mysql--②dql:基本查询
文章目录
-
- • 数据准备
- • 简单查询(不加条件)
- 3、别名查询
- • 基本查询
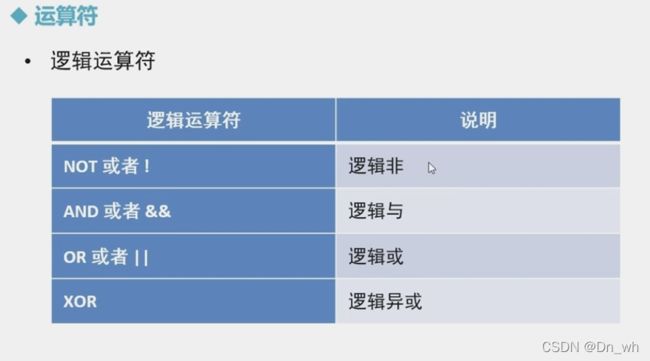
- 逻辑运算符
- • 运算符操作
- • 位运算符
- • 聚合查询
- • 聚合函数--NULL处理:视而不见
- • 分组查询--`group by ,having`
- 分组查询--分组之后的条件筛选-`having`语句
- • 分页查询--`limit`
- • insert into select 语句
- • 总结
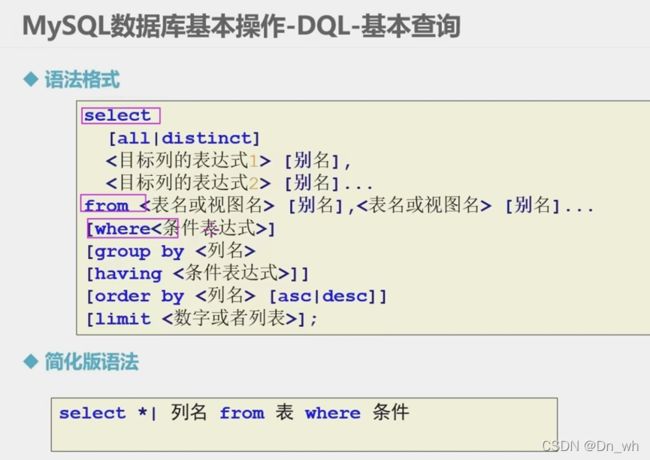
• 数据库最重要的功能
• 使用select语句
• 查询语句
select * 列名字 from 表 where 条件
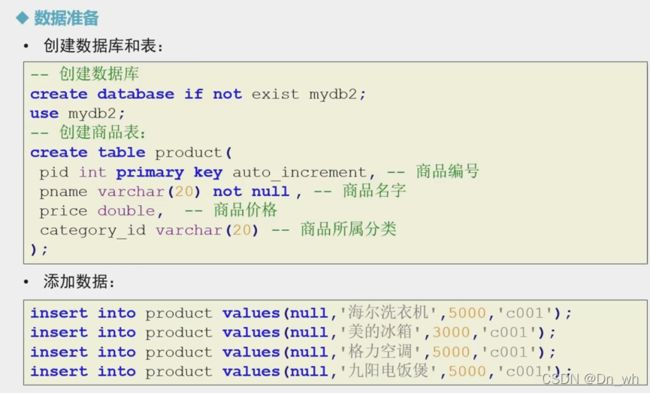
• 数据准备
1、创建数据库和表
2、添加数据
• 简单查询(不加条件)
1、查询所有商品
两种方法:
一是把所有的列都列出来
二是 用 * 代替

