Kylin、druid、presto、impala四种即席查询对比--(转载)
一、什么是即席查询
即席查询是用户根据自己的需求,灵活的选择查询条件,系统根据用户的选择生成相应的统计报表。普通查应用查询是定制开发的,即席查询是用户自定义查询条件
理解:快速的执行自定义SQL(可能无法提前运算和预测)
重点关注:数据存储格式和架构
理解了什么是即席查询之后,下面会从定义、框架原理、优化等几个方面介绍这四个框架、最后会做一个对比,面对不同的业务选择合适的框架
二、Kylin (over)
1、定义:Apache kylin是一个开源分布式分析引擎、提供Hadoop、Spark之上的SQL
查询接口及多维分析(OLAP)能力,可以再亚秒内查询巨大的Hive表
(还可以与BI工具集成ODBC、JDBC、RestAPI、还有自带的Zepplin插件,来访问Kylin服务)
2、架构

Kylin架构
a、REST 服务层:应用程序开发的入口点
b、查询引擎层:Cube准备就绪后,与系统中的其他组件进行交互,从而向用户返回对应的结果
c、路由层:将解析的SQL生成的执行计划转换成Cube缓存的查询,cube通过预计算缓存在hbase中,这些操作可以在毫秒级完成,还有一些操作使用的原始查询,这部分延迟较高(麒麟高版本中已删除该层)
d、元数据管理工具:kylin的元数据管理存储在hbase中
e、任务引擎:处理所有离线任务:包括shell脚本、javaAPI以及MapReduce任务等等
3、原理
学习kylin的原理之前我们需要掌握几个名词
维度:即观察数据的角度
度量:即被聚合的统计值也就是聚合运算的结果
Cuboid:对于每一种维度的组合,将度量值做聚合计算,然后将结果保存为一个物化视图,称为Cuboid。
Cube:所有维度组合的Cuboid作为一个整体,称为Cube。
Apache Kylin的工作原理本质上是MOLAP(多维立方体分析),即对数据模型做Cube预计算,并利用计算的结果加速查询
a、指定数据模型,定义维度和度量
b、预计算Cube,计算所有Cuboid并保存为物化视图
预计算过程是kylin读取hive中的数据,按照我们选定的维度进行计算,将结果保存在hbase中,默认计算引擎为MapReduce,其中build一次的结果我们称为一个segment,其中涉及多个算法,由kylin.cube.algorithm参数决定,参数值可选auto,layer和inmen,默认值为auto。
逐层构建算法(layer)
逐层算法中,按维度数逐层减少来计算,每个层级的计算(除了第一层,它是从原始数据聚合而来),是基于它上一层级的结果来计算的。比如,[Group by A, B]的结果,可以基于[Group by A, B, C]的结果,通过去掉C后聚合得来的;这样可以减少重复计算;当 0维度Cuboid计算出来的时候,整个Cube的计算也就完成了。
每一轮的计算都是一个MapReduce任务,且串行执行;一个N维的Cube,至少需要N+1次MapReduce Job。
缺点:该算法的效率较低,尤其是当Cube维度系数较大的时候
快速构建算法(inmem)
也被称作“逐段”(By Segment) 或“逐块”(By Split) 算法,从1.5.x开始引入该算法,利用Mapper端计算先完成大部分聚合,再将聚合后的结果交给Reducer,从而降低对网络瓶颈的压力。该算法的主要思想是,对Mapper所分配的数据块,将它计算成一个完整的小Cube 段(包含所有Cuboid);每个Mapper将计算完的Cube段输出给Reducer做合并,生成大Cube,也就是最终结果;如图所示解释了此流程。
与旧算法相比,快速算法主要有两点不同:
1) Mapper会利用内存做预聚合,算出所有组合;Mapper输出的每个Key都是不同的,这样会减少输出到Hadoop MapReduce的数据量;
