腾讯 AI Lab 2021 年度回顾
感谢阅读腾讯AI Lab微信号第136篇文章。本文将进行2021年度回顾,祝大家新年快乐!
2021年,腾讯 AI Lab 迈入第 5 个年头。作为一个尚属「年轻」的实验室,在未知而广袤的科学世界中,我们还有很长的路要走。
回望过去这一年,似乎并不特殊:我们依然在坚持「学术有影响,工业有产出」的理念,在踏实科研、创新应用两个方向,稳步向「Make AI Everywhere」的愿景迈进。
同时,我们又确实看到一些特殊之处:疫情让日常生活的数字化需求陡然提升,也让 AI 有了更多用武之地。五年的积淀让我们能从事更深入、更前沿的研究,并在与学界和工业界的合作交流中,发挥企业视角的影响力;同时,我们的技术能够给更多现实问题提供解决方案,以有价值的产出让生活变得更美好。
下面首先将介绍 2021 年腾讯 AI Lab 在虚实集成世界、虚拟人、机器人三大研究方向上的重要探索,然后会分医疗、医药、游戏、内容等主题总结这一年的行业应用成果,最后会概述这一年在不同研究方向上的学术进展。
一、 加速迈向虚实集成世界:
虚拟人及机器人前沿研究
2021 年最火热的,莫过于对下一代互联网,也被称为「全真互联」这一概念的热烈讨论。我们看到,世界朝着数字化和虚拟化方向加速迈进,线上和线下更全面地一体化,实体和电子方式更深度地融合,从而把人、信息、物、服务、制造紧密连接在一起。
在 2020 年,腾讯 AI Lab 和 Robotics X 实验室主任张正友博士,首次提出了虚实集成世界(IPhD,Integrated Physical-Digital World)的概念,并从时间、空间到信息内容维度,解读了「全真互联」时代的四大技术关键点:现实虚拟化、虚拟真实化、全息互联网、智能执行体。在今年 11 月举办的腾讯数字生态大会上,张博士进一步阐释虚实集成世界的发展进程,解读了虚拟与现实正加速融合的趋势。

演讲视频可于大会官网查看:https://des.cloud.tencent.com/2021/
虚拟人与机器人是虚实集成世界中的两大重要组成,下面将介绍实验室今年在这两方面的进展。
虚拟人:多模态 AI 技术驱动的虚拟世界新伙伴
疫情是虚拟数字人产业发展的一道重要分水岭。现实空间常态防控背景下,人们倾向于在数字世界中寻求更多社交互动场景,因此虚拟世界的建设和讨论逐渐增多,相关技术及要素开始逐步构建,而虚拟数字人作为那个世界中人类角色的具象显现,也借势迎来更多关注。
腾讯 AI Lab 自 2017 年起开始虚拟人研究,目标是从语音、口型、表情到全身动作都实现高度拟人,并掌握听、说、读、写、想等全方位技能。团队将计算机视觉、语音/歌声合成和转换、图像/视频合成和迁移、自然语言理解等多模态的AI能力和技术融为一体,生成清晰、流畅、高质的可交互内容,未来将逐步探索虚拟人在虚拟偶像、虚拟助理、在线教育、数字内容生成等领域的应用。

诞生于 2020 年的 AI 虚拟人艾灵,是业内首个由 AI 驱动的虚拟偶像。经过一年「学习」,她新掌握了不少国风才艺:
写作:去年春节,她基于自研的文本创作模型 SongNet,通过H5程序为千万网友撰写藏头对联;5月,她的能力进一步升级,学会作词写诗。
书法:基于前沿图像生成技术,艾灵「拜」颜真卿、柳宗元、米芾和苏轼等中国书法大家为师,再使用图像生成对抗网络技术,“写出”神形兼备的书法字体。
演出能力升级:5月,她首次与青年歌手白举纲跨次元合作,共同演唱国风新歌《百川千仞》,在更大的舞台上让观众看到科技+文化的全新可能。
这套多模态技术系统框架适用于不同风格的虚拟人。在今年11月的数字生态大会,超写实 3D 虚拟人「小志」首度亮相,可以通过输入文本来合成语音「说话」,还能基于文本或语音自动生成准确的口型及生动自然的表情。
机器人家族「上新」:移动能力升级,探索工业场景
自 2018 年在深圳建立以来,腾讯 Robotics X 机器人实验室持续与腾讯 AI Lab 携手推进「AI+机器人」发展。继 2020 年推出四足机器人 Jamoca 后,机器人实验室今年发布了 3 项重要进展。
3月,首个软硬件全自研的多模态四足机器人 Max 发布。它采用创新性的足轮融合一体式设计,实现了「崎岖路面走得稳,平坦路面跑得快」。它还能从四足到双足的站立和移动、后空翻、摔倒自恢复等高难度动作,拥有较好的平衡能力,兼顾了移动速度和稳定性,达到了行业领先水平。
6月,轮腿式机器人 Ollie 发布。它具有轮式机器人优势,在平地移动快、效率高;它也有很强的腿部能力,能在不平、的地面前进、跳跃通过台阶,越障能力强。其相关论文被机器人行业顶会 ICRA 收录。
11月,实验室借助在机器人敏捷移动与灵巧操作等技术方向的不断积累,与腾讯数据中心联合研发了 IDC 运维机器人,创新性地实现了服务器的全自动搬运、上下架、资产扫描盘点等工作任务, 提升了 IDC 运维的效率。
二、行业应用向善
医疗、医药、游戏到内容
作为 AI 科技的前沿探索者,腾讯 AI Lab 深知 AI 变革世界的潜力。因此,腾讯 AI Lab 在积极探索最前沿的 AI 技术的同时,也致力于将这样的潜力转化为切实可行的应用,以更好地为世界带来正向的改变。