2、查询指定列

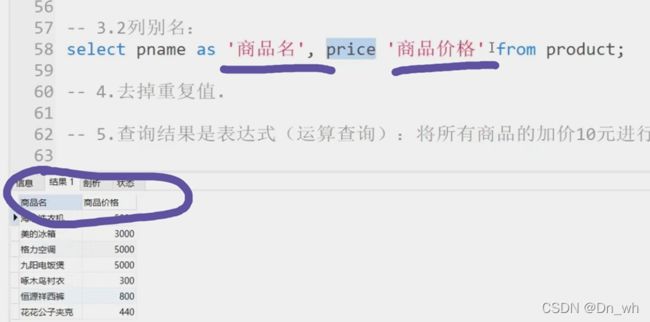
3、别名查询
①表别名

②列别名
可以用汉字,在实际的开发中,一般用英文
在对有些列进行相加相减的时候,起别名比较方便
4、去掉重复值:distinct
第一条语句是删除某一列重复的信息
第二条语句是删除所有列都重复的信息
select distinct price from product;
select distinct * from product;
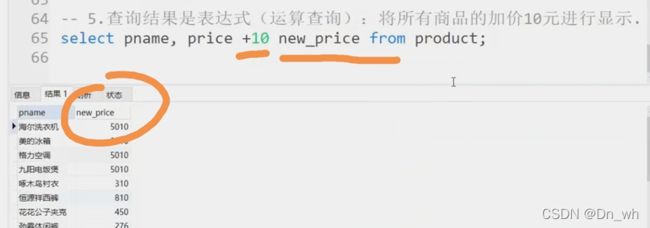
5、查询结果是表达式(运算查询):将所有商品的加价10元进行显示
这个你如果不加new_price 的话,那个表名字就是price+10;
• 基本查询
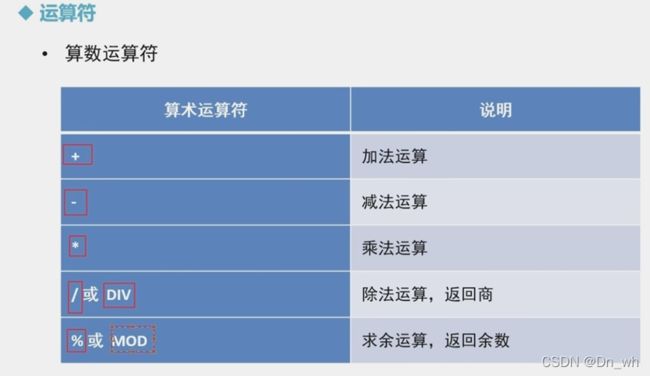
<=> 完全等于,用于比较null值
regexp 比较运算符

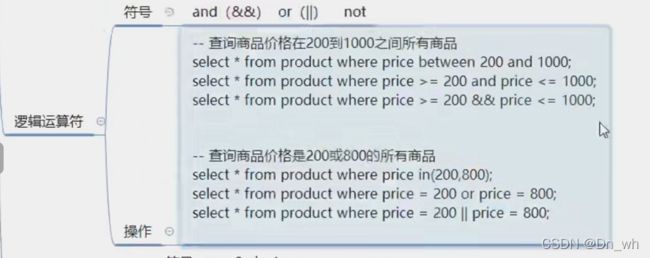
逻辑运算符
对二进制进行 位运算的位运算符

• 运算符操作

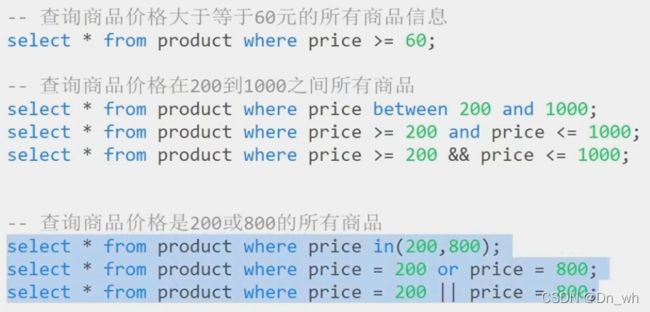
• 运算符操作 条件查询

查询:
大于等于
在两个数据之间
① between ...and
②and
③&&
满足两个条件其中之一
①in 关键字
② or
③ ||
查询带有某个字的:like关键字
如:查询含有“鞋”字的所有商品
select * from product where pname like '%鞋%’; --%用来匹配任意字符
查询某个字开头的