2)一轮MapReduce便会完成所有层次的计算,减少Hadoop任务的调配。
c、执行查询,读取Cuboid,运行,产生查询结果
下面举一个简单的例子说明,假设有一个电商的销售数据集,其中维度包括时间[time]、商品[item]、地区[location]和供应商[supplier],度量为销售额。那么所有维度的组合就有2的4次方-1 = 15种
一维度(1D)的组合有:[time]、[item]、[location]和[supplier]4种;
二维度(2D)的组合有:[time, item]、[time, location]、[time, supplier]、[item, location]、[item, supplier]、[location, supplier]6种;
三维度(3D)的组合也有4种;
四维度(4D)各有一种,总共15种。
注意:每一种维度组合就是一个Cuboid,16个Cuboid整体就是一个Cube。
4、Cube构建优化
1)检查问题Cube
还有一种更为简单的方法可以帮助我们判断Cube是否已经足够优化。在Web GUI的Model页面选择一个READY状态的Cube,当我们把光标移到该Cube的Cube Size列时,Web GUI会提示Cube的源数据大小,以及当前Cube的大小除以源数据大小的比例,称为膨胀率(Expansion Rate),如图所示。
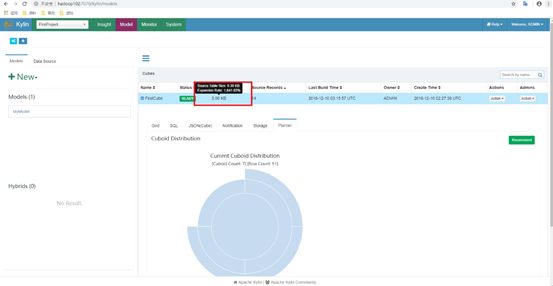
一般来说,Cube的膨胀率应该在0%~1000%之间,如果一个Cube的膨胀率超过1000%,那么Cube管理员应当开始挖掘其中的原因。通常,膨胀率高有以下几个方面的原因。
a、Cube中的维度数量较多,且没有进行很好的Cuboid剪枝优化,导致Cuboid数量极多;
b、Cube中存在较高基数的维度,导致包含这类维度的每一个Cuboid占用的空间都很大,这些Cuboid累积造成整体Cube体积变大;
因此,对于Cube膨胀率居高不下的情况,我们需要结合实际数据进行分析,可灵活地运用以下介绍的优化方法对Cube进行优化。
2)优化构建
a、使用聚合组
强制维度:如果一个维度被定义为强制维度,那么这个分组所产生的Cuboid中每一个都会包含该维度
层级维度:每个层级包含两个或更多个维度。假设一个层级中包含D1,D2…Dn这n个维度,那么在该分组产生的任何Cuboid中,这n个维度只会以(),(D1),(D1,D2)…(D1,D2…Dn)这n+1种形式中的一种出现。
联合维度:每个联合中包含两个或更多个维度,如果某些列形成一个联合,那么在该分组产生的任何Cuboid中,这些联合维度要么一起出现,要么都不出现。
(使用聚合组可以大大减少Cuboid的个数)
b、并发粒度优化
当Segment中某一个Cuboid的大小超出一定的阈值时,系统会将该Cuboid的数据分片到多个分区中,以实现Cuboid数据读取的并行化,从而优化Cube的查询速度。具体的实现方式如下:
构建引擎根据Segment估计的大小,以及参数“kylin.hbase.region.cut”的设置决定Segment在存储引擎中总共需要几个分区来存储,如果存储引擎是HBase,那么分区的数量就对应于HBase中的Region数量。kylin.hbase.region.cut的默认值是5.0,单位是GB,也就是说对于一个大小估计是50GB的Segment,构建引擎会给它分配10个分区。用户还可以通过设置kylin.hbase.region.count.min(默认为1)和kylin.hbase.region.count.max(默认为500)两个配置来决定每个Segment最少或最多被划分成多少个分区。