AI+医疗:初步落地临床,提升病理阅片效率
「AI+医疗」是腾讯 AI Lab 核心研究方向之一。作为与全人类息息相关的研究课题,它值得长期和耐心的投入。
目前我国病理诊断面临着医疗资源分布不均、医生数量严重缺乏、水平参差不齐等难题。近年业内的多项尝试证明,AI 可以有效节省人力、时间成本,提高病理诊断的质量与效率,打破病理科面临的困境。
腾讯 AI Lab 医疗中心不断发展病理 AI 相关能力,专注打造研究与应用双平台,助力病理行业向数字化、智能化加速转型。
在研究侧,病理 AI 科研平台专注自主研发 AI 算法,布局多病种的整合诊断,多次获得国际级权威测试平台冠军,已获得 2 项软件著作权,授权国家专利 20 项,发表论文 30 篇;免疫组化-组织病理AI模型已覆盖 8 大癌症高发病种。
AI Lab 参与开发了迈瑞血细胞形态分析系统算法,细胞分析的多中心临床研究试验已在全国多家顶级三甲医院开展,算法性能比传统设备显著优越。宫颈癌 AI 也在与国内试剂厂商合作,搭载其技术的宫颈细胞 AI 辅助帮教系统已在全国 800 多家各级医院参与线上教学,累计分析超过 120 万次,算法准确度远超同类竞品。
应用侧,由腾讯 AI Lab 医疗中心提供底层技术的觅影病理云平台(病理影像存储与传输系统软件)也于今年获得国家二类医疗器械许可证,落地应用于临床诊疗场景,为医院病理科室提供图像管理、浏览、分析等数字病理服务,并具备病患数据上云、远程精准诊疗和多专家云上会诊等功能,为将推动AI医疗普惠至偏远地区打下坚实基础。

AI+医药:深入前沿研究,增强平台能力
在诊疗之后,如何快速研发出治疗疾病的药物,也是 AI 可发力的方向。2020 年 7 月,腾讯 AI Lab 发布了首个 AI 驱动的药物发现平台「云深」,整合了腾讯 AI Lab 和腾讯云在前沿算法、优化数据库以及计算资源上的优势,提供覆盖临床前新药发现流程的五大模块,包括蛋白质结构预测、虚拟筛选、分子设计/优化、 ADMET 属性预测及合成路线规划。

云深平台:https://drug.ai.tencent.com/
今年平台取得 2 项新进展:
在分子生成方面,8月平台与成都先导合作设计了业内首个经实验验证的骨架跃迁分子生成算法(GraphGMVAE),为药物化学专家设计分子提供更多启发。该算法以 JAK1 抑制剂 Upadacitinib 为例(通常用于治疗中重度类风湿关节炎的药物),证明在保持分子侧链不变的情况下,能有效生成具有相似生物活性但骨架不同的分子。同时,研究还提出了一套对分子优先级排序流程,可以缩小验证范围,提高效率。研究结果被美国化学学会杂志 ACS Omega 收录。
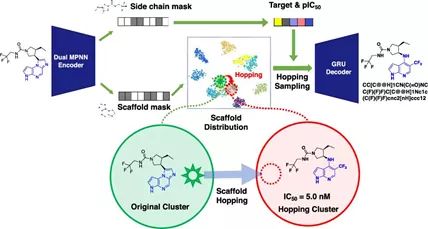
利用 GraphGMVAE 进行骨架跃迁,该项成果发表于行业知名期刊ACS Omega上
在蛋白质结构预测方面,平台去年推出的 tFold 算法精度和速度持续提升。与DeepMind所提出的 AlphaFold2 方法类似,tFold 采用了端到端的结构预测方案,并从模型设计和训练策略等多方面提升了训练阶段的优化效率和稳定性,仅需使用 8 卡 A100 训练 4-5 天。对于中等长度的蛋白质序列,平均运行时间约为 2-3 小时,提速明显。在 CASP14 基准测试集上,该模型在平均 TM-Score 指标上可达到 86.7,优于 RoseTTAFold (TM-Score=79.2),但与 AlphaFold2(TM-Score=90.0) 仍有一定差距。该模型已经在上线「云深」平台,供用户免费使用。
AI+游戏:拓展能力边界,距现实更近一步
计算机科学家们一直对「AI+游戏」保持热情,希望运用可自由定制、监测的游戏环境,解决 AI 算法测试困难、场景稀缺的问题,提升 AI 算法处理复杂问题的能力。
「AI+游戏」正是腾讯 AI Lab 长期深耕的领域。在过往围棋、MOBA 等游戏环境中取得的成果之上,今年团队继续深耕,让AI的足迹走向了麻将、足球、3D开放世界(Minecraft)、即时战略(RTS)等多类游戏环境,不断积累国际一流的学术成果,还在行业全链条应用和生态建设上迈出了坚实步伐。
棋牌拥有简单清晰的规则,清晰的胜负判定条件和行动准则,并在公众认知中被认为代表了人类的智力水平。在今年,实验室棋牌类 AI 「绝艺」的能力,从传统强项围棋(完全信息博弈)到麻将(非完全信息博弈)都不断提升。
在围棋 AI 研究上,「绝艺」持续提升让子棋能力,对普通职业棋手让两子取得 200 连胜,对顶尖职业棋手胜率超过 95%;
在应用上,新增对日韩规则、让先规则等功能。
这些能力将帮助「绝艺」更好地服务中国围棋国家队队员,以及腾讯野狐围棋平台的围棋爱好者们。
在麻将 AI 方面,「绝艺」继去年达到两人麻将职业水平、四人国标获 IJCAI 麻将 AI 比赛冠军后,今年与多位职业选手完成了 2000 多场四人国标对局,平均赢番第一,成为业界首个达到四人国标麻将职业水平的 AI 。
