聊聊数据库吧
昨天有人跟我说我写的文章没有自己的想法,全都是死磕的知识点。我反思了一下,觉得好像有道理,所以我决定改变一下我写文章的风格。这两天在学数据库,数据库对我来说已经不算新的知识点了,算是作为巩固学习吧。所以抽时间跟大家聊聊数据库基础,多表连接以及事务部分的内容。因为对这个知识点比较熟,所以主要想讲一些常用的语句以及需要注意的点。
文章目录
- 数据库基础
-
- 1、DDL数据定义语言
-
- 操作数据库
- 操作表
- 2、DML数据操作语言
-
- 增(insert)
- 删(delete)
- 改(update)
- 3、DQL数据查询语言
-
- 简单查询
- 条件查询
- 模糊查询
- 字段控制查询
- 排序(order by)
- 聚合函数
- 分组查询(group by)
- LIMIT
- 4、DCL数据控制语言
-
- 创建用户
- 用户授权
- 用户权限查询
- 撤销用户权限
- 删除用户
- 未完待续
数据库基础
首先讲一些SQL语句吧,这一部分比较基础,主要是要记住一些关键字和语句的用法就没啥问题了。SQL语句分为以下四种:
- DDL(Data Definition Language):数据定义语言,用来定义数据库对象:库、表、列等。
- DML(Data Manipulation Language):数据操作语言,用来定义数据库记录(数据)增删改。
- DCL(Data Control Language):数据控制语言,用来定义访问权限和安全级别。
- DQL(Data Query Language):数据查询语言,用来查询记录(数据)查询。
1、DDL数据定义语言
在DDL数据定义语言这一块主要用到的是对一些数据库和表的操作,比如对数据库或表的创建,删除,查看以及修改。其主要的关键子分别是:create,drop,show,alter。这里需要注意的是数据库是不区分大小写的。为了让大家更好的理解与使用,我把各种操作格式给列举一下
操作数据库
- 创建数据库:create database 数据库名
- 查看某个数据库:show CREATE DATABASE 数据库名;
- 查看所有数据库:show databases;
- 修改数据库:alter database 数据库名 character set 编码方式
- 删除数据库:drop database 数据库名
- 查看当前使用的数据库:Select database();
- 切换数据库:use 数据库名
操作表
- 创建表:
create table 表名(
列名1 数据类型 [约束],
列名2 数据类型 [约束],
列名n 数据类型 [约束]
);- 删除表:drop table 表名;
- 当前数据库中的所有表: show tables;
- 查看表的字段信息:desc 表名;
- 在一个表中增加列:alter table 表名 add 新列名 新的数据类型
- 修改某个列:alter table 表名 change 旧列名 新列名 新的数据类型
- 删除某个列:alter table 表名 drop 列名
- 修改表名:alter table 旧表名 rename 新表名;
- 查看表表格的创建细节:show create table 表名;
- 修改表的字符集: alter table 表名 character set 编码方式
对数据库和表的DDL(数据定义语言)常用的就是以上列出来的了。那么对数据库和表的定义已经是完成了,接下来就是对数据的操作了。(主要的是对表的操作)
2、DML数据操作语言
从刚刚的DDL数据定义语言,我们只是创建了数据库和表,而表中是空的,没有任何一条数据,那么要往表中添加数据,就需要使用DDL(数据操作语言了)。DML是对表中的数据进行增(插入)、删、改的操作。其用到的关键字分别是:insert,delete,update。
注意:DDL也有增删改的关键字,要注意与DML进行区分。不要和DML数据操作语言的增删改混淆 。
