、产品线对比、用户数对比
预测:根据现有的增减幅度预测未来销售额
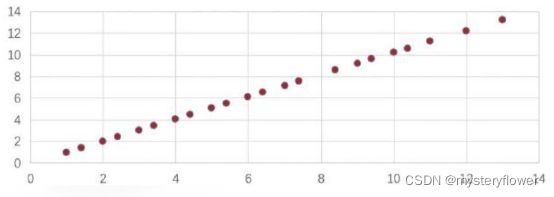
洞察结论
- 数据报告的核心
- 体现数据分析能力

撰写报告
- 报告背景
- 业务现状
- 报告目的
- 解决什么问题
- 数据基本情况
- 数据可信度
- 可视化图表
- 数据的可理解程度
- 策略选择
- 提出解决方案
章节回顾
- 目标确定
- 数据获取
- 数据清洗
- 数据整理
- 描述分析
- 洞察结论
- 撰写报告
课后作业
分析过去4周的支出情况
1. 需要哪些数据
2. 计算哪些指标

第02周 Excel从入门到表格分析
1-1 Excel基本功能
招聘需求分析

数据分析岗位招聘信息 => 数据分析岗位需求分析报告
Excel电子表格
预处理数据样本:清洗、提取、整合
Excel电子表格
电子:存储形式,通过电子设备存储
- 增删改查
- 可视化图表
- 透视表、自动化报表
- 打印、数据自动填充
基本功能

Excel常用功能
1. 预处理
文本函数
重复数据的处理
拆分列数据
数据排序与筛选
2. 统计和分析
数学函数:SUM、AVERAGE
逻辑函数:OR、NOT
条件聚合函数:COUNTIF、SUMIF
LOOKUP引用函数
3.
数据透视表:Pivot Table
认识图表类型
制作可视化图表
章节回顾
7个基础功能板块
常用功能介绍
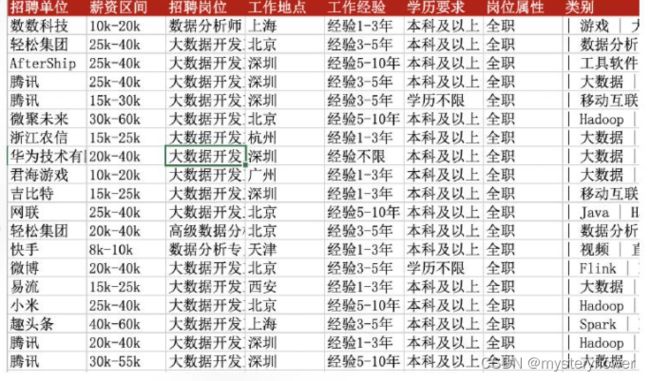
课后作业
1. 公式的分类有哪些
2. 你最常用的函数有哪些
1. 公式的分类
- 自动求和
- 财务
- 逻辑
- 文本
- 日期和时间
- 查找和引用
- 数学和三角函数
- 其他函数
2. 最常用的函数
- 数学函数
1-2 文本函数
什么是函数
计算过去4周的平均支出?

什么是文本函数
对文本进行提取、查找、转换、更新的函数
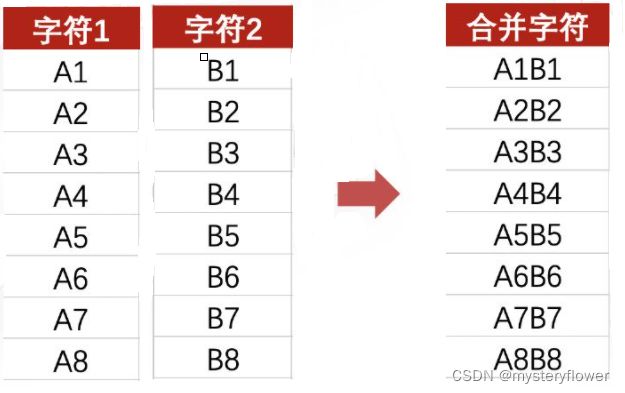
"文本合并"函数:CONCATENATE
文本函数的应用
实战演练
1、MID函数

双击第一个单元格右下角十字+,列数据自动填充
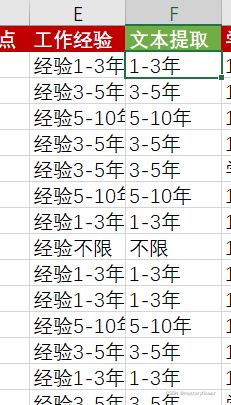
2、SUBSTITUE函数
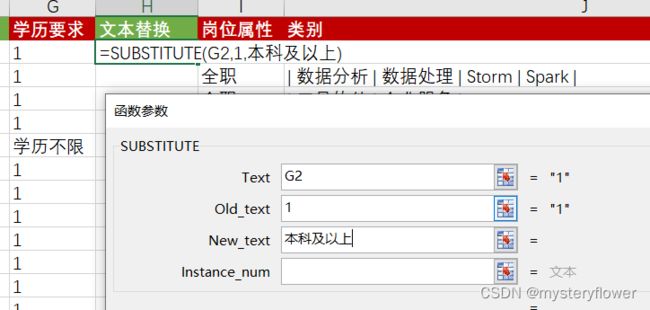
3、FIND函数



章节回顾
文本函数:是对文本类数据进行处理
- mid:提取文本
- substitue:替换文本
- find:验证文本

课后作业

去除以下字符:
- 经验
- 职位描述:
- 岗位描述:
- 工作职责:

=SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(B2,"工作职责:",""),"岗位职责:",""),"职位描述:","")
=MID(C2,3,6)
1-3 数学函数
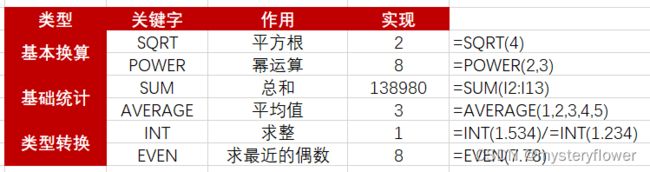
什么是数学函数
- 文本:文本函数,清洗、格式化
- 数值:数学函数、统计计算
注意:
- 1.STDEV:用途:估算样本的标准偏差。它不计算文本值和逻辑值(如 TRUE 和 FALSE)。它反映了数据相对于平均值(mean)的离散程度。
- 2.STDEVA :基于样本估算标准偏差。标准偏差反映数值相对于平均值 (mean) 的离散程度。文本值和逻辑值(如 TRUE 和 FALSE)也将计算在内。
- 3.STDEVP:用途:返回整个样本总体的标准偏差。它反映了样本总体相对于平均值(mean)的离散程度。
简单说函数stdev的根号里面的分母是n-1,而stdevp是n,如果是抽样当然用stdev。
在十个数据的标准偏差如果是总体时就用STDEVP,如果是样本是就用STDEV。
至于STDEVA与STDEV差不多,只不过它可以把逻辑值当数值处理。
章节回顾
- 数学函数:是对数值类数据进行计算
- 基本功能:数学换算、统计、类型转换
- 计算集中趋势、离散趋势
课后作业

计算集中趋势指标:平均值、中位数、众数

1-4 处理重复数据
数据预处理的重要性
清洗、格式化、去重、排序、基础计算 >=50%
数据准确性
统计结果与结论
数据预处理的内容
数据的清理
- 缺失值
- 离群值/异常值
- 重复值
数据的合并、汇总
- 删除、均值填充
如何定位重复数据

针对海量数据,如何快速定位?


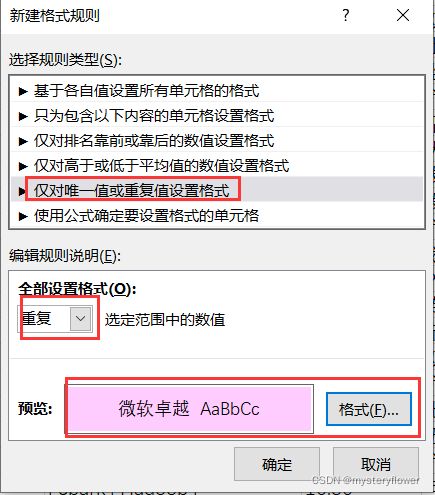
选择单列或这个文本,进行去重处理,结果不是想要的。
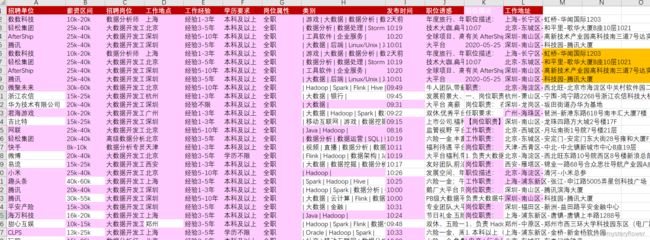
清除规则


章节回顾
- 预处理流程:数据清洗、整合
- 定位重复项:开始菜单-单元格规则,单列重复项、手动
- 去除重复项:数据菜单-去除重复项,多列重复项、自动
课后作业
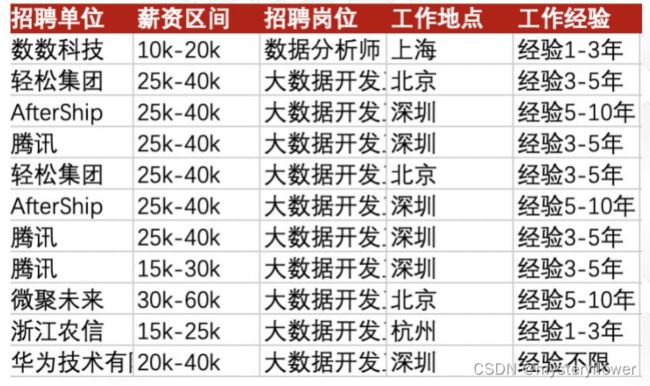
- 1. 去重招聘信息
- 2. 回答去重后的行数