为训练 AI 的决策智能水平,腾讯 AI Lab 自 2018 年起在「王者荣耀」MOBA(多人在线战术竞技)环境中训练「绝悟」AI。今年它的能力迎来了进一步提升。
3 月,「绝悟」在「王者荣耀」MOBA 环境中的策略多样性再度升级,学会在不同阵容和对局中执行多样的策略(如养猪流、反野流、大乔流等)。针对复杂环境中策略难以探索的问题,「绝悟」提出基于宏观目标的分层强化学习框架(MGG, Macro-Goals Guided RL),并验证了该方法在策略探索上的高效性。该项技术于 4 月的「挑战绝悟」游戏活动中初次实践,有效提供玩家挑战趣味性,研究成果已经被 NeurIPS 2021 主会议接受。
9 月,继去年赢得 Google 足球竞赛冠军后,「绝悟」今年基于层次化强化学习实现了业界首个纯强化控制所有球员的 Full Game 11v11 足球 AI , 并且能力远超去年的行为树+强化的冠军版本。
12 月,「绝悟」在 NeurIPS 2021 举办的 MineRL (Sample Efficient RL Competition) 赛事中,以 76.970 的历史最高分完成主赛道(research track)挑战,夺得决赛冠军,并将研究成果共享在 Arxiv 平台,让算法框架可复用于其他复杂决策环境。
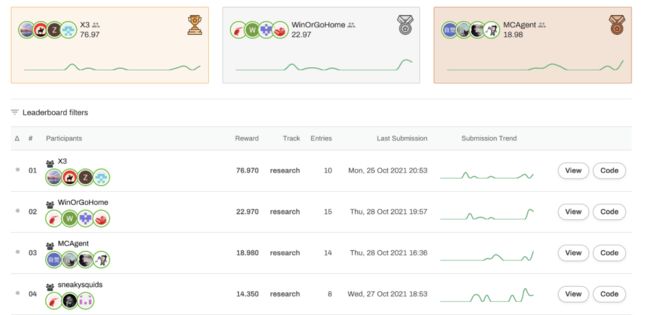
「绝悟」团队(X3)获得历史最高分。完整榜单详见:
https://www.aicrowd.com/challenges/neurips-2021-minerl-diamond-competition/leaderboards
即时战略(RTS)游戏一直被认为是竞技性和策略性方面最具有挑战的一类游戏,其更为巨大的观测、动作以及策略空间,对训练高水准的AI智能体带来了非常大的困难。
腾讯 AI Lab 和 Robotics X 实验室自 2018 年起,以「星际争霸2」这一风靡全球的即时战略游戏为研究对象,深入探索强化学习在处理此类复杂游戏上的可拓展性。同年,团队发布初代 AI 智能体 TStarBot,分别以层次化的动作/策略空间建模和基于中高层动作空间的强化学习训练,在业界首次实现击败游戏中所有等级(包括最高等级的作弊)的内置 Bot。该工作论文(https://arxiv.org/abs/1809.07193)被 2019 年底 DeepMind 公布的 AlphaStar Nature 论文引用。
在今年 4 月,通过之前积累的经验以及吸收 AlphaStar 中的优势技术,实验室提出了 TStarBot-X:在使用比 AlphaStar 算力资源少1-2个数量级(数据消耗速度为AlphaStar的1/30,数据生成速度是AlphaStar的1/73),且和人类操作可比拟的情况下,TStarBot-X 在虫族对虫族对战测试中击败国服和韩服宗师级别人类选手。
其背后的强化学习技术进一步提升,包括高效的联盟训练方式(Efficient League Training),简洁规则引导的策略搜索方式(Rule-guided Policy Search)、以及差异增大的策略优化算法(Divergence- Argumented Policy Optimization)。
完整代码及技术细节可见论文:https://arxiv.org/abs/2011.13729
其所有技术细节以及背后的通用多智能体强化学习联盟训练架构 TLeague 均已开源:https://github.com/tencent-ailab/tleague_projpage
除了攻克更多游戏环境,「绝悟」团队还初步尝试将 AI 能力应用于游戏开发和运营流程中。7月,腾讯 AI Lab 在全球游戏行业顶级会议「2021游戏开发者大会」(GDC)亮相,全面展示了以「绝悟」为代表的 AI 技术在游戏产业全链路中的研究应用能力。
具体而言,AI 在游戏全链路的研究和应用包括两部分:横向上,覆盖游戏制作、运营及周边生态全生命周期,提升游戏品质,丰富玩家体验;在纵向上,AI正拓展更多元的游戏品类,如围棋、麻将等棋牌类,足球等体育类,以及 MOBA 、FPS(第一人称射击游戏)等复杂策略类游戏。
希望了解「绝悟」提高游戏开发效率、打造新玩法、辅助游戏平衡性测试等具体案例,请见文章:「绝悟」参展游戏开发者大会,AI深入游戏产业全链路。
多智能体强化学习主要研究在同一个环境中的多个智能体,如何进行合作或者竞争完成指定的目标。因为具有较高的研究难度,也有广泛的应用前景,这一议题近年广受AI企业及科研院校关注。
为帮助AI学界克服算法、数据、算力、场景等四大要素的挑战,腾讯 AI Lab 与王者荣耀于2019年宣布共建「开悟」AI 开放研究平台,依托于腾讯太极机器学习平台,基于双方在算法、脱敏数据、算力方面的核心优势,为学术研究人员和算法开发者开放的国内领先、国际一流研究与应用探索平台。
这是「开悟」举办高校大赛的第二年,作为业内首个基于 MOBA 游戏场景的 AI 开放平台,它为学生提供的多智能体复杂策略研究环境,其科研及教育价值已获得社会各界的全面认可:
