spark源码----Spark任务划分、调度、执行
从RDD的创建开始讲起
![]()
把它当做入口,然后点进去

主要关注hadoopFile,进去会发现new了一个HadoopRDD

以上其实就是一个RDD的构建过程
又比如我们看flatMap,它一样会去构建一个新的RDD,把之前的RDD给传进去了

又比如我们看map,它一样会去构建一个新的RDD,把之前的RDD给传进去了

在换一个算子reduceByKey,点进去,包含一个默认的分区器

然后再点进去,combineByKeyWithClassTag是一个预聚合概念,所以reduceByKey会先在本地做一次聚合,所以它的效率比groupByKey的效率高

再进去,你会看到最终还是一个RDD
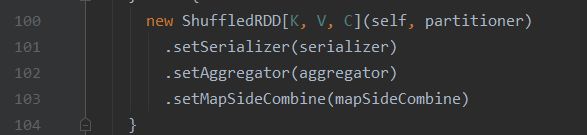
Shuffled会有一个依赖的,所以我们可以进去看看

而map这种,最后进去,它是一对一的依赖

所以reduceByKey这种算子,就叫做宽依赖,map这种就叫窄依赖
宽窄看完后,在看看我们的active算子,以foreach为例(主要是看其任务是怎么一步步的提交的)

点击runJob进去

这里面会不断的去调用runJob,所以我们需要一直点进去,直到没有runJob

如上图由dagScheduler来进行我们的作业
再点runJob进去
def runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit = {
val start = System.nanoTime
// 提交我们的作业
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
// 后面都是在等待我们的执行
ThreadUtils.awaitReady(waiter.completionFuture, Duration.Inf)
waiter.completionFuture.value.get match {
case scala.util.Success(_) =>
logInfo("Job %d finished: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
case scala.util.Failure(exception) =>
logInfo("Job %d failed: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
// SPARK-8644: Include user stack trace in exceptions coming from DAGScheduler.
val callerStackTrace = Thread.currentThread().getStackTrace.tail
exception.setStackTrace(exception.getStackTrace ++ callerStackTrace)
throw exception
}
}
在从submitJob进去

看到这儿会看到是一直往eventProcessLoop里面放东西,那么再进去看看
![]()
再进去

再点,这个BlockingQueue是一个阻塞式队列(放满了阻塞,取没有数据也阻塞)
private[spark] abstract class EventLoop[E](name: String) extends Logging {
private val eventQueue: BlockingQueue[E] = new LinkedBlockingDeque[E]()
private val stopped = new AtomicBoolean(false)
private val eventThread = new Thread(name) {
setDaemon(true)
override def run(): Unit = {
try {
while (!stopped.get) {
val event = eventQueue.take()
try {
// 发了消息,接收
onReceive(event)
} catch {
case NonFatal(e) =>
try {
onError(e)
} catch {
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
}
}
.....
看一下onReceive是怎么处理的,会发现它是一个抽象的方法,那么需要去找具体的实现

JobSubmitted 这个就是刚刚看到的提交的东西,进去看看handleJobSubmitted,下面这一行代码的意思就是创建一个结果的阶段
![]()
再进去,里面一定有一个完成阶段的结果阶段,而val parents = getOrCreateParentStages(rdd, jobId)表示上一级的阶段,有还是没有

