服务调用方式
1. HTTP协议的通信框架
1. HttpURLConnection
HttpURLConnection是java原生支持的。
2. Apache Common HttpClient
HttpClient是Apache Common下的,可以用来提供高效的、功能丰富的HTTP协议的客户端编程工具包。
- 实现了所有的HTTP方法(GET、POST、PUT、HEAD等)
- 支持HTTPS协议
- 支持代理服务器
3. OKhttp3
OKHttp是一个当前主流的网络请求开源框架,可以替代HttpUrlConnection和Apache HttpClient
- 支持http2.0,对一台机器的请求共享一个socket
- 采用连接池技术,可以有效的减少http连接数量
- 无缝集成GZIP压缩技术
- 支持Response Cache,避免重复请求
- 域名多IP支持
4. RestTemplate
Spring RestTemplate是Spring提供的用于访问Rest服务的客户端。
- 面向URL组件,必须依赖于主机+端口+URI
- RestTemplate不依赖于服务接口,仅关注REST响应内容
- Spring Cloud Feign通信在使用RestTemplate
2. RPC框架
1. Java RMI
2. Hessian
Hessian是一个轻量级的remoting on http工具,使用简单的方法提供了RMI的功能。采用的是二进制RPC协议。
3. Dubbo
Dubbo是阿里巴巴公司开源的一个高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和Spring框架无缝集成。Dubbo是一款高性能、轻量级的开源Java RPC框架,它提供了三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现
4. gRPC
gRPC是由Google公司开源的一款高性能的远程过程调用(RPC)框架,可以在任何环境下运行。该框架提供了负载均衡,跟踪,智能监控,身份验证等功能,可以实现系统间的高效连接
3. 跨域
在分布式系统中,会有调用其他业务系统的场景,导致出现跨域问题。跨域实质上是浏览器的一种保护处理请求是可以正常发起的,服务端也是正常接受,只是浏览器对其进行了拦截,导致响应内容不可用。

产生跨域的几种情况如下:
| 当前页面URL | 被请求页面URL | 是否跨域 | 原因 |
|---|---|---|---|
| http://www.lagou.com/ | https://www.lagou.com/ | 跨域 | 协议不同(http、https) |
| http://www.lagou.com/ | http://www.baidu.com | 跨域 | 主域名不同 |
| http://www.lagou.com/ | http://kuai.lagou.com | 跨域 | 子域名不同 |
| http://www.lagou.com:8080 | http://www.lagou.com:8090 | 跨域 | 端口不同 |
常见的解决方案
- 使用jsonp解决网站跨域
缺点:不支持post请求,代码书写比较复杂
-
使用HttpClient内部转发
-
使用设置响应头允许跨域
response.setHeader(“Access-Control-Allow-Origin”, “*”); 设置响应头允许跨域.
-
基于Nginx搭建接口API网关
-
使用Zuul搭建微服务API网关
分布式服务治理
1. 服务协调
分布式协调技术主要用来解决分布式环境当中多个进程之间的同步控制,让他们有序的去访问某种临界资源,防止造成“脏数据”的后果。
分布式锁两种实现方式:
- 基于Redis实现分布式锁
- 基于ZooKeeper实现
2. 服务削峰
削峰从本质上来说就是更多的延缓用户请求,以及层层过滤用户的访问需求,遵从“落地到数据库的请求数要尽量少”的原则
- 消息队列
- 流量削峰漏斗:通过CDN->缓存系统->后台系统->DB ,层层减少后打到DB的流量就少了

3. 服务降级
整个架构整体的负载超出了预设的上限阈值时,为了保证重要或基本的服务能正常运行,我们可以将一些不重要或不紧急的服务或任务进行服务的延迟使用或暂停使用
降级方案:
- 页面降级 :可视化界面禁用点击按钮、调整静态页面
- 延迟服务:如定时任务延迟处理、消息入MQ后延迟处理
- 写降级:直接禁止相关写操作的服务请求
- 读降级:直接禁止相关读服务请求
- 缓存降级:使用缓存方式来降级部分读频繁的接口
后端代码层的处理方式:
- 抛异常
- 返回NULL
- 调用Mock数据
- 调用Fallback处理逻辑
可以将服务架构进行故障风暴分级,根据具体的等级进行降级

4. 服务限流
限流是为了对并发请求进行限制来保护系统。一旦达到限制我们可以拒绝服务、排队或等待
限流算法:
1. 固定窗口计数器
计数器限制每时间内(如一分钟内)请求数不超过一定的值,再下一时间内计数器清零重新计算
存在问题:已知客户端限流1分钟100次。如果客户端在第一分钟的59秒请求了100次,又在第二分钟的第1秒请求了100次,这样两秒内后端就会受到200次请求的压力
2. 滑动窗口计数器
针对固定时间算法会在临界点存在瞬间大流量冲击的场景,滑动时间窗口计数器算法应运而生。它将时间窗口划分为更小的时间片段,每过一个时间片段,时间窗口就右滑一格,每个时间片段都有独立的计数器。我们计算整个时间窗口内的请求总数时会累加所有时间片段内的计数器。
时间窗口划分的越细,那么滑动窗口的滚动就越平滑。
下面举例说明滑动窗口是如何解决临界时间瞬间流量的问题:

一个时间窗口是60s,请求数最大100次。我们分为了3个时间片段。
在0:59时打入了100个请求,落在第3个格子(灰色标记)上(统计0:40-1:00的请求)。1:00的时候窗口右滑,1:01时又打入100个请求,此时打到了第四个(蓝色标记)格子(统计1:01-1:20)。此时统计整个时间窗口的流量是200个,后续的请求将拒绝。
3. 漏桶算法
漏桶算法类似一个限制出水速度的水桶,不管你放多少水,我都是匀速出水,当桶满了,就会溢出。