4月,首届腾讯STAC科创联合大会在成都召开,发布首届「开悟」大赛成果,并为政、企、学界专家提供共议「AI+游戏」行业未来发展的交流平台,同时现场成立校企联合的「人工智能科教联盟」。
工信部原部长李毅中、成都市副市长等嘉宾出席并发表讲话,「开悟」作为行业生态基础设施,对 AI 研究与教育的推动作用受到广泛关注。
8月,第二届「开悟」高校AI大赛启动并扩大规模,邀请了20余所海内外知名高校参赛。
「开悟」也逐步发展为为竞赛-课程-科教联盟-科创联合体的生态聚集地,推进 AI 与教育融合。
同月,「开悟」宣布与 4 所国内一流高校共建教学内容和课程体系改革项目,进一步探索平台在高校AI教育方向的可能性。北京大学李文新、电子科技大学谢宁、清华大学李秀、中国科学技术大学周文罡等四位教授将基于腾讯开悟平台,分别构建一门至少 20 学时的多智能体及强化学习平台的专业课程,理论授课知识点包括但不限于机器学习、强化学习、多智能体决策等相关的知识点。

作为AI游戏研究先行者,腾讯 AI Lab 的相关研究成果正不断走近现实。这些研究的经验、方法与结论,都将在真实世界创造更大的实用价值。
AI+内容:技术融合场景,提供更好的内容服务
◆ 翻译
腾讯交互翻译 TranSmart 是目前业界领先的「以人机交互为核心」的机器翻译产品,覆盖按键到句子、术语到存量语料的人工翻译全流程支持,并在复杂文件格式解析与带标记文档翻译等方面表现突出。

体验地址:https://transmart.qq.com/
经过四年技术积累与一年商业化探索,TranSmart 已支持 Memsource、腾讯自选股、腾讯音乐娱乐集团(TME)、华泰证券、阅文集团、腾讯云官网等垂直领域头部客户,提供的服务包括交互翻译、文件翻译、自动翻译、定制引擎等,并可支持计算机辅助翻译(CAT)软件对接,辅助全球众多译员完成严肃翻译工作。
今年 TranSmart 继承和发展了交互翻译的技术概念,提升复杂场景的译文干预能力,相较于通用自动翻译产品而言,量身定制的人机交互特性全方位赋能人工翻译过程:
个性化增强:在目标场景中,通过复用客户已积累的相关语料,免训练即时生效,自动译文质量显著超出增量式训练的机器翻译;
带标记翻译:在 xml、markdown、html 等场景中,通过标记抽取和还原,确保语义和格式不受损失,实现出色的文件翻译能力;
实时译文建议:译文片段智能推荐和整句补全,相较于译文编辑而言,在自动译文不甚理想时,显著减少修改量,大幅改善人工翻译体验;
翻译记忆融合:动态结合用户已完成的最相似双语句对,生成更符合期望的自动译文,在个性化增强的基础上,取得进一步的性能提升;
术语规则融合:通过引入可编辑的术语翻译规则,应对一词多义等复杂场景下的术语翻译难题,实现更精细的译文质量干预;
翻译输入法:参照原文上下文和机器翻译知识,实现更精准组词,显著加快人工翻译过程中的输入效率。
◆ 搜索与推荐
从个性化内容推荐到内容的自动生成,AI 与数字化内容有着天然的亲和性。依托于其庞大的内容相关业务,腾讯公司一直以来都致力于推进智能技术在搜索和推荐等方面的应用。
在2021年,实验室持续探索相关技术技术,推出异构向量检索系统 VeNN 及异构计算框架 HCF ,并于微信搜一搜等大规模业务中落地。
向量检索方面,VeNN 面向百万至百亿规模的向量相似召回场景,能高效给出针对性方案,并兼顾召回效果和性能。它同时支持 ANN 和暴力计算向量相似召回。针对大规模场景,VeNN融合了 HNSW 和 PQ 索引,在百亿规模场景下做到 R@10 >95% 的同时控制检索耗时<5ms。针对百万级别小规模场景,VeNN 研发了 GPU 下的暴力计算,通过底层 kernel 的深度优化,检索性能在业界处于领先水平。在 VeNN 引擎的基础上, 对文本向量表征、多模态向量表征方面进行 co-design 优化,最终落地于微信搜一搜召回场景,显著改善了长尾 query 的召回情况。
异构计算框架方面,HCF 针对英伟达、英特尔等硬件平台建设跨平台服务端模型推理加速解决方案,其中 BERT 等模型推理性能处于业界领先。HCF 在推理加速方面涵盖了业界通用的层融合,图优化,模型压缩量化等手段,并进行深耕,其中 INT8+QAT 方案在微信搜一搜场景广泛落地,同时能力在英伟达 2021 GTC 会议上分享。除此之外,HCF 也在进一步深入 TVM 编译优化技术,以获取更高的模型推理加速效果和跨平台能力。
三、前沿学术研究与合作
作为国内领先、世界一流的企业级人工智能实验室,腾讯 AI Lab 持续探索机器学习、自然语言处理、视觉计算、语音技术等四大方向前沿技术,并做出业界领先的学术成果。截至今年,实验室已于 AAAI、CVPR、ICLR、IJCAI、ACL、ICML、EMNLP、NeurIPS 等国际人工智能顶会发表超 600 篇文章,包括今年发布的一篇 NAACL 最佳长文,及一篇 ACL 杰出论文。
