Hive基础学习和高级查询(视图、select、join)
本篇文章接续前一篇文章,如对本篇内容有不理解的地方可以参考上一篇博文:Hive学习。
目录
-
- 视图
-
- 视图概述
- 视图操作
- 建表高阶语句
- 高级查询
-
- select
- 关联查询join
- Hive的集合操作
视图
有学过SQL的小伙伴相信对视图这一概念并不陌生。事实上,Hive中的视图和SQL中视图的概念作用等基本一致,下面也见到介绍一下这一概念。
视图概述
- 通过隐藏子查询、连接和函数来简化查询的逻辑结构;
- 它是一个虚拟表,从真实表中选取数据;
- 只保存定义,不保存数据;
- 如果删除或更改基础表,则查询视图会失败;
- 视图是只读的,不能插入或装载数据。
- 它主要应用在将特定的列提供给用户,保护数据隐私。当查询语句复杂的时候,视图也能发挥很好的查询作用。
视图操作
在创建视图之前,我们根据下面的数据创建一个表,并上传相应的数据:
Michael|Montreal,Toronto|Male,30|DB:80|Product:DeveloperLead
Will|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead Shelley|New
York|Female,27|Python:80|Test:Lead,COE:Architect
Lucy|Vancouver|Female,57|Sales:89|Sales:Lead
create table emp(
name string,
address array<string>,
info struct<gender:string,age:int>,
technol map<string,int>,
jobs map<string,string>)
row format delimited
fields terminated by '|'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n';
上传文件:
hdfs dfs -put employee.txt /opt/hive/warehouse/emp
根据上面的表我们来创建视图:
格式:create view 视图名 as select 字段列表 from 表名:
create view emp_view as select * from emp;
视图创建成功后我们可以通过show tables的方法查找视图(show views在Hive2.2.0之后可用,这里版本不够):
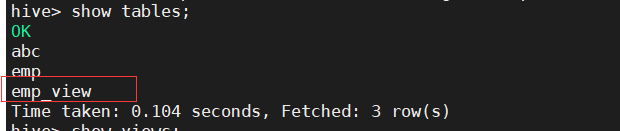
用show create table 视图名指令可以查看视图的定义:
show create table emp_view;
![]()
包含视图名,表的字段列表信息。
视图创建完成后,我们可以通过查询语句通过查询视图来查看信息。
select * from emp_view;

侧视图
侧视图是视图的一种,它常与表生成函数结合使用,将函数的输入和输出连接。我们以下面的数据为例,用侧视图进行单词的统计:
I wish you wish
I love java
I love Hadoop
I love Hive
I love Python
首先创建一个表,并上传文件到HDFS:
create table count(line string);
创建侧视图:
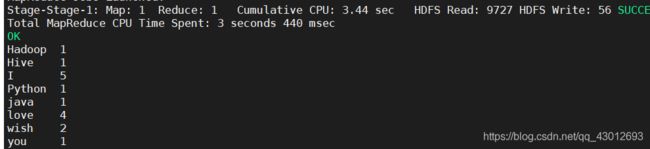
select word,count(word) from count
lateral view explode(split(line,' '))a as word group by word;
word和count(word)就是定义的列名,split(line,’ ')表示数据以空格分隔:
在这个基础上,还可以再继续添加一个侧视图,即支持多层级视图,这里就不再演示,有兴趣的伙伴可以自己研究一下。
建表高阶语句
我们在介绍三种新的建表语句,都是在现有表的基础上进行建立。
CTAS
CTAS -as select 方式建表,格式:
create table 新表名 as select 字段列 from 表名;
create table empCtas as select * from emp;
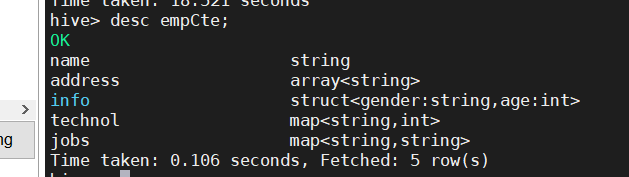
建表成功后我们可以通过desc查看表结构,和原始表一样