假设将把当前Cube的kylin.hbase.region.count.min设置为2,kylin.hbase.region.count.max设置为100。这样无论Segment的大小如何变化,它的分区数量最小都不会低于2,最大都不会超过100。相应地,这个Segment背后的存储引擎(HBase)为了存储这个Segment,也不会使用小于两个或超过100个的分区。我们还调整了默认的kylin.hbase.region.cut,这样50GB的Segment基本上会被分配到50个分区,相比默认设置,我们的Cuboid可能最多会获得5倍的并发量。
三、impala
1、定义:Cloudera公司推出,提供对HDFS、Hbase数据的高性能、低延迟的交互式SQL查询功能。基于Hive,使用内存计算,兼顾数据仓库、具有实时、批处理、多并发等优点。
2、架构
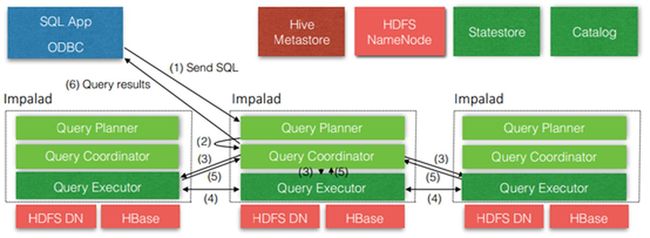
Impala架构
从上图可以看出,Impala自身包含三个模块:Impalad、Statestore和Catalog,除此之外它还依赖hive Metastore和HDFS
1) Impalad:
接收client的请求、Query执行并返回给中心协调节点。
子节点上的守护进程,负责向statestore保持通信,汇报工作。
2) Catalog:
分发表的元数据信息到各个impalad中;
接收来自statestore的所有请求。
3) Statestore:
负责收集分布在集群中各个impalad进程的资源信息、各节点健康状况,同步节点信息;
负责query的协调调度。
3、存储和架构
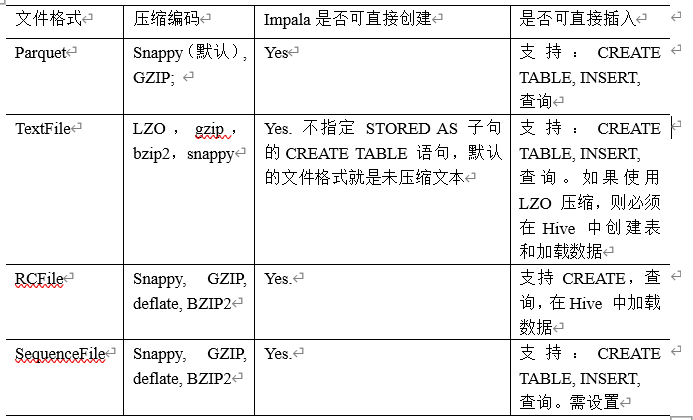
注:impala不支持ORC格式
4、Impala的查询
1. 基本的语法跟hive的查询语句大体一样
2. Impala不支持CLUSTER BY, DISTRIBUTE BY, SORT BY
3. Impala中不支持分桶表
4. Impala不支持COLLECT_SET(col)和explode(col)函数
5. Impala支持开窗函数
5、优化
1、 尽量将StateStore和Catalog单独部署到同一个节点,保证他们正常通信。
2、 通过对Impala Daemon内存限制(默认256M)及StateStore工作线程数,来提高Impala的执行效率。
3、 SQL优化,使用之前调用执行计划
4、 选择合适的文件格式进行存储,提高查询效率。
5、 避免产生很多小文件(如果有其他程序产生的小文件,可以使用中间表,将小文件数据存放到中间表。然后通过insert…select…方式中间表的数据插入到最终表中)
6、 使用合适的分区技术,根据分区粒度测算
7、 使用 compute stats进行表信息搜集,当一个内容表或分区明显变化,重新计算统计相关数据表或分区。因为行和不同值的数量差异可能导致impala选择不同的连接顺序时进行查询。
8、 网络io的优化:
–a.避免把整个数据发送到客户端
–b.尽可能的做条件过滤
–c.使用limit字句
–d.输出文件时,避免使用美化输出
–e.尽量少用全量元数据的刷新
9、 使用profile输出底层信息计划,在做相应环境优化
四、Druid
1、定义
Druid 是一个分布式的支持实时分析的数据存储系统,具有以下几个特点
- 亚秒级 OLAP 查询,包括多维过滤、Ad-hoc 的属性分组、快速聚合数据等等。
- 实时的数据消费,真正做到数据摄入实时、查询结果实时。
- 高效的多租户能力,最高可以做到几千用户同时在线查询。
- 扩展性强,支持 PB 级数据、千亿级事件快速处理,支持每秒数千查询并发。
- 极高的高可用保障,支持滚动升级。
实时数据分析是 Apache Druid 最典型的使用场景。该场景涵盖的面很广,例如:
- 实时指标监控
- 推荐模型
- 广告平台
- 搜索模型
这些场景的特点都是拥有大量的数据,且对数据查询的时延要求非常高。在实时指标监控中,系统问题需要在出现的一刻被检测到并被及时给出报警。在推荐模型中,用户行为数据需要实时采集,并及时反馈到推荐系统中。用户几次点击之后系统就能够识别其搜索意图,并在之后的搜索中推荐更合理的结果