查询第二个字是:hi 的商品--下划线匹配单个字符

查询某一项为null,不能用等于null,因为null和任何数都不等,要用 is null
不是null ,要用 is not null

查询最大最小值,要使用相关函数
least()
greatest()

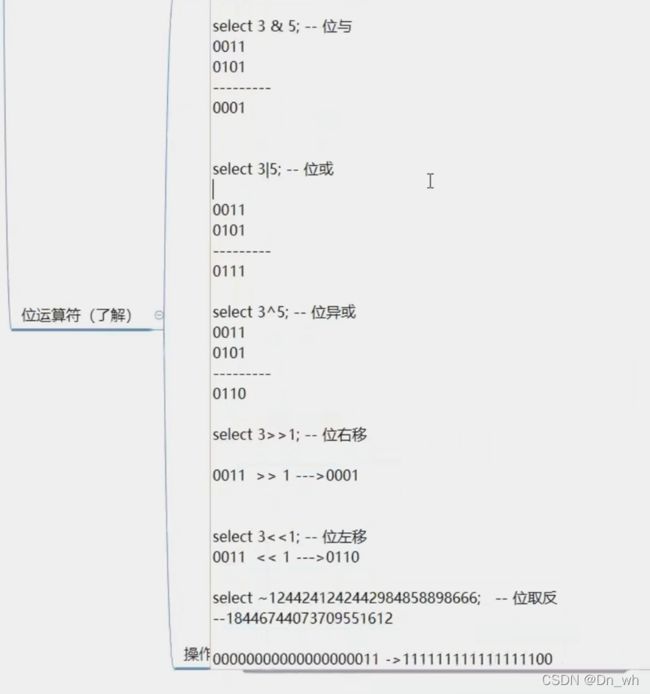
• 位运算符
与运算:只有全为1,结果才为1
或运算:有一个1,结果为1

异或:相同0,不同1
右移,正数补0

取反:~
0---->1
1---->0
计算机底层32位
• 排序查询:order by


第三个查询:由于是经过 去重的,不能选择某一列,要整表查询
• 聚合查询
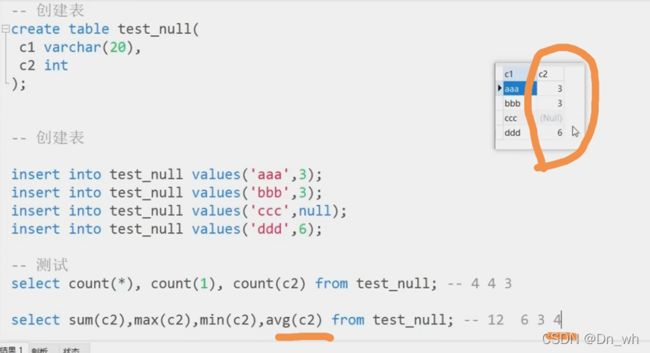
null 不统计

1、查询商品的总条目
一般查询主键的条数
- :代表不为空的列
– 查询商品的总条数
select count (pid) from product;
select count (*) from product;
2、查询约束条件下的条目数
–查询价格大于200商品的总条数
select count(pid) from product where price > 200;
3、查询约束条件下的总和
–查询分类为‘c001’的所有商品的总和
select sum (price) from product where category_id = 'c001' ;
4、查询最大 Max 最小 min
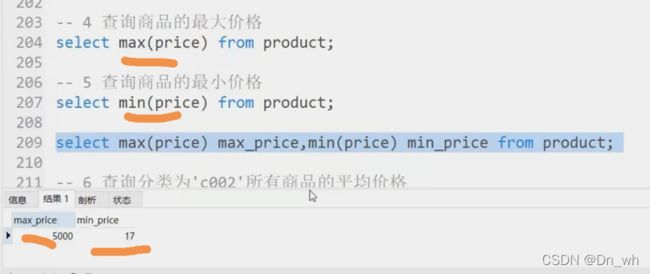
5、查询约束条件下的平均值
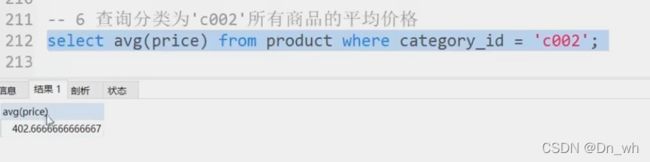
• 聚合函数--NULL处理:视而不见

