Zookeeper 3.5.7(铲屎官)学习教程
目录
- 一、Zookeeper介绍
- 二、Zookeeper的选举机制
-
- 1.服务器启动初始化
- 2.非第一次启动
- 三、脚本案例
-
- 1.启动脚本
- 2.客户端命令操作
- 四、动态监听服务器上下线
-
- 1.具体实现
- 五、Zookeeper分布式锁
-
- 1.实现Zookeeper分布式锁
- 2.Curator实现分布式锁
-
- 2.1官网解释:
- 2.2原生API缺点:
- 2.3curator实现案例
- 六、算法基础
-
- 1.拜占庭将军问题
- 2.Paxos算法
- 3.ZAB协议
-
- 3.1ZAB介绍
- 4.CAP理论
- 七、详细流程
-
- 1.Zookeeper服务端初始化流程
- 2.Zookeeper选举流程
一、Zookeeper介绍
- 是一个观察者模式设计的分布式框架,负责协调客户端与服务端。
- 存储和管理服务端和客户端的注册信息。
- 当服务端注册信息发生变化,通知客户端(上线、下线)。
- 相当于文件系统 + 通知机制。
zookeeper官网下载:https://archive.apache.org/dist/zookeeper/
二、Zookeeper的选举机制
- SID(服务器ID):服务器的唯一标识。
- ZXID(事务ID):用来标识一次服务器状态变更;所有的节点ZXID不一定一致,与Zookeeper的处理逻辑有关。
- Epoch:Leader任期的代号。
1.服务器启动初始化
每台服务器有自己的唯一标识SID,优先选举SID最大的为Leader。
- 5台服务器,服务器1启动,发起选举,投自己1票,当票数到达一半以上(3票),选举结束。
- 服务器2启动,发起选举,SID比服务器1大,投票给服务器2,服务器2有2票。
- 服务器3启动,发起选举,服务器3的SID最大,获得3票(大于一半),成为Leader。
2.非第一次启动
Zookeeper集群有两种情况会进入选举:
- 服务器启动初始化。
- 运行期间与Leader失去连接。
- 服务器与Leader断开连接时,想尝试选举,会被告知存在Leader信息,此时服务器需要建立联系,并更新状态即可。
- Leader挂了,5台服务器,SID为1、2、3、4、5,ZXID为6、6、6、5、5,Epoch都为1,节点3位Leader,3和5都挂了,进行选举:
- 选举比较的优先级:Epoch > ZXID > SID;
- Epoch大,直接胜出。
- Epoch相同,ZXID大胜出。
- ZXID相同,SID大胜出。
- 1、2、4的投票情况:
- 服务器1:1 6 1
- 服务器2:1 6 2
- 服务器4:1 5 4
- 第一轮:Epoch相同。
- 第二轮:服务器4淘汰(ZXID最小淘汰)。
- 第三轮:服务器2成为Leader(SID最大胜出)。
- 选举比较的优先级:Epoch > ZXID > SID;
总结:
- 比较Epoch,大的直接获胜。
- Epoch相同,ZXID大的胜出。
- ZXID相同,SID大的胜出。
三、脚本案例
1.启动脚本
启动hadoop102、hadoop103、hadoop104脚本
#!/bin/bash
# 判断没有参数
if [$# -lt 1]
then
echo "No Args Input..."
exit;
fi
case $1 in
"start")
for i in hadoop102 hadoop103 hadoop104
do
echo "----------------- zookeeper $i 启动 -----------------"
ssh $i "/opt/install/zookeeper-3.5.7/bin/zkServer.sh start"
done
;;
"stop")
for i in hadoop102 hadoop103 hadoop104
do
echo "----------------- zookeeper $i 停止 -----------------"
ssh $i "/opt/install/zookeeper-3.5.7/bin/zkServer.sh stop"
done
;;
"status")
for i in hadoop102 hadoop103 hadoop104
do
echo "----------------- zookeeper $i 状态 -----------------"
ssh $i "/opt/install/zookeeper-3.5.7/bin/zkServer.sh status"
done
;;
*)
echo "Input Args Error..."