同时,我们一直秉承开放合作的理念,与全球高校和研究机构共同前进。2021年,「腾讯AI Lab犀牛鸟专项研究计划」完成第 4 年度闭环,共发表高水平论文近50篇,多项成果已应用于 AI 药物发现平台「云深」、自然语言理解系统「TexSmart」、智能辅助翻译「TranSmart」和腾讯会议等产品。
下面将分主题简单梳理腾讯 AI Lab 在 2021 年发布的一些重要研究成果,并分享我们对相关领域的发展趋势观察。
机器学习
机器学习是 AI 的核心过程和标志性能力,近些年的 AI 发展热潮正是源自深度学习这种机器学习技术的突破。2021 年,腾讯 AI Lab 在多个机器学习方向上都得到了重要的研究成果。
◆ 深度图学习
近几年,图像、视频、游戏博弈、自然语言处理、金融等大数据分析领域都实现了跨越式的进步并催生了很多改变了我们日常生活的应用。近段时间,图神经网络是 AI 领域的一大研究热点,尤其在社交网络、知识图谱、化学研究、文本分析、组合优化等领域,图神经网络在发掘数据中隐含关系方面的强大能力能获得更好的数据表达,进而做出更好的决策。
实验室该领域的研究应用上取得了丰硕的成果。针对图神经网络的鲁棒性问题,所研发的 GCN-LFR 框架[1],显著提升了不同图神经网络模型的稳定性和鲁棒性。在图神经网络的可解释性方面,基于信息瓶颈论的子图识别网络算法[2,3],为图的可解释性提供有效的方法。腾讯 AI Lab 还创新地提出了分层图胶囊网络,来联合学习节点嵌入并自动提取图层次结构[4]。针对图神经网络的自蒸馏,研发的基于邻居差异率(NDR)的方法,显著提升了图神经网络的训练效率和泛化能力[5]。在图神经网络的应用方面,还探索了图神经网络在组合优化,图论领域,以及图的节点匹配上的应用[6,7,8,9]。
此外,在 2021年的 The WebCof 会议上,腾讯 AI Lab 、清华大学、香港中文大学等机构联合组织一场图神经网络 Tutorial[10]。详见:
https://ai.tencent.com/ailab/ml/WWW-Deep-Graph-Learning.html
◆ 自动化机器学习
在自动化机器学习中的元学习和网络结构搜索等研究领域,腾讯AI Lab也取得了诸多成果。
在研究方面,针对元学习中的过拟合问题,AI Lab 所提出的 MetaMix 算法[11],从样本输入特征/标签和网络隐含层特征两个层面进行任务增广,从而提高元学习算法的泛化能力。在提升自动超参数优化的搜索效率方面,TNP 算法[12] 基于神经过程方法,将过往在其他数据集上进行的超参数搜索过程,迁移到当前任务上,以降低超参数搜索过程中试错次数,提升优化效率。
在实际应用方面,针对药物活性预测中不同靶点数据差异性的问题,AI Lab 提出了一个基于相似性的功能区块化的元学习模型 [13],根据靶点活性预测模型的相似度建模预测模型,提高了不同靶点预测任务在元学习算法中的利用程度。此外,针对在线增量数据的应用场景,AI Lab 提出了 AdaXpert 网络结构搜索算法 [14],可以根据数据分布差异情况自行确定是否对网络结构进行调整,从而平衡模型的预测性能和效率。
自然语言处理
在自然语言处理(NLP)领域,一方面 BERT 、GPT 等基于 Transformer 的大规模神经网络语言模型的出现带来了深刻影响;另一方面,大规模语言模型并没有从根本上解决 AI 在语言理解上能力低下的问题,NLP 领域仍需持续研究投入和更多技术突破。腾讯 AI Lab 在自然语言处理方向的目标是开展 NLP 基础研发工作,促进 NLP 技术的发展,提升人类的生活便捷性和工作效率。
2021 年,腾讯AI Lab在一流的国际会议和期刊上发表了50多篇 NLP 方向的学术论文。在NAACL 2021,腾讯 AI Lab 与罗切斯特大学合作的论文《视频辅助无监督语法归纳(Video-aided Unsupervised Grammar Induction)》被 NAACL 评为最佳长文。在ACL 2021,腾讯 AI Lab 贡献 27 篇论文(含九篇 Findings),包括 6 篇杰出论文之一,与香港中文大学合作的《基于单语翻译记忆的神经网络机器翻译技术(Neural Machine Translation with Monolingual Translation Memory)》。论文全文及解读:ACL 杰出论文 + NAACL 最佳论文,腾讯 AI Lab 解读两项 NLP 成果。
在文本理解方面,实验室持续更新文本理解系统 TexSmart ,保持对新出现实体和概念(比如“新冠”)的理解能力。今年 6 月发布的 0.3.0 版本中增加了文本图谱(Text Graph)功能,让用户通过文本图谱获取词语间的多种语义关系。目前其在线 API 和离线 SDK 的合计调用量比年初增加了十亿次/天。实验室还推出了新版本中文词向量数据[15],覆盖更多新词,且向量表示的质量有一定的提升。实验室与腾讯云小微团队联合提出了注入通用型推理知识和任务型知识的中文预训练模型“神农”(该模型仅包含十亿级参数量),并一举登顶 CLUE 总排行榜、1.1 分类任务、阅读理解任务和命名实体任务 4 个榜单,刷新业界记录。