(注意:阿里巴巴也曾创建过一个开源项目叫作Druid(简称阿里Druid),它是一个数据库连接池的项目。阿里Druid 和本问讨论的Druid 没有任何关系,它们解决完全不同的问题。)
2、架构和原理
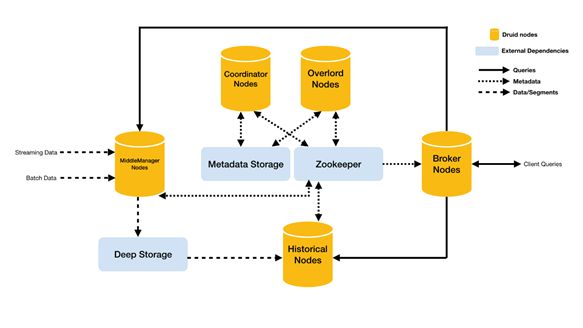
Druid架构
Druid总体包含以下5类节点:
1. 中间管理节点(middleManager node):及时摄入实时数据,已生成Segment数据文件。
2. 历史节点(historical node):加载已生成好的数据文件,以供数据查询。historical 节点是整个集群查询性能的核心所在,因为historical会承担绝大部分的segment查询。
3. 查询节点(broker node):接收客户端查询请求,并将这些查询转发给Historicals和MiddleManagers。当Brokers从这些子查询中收到结果时,它们会合并这些结果并将它们返回给调用者。
4. 协调节点(coordinator node):主要负责历史节点的数据负载均衡,以及通过规则(Rule)管理数据的生命周期。协调节点告诉历史节点加载新数据、卸载过期数据、复制数据、和为了负载均衡移动数据。
5. 统治者(overlord node) :进程监视MiddleManager进程,并且是数据摄入Druid的控制器。他们负责将提取任务分配给MiddleManagers并协调Segement发布。
同时,Druid还包含3类外部依赖:
1. 数据文件存储库(DeepStorage):存放生成的Segment数据文件,并供历史服务器下载,对于单节点集群可以是本地磁盘,而对于分布式集群一般是HDFS。
2. 元数据库(Metastore),存储Druid集群的元数据信息,比如Segment的相关信息,一般用MySQL或PostgreSQL。
3. Zookeeper:为Druid集群提供以执行协调服务。如内部服务的监控,协调和领导者选举。
3、 Druid的数据结构
与Druid架构相辅相成的是其基于DataSource与Segment的数据结构,它们共同成就了 Druid的高性能优势。
3.1. DataSource结构
若与传统的关系型数据库管理系统( RDBMS)做比较,Druid的DataSource可以理解为 RDBMS中的表(Table)。DataSource的结构包含以下几个方面。
1. 时间列( TimeStamp):表明每行数据的时间值,默认使用 UTC时间格式且精确到毫秒级别。这个列是数据聚合与范围查询的重要维度。
2. 维度列(Dimension):维度来自于 OLAP的概念,用来标识数据行的各个类别信息。
3. 指标列( Metric):指标对应于 OLAP概念中的 Fact,是用于聚合和计算的列。这些指标列通常是一些数字,计算操作通常包括 Count、Sum和 Mean等。
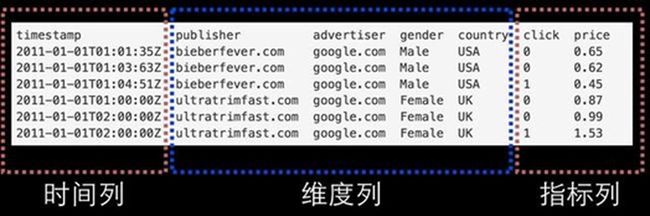
DataSource结构
无论是实时数据消费还是批量数据处理, Druid在基于DataSource结构存储数据时即可选择对任意的指标列进行聚合( RollUp)操作。该聚合操作主要基于维度列与时间范围两方面的情况。
下图显示的是执行聚合操作后 DataSource的数据情况。

DataSource聚合后的数
相对于其他时序数据库, Druid在数据存储时便可对数据进行聚合操作是其一大特点,该特点使得 Druid不仅能够节省存储空间,而且能够提高聚合查询的效率。
3.2. Segment结构