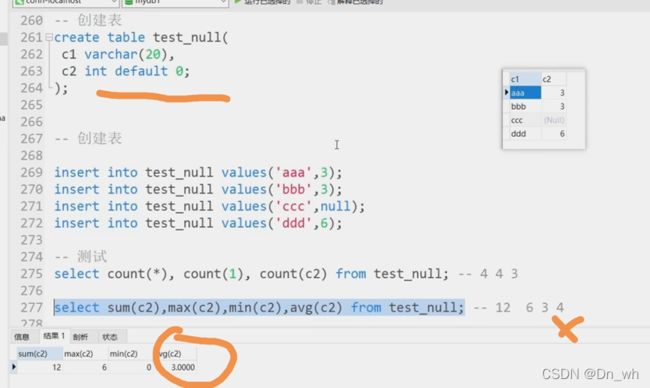
给他默认0,求平均值的时候就把它算上了
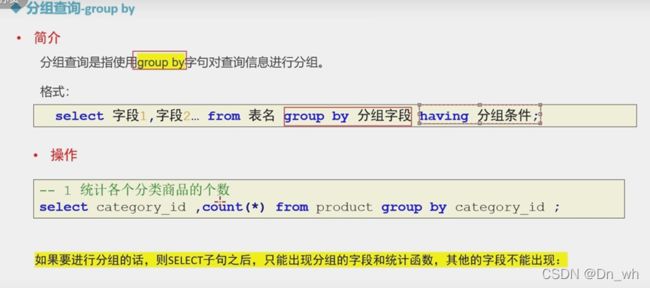
• 分组查询--group by ,having
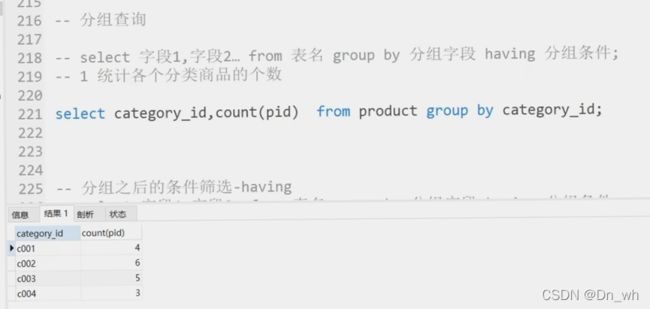
执行过程
注意: 分组之后,select 的后边只能写分组字段和聚合函数
这是因为,分组之后的数据是一组数据,不能用其中一行来表示其他的数据

•
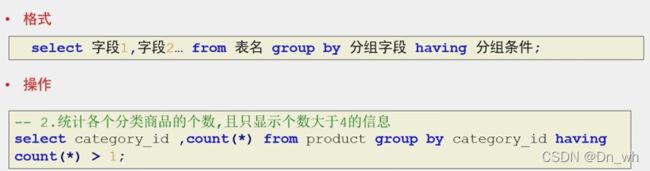
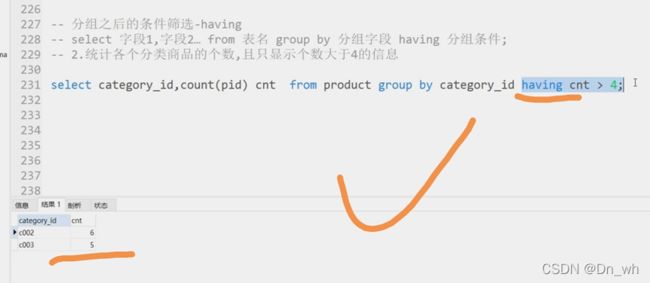
分组查询--分组之后的条件筛选-having语句
注意:
1、分组之后对统计结果进行筛选的货必须使用having,不能使用where
2、where子句用来筛选from 子句中指定的操作所产生的行
3、group by 子句用来从分组where子句的输出
4、having子句用来从分组的结果中筛选行
where 后面不能加聚合函数