;;
esac
查看启动报错日志:
# 查看启动报错日志
bin/zkServer.sh start-foreground
2.客户端命令操作
| 命令基本语法 | 功能描述 |
|---|---|
| help | 显示所有操作命令 |
| ls /path | 1.使用 ls 命令来查看当前 znode 的子节点 [可监听];2.-w 监听子节点变化;3.-s 附加次级信息 |
| create | 1.普通创建;2.-s 含有序列;2.-e 临时(重启或者超时消失) |
| get /path | 1.获得节点的值(可监听);2.-w 监听节点内容变化;3.-s 附加次级信息 |
| set | 设置节点的具体值 |
| stat | 查看节点状态 |
| delete | 删除节点 |
| deleteall | 递归删除节点 |
四、动态监听服务器上下线
在分布式系统中,有多个节点,可以动态上下线,客户端能够感知节点的上下线情况。
1.具体实现
集群上创建/servers节点
# 启动客户端
bin/zkCli.sh
# 创建节点
create /servers "servers"
DistributeServer.java
import org.apache.zookeeper.*;
import java.io.IOException;
public class DistributeServer {
private static String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";
private static int sessionTimeout = 2000;
private ZooKeeper zk = null;
private String parentNode = "/servers";
// 创建到 zk 的客户端连接
public void getConnect() throws IOException {
zk = new ZooKeeper(connectString, sessionTimeout, event -> {
});
}
// 注册服务器
public void registerServer(String hostname) throws Exception {
String create = zk.create(parentNode + "/server",
hostname.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
System.out.println(hostname + " is online " + create);
}
// 业务功能
public void business(String hostname) throws Exception {
System.out.println(hostname + " is working ...");
Thread.sleep(Long.MAX_VALUE);
}
public static void main(String[] args) throws Exception {
// 1 获取 zk 连接
DistributeServer server = new DistributeServer();
server.getConnect();
// 2 利用 zk 连接注册服务器信息
server.registerServer(args[0]);
// 3 启动业务功能
server.business(args[0]);
}
}
DistributeClient.java
import org.apache.zookeeper.ZooKeeper;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class DistributeClient {
private static String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";
private static int sessionTimeout = 2000;
private ZooKeeper zk = null;
private String parentNode = "/servers";
// 创建到 zk 的客户端连接
public void getConnect() throws IOException {
zk = new ZooKeeper(connectString, sessionTimeout, event -> {
// 再次启动监听
try {
getServerList();
} catch (Exception e) {
e.printStackTrace();
}
});
}
// 获取服务器列表信息
public void getServerList() throws Exception {
// 1 获取服务器子节点信息,并且对父节点进行监听
List<String> children = zk.getChildren(parentNode, true);
// 2 存储服务器信息列表
ArrayList<String> servers = new ArrayList<>();
// 3 遍历所有节点,获取节点中的主机名称信息
for (String child : children) {
byte[] data = zk.getData(parentNode + "/" + child,
false, null);
servers.add(new String(data));
}
// 4 打印服务器列表信息
System.out.println(servers);
}
// 业务功能
public void business() throws Exception {
System.out.println("client is working ...");
Thread.sleep(Long.MAX_VALUE);
}
public static void main(String[] args) throws Exception {
// 1 获取 zk 连接
DistributeClient client = new DistributeClient();
client.getConnect();
// 2 获取 servers 的子节点信息,从中获取服务器信息列表
client.getServerList();
// 3 业务进程启动
client.business();
}
}
五、Zookeeper分布式锁
分布式锁和分布式事务的区别:
- 分布式锁:解决并发资源抢占问题。
- 采用redis(redission)、zookeeper(curator)解决。
- 分布式事务:解决顺序化提交问题,保证事务遵循ACID原则。
- 采用rocketMQ解决。
- 2PC(Two-phase commit protocol)二段提交,分别是准备阶段、提交阶段
- 3PC三段提交,分别是准备阶段、预提交阶段和提交阶段,把2PC的提交阶段拆分为两个阶段。
- TCC(Try - Confirm - Cancel),2PC和3PC是强一致事务性,都是数据库层面的,TCC是业务层面的。
参考:https://zhuanlan.zhihu.com/p/183753774
1.实现Zookeeper分布式锁
pom.xml
<dependency>
<groupId>org.apache.zookeepergroupId>
<artifactId>zookeeperartifactId>
<version>3.5.7version>
dependency>
DistributedLock.java
package com.cnwanj.distributed;
