Pytorch中使用torchvision实现deform_conv2d
论文:Deformable ConvNets v2: More Deformable, Better Results
论文链接:https://arxiv.org/abs/1811.11168
在github上有许多实现,但都没有很方便的加入到自己的网络中。同时github上代码很长,对于我这种懒人根本不想调用。突然发现torchvision.ops.deform_conv2d代码,又苦于搜索不到具体如何使用。遂写下记录一下,方便其他人,同时本人学艺不精,如果有任何问题欢迎批评指正。
首先,我们需要回到论文,看如何定义Deformable_ConvNet(就直接贴图了)
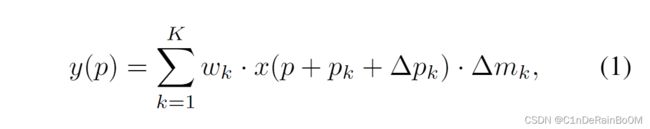
简单来说,将feature map当作一个一个网格,其中输出结果y中,点p这个坐标的值,取决于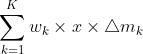 ,其中
,其中 为权重,
为权重,![]() 为论文中引入的modulation scalar factor。而
为论文中引入的modulation scalar factor。而 需要根据三个参数之和作为输入,
需要根据三个参数之和作为输入, 代表的是原坐标,
代表的是原坐标,![]() 是相对于坐标 的相对位移。例如,一个
是相对于坐标 的相对位移。例如,一个![]() 的卷积核,则
的卷积核,则![]() ,以上都是标准卷积。本文提出Deformable_Conv就在于加入了新的参数
,以上都是标准卷积。本文提出Deformable_Conv就在于加入了新的参数![]() ,即需要网络去学习的一个learnable offset。根据论文offset=
,即需要网络去学习的一个learnable offset。根据论文offset=![]() 和mask=
和mask=![]() 都需要进行学习。
都需要进行学习。
原文(The modulation scalar ![]() lies in the range [0,1], while
lies in the range [0,1], while ![]() is a real number with unconstrained range.)就是
is a real number with unconstrained range.)就是 ![]() 是一个0到1的数,这也很容易理解,它是一个模型响应参数,
是一个0到1的数,这也很容易理解,它是一个模型响应参数,![]() 随便取。
随便取。
原文(the initial values of ![]() and
and ![]() are 0 and 0.5, respectively. )初始化。
are 0 and 0.5, respectively. )初始化。
概念理清楚,接下来准备实际操作。(为了更直观,只取一个卷积层构建网络)
想要替换的正常卷积,代码如下:
class net(nn.Module):
def __init__(self):
super(net, self).__init__()
self.conv = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
def forward(self, x):
out = self.relu(self.conv(x))
return out使用deform_conv进行替换,代码如下:
class net(nn.Module):
def __init__(self):
super(dcn, self).__init__()
self.conv = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1) #原卷积
self.conv_offset = nn.Conv2d(3, 18, kernel_size=3, stride=1, padding=1)
init_offset = torch.Tensor(np.zeros([18, 3, 3, 3]))
self.conv_offset.weight = torch.nn.Parameter(init_offset) #初始化为0
self.conv_mask = nn.Conv2d(3, 9, kernel_size=3, stride=1, padding=1)
init_mask = torch.Tensor(np.zeros([9, 1, 3, 3])+np.array([0.5]))
self.conv_mask.weight = torch.nn.Parameter(init_mask) #初始化为0.5
def forward(self, x):
offset = self.conv_offset(x)
mask = torch.sigmoid(self.conv_mask(x)) #保证在0到1之间
out = torchvision.ops.deform_conv2d(input=x, offset=offset,
weight=self.conv.weight,
mask=mask, padding=(1, 1))
return out需要注意的点有deform_conv2d的stride默认为(1, 1),padding默认为(0, 0),dilation默认为(1, 1)。
ok!这样就可以完美的将normal_conv替换成deform_conv了!不需要再去github上去看别人巨长的代码了!感谢pytorch!
最后,随便用mnist数据集跑跑(训练集和验证集都加入了随机旋转,网络为四层卷积,三层全连接,加入了dropout,参数都一样,没有仔细调整)
normal_conv
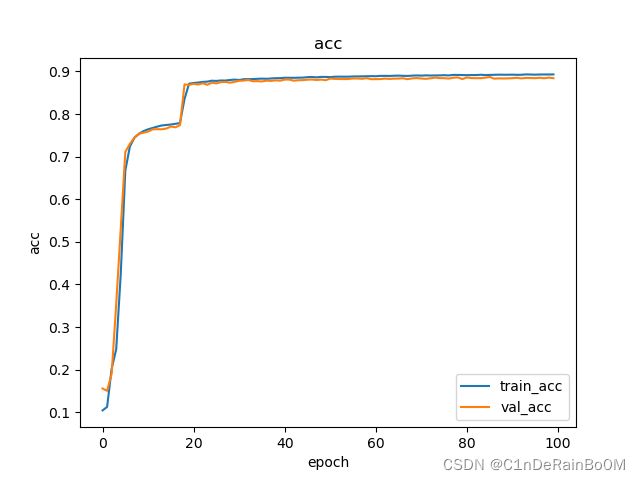
deform_conv

可以发现不仅收敛的更快,同时精度更高。deform_conv确实发挥了作用。
最后的最后,本人学艺不精,如果有任何问题,欢迎各位大神批评指正。