1-5 拆分列数据
为什么要拆分列数据

实例演练
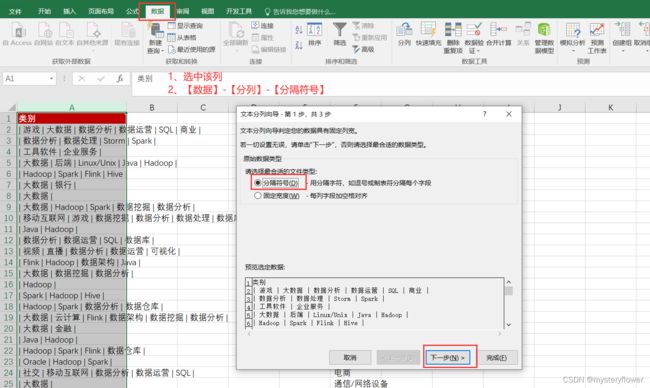

点击【下一步】,再点击【完成】

将所有列都去重处理,再放在同一列,然后进行去重处理即可
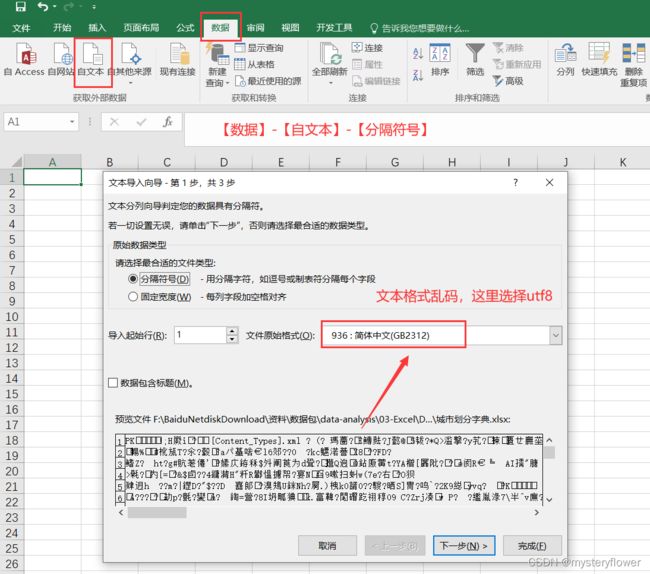
如何拆分列数据
导入数据时的分列
- 数据 - 导入格式 => CSV
- 最常用的数据格式,可读性,便利性
- 爬虫,最常用的存储方式

章节回顾
拆分列数据
- 1. 现有数据
- 2. 导入数据

课后作业

1. 拆分类别数据
2. 对拆分后的数据去重
3. 统计标签个数:81
1-6 数据排序和筛选
为什么要排序

单位招聘需求量
薪资范畴
工作经验要求
× 理性认识
√ 排序
如何对数据进行排序
根据工作经验排序,选中所有,【排序和筛选】-【自定义排序】-【工作经验】
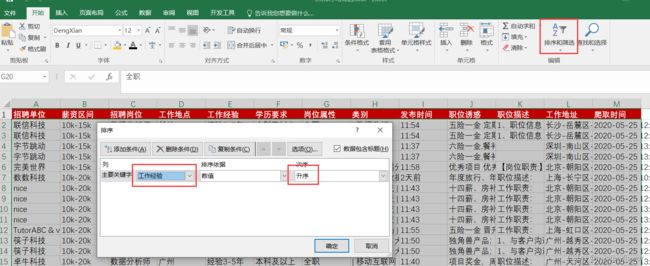
将“经验1年以下”改成“经验0-1年”
将“经验应届毕业生”改成“经验0 经验应届毕业生”
【排序和筛选】-【筛选】,选中“数据分析师”

章节回顾
- 排序:形成更直观的认识
- 筛选:快速提取数据,且不影响原有数据
课后作业
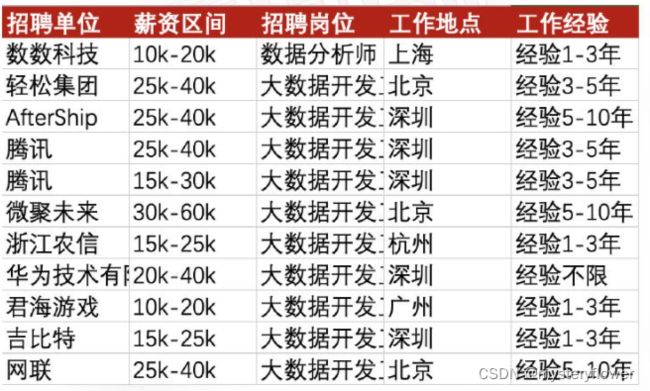
1. 薪资区间从小到大排序
2. 筛选出薪资10k-20k,地点上海,工作经验1-3年的数据

2-1 逻辑函数
数据预处理
- 函数的概念,基本使用方法:文本函数+数学函数
- 清洗、预处理:去重、分列,排序与筛选
什么是逻辑函数

- 正在下雨:TRUE真
- 没有下雨:FALSE假
- 能明确用[是否]或[真假]这样的逻辑值来回答
什么是逻辑值
真假:TRUE FALSE 1 0, 一种计算机语言
逻辑值的运算:与运算 AND、或运算OR、非运算NOT
逻辑运算:与、或、非
交集
1 && 1 = 1
1 && 0 = 0
0 && 0 = 0
并集
1 || 1 = 1
1 || 0 = 1
0 || 0 = 0
求反
!0 = 1
!1 = 0
逻辑函数的基本功能

根据发布时间确定上下午
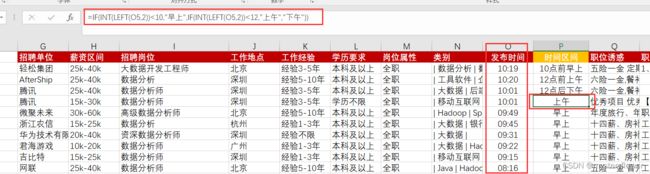
=IF(INT(LEFT(O5,2))<10,"早上",IF(INT(LEFT(O5,2))<12,"上午","下午"))
=IF(INT(LEFT(O5,2))<12,"上午","下午")章节回顾
- 对推论进行真假判断的函数
- IF函数:对不同的判断结果进行数值匹配
课后作业
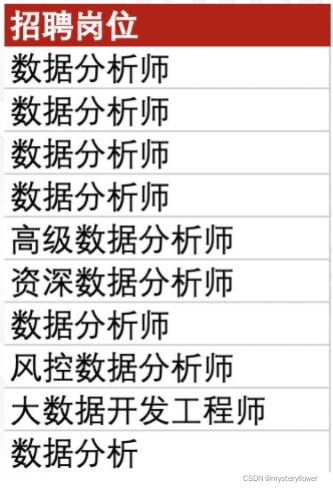
判断岗位是否为数据分析师
1)是,输出“目标岗位”
2)不是,输出空值“”