下面来一波数据的增删改操作:
增(insert)
对表的插入操作可以有两种格式,一种是把需要增加的列名和列值对应的写出来(格式1),另一种是可以不把列名写出来,只需按列名的顺序给出相应的列值(格式2)。
插入单行
格式1:insert into 表名(列名) values(数据值);
例:
insert into student(stuname,stuage,stusex,birthday) values('张三1',18,'a','2000-
1-1');
这里需要注意的是列明和数据值要对应,多列与多个列值之间使用逗号隔开。
格式2:insert into 表名 values(第一行数据),(第二行数据);
插入多行
以上的操作只能实现一行的数据的插入,如果需要同时插入多行数据,也是很简单,使用格式如下:
insert into 表名(列名) values(第一行数据),(第二行数据),(),();
例:
insert into student(stuname,stuage,stusex,birthday)
values('张三3',18,'a','2000-1-1'),
('张三4',18,'a','2000-1-1'),
('张三5',18,'a','2000-1-1'),
('张三6',18,'a','2000-1-1'),
('张三7',18,'a','2000-1-1'),
('张三8',18,'a','2000-1-1');
注意:
- 列名与列值的类型、个数、顺序要依次对应
- 参数值不要超出列定义的长度
- 如果插入空值,可以使用null
- 插入的日期和字符,都要使用英文单引号
删(delete)
删除表中数据有两种方法,一种是使用关键字delete,另一种是使用关键字truncate。一般用的比较多的是delete。
- delete:
格式:delete from 表名 【WHERE 列名=值】 - truncat:
格式:truncate table 表名;
delete和truncate的区别(面试重点)
- DELETE 删除表中的数据,表结构还在;删除后的数据可以找回
- TRUNCATE 删除是把表直接DROP掉,然后再创建一个同样的新表。删除的数据不能找回。执行速度比DELETE快。
改(update)
格式:
update 表名 SET 列名1=列值1,列名2=列值2 … WHERE 列名=值
以上这些就是对数据的操作语句了,基本用到的目前就只有这些,这些都是比较常用的,需要记住。
3、DQL数据查询语言
前面聊了DDL和DML,数据库和表都有了,数据也有了,那如果需要从外部查看表的数据该怎么办呢。唉,不慌,这当然有办法了,这不是还有DQL数据查询语言还没开始讲呢。DQL是数据查询语言,使用DQL我们可以从表中查询所有我们想要的数据。使用DQL语句不会对数据进行改变,而是让数据库把查询结果集发给客户端。好吧,从简单的说起。
简单查询
查询表中所有数据:SELECT * FROM 表名;
查询指定列:select 列名1,列名2 from 表名
条件查询
条件查询就是在查询时给出WHERE子句,在WHERE子句中可以使用如下运算符及关键字=、!=、<>、<、<=、>、>=; BETWEEN…AND; IN(set); IS NULL; AND;OR; NOT;
简单的说条件查询就是在where后面添加限定的条件进行查询。
例如:查询性别为女,并且年龄50以内的记录
SELECT * FROM stu WHERE gender='female' AND age<50;
模糊查询
所谓模糊查询,可以顾名思义的理解为限定条件模糊(不是很明确具体)的查询。例如需要查询姓张的所有人的信息就是一个模糊查询。处理这种查询也有固定的语法格式,如下:
列名 like ‘表达式’
其中的表达式中需要使用到通配符。常用的通配符有两个:
- _(下划线):表示一个字符
- %:表示0-n个字符
刚刚提到的需要查询所有姓张的人,就可以使用 '张%'作为like后面的表达式来进行查询。