在前沿研究上,NLP 团队提出基于二分图匹配的词典语义对齐算法,将分散在不同词典中语义知识融合成为一个整体,并利用迁移学习框架,训练通用精确语义模型,使其根据上下文语境自动化确定一个多义词在句中的精确含义,提升机器理解力[16]。团队还提出了一种新型的句子切分模型[17],及一种简单有效的方法来解决命名实体标注遗漏问题[18]。在细粒度实体分类任务上,团队提出了一种利用多信息源的融合模型[19],及一种不依赖知识图谱产生训练数据而又具有优异性能的实体分类方法[20]。
在文本生成和对话方面,我们持续探索多轮对话、对话知识理解、可控文本生成等核心问题,提出基于新闻知识的自然对话研究并发布 NaturalConv 数据集[21],提出过生成和打分算法显著提升抽取型摘要模型效果[22],并利用 Unlikelihood Training 在低资源场景下训练人设一致的对话系统[23], 基于层级式课程学习和稠密向量检索的多轮对话系统[24],提出多种基于检索结果引导的可控文本生成方法[25],以及一种基于预训练的非自回归文本生成模型[26]。同时,我们研究如何有效公平地评价度量各种生成任务中生成文本的质量[27],如何普适性地理解数据增强在文本生成任务中的作用[28]等重要问题。
在自动机器翻译方面,我们专注于核心翻译问题,致力于改善翻译系统的效果和易用性。我们继续深耕如何更高效利用翻译数据[29],并探索预训练[30]、非自回归模型[31]等机器翻译领域的前沿方向。受益于此,我们的自动翻译(中英和英中)系统准确度继续保持国内前列,在国际翻译比赛 WMT 2021 中也取得了 5 项第一的成绩。
在交互翻译方面,我们聚焦于翻译记忆[32]和翻译输入法[33]。我们提出了一种快速且准确的融合翻译记忆方法;特别地,我们提出的基于单语的翻译记忆模型获得了 ACL 2021 杰出论文奖。另外,我们从实际应用中抽象出了一种词级别翻译提示任务[33];基于该任务,我们发起了第一个面向交互翻译的 Shared Task,它将作为一个新赛道在明年的 WMT 2022 上亮相。
视觉计算
数字经济的高速发展和虚实结合的业界应用对于视觉计算技术提出了新的挑战。首先,视觉理解面临着海量无标注数据,如何有效利用这些数据来优化视觉理解模型成为一个研究热点。其次,作为人机交互的新模式,如何快速生成高清、超写实、可编辑、易控的虚拟人形象成为工业应用的瓶颈。最后,大规模 3D 场景重建和动态场景的 4D 捕捉和建模成为了构建虚拟世界的支撑技术。
2021年,视觉顶级期刊和会议,包括 T-PAMI、TIP、ICCV、CVPR 和 NeurIPS 等共接收了 35 篇腾讯 AI Lab 论文,其中既有视觉理解的底层网络结构探索,也有图像和视频编辑的新方法,还有跨模态的从文字生成图像的新尝试,以及涉及 AI 安全的对抗攻击新成果。
视频理解是计算机视觉中具有长期挑战性的研究课题,如何从数据的不同层面设计理解算法也是学术界广泛研究的热点。2021 年,腾讯 AI Lab 关注新兴自监督表征学习框架,从物体、图像以及视频等三个维度全方面理解视频数据。基于算法创新,腾讯 AI Lab 相关国际竞赛 ActivityNet Challenge 并获得冠军。此外,该技术还应用在微信搜一搜,做游戏、影视综漫等视频的打标签实践,提高了视频搜索准确率。
图像和视频编辑在流媒体内容创作中被广泛应用,比如人像编辑、视频滤镜、图像裁剪等。在基于美学的图像裁剪,实验室首次提出外插式智能图像裁剪算法[34],突破传统算法适用给定有限图像内容的局限。在跨模态图像可控生成上,受画家绘画过程的启发,提出了基于文本的可控图像生成算法[35],会在过程中轮替关注全局结构与局部细节。

基于美学的外插图像智能裁剪 [34]

跨模态可控图像生成 [35]
在视觉系统鲁棒性上,实验室在对抗样本攻防、DeepFake 检测等方向持续发力,提出多个原创性算法[36-38]。黑盒查询式攻击对许多 AI 模型造成严重威胁,实验室提出了轻量级防御方法 [36],为每个查询添加适当随机扰动,在保持正常样本效果时显著提升了模型鲁棒性,并不引入额外部署开销。实验室还研究了物体检测黑盒攻击方法[37],显著算法效率,有助于设计出更鲁棒的模型。在 2021 世界人工智能大会上,实验室还发布了 AI 安全风险矩阵 2.0 版本和 AI 安全网站,受到业界广泛关注。
在今年,我们也尝试将视觉技术应用于野生动物保护。10 月,首个雪豹智能识别及监测数据管理云平台上线,采用了实验室视频理解技术,用 AI 自动检测图像/视频中是否出现雪豹及预测其位置,将巡护员从繁琐的记录、标注、识别工作中解放出来,更高效地找寻雪豹。该技术面临诸多挑战,包括动物尺度差距大,纹理背景接近,难于识别;濒危动物很少出现,难采集到有效视频;不同物种间分布不均,模型泛化难等。实验室借助迁移学习、自动数据增强、难例样本挖掘、多阶段检测等技术手段,有效的提高了物种识别、空境过滤、位置预测等效果。
语音