注意:ctas不能创建partition,external,bucket table!!!
CTE
全称是:CTAS with Common Table Expression,是CTAS的拓展。
格式:create table 表名 as with 临时表名(select…) select * from 临时表名;
create table empCte as
with t1 as(select * from emp)
select * from t1;
上面的CTE我们只用了一层,其实还可以多套几层查询语句,例如下列的示例:
CREATE TABLE cte_employee AS
WITH
r1 AS (SELECT name FROM r2 WHERE name = 'Michael'),
r2 AS (SELECT name FROM employee WHERE sex_age.sex= 'Male'),
r3 AS (SELECT name FROM employee WHERE sex_age.sex= 'Female')
SELECT * FROM r1 UNION ALL SELECT * FROM r3;
层层嵌套,这里用到UNION ALL会在下文进行讲解。
Like
格式:create table 新表名 like 原始表名;
create table empLike like emp;
这一方法十分简单,也更容易理解,相当于是直接复制了emp表:

高级查询
Hive的高级查询语句主要有数据查询(select),数据关联(join),数据合并(union)等,我们先从select说起。
select
HIve的select方法类似于Mysql,我们还是以前面的emp表为例:
select * from emp;

也可以指定想要查询的列还有条件。例如我想要查询名叫Michael的人,展示他的姓名、地址和性别信息就可以通过下面的语句进行查询。
select name,address[0],info.gender from emp where name='Michael';

除了用上面的查询语句外,Hive还有另外两种查询方式:CTE查询和嵌套查询。
CTE
CTE(Common Table Expression)的语法格式为:
with tableName as(select …) select * from tableName;
要和前面讲过的CTE建表语句区分开。这个语句,先执行括号里的查询,执行完括号里的查询之后,会生成一个临时表,tableName就是这个临时表的表名,然后再从这个临时表中查询所需要的信息。
用emp做示例:
with t1 as (select * from emp) select*from t1;

with t1 as (select name,address[0] from emp) select name from t1;

CTE查询我们其实可以看成是一个子查询,先查出一个表中的数据,然后再从这个临时表中进行查找。
嵌套查询
嵌套查询的效果和CTE的效果是一样的,可以看成是不同的写法:
格式:select 字段列 from (select 字段列 from 表名1)表名。
select * from (select * from emp)a;

需要注意的是,括号内的查询执行完成后一定要赋予表名,否则就会报错。
列匹配正则表达式
在进行正则表达式之前需要先在命令行输入以下指令,开启正则:
SET hive.support.quoted.identifiers = none;
匹配语句,匹配所有的列:
select `.*` from emp;

虚拟列
虚拟列是为了快速定位文件而产生的。当我们在日常工作中,针对某些出错的文件需要快速定位,这时就可以用到虚拟列。它主要有以下两种参数:
INPUT__FILE__NAME:Mapper Task的输入文件名称
BLOCK__OFFSET__INSIDE__FILE:当前全局文件位置,文件的行偏移量。
注意是两个下划线,用于数据验证。
select input__file__name from emp;

可以查到文件的路径和文件名;
select block__offset__inside__file from emp;

这里数字所代表的意思是每行数据的其实字节,即从第几个字节开始的,
两个语句合并起来查询就能得到文件详细的路径信息:
select input__file__name,block__offset__inside__file from emp;

关联查询join
Join连接指的是对多表进行联合查询,它用于将两个表甚至更多的表关联起来,在一张表上得出不同表上的信息。类似于SQL的join。Hive的join主要有以下四种连接方式:
内连接:inner join,连接的结果仅包含符合连接条件的行;
外连接:outer join,连接的结果不仅包含符合条件的行,还包括不符合自身条件的行,如左外连接,右外连接,全连接;
交叉连接:cross join,会产生笛卡尔积;
下面我们用下面的数据做示例:
学生表数据:
2016001,Join
2016002,Abigail
2016003,Abby
2016004,Alexandra
2016005,Cathy
2016006,Katherine
成绩表数据:
2016001,YY,60
2016001,SX,88
2016001,YW,91
2016002,SX,77
2016002,YW,33
建表后上传数据:
create table score(
id int,
course string,
scores int)
row format delimited
fields terminated by ','
lines terminated bt '\n';
create table score(
id int,
course string,
scores int)
row format delimited
fields terminated by ','
lines terminated by '\n';
hdfs dfs -put student.txt /opt/hive/warehouse/hivetest.db/student
hdfs dfs -put score.txt /opt/hive/warehouse/hivetest.db/score
内连接:
select name,scores from student a join score b on a.id=b.id;