=IF(COUNTIF(A2,"*开发*"),"开发岗","非开发岗")
=IF(A2="数据分析师","目标岗位","")2-2 条件聚合函数
什么是条件聚合函数

职位需求总数:SUM函数
一二三线城市职位需求总数:?
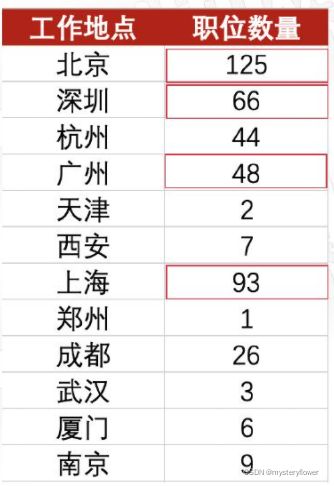
SUM函数:点选符合标准的城市
缺点:
- 太慢,每次都需要点选
- 不灵活,不能随原始数据变化
SUMIF(S)条件聚合函数:在公式中写死条件,原始数据顺序随意
=SUMIFS(E:E,D:D,{"北京","上海","广州","深圳"})如何使用条件聚合函数

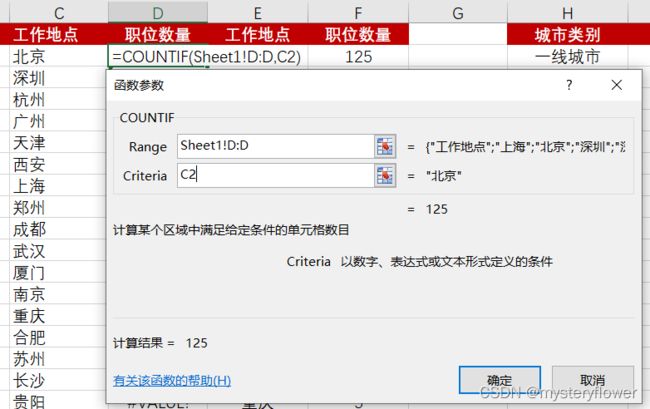
章节回顾
条件聚合函数:对符合特定条件的数据项进行统计;数学函数 + 逻辑函数
SUMIF(S):针对符合条件的数据项求和
COUNTIF(S):针对符合条件的数据项计次
课后作业
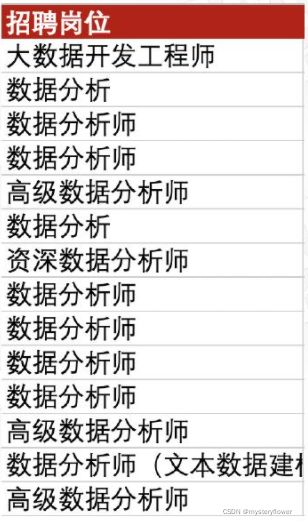
1. 对招聘岗位进行去重处理
2. 统计每一类岗位出现的总次数
3. 统计 *开发工程师与非*开发工程师的职位总数

统计频率:=COUNTIF(C:C,E2)
开发类岗位:=COUNTIF(C:C,"*开发工程师*")2-5 认识图表
为什么要可视化数据


异常数据?
特殊现象?

- 人对图形比文字更敏感
- 逐步发展、广泛使用
图表类型
对比分析:数据项之间的大小关系,比较型图表

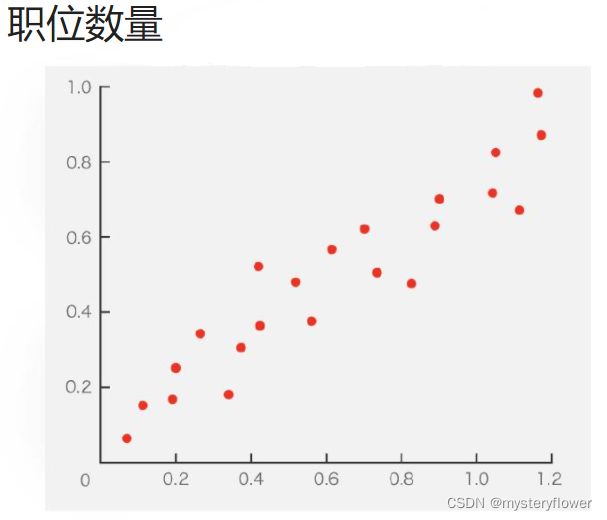
职位需求量与城市划分类型存在相关性?
- 两组数据的相关性分析
- 散点图

变量A随着变量B增加
正相关
关系型图表
城市划分:GDP从小到大


章节回顾
可视化数据的重要性:更有助于理解
图表类型
- 折线图:基于时间的变化
- 直方图:比较类别数据的大小
- 散点图:变量间的相关性
- 饼图、堆积图:部分与整体的比例关系
课后作业
1. 高频能力要求
2. 近5年职位需求分析
3. 行业类型与平均薪酬
4. 数据洞察

2-3 查找与引用函数
什么是查找与引用函数

VLOOKUP函数

- MAX(数据区域)
- VLOOKUP(..)