语音识别上,相对安静环境和高质量识别基本解决,但实际应用中,复杂场景中噪声和多个干扰人声同时存在(鸡尾酒会问题),及人们自由聊天口语化表达风格多样复杂问题依然存在。语音合成上,高度的自然度、表现力、定制化、可控制等能力仍需努力。
在 2021年,信号处理顶级会议 ICASSP 接收了实验室的 12 篇论文,ASRU 接收 4 篇,而语音领域顶级会议 Interspeech 则接收了 9 篇论文,其中既有在语音前沿技术方向的进一步探索,也包含一些理论研究和分析,同时还有在科技向善与文化遗产保护等方面的应用成果。
在研究中,实验室为解决鸡尾酒会问题提出了多项开拓性的解决策略。
一是围绕多通道语音前处理系统,在基础算法方面提出全新时域 Generalized Wiener Filter 波束形成方法[39],在分离/增强任务中较频域波束成形方法在相同 window size、同等模型复杂度下 SI-SDR 绝对性能提升 3.0 dB,相对性能提升 29.7%;在去年提出的全新基于递归神经网络的波束形成方法[40],突破传统波束形成技术效果的基础上,今年进一步优化了模型结构[41],并且围绕多人同时讲话这样一个最具挑战的任务上,为了提高应用效率实现了具有多说话人方向特征的多通道输入和多说话人语音分离输出(MIMO)模型[42],把原本分别进行多路目标语音的处理的操作合并在一个模型之中,大幅降低计算复杂度,达到流式,实时,可部署。
传统前端系统从整个系统层面来看,存在着模块相对独立、难以联合调优、误差级联影响大的问题,今年实验室提出构建一套集合全链路,包括回声消除、声源定位、语音分离、去混响及波束增强等多个功能的神经网络模型方案,能克服模块相对独立的缺陷,实现场景深度定制,多模块自动联合优化。
二是在多模态系统方面,在过去从视觉模态中提取人脸,方位,唇动,声纹等信息,将不同模态信息流通过神经网络模型自动整合,构建多模态语音分离增强与识别系统的基础上,今年提出将空间定位从 2D 扩展到 3D,引入了俯仰角高度信息,3D 特征利用更精确的球面波传播模型,同时还引入与麦克风的深度距离信息,大大突破原有空间分辨精度,实现同一方向的两个说话人,距离不同时也可区分,在高强度噪声、更多说话人的复杂场景下的稳定优越性能。
在语音识别方向,腾讯 AI Lab 首次提出将动态神经网络思想引入语音识别模型中,提出基于 Mixture-of-Expert 结构的语音识别模型 SpeechMoE[43]和 SpeechMoE2[44],针对语音识别任务设计优化了模型多个细节,包括稀疏化,路由损失,训练策略。在模型训练和应用过程中,模型可通过局部及全局信息自动选取网络中的部分路径进行计算,模型容量相对传统模型可以扩大一个数量级,同时又保证在应用时计算复杂度不增加。能够更好的处理语音中存在的各种维度的包括噪声,口音,远近场等复杂变化,最新实验的 conformer-moe 模型相比业界最多应用的 conformer 这类网络结构基础上可进一步获得相对 10% 的提升。另外,AI Lab也提出了利用 Lattce Free MMI loss 从训练到解码改进了基于RNN-T端到端识别系统[45], 在中文标准 Benchmark AIshell1 和 AIshell2 上均取得超越SOTA的性能。
在语音合成方向,在原有 DurIAN 合成系统基础上,探索新的生成模型方案[46],提高语音合成的表现力和可控性。增加对语音音韵、拖音及重音等特征的引入建模,进一步显著提升语音合成系统可控性及表现力,实验室配合王者电竞语音合成应用与游戏解说任务。今年还首次实现语音合成在游戏内素材生成场景上应用突破。通过进一步对语音转换中基于 GAN 的声码器进行改进,效果达到游戏内素材水平,转换后语音 MOS 分数逼近配音录制语音(4.62 vs 4.70)。在生成模型理论研究方面,提出全新基于 Diffusion 的生成模型 Bilateral Denoising Diffusion[47],与基线系统 DiffWave 相比在生成语音 MOS 相当情况下 Denoise 过程步数大大缩减。在个性化定制任务方面,在业内较早提出将 meta-learning 思想引入小数据量定制任务中[48],通过在训练过程中将向训练单位由一条条音频扩展为一项项定制任务,模型可更快达到定制效果,定制周期显著缩短。
四、总结与展望
在即将过去的 2021 年,人类的生活方式持续改变,对虚拟的世界多一份期待,对现实的美好多一份珍惜。唯一不变的是,前沿科学依然是驱动人类前行的主要动力。
在这一年中,腾讯 AI Lab 以虚实集成世界为目标,持续投入虚拟人、医疗、医药、游戏、内容、机器人等多个领域的研究与应用实践,并取得了不少令人鼓舞的成果,为「Make AI Everywhere」,用科技创造美好世界而做出切实的努力。
相比起我们所追寻的目标,5 年只是一个小小的起点。在未来的1年,乃至5年、10年,我们将持续攀登学术的高峰,同时积极拓展 AI 技术的更多行业应用,面对未来更多的未知挑战,以开放的心态与各界伙伴共同成长。
2022,新年快乐!