DataSource是一个逻辑概念, Segment却是数据的实际物理存储格式, Druid正是通过 Segment实现了对数据的横纵向切割( Slice and Dice)操作。从数据按时间分布的角度来看,通过参数 segmentGranularity的设置,Druid将不同时间范围内的数据存储在不同的 Segment数据块中,这便是所谓的数据横向切割。
这种设计为 Druid带来一个显而易见的优点:按时间范围查询数据时,仅需要访问对应时间段内的这些 Segment数据块,而不需要进行全表数据范围查询,这使效率得到了极大的提高。
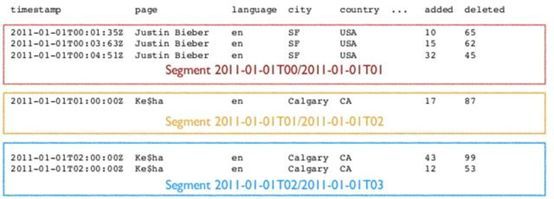
通过 Segment将数据按时间范围存储,同时,在 Segment中也面向列进行数据压缩存储,这便是所谓的数据纵向切割。而且在 Segment中使用了 Bitmap等技术对数据的访问进行了优化。
五、Presto
1、定义
Presto是一个开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB字节。注:虽然Presto可以解析SQL,但它不是一个标准的数据库。不是MySQL、Oracle的代替品,也不能用来处理在线事务(OLTP)
应用场景
Presto支持在线数据查询,包括Hive,关系数据库(MySQL、Oracle)以及专有数据存储。一条Presto查询可以将多个数据源的数据进行合并,可以跨越整个组织进行分析。
Presto主要用来处理响应时间小于1秒到几分钟的场景。
2、架构
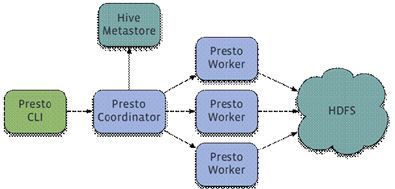
Presto有两类服务器:Coordinator和Worker。
1)Coordinator
Coordinator服务器是用来解析语句,执行计划分析和管理Presto的Worker结点。Presto安装必须有一个Coordinator和多个Worker。如果用于开发环境和测试,则一个Presto实例可以同时担任这两个角色。
Coordinator跟踪每个Work的活动情况并协调查询语句的执行。Coordinator为每个查询建立模型,模型包含多个Stage,每个Stage再转为Task分发到不同的Worker上执行。
Coordinator与Worker、Client通信是通过REST API。
2)Worker
Worker是负责执行任务和处理数据。Worker从Connector获取数据。Worker之间会交换中间数据。Coordinator是负责从Worker获取结果并返回最终结果给Client。
当Worker启动时,会广播自己去发现 Coordinator,并告知 Coordinator它是可用,随时可以接受Task。
Worker与Coordinator、Worker通信是通过REST API。
3)数据源
贯穿全文,你会看到一些术语:Connector、Catelog、Schema和Table。这些是Presto特定的数据源
(1)Connector
Connector是适配器,用于Presto和数据源(如Hive、RDBMS)的连接。你可以认为类似JDBC那样,但却是Presto的SPI的实现,使用标准的API来与不同的数据源交互。
Presto有几个内建Connector:JMX的Connector、System Connector(用于访问内建的System table)、Hive的Connector、TPCH(用于TPC-H 基准数据)。还有很多第三方的Connector,所以Presto可以访问不同数据源的数据。
每个Catalog都有一个特定的Connector。如果你使用catelog配置文件,你会发现每个文件都必须包含connector.name属性,用于指定catelog管理器(创建特定的Connector使用)。一个或多个catelog用同样的connector是访问同样的数据库。例如,你有两个Hive集群。你可以在一个 Presto集群上配置两个catelog,两个catelog都是用Hive Connector,从而达到可以查询两个 Hive集群。