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import java.io.IOException;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.CountDownLatch;
/**
* @author: cnwanj
* @date: 2022-02-19 15:55:41
* @version: 1.0
* @desc: Zookeeper分布式锁实现
*/
public class DistributedLock {
private final String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";
private final int sessionTimeout = 2000;
private final ZooKeeper zk;
// 等待连接完毕
private CountDownLatch connectLatch = new CountDownLatch(1);
// 等待监听上一个节点完毕
private CountDownLatch waitLatch = new CountDownLatch(1);
// 前一个节点路径
private String waitPath;
private String currentMode;
public DistributedLock() throws IOException, InterruptedException, KeeperException {
// 建立连接
zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
// 释放连接等待(若已建立连接)
if (watchedEvent.getState() == Event.KeeperState.SyncConnected) {
connectLatch.countDown();
}
// 释放监听等待(存在释放锁 && 路径是前一个节点)
if (watchedEvent.getType() == Event.EventType.NodeDeleted && watchedEvent.getPath().equals(waitPath)) {
waitLatch.countDown();
}
}
});
// 线程等待,建立连接再执行后面
connectLatch.await();
// 判断根目录是否存在
Stat stat = zk.exists("/locks", false);
if (stat == null) {
// 创建根节点(参数1:目录名称,参数2:目录下内容,参数3:对外开放,参数4:永久创建)
zk.create("/locks", "locks".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
}
// 加锁
public void zkLock() throws KeeperException, InterruptedException {
// 创建临时带序号节点
currentMode = zk.create("/locks/" + "seq-", null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
// 校验节点是否第一个,是的话直接加锁,若不是,需要监听前一个是否解锁
List<String> childrenList = zk.getChildren("/locks", false);
// 如果只有一个节点,直接获取锁
if (childrenList.size() == 1) {
return;
} else {
// 从小到大排序
Collections.sort(childrenList);
// 当前节点名称
String thisNode = currentMode.substring("/locks/".length());
// 获取节点位置
int index = childrenList.indexOf(thisNode);
if (index == -1) {
System.out.println("数据异常");
} else if (index == 0) {
// thisNode为最小,直接获取锁
return;
} else {
// 获取前一个节点路径
waitPath = "/locks/" + childrenList.get(index - 1);
// 获取前一个节点,初始化监听
zk.getData(waitPath, true, null);
// 等待监听
waitLatch.await();
return;
}
}
}
// 解锁
public void unZkLock() throws KeeperException, InterruptedException {
// 删除节点
zk.delete(currentMode, -1);
}
}
DistributedLockTest.java
package com.cnwanj.distributed;
import org.apache.zookeeper.KeeperException;
import java.io.IOException;
/**
* @author: cnwanj
* @date: 2022-02-19 21:50:39
* @version: 1.0
* @desc: 测试Zookeeper分布式锁
*/
public class DistributedLockTest {
public static void main(String[] args) throws InterruptedException, IOException, KeeperException {
// 创建分布式锁1
final DistributedLock lock1 = new DistributedLock();
// 创建分布式锁2
final DistributedLock lock2 = new DistributedLock();
// 创建线程1
new Thread(() -> {
// 获取锁对象
try {
lock1.zkLock();
System.out.println("线程1获取锁");
Thread.sleep(3 * 1000);
lock1.unZkLock();
System.out.println("线程1释放锁");
} catch (KeeperException | InterruptedException e) {
e.printStackTrace();
}
}).start();
// 创建线程2
new Thread(() -> {
try {
lock2.zkLock();
System.out.println("线程2获取锁");
Thread.sleep(3 * 1000);
lock2.unZkLock();
System.out.println("线程2释放锁");
} catch (KeeperException | InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
2.Curator实现分布式锁
2.1官网解释:
Apache Curator is a Java/JVM client library for Apache ZooKeeper, a distributed coordination service. It includes a highlevel API framework and utilities to make using Apache ZooKeeper much easier and more reliable. It also includes recipes for common use cases and extensions such as service discovery and a Java 8 asynchronous DSL.