- 消耗人工
- Excel自动化:设定函数、自动化提取
如何使用VLOOKUP函数
2-8 本章小结
如何使用Excel进行数据分析
1. 预处理
- 文本函数
- 数学函数
- 去重功能
- 列拆分
2. 汇总与统计
- 逻辑函数
- 条件聚合函数
- 查找与引用函数
- 数据透视表
3. 可视化
- 选择图表
- 创建图表
数据分析人才需求报告
数据洞察:数据报告
章节预告
- 数据提取工具:SQL
- 数据可视化面板:Tableau
- 大数据处理与分析语言:Python
- 2D绘图库:Matplotlib
第06周 Python实现网络爬虫
1-1 什么是爬虫
电影 => 电影评分网站 => 抓取网站信息

爬取信息
为什么要爬虫

推荐观看指数 = 评分*0.2 + 导演*0.2 + 演员*0.2 + 评价分数*0.4 + 剧情偏好
Python如何实现爬虫
定位目标网址:url
获取网页信息:Requests库
提取目标信息:网页结构,BeautifulSoup库
章节回顾
爬虫是什么:利用技术手段实现网页信息的抓取
为什么要爬虫:获取以及处理信息的效率倍增
如何实现:Requests库,访问并获取网页信息
BeautifulSoup库,解析并提取信息
课后作业
1. 访问网页并获取网页信息,可以使用的Python库?
2. 解析网页结构并提取目标信息,可以使用的Python库?
- 1. request库
- 2. beautifulsoup库
1-2 Requests库入门
Requests 提供哪些功能
- 官网文档
- 实例代码,功能说明
- 应用过程中遇到问题
- 搜索解决方案
在百度里搜【requests官方中文文档】,选择【快速入手】
https://docs.python-requests.org/zh_CN/latest/user/quickstart.html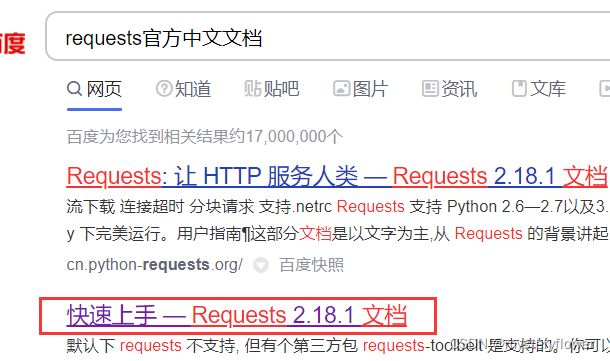
https://html5-editor.net/ # 可将html代码放入此网站查看网页显示情况Request库入门.py
# 导入模块
# 需要安装Requests库,可通过anaconda安装 或 pip install requests
import requests
# https://movie.douban.com/
# 定义url
url_douban_movie = 'https://movie.douban.com/' # 注意:http和https一定要添加
# headers 在requests入手文档中搜索headers
headers = {'user-agent': 'my-app/0.0.1'}
# 访问、并获取网页信息
# response 响应 request 请求
# response_douban_movie = requests.get(url=url_douban_movie) # 此时打印页面内容为空,网站有反爬虫机制,加上headers参数伪装成浏览器请求
response_douban_movie = requests.get(url=url_douban_movie, headers=headers)
# print(response_douban_movie.text) # 打印响应内容,此时为页面html代码,可复制html代码保存到文件test.html
# https://html5-editor.net/ 可将html代码放入此网站查看网页显示情况
# XX电影主页
url2 = "https://movie.douban.com/subject/34961898/"
# url2 = "https://movie.douban.com/subject/34961898/?tag=热门&from=gaia"
response2 = requests.get(url=url2, headers=headers)
# print(response2.text)
# 百度百科
url3 = "https://baike.baidu.com"
response3 = requests.get(url=url3, headers=headers)
# print(response3.text)章节回顾
基本功能:
- 与网站简历连接
- 抓取网站内容
- 实现登录认证
代码编写
- 豆瓣电影主页
- 单个电影页面
- 百度百科(图片加载)
课后作业
抓取豆瓣电影《楚门的世界》的网页信息:https://movie.douban.com/subject/1292064/
# 楚门的世界
import requests
headers = {'user-agent': 'my-app/0.0.1'}
url = "https://movie.douban.com/subject/1292064/"
response = requests.get(url,headers=headers)
print(response.text)1-3 认识HTML网页结构
为什么要了解网页结构