进去看看,红框,判断有没有shuffle的依赖

在点进去看看
// 其实就是在从后往前查找shuffle再哪儿
private[scheduler] def getShuffleDependencies(
rdd: RDD[_]): HashSet[ShuffleDependency[_, _, _]] = {
// 这个就是最终的返回
val parents = new HashSet[ShuffleDependency[_, _, _]]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new Stack[RDD[_]]
waitingForVisit.push(rdd) // 往栈里放值
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.pop() // 判断之后取出 toVisit 就是当前的这个RDD
if (!visited(toVisit)) {
visited += toVisit
toVisit.dependencies.foreach { // 看一下当前访问的RDD的依赖里面有没有shuffle的依赖
// 在这里赋值的
case shuffleDep: ShuffleDependency[_, _, _] =>
parents += shuffleDep
case dependency => // 没有的情况下是把当前RDD依赖的那个RDD给放进去
waitingForVisit.push(dependency.rdd)
}
}
}
parents // 比如wordCount只有一个shuffle,所以就只会返回一个
}
再回去
private def getOrCreateParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
// shuffle依赖拿到之后,再根据shuffle来拿到和转化stage
getShuffleDependencies(rdd).map { shuffleDep =>
getOrCreateShuffleMapStage(shuffleDep, firstJobId)
}.toList
}
到这儿的话val parents = getOrCreateParentStages(rdd, jobId)就已经完成了
然后把这个放到了val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)这里面去
所以,我们再去看handleJobSubmitted这个方法
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
try {
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
// 从这里就可以看出,我们的job里面包含了stage,虽然只有一个,但是finalStage里面又包含了parents
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
clearCacheLocs()
logInfo("Got job %s (%s) with %d output partitions".format(
job.jobId, callSite.shortForm, partitions.length))
logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage))
val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
// 阶段划分完了之后,提交 finalStage这个是最终的那个阶段
submitStage(finalStage)
}
到submitStage里面去看看
// stage 这个就是我们最终的那个阶段
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
// 获取丢失的ParentStages
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
// 如果没有上级
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
// 这里一定是先提交第一个阶段或者前面的阶段先提交
submitMissingTasks(stage, jobId.get) //这是最终跳出去的地方 也是提交任务的地方
} else {
// 然后又把上级挨个遍历 然后做了个递归操作
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
到getMissingParentStages这里面去看看, 把当前阶段的最终的RDD放进去,当不为空的时候,放到visit里面去
其实就是在判断有没有上一级的阶段

到submitMissingTasks去看看,发现其中只有两种stage

看到这儿,你会发现它会判断你的阶段到底是符合哪种类型的,也只有两种类型的阶段,然后每一种类型的阶段,都会变成对应的task,task的个数又取决于partitionsToCompute,顾名思义就是我们的计算分区

如果task不是空的,就说明我们有任务,那么就提交我们的任务 先转化成TaskSet,然后提交
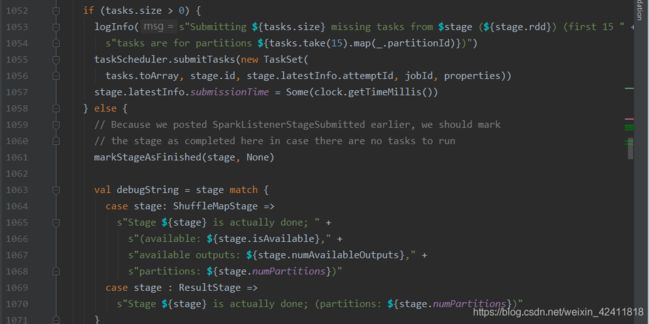
到submitTasks去看,发现是一个抽象的,那么我们再去搜索一下,在TaskSchedulerImpl这里面
override def submitTasks(taskSet: TaskSet) {
val tasks = taskSet.tasks
logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks")
this.synchronized {
// 创建一个TaskSetManager来管理和调度这个taskSet中的task
val manager = createTaskSetManager(taskSet, maxTaskFailures)
val stage = taskSet.stageId
val stageTaskSets =
taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
stageTaskSets(taskSet.stageAttemptId) = manager
val conflictingTaskSet = stageTaskSets.exists { case (_, ts) =>
ts.taskSet != taskSet && !ts.isZombie
}
if (conflictingTaskSet) {
throw new IllegalStateException(s"more than one active taskSet for stage $stage:" +
s" ${stageTaskSets.toSeq.map{_._2.taskSet.id}.mkString(",")}")
}
// 然后放到TaskSetManagerPoll中去(这句话的最终意思可以到addTaskSetManager中去看看,又是一个抽象的方法,再去找找,最后会看到rootPool.addSchedulable(manager),之所以要放到池子里面去是因为,不能保证我们的任务好了之后execute已经准备好了,等有资源之后在发送任务,否则来一个发一个,资源都没有,根本没法发)
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
if (!isLocal && !hasReceivedTask) {
starvationTimer.scheduleAtFixedRate(new TimerTask() {
override def run() {
if (!hasLaunchedTask) {
logWarning("Initial job has not accepted any resources; " +
"check your cluster UI to ensure that workers are registered " +
"and have sufficient resources")
} else {
this.cancel()
}
}
}, STARVATION_TIMEOUT_MS, STARVATION_TIMEOUT_MS)
}
hasReceivedTask = true
}
backend.reviveOffers()
}
然后到reviveOffers去看看,又是抽象,去找下具体实现,在这里会作为一条信息接收