意思是:Curator是Zookeeper的一个Java/Jvm客户端库,也是一个分布式协调服务,Curator成为Zookeeper更简单可靠的一个高可用框架和工具,它也包含了一些常用的用例和扩展方法,如Java8和异步DSL。
官网:https://curator.apache.org
2.2原生API缺点:
- 会话连接是异步的,需要自己去处理;比如使用 CountDownLatch。
- Watch 需要重复注册,不然就不能生效。
- 开发的复杂性还是比较高的。
- 不支持多节点删除和创建,需要自己去递归。
2.3curator实现案例
maven依赖引入:
<dependency>
<groupId>org.apache.zookeepergroupId>
<artifactId>zookeeperartifactId>
<version>3.5.7version>
dependency>
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-frameworkartifactId>
<version>4.3.0version>
dependency>
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-recipesartifactId>
<version>4.3.0version>
dependency>
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-clientartifactId>
<version>4.3.0version>
dependency>
package com.cnwanj.lock.curator;
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.apache.curator.retry.ExponentialBackoffRetry;
/**
* @author: cnwanj
* @date: 2022-02-20 11:57:56
* @version: 1.0
* @desc: curator实现分布式锁
*/
public class CuratorTest {
private String rootNode = "/locks";
private String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";
private int connectionTimeout = 2000;
private int sessionTimeout = 2000;
public static void main(String[] args) {
new CuratorTest().test();
}
private void test() {
// 分布式锁1
InterProcessMutex lock1 = new InterProcessMutex(getCuratorFramework(), rootNode);
// 分布式锁2
InterProcessMutex lock2 = new InterProcessMutex(getCuratorFramework(), rootNode);
// 线程1
new Thread(() -> {
try {
lock1.acquire();
System.out.println("线程1获取锁");
lock1.acquire();
System.out.println("线程1再次获取锁");
Thread.sleep(5 * 1000);
lock1.release();
System.out.println("线程1释放锁");
lock1.release();
System.out.println("线程1再次释放锁");
} catch (Exception e) {
e.printStackTrace();
}
}).start();
// 线程1
new Thread(() -> {
try {
lock2.acquire();
System.out.println("线程2获取锁");
lock2.acquire();
System.out.println("线程2再次获取锁");
Thread.sleep(5 * 1000);
lock2.release();
System.out.println("线程2释放锁");
lock2.release();
System.out.println("线程2再次释放锁");
} catch (Exception e) {
e.printStackTrace();
}
}).start();
}
private CuratorFramework getCuratorFramework() {
// 重试策略,尝试时间3秒,重试3次
RetryPolicy policy = new ExponentialBackoffRetry(3000, 3);