https://movie.douban.com/subject/1292064/
打开页面
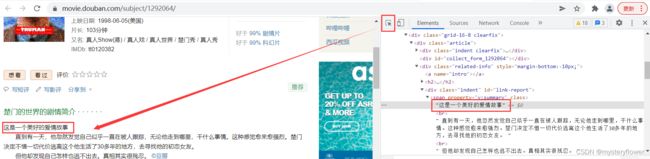
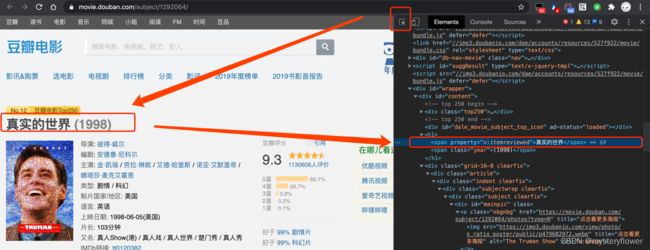
快捷键 F12/Ctrl+Shift+I,打开开发者工具
Elements板,最左边小箭头,可用于查看页面元素,可临时修改页面内容
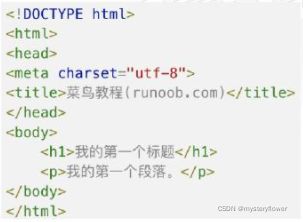
HTML网页结构
标题
电影简介
 特色介绍
影评
特色介绍
影评
这是一个段落
这是一个重点
这是一个段落
这是一个重点
这是一个段落
这是一个重点
相关推荐
章节回顾
认识网页结构:通过网页标签定位数据
定位标识符:浏览器开发者工具,目标信息的标签、标识
网页的基本结构
课后作业
改写电影页面《楚门的世界》:
1.将名字改为《真实的世界》
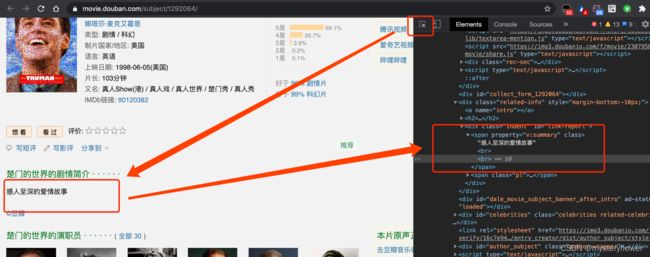
2.将简介改为:"感人至深的爱情故事"
3.将电影封面改为任意网络图片(替换图片链接)

1-4 BeautifulSoup库入门
BeautifulSoup 有哪些功能
- 官网文档
- 实例代码,功能说明
- 应用过程中遇到问题
- 搜索解决方案
在百度里搜【BeatuifulSoup 官方文档】,选择【快速入手】
https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/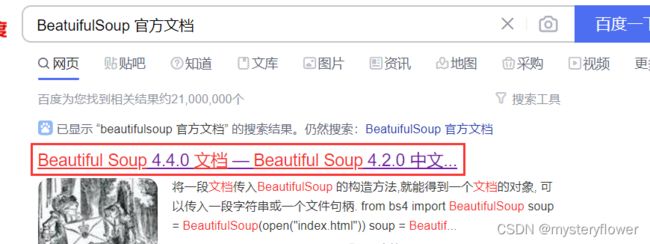

安装命令:
pip install beautifulsoup4BeatifulSoup库入门.py
import requests
from bs4 import BeautifulSoup
# 获取网页全部信息
url = "https://movie.douban.com/subject/1292064/"
headers = {'user-agent': 'my-app/0.0.1'}
response = requests.get(url=url,headers=headers)
# print(response.text)
# print("\n"+("-"*50)) # print("\n--------------------------")
# 解析网页
soup = BeautifulSoup(response.text, 'html.parser')
# print(soup.prettify()) # 按照标准的缩进格式的结构输出
# soup = soup.prettify()
# 查看 Beautiful Soup 文档【指定文档解析器】
# 提取目标消息
# print(soup.title) # 提取title标签
# print(soup.title.text) # 提取title标签内容
print(soup.title.string) # 标题
# print(soup.find_all(property="v:summary")) # property="v:summary"
print(soup.find_all(property="v:summary")[0].text)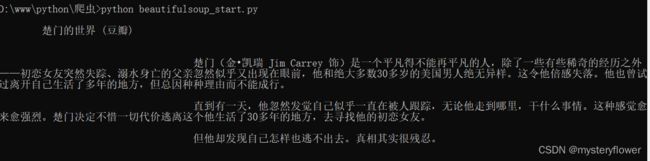
章节回顾
基本功能:匹配目标标签、提取信息
代码编写:
soup = BeautifulSoup(html)
soup.prettify()
soup.find(tag=value)课后作业
1. 美化获取到的网页数据
2. 提取标签文本
3. 提取短评部分的所有文本

2-1 获取目标信息
Python阶段目标
- 分析电影数据
- 电影总量、评分情况、国家分布、题材偏好
- 获取数据、预处理、计算分析、可视化
获取数据-电影简介

获取目标信息.py
import requests
from bs4 import BeautifulSoup
def get_list(soup_list):
"""
清洗解析后的网页信息,并以列表形式返回
:params soup_list: bs_list
:return: list
"""
list = []
for ele in soup_list:
list.append(ele.string)
return list
# 访问网页、获取信息
url = "https://movie.douban.com/subject/1292064/"
headers = {'user-agent': 'my-app/0.0.1'}
response = requests.get(url=url,headers=headers)
# 获取目标信息
soup = BeautifulSoup(response.text,'html.parser')
# print(soup.prettify())
# 存储容器
movie_info = {}
# 电影名称
# property="v:itemreviewed"
# movie_name = soup.find(property="v:itemreviewed")
movie_info['title'] = soup.find(property="v:itemreviewed").string
# print(movie_name)
# 简介部分
movie_info['director'] = soup.find(rel="v:directedBy").string #导演
movie_info['writer'] = soup.find_all(class_="attrs")[1].string # 编剧
# actlist = soup.find_all(rel="v:starring")
# for 遍历数据项,.string获取目标信息
# act_list = []
# for ele in soup.find_all(rel="v:starring"):
# act_list.append(ele.string)
# # print(act_list)
# actors = act_list # 演员列表
movie_info['actors'] = get_list(soup.find_all(rel="v:starring")) # 演员列表
movie_info['genre'] = get_list(soup.find_all(property="v:genre")) # 类型
movie_info['language'] = soup.find(text="语言:").next_element.strip() # 语言
movie_info['release_date'] = soup.find(property="v:initialReleaseDate").string # 上映日期
movie_info['runtime'] = soup.find(property="v:runtime").string # 片长
# 评分部分
movie_info['average'] = soup.find(property="v:average").string
movie_info['votes'] = soup.find(property="v:votes").string
# print(movie_info)
# for k,ele in movie_info.items():
# print(k,': ',ele)
for key in movie_info:
print(key, ': ', movie_info.get(key))章节回顾
Python阶段目标
- 电影信息的抓取、存储
- 预处理、计算分析、可视化
提取电影信息

