r语言结构方程模型可视化_模型一个结构方程模型(SEM)的简单实验
结构方程模型基于研究者的先验知识预先设定系统内因子间的依赖关系, 不仅能够判别各因子之间的关系强度(路径系数), 还能对整体模型进行拟合和判断, 从而能更全面地了解自然系统。结构方程模型明确考虑因果关系,A→B表示A影响B,即因为A所以B。并且可以存在A→B和C,即因为A所以BC,A可以为生长情况等潜变量,BC为胸径树高等指标变量;还可以分析潜在变量之间的关系。并且考虑了因变量的随机误差,是一个能够全面反映整体关系的分析方法。
具体用R语言怎么实现?
①下载两个包“lavaan”与“semPlot”。
②以自带数据为例:
head(HolzingerSwineford1939,10)
③构建一个结构模型:
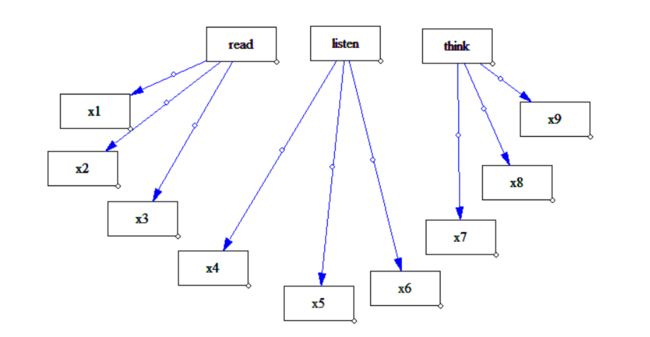
如这种,觉得x1x2x3与read能力相关,x4x5x6与listen能力相关,x7x8x9与think能力相关。
④验证性因子分析
hz=HolzingerSwineford1939model="read=~x1+x2+x3;listen=~x4+x5+x6;think=~x7+x8+x9"fit=cfa(model=model,data=hz)summary(fit,standardized=TRUE) #其中最上面的是整个模型的P值。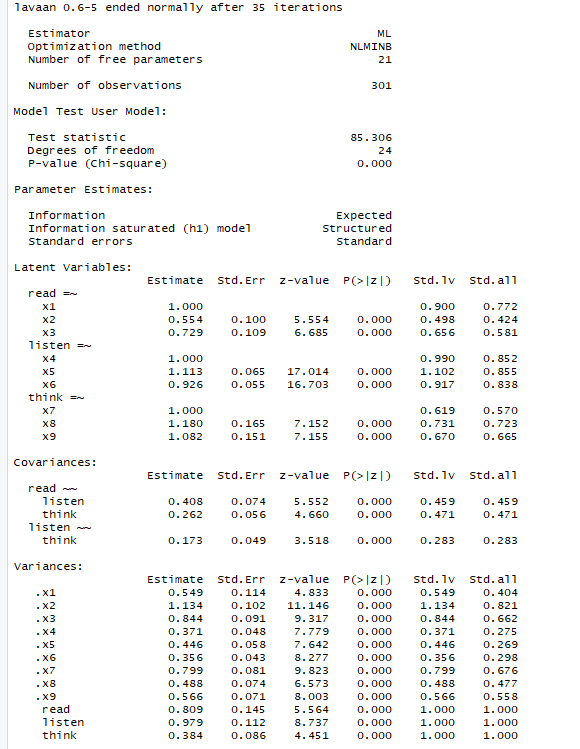
可视化:
par(mfrow=c(1,2));semPaths(fit,what="est",layout="tree");semPaths(fit,what="std",layout="tree")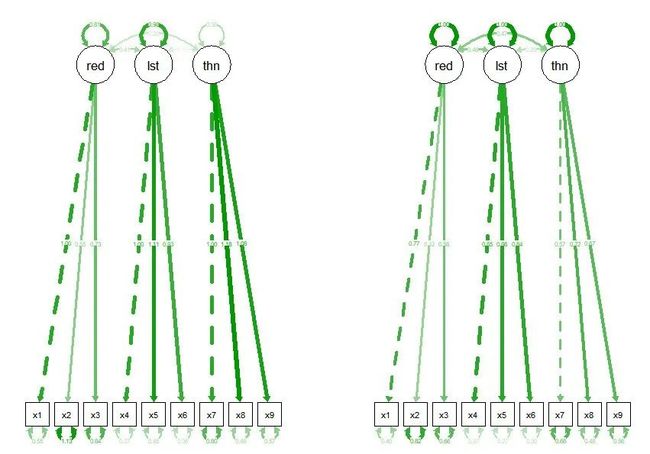
其间的数字为路径系数,反应各关系的强度大小,可正可负,反应受因子的正负效应。根据what可选择不同的标准。
⑤评价
fitmeasures(fit,c("cfi","rmsea","bic","rmsea.ci.upper"))
![]()
主要看cfi(比较拟合指数,越大越好,一般要超过0.9);rmaea(近似均方根误差,越小越好,一般以0.01,0.05,0.08为界,小于0.05效果较好)。
⑥调整
假如评价效果不好,怎么调整呢?
mf=modificationindices(fit)
mf=mf[order(mf$mi,mf$epc,decreasing = TRUE),]以mi排序,mi大的优先调整。
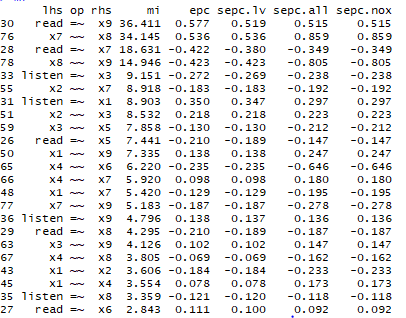
即可在步骤④中的read的关系加入x9再尝试。
即:model="read=~x1+x2+x3+x9;listen=~x4+x5+x6;think=~x7+x8+x9"可以知道结果确实优化了。
⑦这里是构造了三个潜变量,实际上潜变量的位置也可以变成可测度的数值,
model="read~x1+x2+x3+x9;listen~x4+x5+x6;think~x7+x8+x9"
那时候其实更加变成了一个线性模型了。
refence:
王酉石,储诚进.结构方程模型及其在生态学中的应用[J].植物生态学报,2011,35(03):337-344.
B站bili_MoonRiver的结构方程模型实现