(2)Catelog
一个Catelog包含Schema和Connector。例如,你配置JMX的catelog,通过JXM Connector访问JXM信息。当你执行一条 SQL语句时,可以同时运行在多个catelog。
Presto处理table时,是通过表的完全限定(fully-qualified)名来找到catelog。例如,一个表的权限定名是hive.test_data.test,则test是表名,test_data是schema,hive是catelog。
Catelog的定义文件是在Presto的配置目录中。
(3)Schema
Schema是用于组织table。把catelog好schema结合在一起来包含一组的表。当通过Presto访问hive或Mysq时,一个schema会同时转为hive和mysql的同等概念。
(4)Table
Table跟关系型的表定义一样,但数据和表的映射是交给Connector。
数据模型
1)Presto采取三层表结构:
Catalog:对应某一类数据源,例如Hive的数据,或MySql的数据
Schema:对应MySql中的数据库
Table:对应MySql中的表
2)Presto的存储单元包括:
Page:多行数据的集合,包含多个列的数据,内部仅提供逻辑行,实际以列式存储。
Block:一列数据,根据不同类型的数据,通常采取不同的编码方式,了解这些编码方式,有助于自己的存储系统对接presto。
3)不同类型的Block:
(1)Array类型Block,应用于固定宽度的类型,例如int,long,double。block由两部分组成:
boolean valueIsNull[]表示每一行是否有值。
T values[] 每一行的具体值。
(2)可变宽度的Block,应用于String类数据,由三部分信息组成
Slice:所有行的数据拼接起来的字符串。
int offsets[]:每一行数据的起始便宜位置。每一行的长度等于下一行的起始便宜减去当前行的起始便宜。
boolean valueIsNull[] 表示某一行是否有值。如果有某一行无值,那么这一行的便宜量等于上一行的 偏移量。
(3)固定宽度的String类型的block,所有行的数据拼接成一长串Slice,每一行的长度固定。
(4)字典block:对于某些列,distinct值较少,适合使用字典保存。主要有两部分组成:
字典,可以是任意一种类型的block(甚至可以嵌套一个字典block),block中的每一行按照顺序排序编号。
int ids[]表示每一行数据对应的value在字典中的编号。在查找时,首先找到某一行的id,然后到字典中获取真实的值。
总结:
1.Druid:是一个实时处理时序数据的OLAP数据库,因为它的索引首先按照时间分片,查询的时候也是按照时间线去路由索引。
2.Kylin:核心是Cube,Cube是一种预计算技术,基本思路是预先对数据作多维索引,查询时只扫描索引而不访问原始数据从而提速。
3.Presto:它没有使用Mapreduce,大部分场景下比HIVE块一个数量级,其中的关键是所有的处理都在内存中完成。
4.Impala:基于内存计算,速度快,支持的数据源没有Presto多。
5.SparkSQL:是spark用来处理结构化的一个模块,它提供一个抽象的数据集DataFrame,并且是作为分布式SQL查询引擎的应用。它还可以实现Hive on Spark,hive里的数据用sparksql查询。
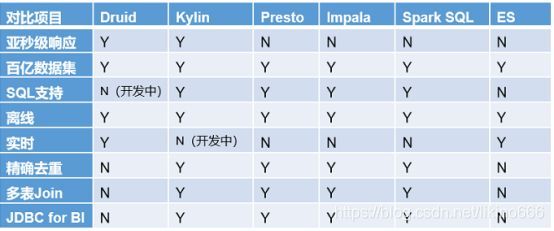
6.框架选型:(1)从超大数据的查询效率来看:
Druid>Kylin>Presto>SparkSQL
(2)从支持的数据源种类来讲:
Presto>SparkSQL>Kylin>Druid