实现:一个固定大小的FIFO队列,定时取元素,队列满了再加入请求直接拒接。
- 优点:可以削峰,不会出现流量突刺现象。
- 缺点:桶队列中的请求会排队,响应时间变长。
4. 令牌桶算法
令牌桶算法是以一个恒定的速度往桶里放令牌,桶满了就废弃,每进来一个请求就去桶里拿令牌,拿到令牌就可以处理请求,没有令牌了就拒绝请求。
- 优点:应对突发流量,桶里有令牌时可以快速响应
- 缺点:相对漏桶一定程度上对下游的保护没那么大
5. 服务熔断
在互联网系统中,当下游系统变慢或宕机时,上游服务为了保护系统整体的可用性,可以暂时切断对下游服务的调用。这种牺牲局部,保全整体的措施就叫做熔断。
一般的熔断机制:
- 开启熔断
在固定时间窗口内,接口调用超时比率达到一个阈值,会开启熔断。进入熔断状态后,后续对服务接口的调用不再经过网络,直接执行本地的默认方法,达到服务降级的效果。
2. 熔断恢复
熔断不可能是永久的,当经过了规定时间之后,服务将从熔断状态恢复过来,再次接受调用方的远程调用。
Spring Cloud Hystrix
Spring Cloud Hystrix是基于Netflix的开源框架Hystrix实现,该框架实现了服务熔断、线程隔离等一系列服务保护功能。
对于熔断机制的实现,Hystrix设计了三种状态:
- 熔断关闭状态(Closed)
服务没有故障时,熔断器所处的状态,对调用方的调用不做任何限制。 - 熔断开启状态(Open)
在固定时间内(Hystrix默认是10秒),接口调用出错比率达到一个阈值(Hystrix默认为50%),会进入熔断开启状态。进入熔断状态后,后续对该服务接口的调用不再经过网络,直接执行本地的fallback方法。 - 半熔断状态(Half-Open)
在进入熔断开启状态一段时间之后(Hystrix默认是5秒),熔断器会进入半熔断状态。所谓半熔断就是尝试恢复服务调用,允许有限的流量调用该服务,并监控调用成功率。如果成功率达到预期,则说明服务已恢复,进入熔断关闭状态;如果成功率仍旧很低,则重新进入熔断开启状态。
三个状态的转化关系如下图:

Sentinel
Sentinel和Hystrix的原则是一致的,当调用链路中某个资源出现不稳定,例如,表现为timeout,异常比例升高的时候,则对这个资源的调用进行限制,并让请求快速失败,防止影响到其他的资源。
Sentinel熔断手段:
- 通过对并发线程数进行限制
- 通过响应时间对资源降级
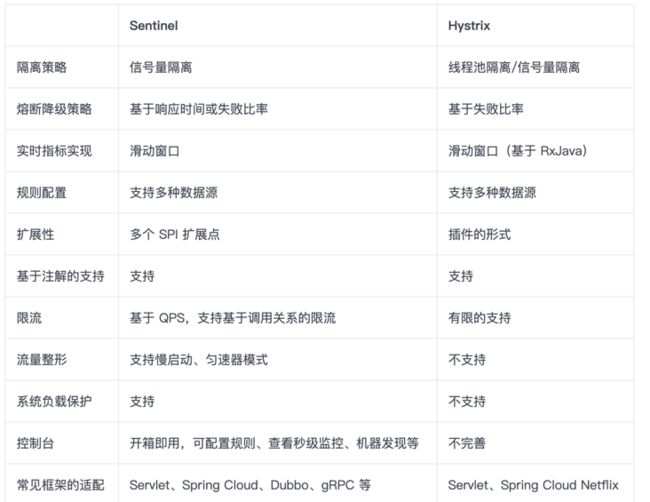
Sentinel和Hystrix对比
6. 链路追踪
分布式微服务架构上通过业务来划分服务的,通过REST调用对外暴露的一个接口,可能需要很多个服务协同才能完成这个接口功能。随着服务的越来越多,对调用链的分析会越来越复杂。
链路追踪的作用:
- 故障快速定位
- 分析各个调用环节的性能
- 数据分析,可以分析用户的行为路径。
- 生成服务调用拓补图
链路跟踪设计原则
- 设计目标
- 低侵入性,应用透明
- 低损耗
- 大范围部署,扩展性
- 埋点和生成日志
埋点即系统在当前节点的上下文信息,可以分为客户端埋点、服务端埋点,以及客户端和服务端双向型埋点。埋点日志通常要包含以下内容:TraceId、RPCId、调用的开始时间,调用类型,协议类型,调用方ip和端口,请求的服务名等信息;调用耗时,调用结果,异常信息,消息报文等
3. 抓取和存储日志
日志的采集和存储有许多开源的工具可以选择,一般来说,会使用离线+实时的方式去存储日志,主要是分布式日志采集的方式。典型的解决方案如Flume结合Kafka。
-
分析和统计调用链数据
一条调用链的日志散落在调用经过的各个服务器上,首先需要按 TraceId 汇总日志,然后按照RpcId对调用链进行顺序整理。调用链数据不要求百分之百准确,可以允许中间的部分日志丢失。 -
计算和展示
汇总得到各个应用节点的调用链日志后,可以针对性的对各个业务线进行分析。需要对具体日志进行整理,进一步储存在HBase或者关系型数据库中,可以进行可视化的查询。
大的互联网公司都有自己的分布式跟踪系统,比如Google的Dapper,Twitter的zipkin,淘宝的鹰眼,新浪的Watchman,京东的Hydra,国内开源爱好者开源的Skywalking。