课后作业
提取电影基础数据

2-2 连续获取多个页面信息
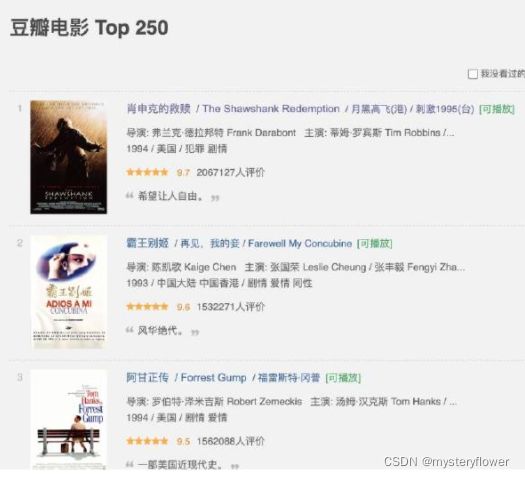
为什么要实现连续抓取
一部电影:电影单链
大量数据:?

电影链接 => 访问链接,获取基础数据 => 提取数据、页面跳转?
连续获取多个页面信息.py
import requests
from bs4 import BeautifulSoup
# 访问top250主页;访问页面、获取信息
# base_url = "https://movie.douban.com/top250"
headers = {'user-agent': 'my-app/0.0.1'}
# 跳转页面 ?start=225&filter=
# 先访问url链接,加上参数0,25,50,75~225
page = 0
max_page = 225 # start参数对应的值,也就是说第10页对应的start值
movie_links = []
movie_names = []
while page<=max_page:
# 访问页面
url = "https://movie.douban.com/top250?start=" + page.__str__() + "&filter="
response = requests.get(url=url,headers=headers)
# 实现每个页面信息的抓取: 电影单链
soup = BeautifulSoup(response.text,'html.parser')
# print(soup.find_all(class_="hd"))
for ele in soup.find_all(class_="hd"):
# print(ele.find(class_="title").string)
# print(ele.find('a',href=True).attrs['href']) # BeautifulSoup如何获取到href
movie_names.append(ele.find(class_="title").string)
movie_links.append(ele.find('a',href=True).attrs['href'])
# 修改start参数
page += 25
# 验证数据正确性
# print(url)
# 浏览所有抓取到的信息
for name,link in zip(movie_names,movie_links):
print(name, ': ', link)
# movie_links = []
# movie_names = []
# base_url = "https://movie.douban.com/top250"
# for start in range(0,250,25):
# url = base_url + "?start=" + start.__str__() + "&filter="
# response = requests.get(url=url,headers=headers)
# soup = BeautifulSoup(response.text,'html.parser')
# for title in soup.find_all(class_="hd"):
# movie_names.append(title.find(class_="title").string)
# movie_links.append(title.find('a',href=True).attrs['href'])
# for movie_name,movie_link in zip(movie_names,movie_links):
# print(movie_name, ': ', movie_link)章节回顾
为什么要连续抓取
- 大数据的需求
- 自动化的手段快速获取数据
如何实现连续抓取
- 理清跳转页面的逻辑
- URL参数控制显示页面
代码编写
- 跳转页面、抓取链接
课后作业
抓取TOP250所有高分电影链接