inner可以省略通过内连接,可以把两张表上相同学生id的姓名和分数都查询出来然后整合到一起显示。
外连接:
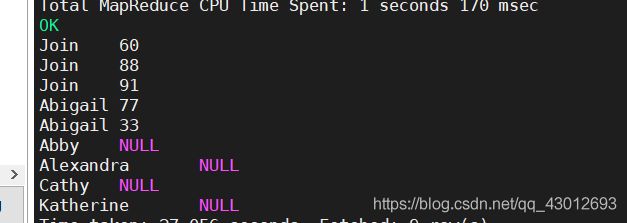
左外连接,又称左连接,连接时以join左边的表为主,查询出后,主表的数据都会显示出来,不论是否符合查询条件:
select name,scores from student a left join score b on a.id=b.id;
和内连接的代码不同的是多了个left,同样outer也可以省略。查询结果显示了学生表的所有信息,但是分数表中并不包含所有的学生成绩,所有分数那一列为空值。
右外连接(右连接):
select name,scores from student a right join score b on a.id=b.id;
和左连接相同,只不过是以join右面的表为主。
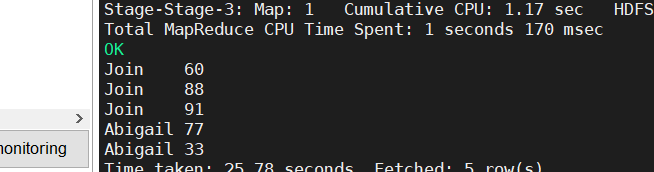
全连接:
全连接的关键字是full,相当于是左连接和右连接的结合,关键字是full:
select name,scores from student a full join score b on a.id=b.id;
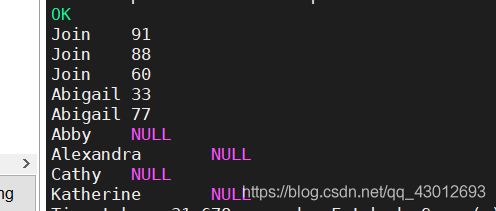
交叉连接:
select name,scores from student a cross join score b;
交叉连接关键字是cross,它会把所有的数据都查出来并赋上相应的值,这些值可能是错误的,它产生的行数为两表行数的积。当然我们可以通过加上查询条件来精确我们的数据。交叉连接的效果等于select name,scores from student,score;

MapJoin
在学习MapReduce的时候接触过,通过Map端用java来实现文件的合并而不需要进入Reduce阶段,节省了再shuffle阶段的工作量,从而起到优化作用,那么这里我们就用Hive语句来实现这一过程。
MapJoin的操作在Map端完成,由小表关联大表,可进行不等值连接。在进行join之前,首先要开启join操作:
set hive.auto.convert.join=true(默认值)
运行时自动将连接转换为MapJoin。
select /*+ mapjoin(student)*/ name from student a left join score b on
a.id=b.id;

可以看出,MapJoin的语句和其他join语句还是有所不同的,它声明了使用MapJoin的表。MapJoin不支持在unionall,lateral view,group by,join,sort by,cluster by,distribute by等后面进行操作,需要在这之前操作。
Hive的集合操作
集合操作这里主要有两种:union all和union.。
union all合并后保留重复项,union在Hive更新1.2版本后,合并后删除重复项。在进行合并的时候,子集数据必须具有相同的名称(列名称)才可。给大家放一个示例感受一下:
select a.id from student a
union all
select b.id from score b;
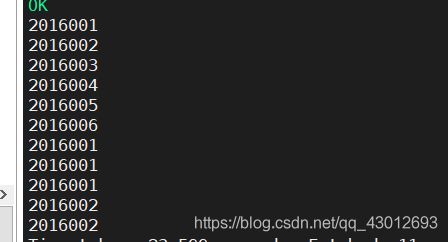
我所使用的是union all(受限于版本,无法演示union)它所输出的结果是把两表内所有的id都整合到一起查询出来。在我们平时的查询过程中,也可以在查询语句中套一层union all或者union,方便我们代码的书写。