再举一个比较典型的例子,要查询名字中包含张字的人,表达式是这样子写的:’%张%‘
字段控制查询
字段其实就是列,当需要查询表中某列的数据时,可能会存在相同的数据,比如一个数据表中有一个字段为性别的字段,当需要查询这一列的信息的时候如果不使用字段控制,查出来的结果可能会有许多重复的数据,因为按正常来说性别就只有男和女两种,当查询这个字段时我们希望的是只查出男和女这两条数据,此时,我们就需要使用distinct关键字来取去除重复数据。
例如:
select distinct sex from student;
这样子查询出来的数据就不会包含重复值。
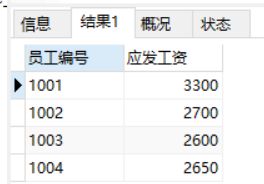
字段控制除了能用来去除重复值,还可以查询各字段通过算数运算的结果,但前提是要查询的字段必须是数值类型的数据,也就是能参与算数运算的数据。在计算出各字段运算后的结果时,可以使用关键字AS来给这个结果添加一个列名。也可以省略AS , 直接在运算表达式后面写上新增的列名。例如需要查询下表中的basesalary+titlesalary 作为’应发工资’
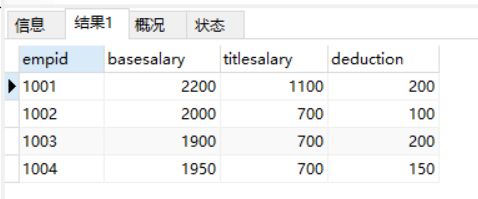
select empid as '员工编号', basesalary+titlesalary '应发工资' from salary;
结果如下:
排序(order by)
当需要对查询出来的结果进行排序,升序或降序时,可以使用order by来实现。
格式:
order by 列名 asc/desc
其中asc表示升序,desc 表示降序。也可以不写这两个关键字,默认是升序。
例如:需要将下表中的学生成绩进行降序排序
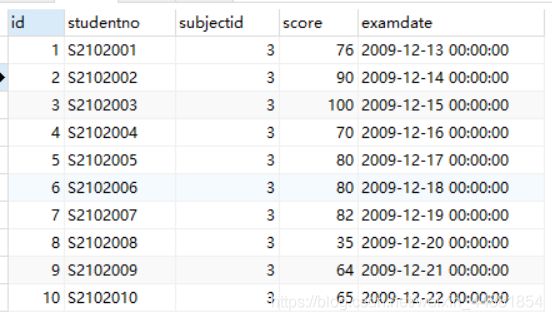
SELECT * from score ORDER BY score DESC

但是上面的查询结果我们看到有两个同学的成绩都是80分的,当有成绩相同的情况下,我们想按照学号进行降序排序,可以继续在order by 后面继续添加需要排序的列,列与列之间用逗号隔开。如下:
SELECT * from score ORDER BY score DESC,studentno DESC;
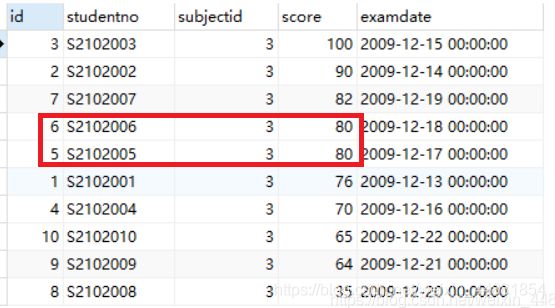
聚合函数
聚合函数是用来运算表中某一类数据的函数,有如下操作:
- COUNT(列名):统计指定列不为NULL的记录行数;
- MAX(列名):计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算;
- MIN(列名):计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算;
- SUM(列名):计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为0;
- AVG(列名):计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为0;
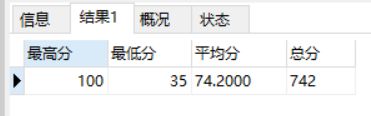
这些也都比较常用,也比较简单。就举一个简单的例子,就在刚刚排序的时候用到的score表,当要查询score表中成绩的最高分,最低分,平均分,总分,如下:
select MAX(score) 最高分, MIN(score) 最低分 ,
AVG(score)平均分,SUM(score) 总分 from score
分组查询(group by)
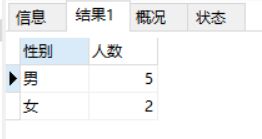
分组查询,顾名思义,就是使用部分来分组进行查询。例如需要查询男生的人数和女生的人数就需要使用到分组查询,分组查询需要使用group by 子句。这里需要注意的是,如果使用分组查询,那么select后面只能是聚合函数,或需要进行分组的列名。