2-3 整合爬虫功能函数
函数
- 获取网页信息
- 获取电影链接
- 爬取电影信息

- 随意组合、按序执行:检索麻烦、多次改动
- 变量、函数:结构化、灵活更新
整合爬虫功能函数.py
import requests
from bs4 import BeautifulSoup
headers = {'user-agent': 'my-app/0.0.1'}
movie_links = []
movie_names = []
def get_list(soup_list):
"""
清洗解析后的网页信息,并以列表形式返回
:params soup_list: bs_list
:return: list
"""
list = []
for ele in soup_list:
list.append(ele.string)
return list
# 1. 访问主页面,并且完成页面跳转
def get_page(page_link):
page = 0
max_page = 225 # start参数对应的值,也就是说第10页对应的start值
while page<=max_page:
# 访问页面
url = page_link + "?start=" + page.__str__() + "&filter="
response = requests.get(url=url,headers=headers)
get_links(response)
# 修改start参数
page += 25
# print(url)
# 2. 抓取每个页面所有的电影链接
def get_links(response):
# 实现每个页面信息的抓取: 电影单链
soup = BeautifulSoup(response.text,'html.parser')
for ele in soup.find_all(class_="hd"):
movie_names.append(ele.find(class_="title").string)
movie_links.append(ele.find('a',href=True).attrs['href'])
# 3. 根据电影链接,获取基本信息、评分信息
def get_infos(url):
# 访问网页、获取信息
response = requests.get(url=url,headers=headers)
# 获取目标信息
soup = BeautifulSoup(response.text,'html.parser')
# 存储容器
movie_info = {}
movie_info['title'] = soup.find(property="v:itemreviewed").string
try:
# 简介部分
movie_info['director'] = soup.find(rel="v:directedBy").string #导演
# movie_info['writer'] = soup.find_all(class_="attrs")[1].string # 编剧
writer = soup.find_all(class_="attrs")
# if len(writer)>1:
# movie_info['writer'] = soup.find_all(class_="attrs")[1].string
# else:
# movie_info['writer'] = ""
movie_info['writer'] = soup.find_all(class_="attrs")[1].string if len(writer)>1 else ""
movie_info['actors'] = get_list(soup.find_all(rel="v:starring")) # 演员列表
movie_info['genre'] = get_list(soup.find_all(property="v:genre")) # 类型
movie_info['language'] = soup.find(text="语言:").next_element.strip() # 语言
movie_info['release_date'] = soup.find(property="v:initialReleaseDate").string # 上映日期
movie_info['runtime'] = soup.find(property="v:runtime").string # 片长
# 评分部分
movie_info['average'] = soup.find(property="v:average").string
movie_info['votes'] = soup.find(property="v:votes").string
except AttributeError:
print("电影已下架")
for key in movie_info:
print(key, ': ', movie_info.get(key))
print('*'*100)
# return movie_info
# 获取每个页面信息 > 调用了获取页面所有电影链接 > for循环,调用获取信息的功能
if __name__ == '__main__':
# 调用功能1.实现页面的访问
get_page(page_link="https://movie.douban.com/top250")
# 测试
# get_infos("https://movie.douban.com/subject/26430107/")
# exit()
# 获取所有链接
# 浏览所有抓取到的信息
for name,link in zip(movie_names,movie_links):
print(name, ': ', link)
get_infos(link)章节回顾
- 为什么要函数化:结构化、改动方便、随意调用
- 如何函数化:def定义、功能拆分为函数
- 代码编写:跳转页面、抓取链接、抓取信息
获取网页信息
获取电影链接
爬取电影信息
课后作业
抓取TOP250所有高分电影信息
2-4 数据存储与代码优化
import requests
from bs4 import BeautifulSoup
import pandas as pd
headers = {'user-agent': 'my-app/0.0.1'}
movie_links = []
movie_names = []
all_infos = []
def get_list(soup_list):
"""
清洗解析后的网页信息,并以列表形式返回
:params soup_list: bs_list
:return: list
"""
list = []
for ele in soup_list:
list.append(ele.string)
return list
# 1. 访问主页面,并且完成页面跳转
def get_page(page_link):
# page = 0
page = 200
max_page = 225 # start参数对应的值,也就是说第10页对应的start值
while page<=max_page:
# 访问页面
url = page_link + "?start=" + page.__str__() + "&filter="
response = requests.get(url=url,headers=headers)
get_links(response)
# 修改start参数
page += 25
# print(url)
# 2. 抓取每个页面所有的电影链接
def get_links(response):
# 实现每个页面信息的抓取: 电影单链
soup = BeautifulSoup(response.text,'html.parser')
for ele in soup.find_all(class_="hd"):
movie_names.append(ele.find(class_="title").string)
movie_links.append(ele.find('a',href=True).attrs['href'])
# 3. 根据电影链接,获取基本信息、评分信息
def get_infos(url):
# 访问网页、获取信息
response = requests.get(url=url,headers=headers)
# 获取目标信息
soup = BeautifulSoup(response.text,'html.parser')
# 存储容器
movie_info = {}
movie_info['title'] = soup.find(property="v:itemreviewed").string
try:
# 简介部分
movie_info['director'] = soup.find(rel="v:directedBy").string #导演
# movie_info['writer'] = soup.find_all(class_="attrs")[1].string # 编剧
writer = soup.find_all(class_="attrs")
# if len(writer)>1:
# movie_info['writer'] = soup.find_all(class_="attrs")[1].string
# else:
# movie_info['writer'] = ""
# movie_info['writer'] = soup.find_all(class_="attrs")[1].string if len(writer)>1 else ""
movie_info['writer'] = get_list(soup.find_all(class_="attrs")[1].find_all('a')) if len(writer)>1 else ""
movie_info['actors'] = get_list(soup.find_all(rel="v:starring")) # 演员列表
movie_info['genre'] = get_list(soup.find_all(property="v:genre")) # 类型
movie_info['language'] = soup.find(text="语言:").next_element.strip() # 语言
movie_info['release_date'] = soup.find(property="v:initialReleaseDate").string # 上映日期
movie_info['runtime'] = soup.find(property="v:runtime").string # 片长
# 评分部分
movie_info['average'] = soup.find(property="v:average").string
movie_info['votes'] = soup.find(property="v:votes").string
movie_info['link'] = url # 链接
except AttributeError:
print("电影已下架")
# for key in movie_info:
# print(key, ': ', movie_info.get(key))
# print('*'*100)
# 电影信息存到列表中
all_infos.append(movie_info)
# return movie_info
# 获取每个页面信息 > 调用了获取页面所有电影链接 > for循环,调用获取信息的功能
if __name__ == '__main__':
# 调用功能1.实现页面的访问
get_page(page_link="https://movie.douban.com/top250")
# 测试
# get_infos("https://movie.douban.com/subject/26430107/")
# exit()
# 获取所有链接
# 浏览所有抓取到的信息
for name,link in zip(movie_names,movie_links):
print(name, ': ', link)
get_infos(link)
# print(all_infos)
# 将电影信息转为二维表,并存到电子表格中
data = pd.DataFrame(all_infos)
data.to_excel("250部高分电影.xlsx")章节回顾
list数据容器
- 存储多条电影数据
pandas库
- DataFrame转换为二维表
- to_excel存储为电子表格
课后作业
将250部电影信息存储为Excel电子表格