// 创建Curator
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString(connectString)
.connectionTimeoutMs(connectionTimeout)
.sessionTimeoutMs(sessionTimeout)
.retryPolicy(policy)
.build();
// 开启连接
client.start();
System.out.println("zk初始化完成...");
return client;
}
}
六、算法基础
1.拜占庭将军问题
拜占庭将军问题是一个协议问题,拜占庭帝国军队的将军们必须全体一致的决定是否攻击某一支敌军。问题是这些将军在地理上是分隔开来的,并且将军中存在叛徒。叛徒可以任意行动以达到以下目标:欺骗某些将军采取进攻行动;促成一个不是所有将军都同意的决定,如当将军们不希望进攻时促成进攻行动;或者迷惑某些将军,使他们无法做出决定。如果叛徒达到了这些目的之一,则任何攻击行动的结果都是注定要失败的,只有完全达成一致的努力才能获得胜利。
2.Paxos算法
**Paxos算法:**一种基于消息传递且具有高度容错特性的一致性算法。
**Paxos算法解决的问题:**就是如何快速正确的在一个分布式系统中对某个数据值达成一致,并且保证不论发生任何异常,都不会破坏整个系统的一致性。
3.ZAB协议
3.1ZAB介绍
Zab 借鉴了 Paxos 算法,是特别为 Zookeeper 设计的支持崩溃恢复的原子广播协议。基于该协议,Zookeeper 设计为只有一台客户端(Leader)负责处理外部的写事务请求,然后Leader 客户端将数据同步到其他 Follower 节点。即 Zookeeper 只有一个 Leader 可以发起提案。
4.CAP理论
CAP理论告诉我们,一个分布式系统不可能同时满足以下三种:
- 一致性(Consistency)
- 可用性(Available)
- 分区容错性(Partition Tolerance)
这三个基本需求,最多只能同时满足其中的两项,因为P是必须的,因此往往选择就在CP或者AP中。
1)一致性(Consistency)
在分布式环境中,一致性是指数据在多个副本之间是否能够保持数据一致的特性。在一致性的需求下,当一个系统在数
据一致的状态下执行更新操作后,应该保证系统的数据仍然处于一致的状态。
2)可用性(Available)
可用性是指系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。
3)分区容错性(Partition Tolerance)
分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络
环境都发生了故障。
ZooKeeper保证的是CP
- Zookeeper不能保真每次服务请求都可用(在极端环境下,ZooKeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果)。所以说,ZooKeeper不能保证服务可用性。
- 进行Leader选举时集群不可用。
七、详细流程
1.Zookeeper服务端初始化流程
zkServer.sh start启动 > new QuorumPeerMain();
- 解析参数:包括解析zoo.cfg、myid等配置文件。
- 删除过期快照:默认关闭,最少保留3份,开启后会清理过期数据。
- 建立通信:默认NIO通信,初始化服务端socket,绑定2181端口。
- 启动zookeeper(quorumPeer.start())。
NIO:
- 非堵塞IO通信方式,由一个线程处理所有的IO事件,并负责分发。
- 线程之前通过wait、notify通信,减少线程切换。
- 事件来到时触发操作,不需要堵塞监视事件,存在驱动机制。
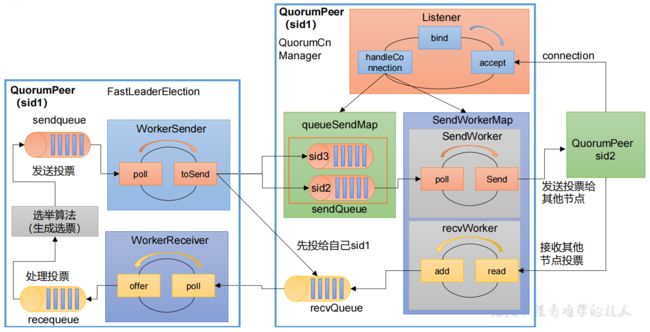
2.Zookeeper选举流程
选举主要分为两步:发送投票和处理投票
通过选举算法(FastLeaderElection)生成选票。
发送选票:
-
FastLeaderElection类:
- 生成选票。
- 将票放入队列(sendqueue)。
- 推(poll)到缓冲区(WorkerSender)中,并发送到管理队列(queueSendMap)中。
-
QuorumCnManager类:
- 从管理队列中poll到发送者中。
- 发送者发送(send)给其他节点。
处理选票:
- QuorumCnManager类:
- recvWorker(接收者)读取其他节点的投票。
- 将投票添加到recvQueue(接收队列)中。
- FastLeaderElection类:
- 通过recvQueue(接收队列)中的投票poll到WorkerReceiver(工作接收者)中。
- WorkerReceiver(工作接收者)将投票放入recequeue队列中。
- 最后生成选票