再点进去看看,到这里就会从我们的任务池中去取我们的任务,如果去到就往下执行

private def launchTasks(tasks: Seq[Seq[TaskDescription]]) {
// 取出我们的任务
for (task <- tasks.flatten) {
// 序列化 因为是从driver发到execute中的,所以需要序列化
val serializedTask = TaskDescription.encode(task)
if (serializedTask.limit >= maxRpcMessageSize) {
scheduler.taskIdToTaskSetManager.get(task.taskId).foreach { taskSetMgr =>
try {
var msg = "Serialized task %s:%d was %d bytes, which exceeds max allowed: " +
"spark.rpc.message.maxSize (%d bytes). Consider increasing " +
"spark.rpc.message.maxSize or using broadcast variables for large values."
msg = msg.format(task.taskId, task.index, serializedTask.limit, maxRpcMessageSize)
taskSetMgr.abort(msg)
} catch {
case e: Exception => logError("Exception in error callback", e)
}
}
}
else {
val executorData = executorDataMap(task.executorId)
executorData.freeCores -= scheduler.CPUS_PER_TASK
logDebug(s"Launching task ${task.taskId} on executor id: ${task.executorId} hostname: " +
s"${executorData.executorHost}.")
// 这里就是driver的终端和execute的终端需要发送消息了 发送的消息是启动的任务
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
}
}
再去看看我们是怎么接收上面的消息的,名字叫CoarseGrainedExecutorBackend
override def receive: PartialFunction[Any, Unit] = {
case RegisteredExecutor =>
logInfo("Successfully registered with driver")
try {
executor = new Executor(executorId, hostname, env, userClassPath, isLocal = false)
} catch {
case NonFatal(e) =>
exitExecutor(1, "Unable to create executor due to " + e.getMessage, e)
}
case RegisterExecutorFailed(message) =>
exitExecutor(1, "Slave registration failed: " + message)
// 这就是刚刚发送的任务
case LaunchTask(data) =>
if (executor == null) {
exitExecutor(1, "Received LaunchTask command but executor was null")
} else {
// 反序列化
val taskDesc = TaskDescription.decode(data.value)
logInfo("Got assigned task " + taskDesc.taskId)
// 然后发送到计算对象,开始准备计算了
executor.launchTask(this, taskDesc)
}
case KillTask(taskId, _, interruptThread, reason) =>
if (executor == null) {
exitExecutor(1, "Received KillTask command but executor was null")
} else {
executor.killTask(taskId, interruptThread, reason)
}
case StopExecutor =>
stopping.set(true)
logInfo("Driver commanded a shutdown")
// Cannot shutdown here because an ack may need to be sent back to the caller. So send
// a message to self to actually do the shutdown.
self.send(Shutdown)
case Shutdown =>
stopping.set(true)
new Thread("CoarseGrainedExecutorBackend-stop-executor") {
override def run(): Unit = {
// executor.stop() will call `SparkEnv.stop()` which waits until RpcEnv stops totally.
// However, if `executor.stop()` runs in some thread of RpcEnv, RpcEnv won't be able to
// stop until `executor.stop()` returns, which becomes a dead-lock (See SPARK-14180).
// Therefore, we put this line in a new thread.
executor.stop()
}
}.start()
}
以上就是源码层次的任务划分、调度、执行