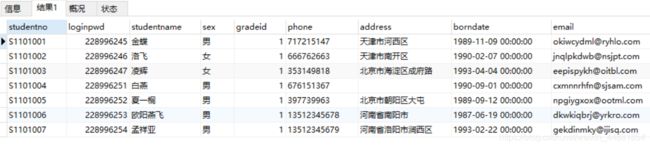
例如:要查询下面student表中男生和女生的人数。这里就需要对sex这个字段进行分组操作。
SELECT sex 性别, count(*) 人数 from student GROUP BY sex;
在分组查询中还有一个having子句,用来过滤分组后的数据,having子句不能单独出现。
having与where的区别
1.having是在分组后对数据进行过滤,where是在分组前对数据进行过滤
2.having后面可以使用分组函数(统计函数)
where后面不可以使用分组函数。
WHERE是对分组前记录的条件,如果某行记录没有满足WHERE子句的条件,那么这行记录不会参加分组;而HAVING是对分组后数据的约束。
多列分组:
统计出stu表中每个班级的男女生各多少人
select gradename,gender ,count(*) from stu
group by gradename,gender
LIMIT
LIMIT用来限定查询结果的起始行,以及总行数。
- limit 开始下标,显示条数;//开始下标从0开始
- limit 显示条数;//表示默认从0开始获取数据
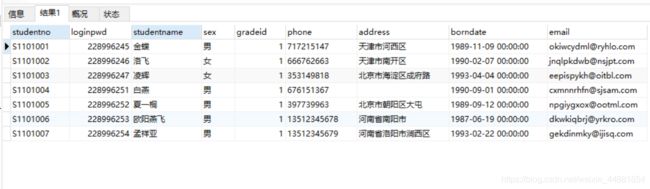
例如:查询10条记录,起始行从0开始
select * from student LIMIT 0,10
或
select * from student LIMIT 10
以上两个sql语句的查询结果是一样的
到这里基本的查询语句都已经聊完了,基础还有最后一个DCL没有聊,继续聊聊吧。
4、DCL数据控制语言
DCL是数据控制语言,用来定义访问安全权限和安全级别。经常用到的数据控制语言主要是用来创建用户、用户授权、用户权限查询、撤销用户权限、删除用户。
创建用户
格式1:
create user 用户名@指定ip identified by 密码;
例:create user test123@localhost IDENTIFIED by ‘test123’
格式2:
create user 用户名@客户端ip identified by 密码; 指定IP才能登陆
例:create user [email protected] IDENTIFIED by ‘test456’
格式3:
create user 用户名@‘% ’ identified by 密码 任意IP均可登陆
例:create user test7@’%’ IDENTIFIED by ‘test7’
用户授权
格式:(给指定用户授予指定指定数据库指定权限)
grant 权限1,权限2,…,权限n on 数据库名.* to 用户名@IP;
例:grant select,insert,update,delete,create on chaoshi.* to ‘test456’@‘127.0.0.1’;
给指定用户授予所有数据库所有权限:
grant all on . to ‘test456’@‘127.0.0.1’
用户权限查询
show grants for 用户名@IP;
例:show grants for ‘root’@’%’;
撤销用户权限
revoke 权限1,权限2,…,权限n on 数据库名.* from 用户名@IP;
例:REVOKE SELECT ON . FROM ‘root’@’%’ ;
删除用户
drop user 用户名@IP
例:drop user test123@localhost;
未完待续
数据库基础部分就先聊到这了,本来只想随便聊聊的,没想到又是个长篇大论,注意,这只是数据库的基础部分,咱们还有多表连接和事务都还没有聊,可是今天好像已经聊了很久了,那就改天再聊吧(主要是想溜了~)。内容看似不多,一聊起来巴拉巴拉没完没了的。改天见。感谢大伙儿的支持!