group by 后分组必须用having
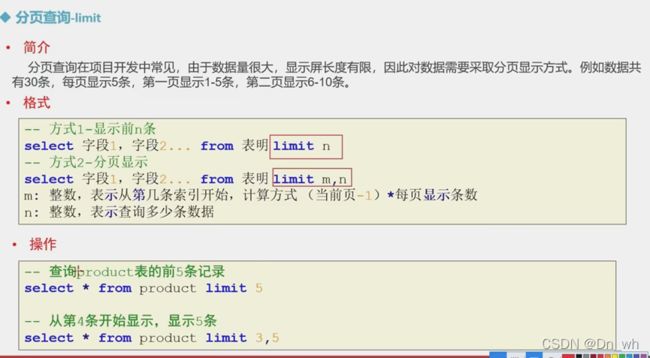
• 分页查询--limit
第一条是0,第n条是n—1

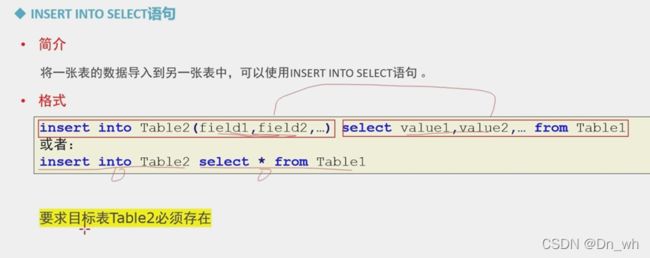
• insert into select 语句
将一张表的数据导入到另一张表中
要求;
目标表必须存在
前面表的字段和后面表都存在,类型一致
例子:
按类别分组插入查询

• 总结
1、简单查询
2、运算符操作
3、排序查询--order by asc (升序)| desc(降序)
4、聚合查询
5、分组查询
6、分页查询
• 基本查询DQL
1、简单查询:
2、运算符操作:

3、排序查询-order by

4、聚合查询-count sum max min avg
count(*) = count(1)
如果列中有null,不进行计算,当做不存在

分组之后是对每组进行查询:
eg:
--统计各个分类商品的个数
--注意:分组之后,select 的后边只能写分组字段和聚合函数
select category_id , count(pid) from product group by category_id;
5、分组查询-group by
6、分页显示-limit
查询product 表的前5 条记录
select * from product limit5;
#从第4 条开始显示,显示2条
select* from product limit3,5;
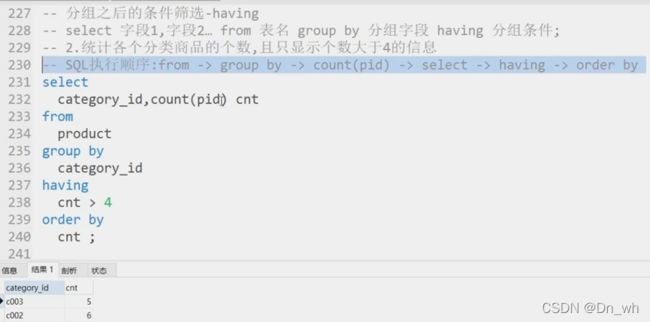
7、sql 的书写顺序:
select
category_id,count(pid) cnt
from
product
where
price >1000
group by
category_id
having
cnt > 4
order by
cnt
limit 1
;
8、SQL 的执行顺序
from
where
group by
count(pid)
having
select
orderby
limit