附录1:开放平台
云深平台:https://drug.ai.tencent.com/
开悟平台:https://aiarena.tencent.com/aiarena/
TexSmart 文本理解系统: https://texsmart.qq.com/
TranSmart 交互翻译系统:https://transmart.qq.com/
附录2:论文链接
● 机器学习
[1] 基于低频滤波分析的鲁棒图神经网络训练框架
https://papers.nips.cc/paper/2021/file/d30960ce77e83d896503d43ba249caf7-Paper.pdf
[2] 基于图信息瓶颈的子图识别
https://openreview.net/pdf?id=bM4Iqfg8M2k
[3] 利用子图信息瓶颈识别预测子结构
https://www.computer.org/csdl/journal/tp/5555/01/09537601/1wTimW3yyNW
[4] 分层图胶囊网络
https://ojs.aaai.org/index.php/AAAI/article/view/17268
[5] 针对图神经网络的自蒸馏方法
https://www.ijcai.org/proceedings/2021/314
[6] 基于跨网络嵌入的无监督大规模社交网络对齐
https://dl.acm.org/doi/pdf/10.1145/3459637.3482310
[7] 基于图卷积方法预测社交团体中的关键用户
https://ieeexplore.ieee.org/abstract/document/9457127
[8] 基于深度学习的无特征旅行商问题求解器选择
https://arxiv.org/pdf/2006.00715
[9] 一个基于图神经网络的大规模子图计数框架
https://dl.acm.org/doi/pdf/10.1145/3448016.3457289
[10] TheWebConf 21图神经网络Tutorial:高级深度图学习:更深、更快、更鲁棒和无监督
https://ai.tencent.com/ailab/ml/WWW-Deep-Graph-Learning.html
[11] 利用任务增强提升元学习的泛化能力
http://proceedings.mlr.press/v139/yao21b.html
[12] 基于神经过程的元学习超参数性能预测
https://proceedings.mlr.press/v139/wei21c.html
[13] 基于功能区块化知识迁移的少样本药物发现算法
https://openreview.net/forum?id=Dti5bw14YZF¬eId=BWhMUFFt_S
[14] AdaXpert: 针对在线增量数据的网络结构自适应方法
https://proceedings.mlr.press/v139/niu21a.html
● 自然语言处理
[15] 腾讯AI Lab的中文词向量数据
https://ai.tencent.com/ailab/nlp/en/embedding.html
[16] 通过对齐词典释义桥接词和释义之间的语义
https://aclanthology.org/2021.emnlp-main.610/
[17] 句子切分模型
https://aclanthology.org/2021.findings-emnlp.18.pdf
[18] 实体漏标的一种解决方法
https://openreview.net/pdf?id=5jRVa89sZk
[19] 多信息源融合的细粒度实体分类
https://aclanthology.org/2021.emnlp-main.210.pdf
[20] 无知识图谱的细粒度实体分类
https://aclanthology.org/2021.emnlp-main.431.pdf
[21] NaturalConv
https://arxiv.org/abs/2103.02548
[22] 基于过生成和打分的抽象摘要模型
https://aclanthology.org/2021.naacl-main.110/
[23] 利用Unlikelihood Training在低资源场景下训练人设一致的对话系统
https://arxiv.org/pdf/2106.06169.pdf
[24] 基于层级式课程学习和稠密向量检索的多轮对话系统
https://arxiv.org/pdf/2012.14756.pdf
https://arxiv.org/pdf/2110.06612.pdf
[25] 基于检索结果引导的可控文本生成
https://arxiv.org/pdf/2004.02214.pdf
https://aclanthology.org/2021.findings-acl.50.pdf
https://arxiv.org/pdf/2104.00929.pdf
https://arxiv.org/pdf/2109.07812.pdf
https://arxiv.org/pdf/2105.11269.pdf
[26] 基于预训练的非自回归文本生成模型
https://arxiv.org/pdf/2102.08220.pdf
[27] 文本生成任务的评价度量
https://aclanthology.org/2021.acl-long.34.pdf
https://aclanthology.org/2021.findings-acl.220.pdf
https://aclanthology.org/2021.findings-acl.432.pdf
https://aclanthology.org/2021.findings-acl.193.pdf
[28] 数据增强在文本生成任务中的作用
https://aclanthology.org/2021.acl-long.173.pdf
[29] 对翻译数据的更有效利用
https://aclanthology.org/2021.acl-long.221/
https://aclanthology.org/2021.acl-long.266/
[30] 针对机器翻译的预训练
https://aclanthology.org/2021.findings-acl.373/
[31] 非自回归神经机器翻译
https://openreview.net/forum?id=ZTFeSBIX9C
https://icml.cc/virtual/2021/poster/8931
[32] 翻译记忆
https://aclanthology.org/2021.acl-long.246/
https://aclanthology.org/2021.acl-long.567.pdf
[33] 翻译输入法
https://aclanthology.org/2021.acl-long.370/
● 计算机视觉
[34] 美学引导的外向图像裁剪 (Siggraph Asia)
https://www.shaopinglu.net/publications_files/tog21.pdf
[35] 基于动态属性敏感生成式网络的文本到图像生成方法 (ICCV)
https://openaccess.thecvf.com/content/ICCV2021/papers/Ruan_DAE-GAN_Dynamic_Aspect-Aware_GAN_for_Text-to-Image_Synthesis_ICCV_2021_paper.pdf
[36] 针对基于查询的黑盒攻击的随机噪声防御方法 (NeurIPS)
https://papers.nips.cc/paper/2021/file/3eb414bf1c2a66a09c185d60553417b8-Paper.pdf
[37] 矩形翻转攻击:一种针对目标检测系统的基于查询的黑盒攻击方法 (ICCV)
https://openaccess.thecvf.com/content/ICCV2021/papers/Liang_Parallel_Rectangle_Flip_Attack_A_Query-Based_Black-Box_Attack_Against_Object_ICCV_2021_paper.pdf
[38] 一种基于泛化扰动邻域的半监督鲁棒对抗训练方法 (Pattern Recognition)
https://www.sciencedirect.com/science/article/abs/pii/S0031320321006488
● 语音
[39]一种时域广义维纳滤波方法进行多通道语音分离
https://arxiv.org/pdf/2112.03533.pdf
[40]全新的基于递归神经网络的波束形成方法
https://arxiv.org/abs/2008.06994
[41]一种广义的空-时递归网络波束成形方法
https://arxiv.org/pdf/2101.01280.pdf
[42] 多入多出自注意力递归神经网络多说话人语音分离
https://arxiv.org/pdf/2104.08450.pdf
[43]SpeechMoE: 采用动态路由专家网络的超大声学模型
https://arxiv.org/pdf/2105.03036.pdf
[44]SpeechMoE2: 改进路由方法的混合专家网络模型
https://arxiv.org/pdf/2111.11831.pdf
[45]应用LF-MMI的一致性训练和解码的端到端识别
https://arxiv.org/pdf/2112.02498.pdf
[46] Glow-WaveGAN: 应用GAN的VAE学习的表征特征实现高质量基于flow的语音合成
https://arxiv.org/pdf/2106.10831.pdf
[47]双向去噪扩散模型
https://arxiv.org/pdf/2108.11514.pdf
[48]META-VOICE: 采用元学习的快速少量语句风格迁移音色克隆
https://arxiv.org/pdf/2111.07218.pdf

* 欢迎转载,请注明来自腾讯AI Lab微信(tencent_ailab)